- Beautiful Soup — Installation
- Creating a virtual environment (optional)
- Linux environment
- Windows environment
- Installing virtual environment
- Screenshot
- Installing BeautifulSoup
- Linux Machine
- Windows Machine
- Problems after installation
- Installing a Parser
- Linux Machine
- Windows Machine
- Running Beautiful Soup
- Output
- Output
- Модуль BeautifulSoup4 в Python, разбор HTML.
- Извлечение данных из документов HTML и XML.
- Установка BeautifulSoup4 в виртуальное окружение:
- Содержание:
- Выбор парсера для использования в BeautifulSoup4.
- Парсер lxml .
- Парсер html5lib .
- Встроенный в Python парсер html.parser .
- Основные приемы работы с BeautifulSoup4.
- Навигация по структуре HTML-документа:
- Извлечение URL-адресов.
- Извлечение текста HTML-страницы.
- Поиск тегов по HTML-документу:
- Поиск тегов при помощи CSS селекторов:
- Дочерние элементы.
- Родительские элементы.
- Документация Beautiful Soup¶
- Техническая поддержка¶
- Быстрый старт¶
- Установка Beautiful Soup¶
- Проблемы после установки¶
- Установка парсера¶
Beautiful Soup — Installation
As BeautifulSoup is not a standard python library, we need to install it first. We are going to install the BeautifulSoup 4 library (also known as BS4), which is the latest one.
To isolate our working environment so as not to disturb the existing setup, let us first create a virtual environment.
Creating a virtual environment (optional)
A virtual environment allows us to create an isolated working copy of python for a specific project without affecting the outside setup.
Best way to install any python package machine is using pip, however, if pip is not installed already (you can check it using – “pip –version” in your command or shell prompt), you can install by giving below command −
Linux environment
Windows environment
To install pip in windows, do the following −
Download the get-pip.py from https://bootstrap.pypa.io/get-pip.py or from the github to your computer.
Open the command prompt and navigate to the folder containing get-pip.py file.
Run the following command −
That’s it, pip is now installed in your windows machine.
You can verify your pip installed by running below command −
Installing virtual environment
Run the below command in your command prompt −
After running, you will see the below screenshot −

Below command will create a virtual environment (“myEnv”) in your current directory −
Screenshot
To activate your virtual environment, run the following command −

In the above screenshot, you can see we have “myEnv” as prefix which tells us that we are under virtual environment “myEnv”.
To come out of virtual environment, run deactivate.
As our virtual environment is ready, now let us install beautifulsoup.
Installing BeautifulSoup
As BeautifulSoup is not a standard library, we need to install it. We are going to use the BeautifulSoup 4 package (known as bs4).
Linux Machine
To install bs4 on Debian or Ubuntu linux using system package manager, run the below command −
You can install bs4 using easy_install or pip (in case you find problem in installing using system packager).
(You may need to use easy_install3 or pip3 respectively if you’re using python3)
Windows Machine
To install beautifulsoup4 in windows is very simple, especially if you have pip already installed.
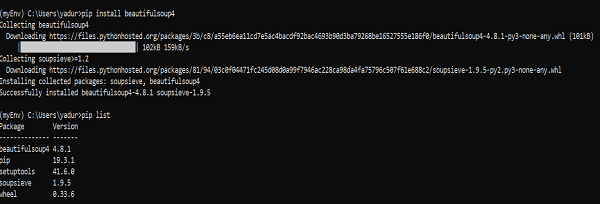
So now beautifulsoup4 is installed in our machine. Let us talk about some problems encountered after installation.
Problems after installation
On windows machine you might encounter, wrong version being installed error mainly through −
error: ImportError “No module named HTMLParser”, then you must be running python 2 version of the code under Python 3.
error: ImportError “No module named html.parser” error, then you must be running Python 3 version of the code under Python 2.
Best way to get out of above two situations is to re-install the BeautifulSoup again, completely removing existing installation.
If you get the SyntaxError “Invalid syntax” on the line ROOT_TAG_NAME = u’[document]’, then you need to convert the python 2 code to python 3, just by either installing the package −
or by manually running python’s 2 to 3 conversion script on the bs4 directory −
Installing a Parser
By default, Beautiful Soup supports the HTML parser included in Python’s standard library, however it also supports many external third party python parsers like lxml parser or html5lib parser.
To install lxml or html5lib parser, use the command −
Linux Machine
Windows Machine
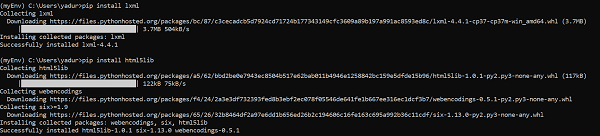
Generally, users use lxml for speed and it is recommended to use lxml or html5lib parser if you are using older version of python 2 (before 2.7.3 version) or python 3 (before 3.2.2) as python’s built-in HTML parser is not very good in handling older version.
Running Beautiful Soup
It is time to test our Beautiful Soup package in one of the html pages (taking web page – https://www.tutorialspoint.com/index.htm, you can choose any-other web page you want) and extract some information from it.
In the below code, we are trying to extract the title from the webpage −
Output
One common task is to extract all the URLs within a webpage. For that we just need to add the below line of code −
Output
Similarly, we can extract useful information using beautifulsoup4.
Now let us understand more about “soup” in above example.
Источник
Модуль BeautifulSoup4 в Python, разбор HTML.
Извлечение данных из документов HTML и XML.
BeautifulSoup4 (bs4) — это библиотека Python для извлечения данных из файлов HTML и XML. Для естественной навигации, поиска и изменения дерева HTML, модуль BeautifulSoup4, по умолчанию использует встроенный в Python парсер | html.parser |. BS4 так же поддерживает ряд сторонних парсеров Python, таких как lxml , html5lib и xml (для разбора XML-документов).
Установка BeautifulSoup4 в виртуальное окружение:
Содержание:
Выбор парсера для использования в BeautifulSoup4.
BeautifulSoup4 представляет один интерфейс для разных парсеров, но парсеры неодинаковы. Разные парсеры, анализируя один и того же документ создадут различные деревья HTML. Самые большие различия будут между парсерами HTML и XML. Так же парсеры различаются скоростью разбора HTML документа.
Если дать BeautifulSoup4 идеально оформленный документ HTML, то различий построенного HTML-дерева не будет. Один парсер будет быстрее другого, но все они будут давать структуру, которая выглядит точно так же, как оригинальный документ HTML. Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Различия в построении HTML-дерева разными парсерами, разберем на короткой HTML-разметке:
Парсер lxml .
- Для запуска примера, необходимо установить модуль lxml .
- Очень быстрый, имеет внешнюю зависимость от языка C.
- Нестрогий.
Парсер html5lib .
- Для запуска примера, необходимо установить модуль html5lib .
- Ну очень медленный.
- Разбирает страницы так же, как это делает браузер, создавая валидный HTML5.
Обратите внимание, что парсер html5lib НЕ игнорирует висячий тег
, и к тому же добавляет открывающий тег
. Также html5lib добавляет пустой тег ( lxml этого не сделал).
Встроенный в Python парсер html.parser .
- Не требует дополнительной установки.
- Приличная скорость, но не такой быстрый, как lxml .
- Более строгий, чем html5lib .
Как и lxml , встроенный в Python парсер игнорирует закрывающий тег
. В отличие от html5lib , этот парсер не делает попытки создать правильно оформленный HTML-документ, добавив теги или .
Вывод: Парсер html5lib использует способы, которые являются частью стандарта HTML5, поэтому он может претендовать на то, что его подход самый «правильный«.
Основные приемы работы с BeautifulSoup4.
Чтобы разобрать HTML-документ, необходимо передать его в конструктор класса BeautifulSoup() . Можно передать строку или открытый дескриптор файла:
Первым делом документ конвертируется в Unicode, а HTML-мнемоники конвертируются в символы Unicode:
Дальнейшие примеры будут разбираться на следующей HTML-разметке.
Передача этого HTML-документа в конструктор класса BeautifulSoup() создает объект, который представляет документ в виде вложенной структуры:
Навигация по структуре HTML-документа:
Перемещаться по одному уровню можно при помощи атрибутов .previous_sibling и .next_sibling . Например, в представленном выше HTML, теги обернуты в тег
— следовательно они находятся на одном уровне.
Так же можно перебрать одноуровневые элементы данного тега с помощью .next_siblings или .previous_siblings .
Атрибут .next_element строки или HTML-тега указывает на то, что было разобрано непосредственно после него. Это могло бы быть тем же, что и .next_sibling , но обычно результат резко отличается.
Это потому, что в оригинальной разметке слово Tillie появилось перед точкой с запятой. Парсер обнаружил тег , затем слово Tillie, затем закрывающий тег , затем точку с запятой и оставшуюся часть предложения. Точка с запятой находится на том же уровне, что и тег , но слово Tillie встретилось первым.
Атрибут .previous_element является полной противоположностью .next_element . Он указывает на элемент, который был обнаружен при разборе непосредственно перед текущим:
При помощи атрибутов .next_elements и .previous_elements можно получить список элементов, в том порядке, в каком он был разобран парсером.
Извлечение URL-адресов.
Одна из распространенных задач, это извлечение URL-адресов, найденных на странице в HTML-тегах :
Извлечение текста HTML-страницы.
Другая распространенная задача — извлечь весь текст со HTML-страницы:
Поиск тегов по HTML-документу:
Найти первый совпавший HTML-тег можно методом BeautifulSoup.find() , а всех совпавших элементов — BeautifulSoup.find_all() .
Поиск тегов при помощи CSS селекторов:
Поиск тега под другими тегами:
Поиск тега непосредственно под другими тегами:
Поиск одноуровневых элементов:
Поиск тега по классу CSS:
Поиск тега по ID:
Дочерние элементы.
Извлечение НЕПОСРЕДСТВЕННЫХ дочерних элементов тега. Если посмотреть на HTML-разметку в коде ниже, то, непосредственными дочерними элементами первого
- будут являться три тега
и тег
- со всеми вложенными тегами.
Обратите внимание, что все переводы строк \n и пробелы между тегами, так же будут считаться дочерними элементами. Так что имеет смысл заранее привести исходный HTML к «нормальному виду«, например так: re.sub(r’>\s+
Извлечение ВСЕХ дочерних элементов. Эта операция похожа на рекурсивный обход HTML-дерева в глубину от выбранного тега.
Обратите внимание, что простой текст, который находится внутри тега, так же считается дочерним элементом этого тега.
Если внутри тега есть более одного дочернего элемента (как в примерен выше) и необходимо извлечь только текст, то можно использовать атрибут .strings или генератор .stripped_strings .
Генератор .stripped_strings дополнительно удаляет все переводы строк \n и пробелы между тегами в исходном HTML-документе.
Родительские элементы.
Что бы получить доступ к родительскому элементу, необходимо использовать атрибут .parent .
Taк же можно перебрать всех родителей элемента с помощью атрибута .parents .
Источник
Документация Beautiful Soup¶

Beautiful Soup — это библиотека Python для извлечения данных из файлов HTML и XML. Она работает с вашим любимым парсером, чтобы дать вам естественные способы навигации, поиска и изменения дерева разбора. Она обычно экономит программистам часы и дни работы.
Эти инструкции иллюстрируют все основные функции Beautiful Soup 4 на примерах. Я покажу вам, для чего нужна библиотека, как она работает, как ее использовать, как заставить ее делать то, что вы хотите, и что нужно делать, когда она не оправдывает ваши ожидания.
Эта документация относится к Beautiful Soup версии 4.9.2. Примеры в документации работают одинаково на Python 2.7 и Python 3.8.
Возможно, вы ищете документацию для Beautiful Soup 3. Если это так, имейте в виду, что Beautiful Soup 3 больше не развивается, и что поддержка этой версии будет прекращена 31 декабря 2020 года или немногим позже. Если вы хотите узнать о различиях между Beautiful Soup 3 и Beautiful Soup 4, читайте раздел Перенос кода на BS4.
Эта документация переведена на другие языки пользователями Beautiful Soup:
Техническая поддержка¶
Если у вас есть вопросы о Beautiful Soup или возникли проблемы, отправьте сообщение в дискуссионную группу. Если ваша проблема связана с разбором HTML-документа, не забудьте упомянуть, что говорит о нем функция diagnose() .
Быстрый старт¶
Вот HTML-документ, который я буду использовать в качестве примера в этой документации. Это фрагмент из «Алисы в стране чудес» :
Прогон документа через Beautiful Soup дает нам объект BeautifulSoup , который представляет документ в виде вложенной структуры данных:
Вот несколько простых способов навигации по этой структуре данных:
Одна из распространенных задач — извлечь все URL-адреса, найденные на странице в тегах :
Другая распространенная задача — извлечь весь текст со страницы:
Это похоже на то, что вам нужно? Если да, продолжайте читать.
Установка Beautiful Soup¶
Если вы используете последнюю версию Debian или Ubuntu Linux, вы можете установить Beautiful Soup с помощью системы управления пакетами:
$ apt — get install python — bs4 (для Python 2)
$ apt — get install python3 — bs4 (для Python 3)
Beautiful Soup 4 публикуется через PyPi, поэтому, если вы не можете установить библиотеку с помощью системы управления пакетами, можно установить с помощью easy_install или pip . Пакет называется beautifulsoup4 . Один и тот же пакет работает как на Python 2, так и на Python 3. Убедитесь, что вы используете версию pip или easy_install , предназначенную для вашей версии Python (их можно назвать pip3 и easy_install3 соответственно, если вы используете Python 3).
$ pip install beautifulsoup4
( BeautifulSoup — это не тот пакет, который вам нужен. Это предыдущий основной релиз, Beautiful Soup 3. Многие программы используют BS3, так что он все еще доступен, но если вы пишете новый код, нужно установить beautifulsoup4 .)
Если у вас не установлены easy_install или pip , вы можете скачать архив с исходным кодом Beautiful Soup 4 и установить его с помощью setup.py .
$ python setup.py install
Если ничего не помогает, лицензия на Beautiful Soup позволяет упаковать библиотеку целиком вместе с вашим приложением. Вы можете скачать tar-архив, скопировать из него в кодовую базу вашего приложения каталог bs4 и использовать Beautiful Soup, не устанавливая его вообще.
Я использую Python 2.7 и Python 3.8 для разработки Beautiful Soup, но библиотека должна работать и с более поздними версиями Python.
Проблемы после установки¶
Beautiful Soup упакован как код Python 2. Когда вы устанавливаете его для использования с Python 3, он автоматически конвертируется в код Python 3. Если вы не устанавливаете библиотеку в виде пакета, код не будет сконвертирован. Были также сообщения об установке неправильной версии на компьютерах с Windows.
Если выводится сообщение ImportError «No module named HTMLParser», ваша проблема в том, что вы используете версию кода на Python 2, работая на Python 3.
Если выводится сообщение ImportError «No module named html.parser», ваша проблема в том, что вы используете версию кода на Python 3, работая на Python 2.
В обоих случаях лучше всего полностью удалить Beautiful Soup с вашей системы (включая любой каталог, созданный при распаковке tar-архива) и запустить установку еще раз.
Если выводится сообщение SyntaxError «Invalid syntax» в строке ROOT_TAG_NAME = u'[document]’ , вам нужно конвертировать код из Python 2 в Python 3. Вы можете установить пакет:
$ python3 setup.py install
или запустить вручную Python-скрипт 2to3 в каталоге bs4 :
$ 2to3 — 3.2 — w bs4
Установка парсера¶
Beautiful Soup поддерживает парсер HTML, включенный в стандартную библиотеку Python, а также ряд сторонних парсеров на Python. Одним из них является парсер lxml. В зависимости от ваших настроек, вы можете установить lxml с помощью одной из следующих команд:
$ apt — get install python — lxml
$ pip install lxml
Другая альтернатива — написанный исключительно на Python парсер html5lib, который разбирает HTML таким же образом, как это делает веб-браузер. В зависимости от ваших настроек, вы можете установить html5lib с помощью одной из этих команд:
$ apt — get install python — html5lib
$ pip install html5lib
Эта таблица суммирует преимущества и недостатки каждого парсера:
Источник



