- Как установить юпитер ноутбук windows 10
- Getting started with JupyterLab
- Install with conda
- Install with pip
- Run JupyterLab
- Getting started with the classic Jupyter Notebook
- conda
- Getting started with Voilà
- Installation
- conda
- Как установить юпитер ноутбук windows 10
- Руководство по Jupyter Notebook для начинающих
- Настройка Jupyter Notebook
- Основы Jupyter Notebook
- Добавление описания к notebook
- Интерактивная наука о данных
- Подписывайтесь на канал в Дзене
- Установка Jupyter Notebook на компьютере и подключение к Apache Spark в HDInsight Install Jupyter Notebook on your computer and connect to Apache Spark on HDInsight
- Предварительные требования Prerequisites
- Установка Jupyter Notebook на компьютере Install Jupyter Notebook on your computer
- Установка программы Spark Magic Install Spark magic
- Установка ядер PySpark и Spark Install PySpark and Spark kernels
- Настройка волшебной команды Spark для подключения к кластеру HDInsight Spark Configure Spark magic to connect to HDInsight Spark cluster
- Зачем устанавливать Jupyter на моем компьютере? Why should I install Jupyter on my computer?
Как установить юпитер ноутбук windows 10
Get up and running with the JupyterLab or the classic Jupyter Notebook on your computer within minutes!
Getting started with JupyterLab
The installation guide contains more detailed instructions
Install with conda
If you use conda , you can install it with:
Install with pip
If you use pip , you can install it with:
If installing using pip install —user , you must add the user-level bin directory to your PATH environment variable in order to launch jupyter lab . If you are using a Unix derivative (FreeBSD, GNU / Linux, OS X), you can achieve this by using export PATH=»$HOME/.local/bin:$PATH» command.
Run JupyterLab
Once installed, launch JupyterLab with:
Getting started with the classic Jupyter Notebook
conda
We recommend installing the classic Jupyter Notebook using the conda package manager. Either the miniconda or the miniforge conda distributions include a minimal conda installation.
Then you can install the notebook with:
If you use pip , you can install it with:
Congratulations, you have installed Jupyter Notebook! To run the notebook, run the following command at the Terminal (Mac/Linux) or Command Prompt (Windows):
Getting started with Voilà
Installation
Voilà can be installed using conda or pip . For more detailed instructions, consult the installation guide.
conda
If you use conda , you can install it with:
If you use pip , you can install it with:
Copyright © 2021 Project Jupyter – Last updated Fri, Apr 02, 2021
Как установить юпитер ноутбук windows 10

Установка Python + Jupyter Notebook (название старой версии — Ipython Notebook):
Windows
1. Если у вас не установлен python3, скачайте дистрибутив с официального сайта. Внимание: нужно скачивать версию 3.4, так как версия 3.5 для 32-битных систем не поддерживается. Узнать разрядность системы можно через Система->Свойства.
2. При установке нужно обязательно поставить флажок «Add python.exe to PATH», чтобы путь к исполняемым командам python и pip был записан в переменной среды.
3. После установки откройте командную строку (перезагрузите, если она была открыта) и наберите команду «pip install jupyter».
Linux
1. Установите пакет python3 с помощью вашего пакетного менеджера (в Ubuntu — «sudo apt-get install python3».
2. Перезапустите bash и установите jupyter notebook через pip: «pip install jupyter».
OS X
1. Установите пакетный менеджер Homebrew (http://brew.sh).
2. Установите пакет python3: «brew install python3»
3. Установите jupyter через pip: «pip install jupyter».
Запуск Jupyter Notebook:
1. В командной строке перейдите в папку с файлом *.ipynb или в любую папку выше.
2. Наберите команду «jupyter notebook» (или «ipython notebook»): в браузере должна открыться новая вкладка с интерфейсом jupyter и списком файлов/папок. Выберите нужный или создайте новый — запустится новый jupyter notebook.
Руководство по Jupyter Notebook для начинающих


Jupyter Notebook — это мощный инструмент для разработки и представления проектов Data Science в интерактивном виде. Он объединяет код и вывод все в виде одного документа, содержащего текст, математические уравнения и визуализации.
Такой пошаговый подход обеспечивает быстрый, последовательный процесс разработки, поскольку вывод для каждого блока показывается сразу же. Именно поэтому инструмент стал настолько популярным в среде Data Science за последнее время. Большая часть Kaggle Kernels (работы участников конкурсов на платформе Kaggle) сегодня созданы с помощью Jupyter Notebook.
Этот материал предназначен для новичков, которые только знакомятся с Jupyter Notebook, и охватывает все этапы работы с ним: установку, азы использования и процесс создания интерактивного проекта Data Science.
Настройка Jupyter Notebook
Чтобы начать работать с Jupyter Notebook, библиотеку Jupyter необходимо установить для Python. Проще всего это сделать с помощью pip:
Лучше использовать pip3 , потому что pip2 работает с Python 2, поддержка которого прекратится уже 1 января 2020 года.
Теперь нужно разобраться с тем, как пользоваться библиотекой. С помощью команды cd в командной строке (в Linux и Mac) в первую очередь нужно переместиться в папку, в которой вы планируете работать. Затем запустите Jupyter с помощью следующей команды:
Это запустит сервер Jupyter, а браузер откроет новую вкладку со следующим URL: https://localhost:8888/tree. Она будет выглядеть приблизительно вот так:






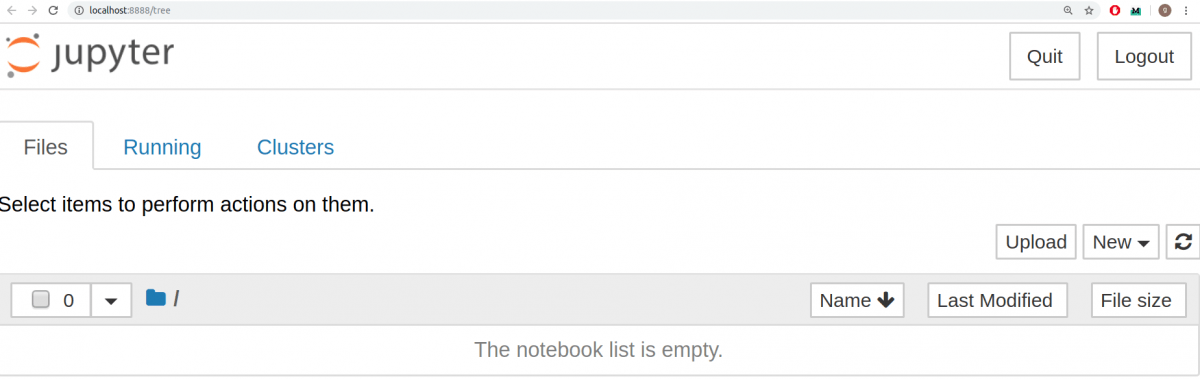
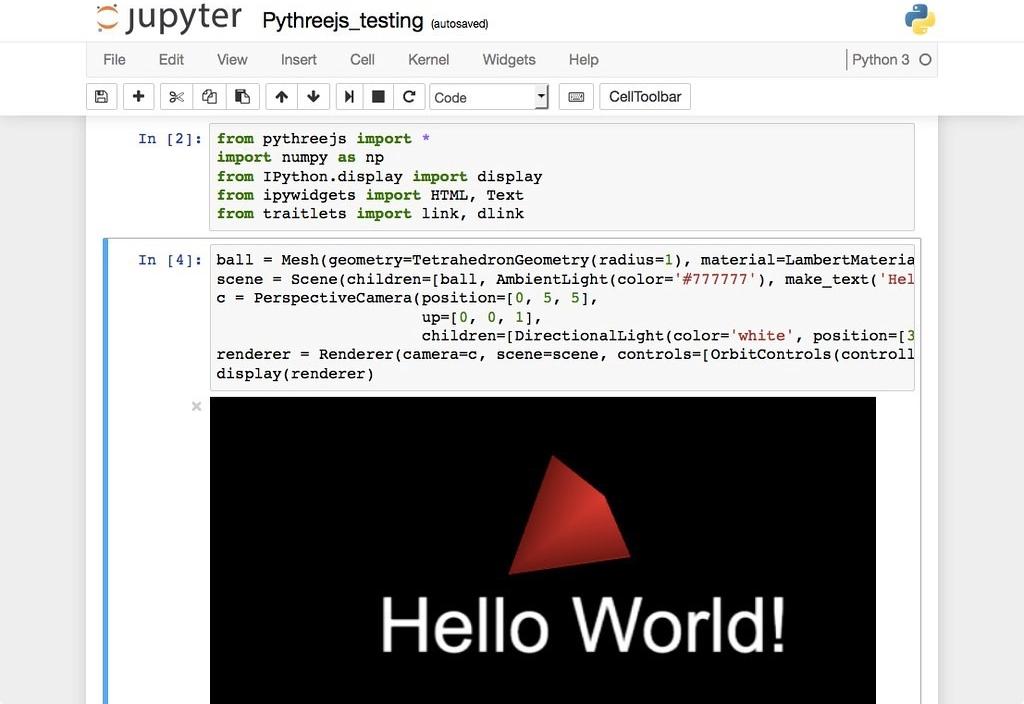
Отлично. Сервер Jupyter работает. Теперь пришло время создать первый notebook и заполнять его кодом.
Основы Jupyter Notebook
Для создания notebook выберите «New» в верхнем меню, а потом «Python 3». Теперь страница в браузере будет выглядеть вот так:
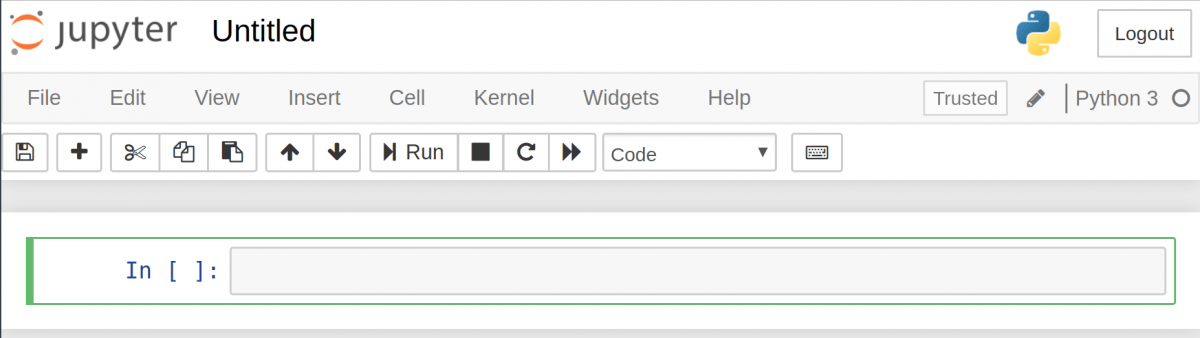
Обратите внимание на то, что в верхней части страницы, рядом с логотипом Jupyter, есть надпись Untitled — это название notebook. Его лучше поменять на что-то более понятное. Просто наведите мышью и кликните по тексту. Теперь можно выбрать новое название. Например, George’s Notebook .
Теперь напишем какой-нибудь код!
Перед первой строкой написано In [] . Это ключевое слово значит, что дальше будет ввод. Попробуйте написать простое выражение вывода. Не забывайте, что нужно пользоваться синтаксисом Python 3. После этого нажмите «Run».
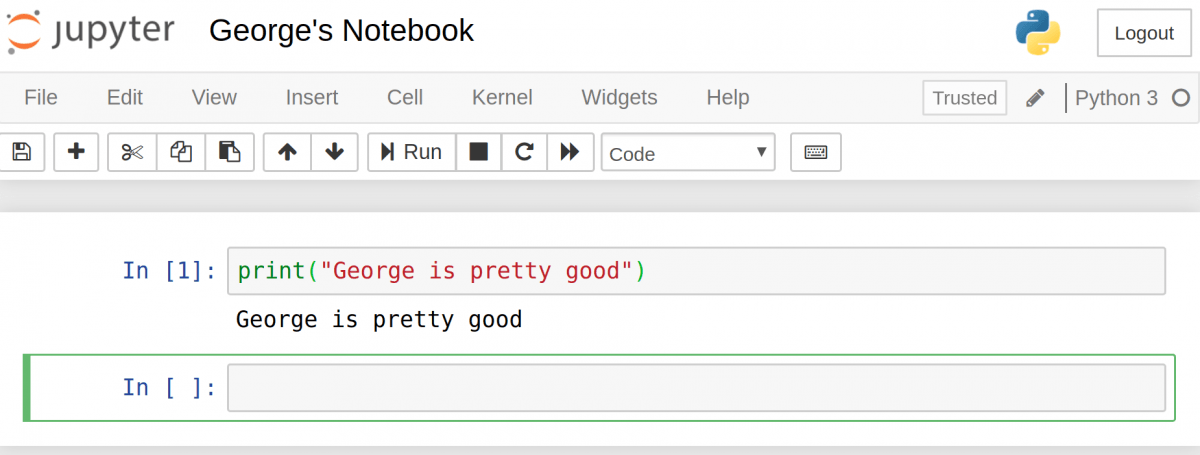
Вывод должен отобразиться прямо в notebook. Это и позволяет заниматься программированием в интерактивном формате, имея возможность отслеживать вывод каждого шага.
Также обратите внимание на то, что In [] изменилась и вместе нее теперь In [1] . Число в скобках означает порядок, в котором эта ячейка будет запущена. В первой цифра 1 , потому что она была первой запущенной ячейкой. Каждую ячейку можно запускать индивидуально и цифры в скобках будут менять соответственно.
Рассмотрим пример. Настроим 2 ячейки, в каждой из которых будет разное выражение print . Сперва запустим вторую, а потом первую. Можно увидеть, как в результате цифры в скобках меняются.
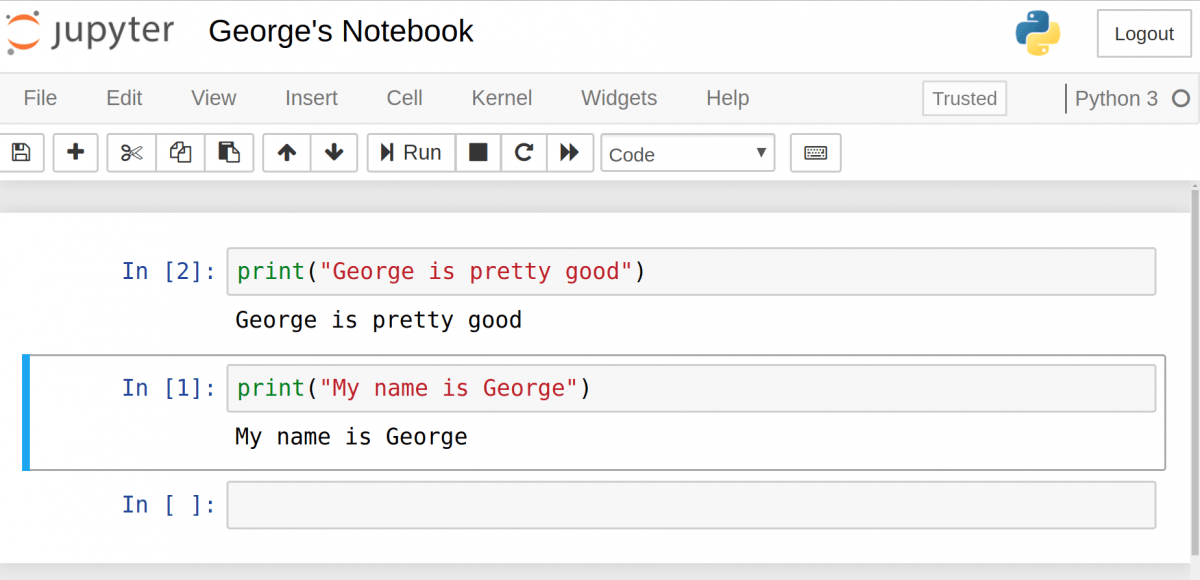







Если есть несколько ячеек, то между ними можно делиться переменными и импортами. Это позволяет проще разбивать весь код на связанные блоки, не создавая переменную каждый раз. Главное убедиться в запуске ячеек в правильном порядке, чтобы переменные не использовались до того, как были созданы.
Добавление описания к notebook
В Jupyter Notebook есть несколько инструментов, используемых для добавления описания. С их помощью можно не только оставлять комментарии, но также добавлять заголовки, списки и форматировать текст. Это делается с помощью Markdown.
Первым делом нужно поменять тип ячейки. Нажмите на выпадающее меню с текстом «Code» и выберите «Markdown». Это поменяет тип ячейки.
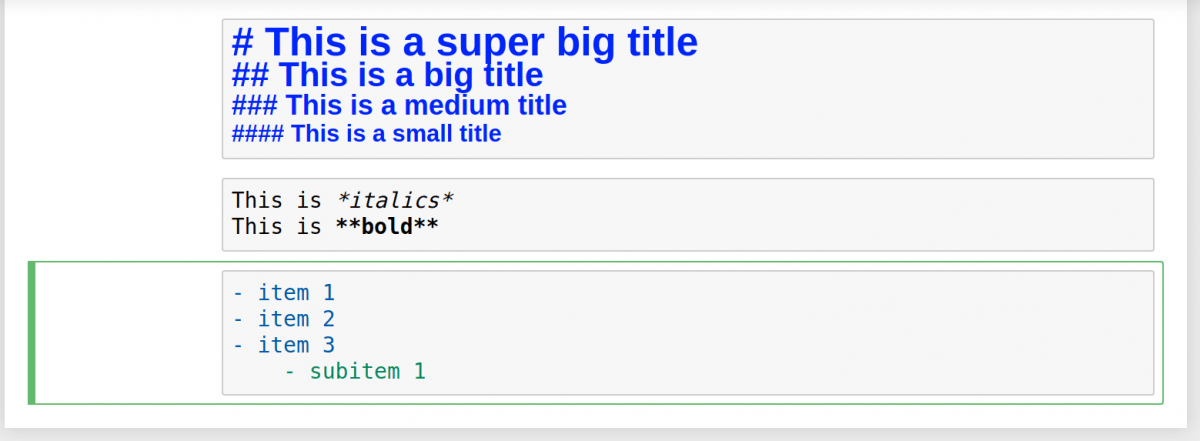
Попробуем несколько вариантов. Заголовки можно создавать с помощью символа # . Один такой символ создаст самый крупный заголовок верхнего уровня. Чем больше # , тем меньше будет текст.
Сделать текст курсивным можно с помощью символов * с двух сторон текста. Если с каждой стороны добавить по два * , то текст станет полужирным. Список создается с помощью тире и пробела для каждого пункта.
Интерактивная наука о данных
Соорудим простой пример проекта Data Science. Этот notebook и код взяты из реального проекта.
Начнем с ячейки Markdown с самым крупным текстом, который делается с помощью одного # . Затем список и описание всех библиотек, которые необходимо импортировать.
Следом идет первая ячейка, в которой происходит импорт библиотек. Это стандартный код для Python Data Science с одним исключение: чтобы прямо видеть визуализации Matplotlib в notebook, нужна следующая строчка: %matplotlib inline .

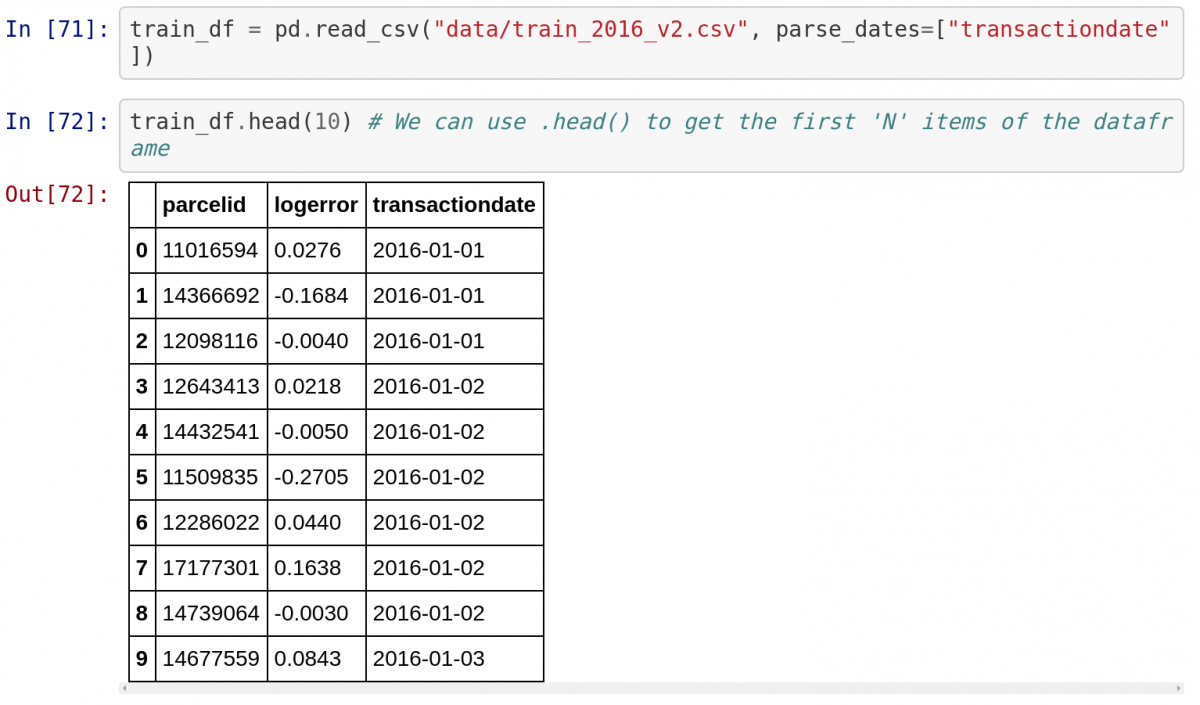
Следом нужно импортировать набор данных из файла CSV и вывести первые 10 пунктов. Обратите внимание, как Jupyter автоматически показывает вывод функции .head() в виде таблицы. Jupyter отлично работает с библиотекой Pandas!
Теперь нарисуем диаграмму прямо в notebook. Поскольку наверху есть строка %matplotlib inline , при написании plt.show() диаграмма будет выводиться в notebook!
Также обратите внимание на то, как переменные из предыдущих ячеек, содержащие данные из CSV-файла, используются в последующих ячейках в том случае, если по отношению к первым была нажата кнопка «Run».
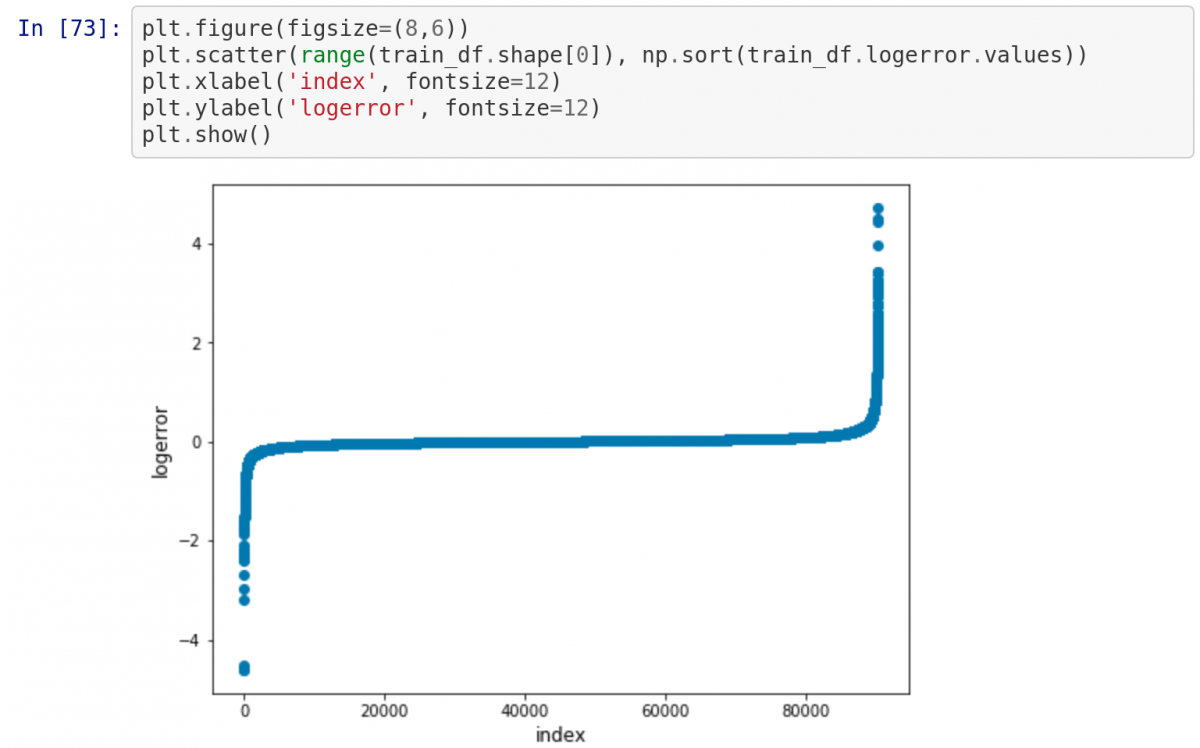
Это простейший способ создания интерактивного проекта Data Science!
На сервере Jupyter есть несколько меню, с помощью которых от проекта можно получить максимум. С их помощью можно взаимодействовать с notebook, читать документацию популярных библиотек Python и экспортировать проект для последующей демонстрации.
Файл (File): отвечает за создание, копирование, переименование и сохранение notebook в файл. Самый важный пункт в этом разделе — выпадающее меню Download , с помощью которого можно скачать notebook в разных форматах, включая pdf, html и slides для презентаций.
Редактировать (Edit): используется, чтобы вырезать, копировать и вставлять код. Здесь же можно поменять порядок ячеек, что понадобится для демонстрации проекта.
Вид (View): здесь можно настроить способ отображения номеров строк и панель инструментов. Самый примечательный пункт — Cell Toolbar , к каждой ячейке можно добавлять теги, заметки и другие приложения. Можно даже выбрать способ форматирования для ячейки, что потребуется для использования notebook в презентации.
Вставить (Insert): для добавления ячеек перед или после выбранной.
Ячейка (Cell): отсюда можно запускать ячейки в определенном порядке или менять их тип.
Помощь (Help): в этом разделе можно получить доступ к важной документации. Здесь же упоминаются горячие клавиши для ускорения процесса работы. Наконец, тут можно найти ссылки на документацию для самых важных библиотек Python: Numpy, Scipy, Matplotlib и Pandas.
Подписывайтесь на канал в Дзене
Полезный контент для начинающих и опытных программистов в канале Лента Python разработчика — Как успевать больше, делать лучше и не потерять мотивацию.
Установка Jupyter Notebook на компьютере и подключение к Apache Spark в HDInsight Install Jupyter Notebook on your computer and connect to Apache Spark on HDInsight
Из этой статьи вы узнаете, как установить Jupyter Notebook с ядром PySpark (для Python) и Apache Spark (для Scala) с помощью программы Spark Magic. In this article, you learn how to install Jupyter Notebook with the custom PySpark (for Python) and Apache Spark (for Scala) kernels with Spark magic. Затем вы подключаете записную книжку к кластеру HDInsight. You then connect the notebook to an HDInsight cluster.
При установке Jupyter и подключении к Apache Spark в HDInsight необходимо выполнить четыре основных шага. There are four key steps involved in installing Jupyter and connecting to Apache Spark on HDInsight.
- Настройка кластера Spark. Configure Spark cluster.
- Установите Jupyter Notebook. Install Jupyter Notebook.
- Установите ядра PySpark и Spark с помощью волшебной команды Spark. Install the PySpark and Spark kernels with the Spark magic.
- Настройте волшебную команду Spark для доступа к кластеру Spark в HDInsight. Configure Spark magic to access Spark cluster on HDInsight.
Дополнительные сведения о пользовательских ядрах и волшебе Spark см. в разделе ядра, доступные для записных книжек Jupyter с кластерами Apache Spark Linux в HDInsight. For more information about custom kernels and Spark magic, see Kernels available for Jupyter Notebooks with Apache Spark Linux clusters on HDInsight.
Предварительные требования Prerequisites
Кластер Apache Spark в HDInsight. An Apache Spark cluster on HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark. For instructions, see Create Apache Spark clusters in Azure HDInsight. Локальная Записная книжка подключается к кластеру HDInsight. The local notebook connects to the HDInsight cluster.
Опыт работы с записными книжками Jupyter с Spark в HDInsight. Familiarity with using Jupyter Notebooks with Spark on HDInsight.
Установка Jupyter Notebook на компьютере Install Jupyter Notebook on your computer
Установите Python перед установкой записных книжек Jupyter. Install Python before you install Jupyter Notebooks. В дистрибутиве Anaconda будут установлены оба, Python и Jupyter Notebook. The Anaconda distribution will install both, Python, and Jupyter Notebook.
Скачайте установщик Anaconda для своей платформы и запустите программу установки. Download the Anaconda installer for your platform and run the setup. В мастере установки укажите параметр для добавления Anaconda в переменную PATH. While running the setup wizard, make sure you select the option to add Anaconda to your PATH variable. См. также Установка Jupyter с помощью Anaconda. See also, Installing Jupyter using Anaconda.
Установка программы Spark Magic Install Spark magic
Введите команду pip install sparkmagic==0.13.1 для установки программы Spark Magic для кластеров HDInsight версии 3,6 и 4,0. Enter the command pip install sparkmagic==0.13.1 to install Spark magic for HDInsight clusters version 3.6 and 4.0. См. также документацию по sparkmagic. See also, sparkmagic documentation.
Убедитесь, что ipywidgets установлен правильный параметр, выполнив следующую команду: Ensure ipywidgets is properly installed by running the following command:
Установка ядер PySpark и Spark Install PySpark and Spark kernels
Найдите место sparkmagic установки, введя следующую команду: Identify where sparkmagic is installed by entering the following command:
Затем измените рабочий каталог на Расположение , указанное в приведенной выше команде. Then change your working directory to the location identified with the above command.
В новом рабочем каталоге введите одну или несколько приведенных ниже команд, чтобы установить требуемые ядра. From your new working directory, enter one or more of the commands below to install the wanted kernel(s):
| Ядро Kernel | Get-Help Command |
|---|---|
| Spark Spark | jupyter-kernelspec install sparkmagic/kernels/sparkkernel |
| SparkR SparkR | jupyter-kernelspec install sparkmagic/kernels/sparkrkernel |
| PySpark PySpark | jupyter-kernelspec install sparkmagic/kernels/pysparkkernel |
| PySpark3 PySpark3 | jupyter-kernelspec install sparkmagic/kernels/pyspark3kernel |
Необязательный параметр. Optional. Введите следующую команду, чтобы включить расширение сервера: Enter the command below to enable the server extension:
Настройка волшебной команды Spark для подключения к кластеру HDInsight Spark Configure Spark magic to connect to HDInsight Spark cluster
В этом разделе вы настроите магическое значение Spark, установленное ранее, для подключения к кластеру Apache Spark. In this section, you configure the Spark magic that you installed earlier to connect to an Apache Spark cluster.
Запустите оболочку Python с помощью следующей команды: Start the Python shell with the following command:
Сведения о конфигурации Jupyter обычно хранятся в домашнем каталоге пользователей. The Jupyter configuration information is typically stored in the users home directory. Введите следующую команду, чтобы указать домашний каталог, и создайте папку с именем . sparkmagic. Enter the following command to identify the home directory, and create a folder called .sparkmagic. Будет выведен полный путь. The full path will be outputted.
В папке .sparkmagic Создайте файл с именем config.js и добавьте в него следующий фрагмент JSON. Within the folder .sparkmagic , create a file called config.json and add the following JSON snippet inside it.
Внесите следующие изменения в файл: Make the following edits to the file:
| Значение шаблона Template value | Новое значение New value |
|---|---|
| ИМЕН | Имя входа кластера, по умолчанию — admin . Cluster login, default is admin . |
| CLUSTERDNSNAME | Имя кластера Cluster name |
| Пароль в кодировке Base64 для фактического пароля. A base64 encoded password for your actual password. Пароль для base64 можно создать по адресу https://www.url-encode-decode.com/base64-encode-decode/ . You can generate a base64 password at https://www.url-encode-decode.com/base64-encode-decode/. | |
| «livy_server_heartbeat_timeout_seconds»: 60 | При использовании sparkmagic 0.12.7 (кластеры версии 3.5 и 3.6) не заключайте. Keep if using sparkmagic 0.12.7 (clusters v3.5 and v3.6). При использовании sparkmagic 0.2.3 (Clusters v 3.4) Замените на «should_heartbeat»: true . If using sparkmagic 0.2.3 (clusters v3.4), replace with «should_heartbeat»: true . |
Полный пример файла можно просмотреть в образце config.jsвразделе. You can see a full example file at sample config.json.
Сигналы пульса отправляются, чтобы предотвратить утечку сеансов. Heartbeats are sent to ensure that sessions are not leaked. При переходе в спящий режим или завершении работы компьютера пульс не отправляется, что приводит к очистке сеанса. When a computer goes to sleep or is shut down, the heartbeat is not sent, resulting in the session being cleaned up. Если вы хотите отключить такое поведение для кластеров версии 3.4, то можете настроить для параметра Livy livy.server.interactive.heartbeat.timeout значение 0 с помощью пользовательского интерфейса Ambari. For clusters v3.4, if you wish to disable this behavior, you can set the Livy config livy.server.interactive.heartbeat.timeout to 0 from the Ambari UI. Если для кластеров версии 3.5 не настроить соответствующую конфигурацию, приведенную выше, то сеанс не будет удален. For clusters v3.5, if you do not set the 3.5 configuration above, the session will not be deleted.
Запустите Jupyter. Start Jupyter. Выполните следующую команду из командной строки. Use the following command from the command prompt.
Убедитесь, что вы можете использовать магическую платформу Spark, доступную в ядрах. Verify that you can use the Spark magic available with the kernels. Выполните следующие шаги. Complete the following steps.
а. a. Создайте новую записную книжку. Create a new notebook. В правом углу выберите создать. From the right-hand corner, select New. Вы должны увидеть ядро по умолчанию Python 2 или Python 3 и установленные ядра. You should see the default kernel Python 2 or Python 3 and the kernels you installed. Фактические значения могут различаться в зависимости от выбранных вариантов установки. The actual values may vary depending on your installation choices. Выберите PySpark. Select PySpark.

После выбора нового проверьте оболочку на наличие ошибок. After selecting New review your shell for any errors. Если отображается сообщение об ошибке, TypeError: __init__() got an unexpected keyword argument ‘io_loop’ возможно, возникла известная проблема с определенными версиями Торнадо. If you see the error TypeError: __init__() got an unexpected keyword argument ‘io_loop’ you may be experiencing a known issue with certain versions of Tornado. Если это так, завершите работу ядра, а затем понизить установку торнадо, выполнив следующую команду: pip install tornado==4.5.3 . If so, stop the kernel and then downgrade your Tornado installation with the following command: pip install tornado==4.5.3 .
b. b. Запустите следующий фрагмент кода. Run the following code snippet.
Если вы успешно получили выходные данные, подключение к кластеру HDInsight работает. If you can successfully retrieve the output, your connection to the HDInsight cluster is tested.
Если вы хотите обновить конфигурацию записной книжки для подключения к другому кластеру, обновите config.jsс новым набором значений, как показано на шаге 3 выше. If you want to update the notebook configuration to connect to a different cluster, update the config.json with the new set of values, as shown in Step 3, above.
Зачем устанавливать Jupyter на моем компьютере? Why should I install Jupyter on my computer?
Причины для установки Jupyter на компьютере и последующего подключения к кластеру Apache Spark в HDInsight: Reasons to install Jupyter on your computer and then connect it to an Apache Spark cluster on HDInsight:
- Предоставляет возможность создавать записные книжки локально, тестировать приложение в работающем кластере, а затем отправлять в кластер записные книжки. Provides you the option to create your notebooks locally, test your application against a running cluster, and then upload the notebooks to the cluster. Чтобы отправить записные книжки в кластер, можно отправить их с помощью Jupyter Notebook, выполняющегося или в кластере, или сохранить их в /HdiNotebooks папке в учетной записи хранения, связанной с кластером. To upload the notebooks to the cluster, you can either upload them using the Jupyter Notebook that is running or the cluster, or save them to the /HdiNotebooks folder in the storage account associated with the cluster. Дополнительные сведения о хранении записных книжек в кластере см. в разделе где хранятся записные книжки Jupyter? For more information on how notebooks are stored on the cluster, see Where are Jupyter Notebooks stored?
- С помощью локально доступных записных книжек вы сможете подключиться к различным кластерам Spark в зависимости от потребностей вашего приложения. With the notebooks available locally, you can connect to different Spark clusters based on your application requirement.
- Можно использовать GitHub для реализации системы управления версиями, чтобы контролировать версии записных книжек. You can use GitHub to implement a source control system and have version control for the notebooks. Вы также можете создать среду совместной работы, в которой несколько пользователей будут работать с одной записной книжкой. You can also have a collaborative environment where multiple users can work with the same notebook.
- Вы можете работать с записными книжками локально даже без кластера. You can work with notebooks locally without even having a cluster up. Кластер нужен только для тестирования записных книжек, но не обязателен для ручного управления записными книжками или средой разработки. You only need a cluster to test your notebooks against, not to manually manage your notebooks or a development environment.
- Настройка локальной среды разработки может быть проще, чем настройка установки Jupyter в кластере. It may be easier to configure your own local development environment than it’s to configure the Jupyter installation on the cluster. Вы можете воспользоваться всеми преимуществами программного обеспечения, установленными локально, без настройки одного или нескольких удаленных кластеров. You can take advantage of all the software you’ve installed locally without configuring one or more remote clusters.
Если Jupyter установлен на локальном компьютере, несколько пользователей могут одновременно запустить одну и ту же записную книжку в одном кластере Spark. With Jupyter installed on your local computer, multiple users can run the same notebook on the same Spark cluster at the same time. В такой ситуации создаются несколько сеансов Livy. In such a situation, multiple Livy sessions are created. Если вы столкнетесь с проблемами и начнете их отладку, вам будет сложно определить, какой сеанс Livy какому пользователю принадлежит. If you run into an issue and want to debug that, it will be a complex task to track which Livy session belongs to which user.



