- Работа с mdadm в Linux для организации RAID
- Установка mdadm
- Сборка RAID
- Подготовка носителей
- Создание рейда
- Создание файла mdadm.conf
- Создание файловой системы и монтирование массива
- Информация о RAID
- Восстановление RAID на Linux
- Восстановление работы (rebuild) дисковых разделов по одному после единичного легкого сбоя
- Программный RAID-6 под Linux: опыт восстановления массива 16Тб
Работа с mdadm в Linux для организации RAID
mdadm — утилита для работы с программными RAID-массивами различных уровней. В данной инструкции рассмотрим примеры ее использования.
Установка mdadm
Утилита mdadm может быть установлена одной командой.
Если используем CentOS / Red Hat:
yum install mdadm
Если используем Ubuntu / Debian:
apt-get install mdadm
Сборка RAID
Перед сборкой, стоит подготовить наши носители. Затем можно приступать к созданию рейд-массива.
Подготовка носителей
Сначала необходимо занулить суперблоки на дисках, которые мы будем использовать для построения RAID (если диски ранее использовались, их суперблоки могут содержать служебную информацию о других RAID):
mdadm —zero-superblock —force /dev/sd
* в данном примере мы зануляем суперблоки для дисков sdb и sdc.
Если мы получили ответ:
mdadm: Unrecognised md component device — /dev/sdb
mdadm: Unrecognised md component device — /dev/sdc
. то значит, что диски не использовались ранее для RAID. Просто продолжаем настройку.
Далее нужно удалить старые метаданные и подпись на дисках:
wipefs —all —force /dev/sd
Создание рейда
Для сборки избыточного массива применяем следующую команду:
mdadm —create —verbose /dev/md0 -l 1 -n 2 /dev/sd
- /dev/md0 — устройство RAID, которое появится после сборки;
- -l 1 — уровень RAID;
- -n 2 — количество дисков, из которых собирается массив;
- /dev/sd — сборка выполняется из дисков sdb и sdc.
Мы должны увидеть что-то на подобие:
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store ‘/boot’ on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
—metadata=0.90
mdadm: size set to 1046528K
Также система задаст контрольный вопрос, хотим ли мы продолжить и создать RAID — нужно ответить y:
Continue creating array? y
Мы увидим что-то на подобие:
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
. и находим информацию о том, что у наших дисков sdb и sdc появился раздел md0, например:
.
sdb 8:16 0 2G 0 disk
??md0 9:0 0 2G 0 raid1
sdc 8:32 0 2G 0 disk
??md0 9:0 0 2G 0 raid1
.
* в примере мы видим собранный raid1 из дисков sdb и sdc.
Создание файла mdadm.conf
В файле mdadm.conf находится информация о RAID-массивах и компонентах, которые в них входят. Для его создания выполняем следующие команды:
echo «DEVICE partitions» > /etc/mdadm/mdadm.conf
mdadm —detail —scan —verbose | awk ‘/ARRAY/
DEVICE partitions
ARRAY /dev/md0 level=raid1 num-devices=2 metadata=1.2 name=proxy.dmosk.local:0 UUID=411f9848:0fae25f9:85736344:ff18e41d
* в данном примере хранится информация о массиве /dev/md0 — его уровень 1, он собирается из 2-х дисков.
Создание файловой системы и монтирование массива
Создание файловой системы для массива выполняется также, как для раздела:
* данной командой мы создаем на md0 файловую систему ext4.
Примонтировать раздел можно командой:
mount /dev/md0 /mnt
* в данном случае мы примонтировали наш массив в каталог /mnt.
Чтобы данный раздел также монтировался при загрузке системы, добавляем в fstab следующее:
/dev/md0 /mnt ext4 defaults 1 2
Для проверки правильности fstab, вводим:
Мы должны увидеть примонтированный раздел md, например:
/dev/md0 990M 2,6M 921M 1% /mnt
Информация о RAID
Посмотреть состояние всех RAID можно командой:
В ответ мы получим что-то на подобие:
md0 : active raid1 sdc[1] sdb[0]
1046528 blocks super 1.2 [2/2] [UU]
* где md0 — имя RAID устройства; raid1 sdc[1] sdb[0] — уровень избыточности и из каких дисков собран; 1046528 blocks — размер массива; [2/2] [UU] — количество юнитов, которые на данный момент используются.
** мы можем увидеть строку md0 : active(auto-read-only) — это означает, что после монтирования массива, он не использовался для записи.
Подробную информацию о конкретном массиве можно посмотреть командой:
* где /dev/md0 — имя RAID устройства.
Version : 1.2
Creation Time : Wed Mar 6 09:41:06 2019
Raid Level : raid1
Array Size : 1046528 (1022.00 MiB 1071.64 MB)
Used Dev Size : 1046528 (1022.00 MiB 1071.64 MB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Wed Mar 6 09:41:26 2019
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : proxy.dmosk.local:0 (local to host proxy.dmosk.local)
UUID : 304ad447:a04cda4a:90457d04:d9a4e884
Events : 17
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
- Version — версия метаданных.
- Creation Time — дата в время создания массива.
- Raid Level — уровень RAID.
- Array Size — объем дискового пространства для RAID.
- Used Dev Size — используемый объем для устройств. Для каждого уровня будет индивидуальный расчет: RAID1 — равен половине общего размера дисков, RAID5 — равен размеру, используемому для контроля четности.
- Raid Devices — количество используемых устройств для RAID.
- Total Devices — количество добавленных в RAID устройств.
- Update Time — дата и время последнего изменения массива.
- State — текущее состояние. clean — все в порядке.
- Active Devices — количество работающих в массиве устройств.
- Working Devices — количество добавленных в массив устройств в рабочем состоянии.
- Failed Devices — количество сбойных устройств.
- Spare Devices — количество запасных устройств.
- Consistency Policy — политика согласованности активного массива (при неожиданном сбое). По умолчанию используется resync — полная ресинхронизация после восстановления. Также могут быть bitmap, journal, ppl.
- Name — имя компьютера.
- UUID — идентификатор для массива.
- Events — количество событий обновления.
- Chunk Size (для RAID5) — размер блока в килобайтах, который пишется на разные диски.
Подробнее про каждый параметр можно прочитать в мануале для mdadm:
Также, информацию о разделах и дисковом пространстве массива можно посмотреть командой fdisk:
Источник
Восстановление RAID на Linux
Для управления программным RAID массивом в ОС Linux применяется программа mdadm.
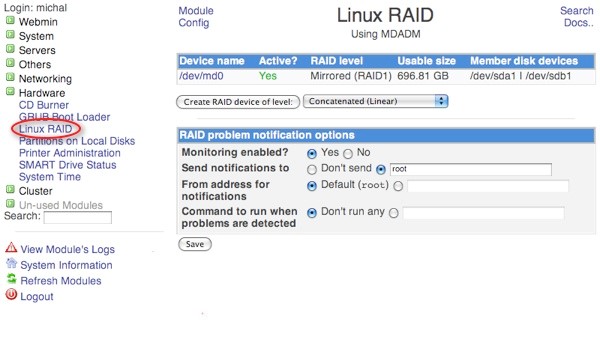
Рис. 1 – Интерфейс программы для управления массивами в ОС Linux
Для мониторинга состояния массива можно ввести следующие команды:
- # more /proc/mdstat – дает информацию обо всех массивах;
- # cat /proc/mdstat – альтернативный вариант;
- # watch -n .1 cat /proc/mdstat – альтернативный вариант.
Для получения сведений об определенном разделе диска следует набрать команду: # mdadm -E /dev/sd. Для mdadm восстановления массива потребуется выполнить цепочку несложных действий.
Восстановление работы (rebuild) дисковых разделов по одному после единичного легкого сбоя
Для восстановления разделов потребуется выполнить: # mdadm -a /dev/md /dev/sd. Следует соблюдать аккуратность с нумерацией разделов. Если была допущена ошибка, требуется удалить компонент из RAID с помощью команды: # mdadm -r /dev/md0 /dev/sdb1. Эта мера не всегда помогает, поскольку устройство может быть занято.
Для замены неисправного диска есть три шага:
- нужно выключить компьютер и произвести замену диска;
- включить компьютер и выявить разделы, имеющиеся на обоих дисках: # fdisk /dev/sd -l ;
- воспользовавшись fdisk, сформировать разделы на новом диске, которые эквивалентны оригиналу. Чтобы включить диск в зеркало, нужно пометить соответствующий его раздел (sda1 либо sda2) как загрузочный.
Далее нужно добавить диск в массив с помощью команд:
- # mdadm –manage /dev/md0 –add /dev/sda1;
- # mdadm –manage /dev/md1 –add /dev/sda5.
В результате начнется процесс синхронизации. Далее требуется произвести установку загрузчика на новый диск:
Неопытные пользователи не всегда способны разобраться во всех тонкостях процедуры восстановления данных. Поэтому целесообразнее будет доверить такую непростую работу в руки квалифицированных специалистов. Консультацию вы можете получить, набрав номер 8 (495) 280-18-99 .
Источник
Программный RAID-6 под Linux: опыт восстановления массива 16Тб
Несколько дней назад вышел из строя один из жестких дисков на бюджетном массиве из 16х1ТБ дисков. Уровень массива: RAID 6. Ситуация осложнилась тем, что (как оказалось) ранее также встал кулер на видеокарте этого же сервера, что не было заранее подмечено, и после замены HDD, в результате изменения режима охлаждения корпуса — это стало проявляться в виде зависаний во время синхронизации, что само по себе очень неприятно. Вылилось это в то, что массив перестал автособираться, и были помечены как сбойные еще несколько дисков, и пришлось уже разбираться с ним по-серьёзному, курить вики, мануалы и форумы (форумы — самое полезное, поскольку описывают опыт конкретных людей в конкретных ситуациях).
Структура моего массива:
разделы:
md0 — /root 8х1 Гб, RAID 6
md1 — /data: 16х999Гб, RAID 6
Сначала все эксперименты по сборке ставились на md0, т. е. на рутовой партиции, которая сама по себе большой ценностью не обладает, разве что тот факт что это настроенная система.
Итак я загрузился с 1-го диска Дебиан в режиме «Resque mode»
Попытка автосборки массива через
привела к выводу ошибки «недостаточно дисков для сборки массива».
Продолжаем по науке:
1. Необходимо сохранить информацию описания для массивов, которые содержат иформацию, какой конкретно диск является каким номером в массиве. На случай если придется собирать «опасными методами»:
Данные файлы содержат что-то похожее на приведенное ниже для всех HDD, у которых на партиции sdX1 есть суперблок (в моем случае только 8 из 16 для md0 имеют суперблок на sdX1)
Ниже пример вывода одного из разделов:
Кратко о том, что это означает:
sdf2 — текущая анализируемая партиция
Version 0.90.00 — Версия суперблока
Также вы увидите кучу полезной информации — размер массива, UUID, Level, Размер массива, Кол-во устройств и т. д.
Но самое важное для нас сейчас — это таблица внизу списка, первая строчка в ней, указывает, каким по счету HDD в массиве является наш экзаменуемый:
Также обратите пристальное внимание на версию суперблока! В моем случае это 0.90.00.
Тут мы видим его номер в массиве, т. е. 4 — такие же номера вы найдете в выводе для всех других устройств из списка. Обратите внимание, что буковка диска в строчке статуса другая — sdl1 — это означает, что диск был проинициализирован на другом SATA порту, затем перемещен. Это некритичная информация, но может быть полезной.
Критичным является название устройства и его номер в массиве (они поменяются при переносе устройств с порта на порт).
Сохраняем созданный файл raid_layout (например на флешке), чтобы не потерялся, и приступаем к следующему шагу:
2. Пытаемся собрать массив
Собрать массив можно 2мя способами: автоматический и ручной.
Если автоматически он собрался, считайте вам повезло, надо просто проверить все ли HDD в массиве, и если нет, добавить недостающие, и дальше можно не читать. Но, в моем случае, автоматическая сборка не проходит с ошибкой, что недостаточно работающих устройств:
и массив был создан на 4 из 8 дисков. Работать конечно не будет, поскольку Raid6 позволяет отсутствовать только 2-м дискам.
Проверяем статус массива
Тут есть тонкость — если в списке HDD встречается не проинициализированный или помеченный как сбойный, то сборка немедленно прекращается, поэтому полезен флаг «-v» — чтобы увидеть на каком из HDD сборка встала.
Тоже самое, но мы указали конкретно, какие HDD использовать для сборки.
Скорее всего массив не соберется также, как и в случае с автоматической сборкой. Но, собирая вручную, вы начинаете лучше понимать саму суть происходящего.
Массив также не соберется, если в метаданных раздела, диск помечен как «faulty».
Тут я перескакивая на то, как я запустил массив с данными, поскольку /root массив я потерял, почему и как — рассказано ниже. Собрать массив игнорируя статус «faulty» — можно добавив флаг «-f» (force) — в моем случае это решило проблему сборки основного раздела с данными т. е. раздел был успешно пересобран следующей командой:
наверняка, простой способ собрать его был бы следующим:
Но, поскольку я добрался до флага «-f» через тернии, это сейчас понятно.
Т. е. разделы, помеченные как сбойные, или устаревшие были добавлены в массив, а не проигнорированы. С большой вероятностью, сбойным или устаревшим раздел может быть помечен при плохо, или не плотно сидящем SATA кабеле, что является не редкостью.
Тем не менее, у меня получился массив в режиме degraded, на 14 дисков из 16.
Теперь, чтобы восстановить нормальную работоспособность массива и не бояться за него, нужно добавить в него 2 недостающих диска:
где Х буковка раздела нового HDD
Ниже я приведу сложности с которыми я столкнулся, дабы уберечь других, от наступания на мои грабли:
Я использовал рекомендации WIKI — Linux RAID Recovery ( raid.wiki.kernel.org/index.php/RAID_Recovery ) по работе с массивом с Linux RAID WIKI — Советую быть с ними осторожными, поскольку страничка очень кратко описывает процесс, и благодаря этим рекомендациям, я разрушил /root (md0) моего массива.
До данной строчки в самом низу статьи WIKI, все очень полезно:
Данная строчка демонстрирует как пересоздать массив, зная какие устройства в каком порядке в него входят. Тут очень важно учесть версию своего суперблока, поскольку новые mdadm создают суперблок 1.2 и он располагается в начале раздела, 0.90 же располагается в конце. Поэтому нужно добавить флаг «—metadata=0.90».
После того, как я собрал массив используя «—create», файловая система оказалась разрушенной, и ни основной суперблок ext4, ни резервные не нашлись. Сначала я обнаружил, что новый суперблок не 0.90 а 1.2, что могло являться причиной уничтожения раздела, но, похоже, не являлось, поскольку изменение версии RAID суперблока на 0.90 и поиск backup суперблока ext4 — был неудачен.
Поскольку /root партиция — это не самая важная часть, тут я решил поэкспериментировать — массив был переформатирован и после этого остановлен:
mdadm —stop /dev/md2
и тотчас создан ещё раз через «—create»: результат — файловая система разрушена опять, хотя этого случиться не должно было, я уверен, что не перепутал порядок устройств и первый раз, и тем более 2-й.
Возможно кто-то успешно восстанавливал разделы, через «—create», буду рад добавить в данную статью, что конкретно мною было сделано неправильно, и почему разрушалась FS. Возможно, она была собрана еще и с другими параметрами размера блока (chunk size).
Очевидно что какими либо рекомендациями из данной статьи следует пользоваться на свой страх и риск, никто не гарантирует что в Вашем случае все сработает именно так как в моём.
Источник



