Уничтожение данных на жестком диске в Linux
Когда мы удаляем файл из файловой системы, данные физически не удаляются: операционная система просто отмечает область, ранее занятую файлом, как свободную и делает ее доступной для хранения новой информации. Единственный способ убедиться, что данные действительно удалены с устройства, – перезаписать их другими данными. Если диск с конфиденциальной информацией меняет владельца и вы боитесь, что она может попасть не в те руки необходимо предпринять определенные действия.
Многие криминалистические инструменты с открытым исходным кодом находятся в свободном доступе в Интернете, и их можно использовать для извлечения потерянных или удаленных данных с жесткого диска. Многие из них настолько просты в использовании, что обычные пользователи настольных компьютеров также могут загрузить их и достать данные.
Рассмотрим некоторые инструменты, которые мы можем использовать, чтобы полностью стереть данные на устройстве.
Стирание данных с использованием dd
Утилита dd – мощная программа, включенная по умолчанию во все основные дистрибутивы Linux. С ее помощью мы можем заполнить содержимое диска нулями или случайными данными. В обоих случаях мы можем использовать данные, сгенерированные специальными файлами: /dev/zero и dev/urandom (или /dev/random) соответственно. Первый возвращает нули каждый раз, когда над ним выполняется операция чтения; второй возвращает случайные байты, используя генератор случайных чисел ядра Linux.
Чтобы заполнить диск нулями, мы можем запустить:
Чтобы использовать случайные данные, вместо этого:
Стирание данных с помощью shred
Основное назначение данной утилиты состоит в том, чтобы перезаписать файлы и при необходимости удалить их. Утилита основана на предположении , что файловая система перезаписывает данные на месте. Однако приложение может не позволить нам достичь ожидаемого результата. Например, в журналируемой файловой системе, таких как ext4 (пожалуй наиболее часто используемая файловая система Linux), если она смонтирована с опцией data=journal.
При монтировании файловой системы ext4 с опциями data=ordered или data=writeback (первая используется по умолчанию) данные записываются в основную файловую систему после фиксации метаданных в журнале. В обоих случаях shred работает нормально, что дает ожидаемые результаты. При использовании опции data=journal помимо метаданных в журнал файловой системы записываются также и сами данные и лишь затем данные записываются в основную файловую систему. Легко понять, почему это может вызвать проблемы.
Рассмотрим несколько примеров использования приложения. Предположим, мы хотим безопасно содержимое файла с именем «test».
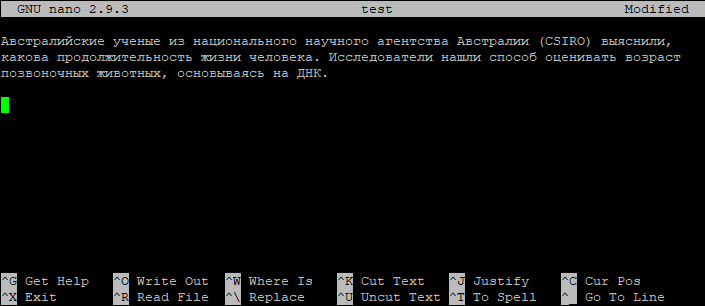
Все, что нам нужно сделать, это запустить следующую команду (здесь мы используем опцию -v, чтобы сделать программу более подробной):

Вот что мы можем видеть после выполнения команды:
По умолчанию приложение переписывает указанный файл случайными данными в три прохода. Количество проходов можно изменить с помощью опции -n. Чтобы переопределить файл 6 раз, мы запустим:

В некоторых случаях мы можем скрыть тот факт, что операция удаления была выполнена для файла или устройства. В этих ситуациях мы можем использовать опцию программы -z (сокращение от –zero), чтобы заставить программу выполнить дополнительный проход нулями:

Из подробного вывода команды мы действительно можем заметить, как выполняется последний проход, записав нули ( 000000).
Помимо работы с файлами shred позволяет производить такие же операции с разделами. Например, нам необходимо навсегда затереть информацию на диске sda:
Источник
Затираем диск безвозвратно в Linux.
Опубликовано 14.07.2015 пользователем Johhny
При передаче/продаже кому-либо накопителя невольно задумываешься: не полезут ли восстанавливать там стертую информацию и как удалить файлы безвозвратно. В статье будем использовать команду dd, которая есть практически в каждом популярном Linux-дистрибутиве, для полного затирания данных на флешке.

Возьмем для примера флешку, на которой записан файл: some_interesting.txt Посмотрим все подключенные накопители, зарегистрированные в системе:

sdb — это наш 8Гб USB Flash drive.
Теперь чистим ее как обычно. Вроде все хорошо, но существует множество программ, которые легко восстановят нам эту информацию. Чтобы убедиться, что ничего на самом деле не стерто воспользуемся командой:
dd if=/dev/sdb | hexdump -C
Бам! Вот и содержимое нашего текстового файла:

Для того чтобы правильно затереть диск потребуется его полная перезапись. Перезаписать можно случайными данными:
dd if=/dev/urandom of=/dev/sdb
dd if=/dev/zero of=/dev/sdb

После этого убедимся, что ничего уже не восстановить:
dd if=/dev/sdb | hexdump -C

Существует мнение об остаточной намагниченности после перезаписи данных и большое количество споров по этому поводу. Если паранойя не отпускает, можно перестраховаться и выполнить несколько циклов записи.
Источник
Выборочно забить HDD нулями
Хочу отдать подыхающий 3 TB диск в компьютерную барахолку за небольшую плату. Так как есть некоторые файлы с паролями и т.п. а делать dd if=/dev/zero of=/dev/sda для всего диска — слишком долго, возник вопрос. Как выборочно затереть диск, «прострелив», скажем, начало каждого файла, или каждый 10-й сектор диска, или стерев полностью структуру каталогов физически на ext4/xfs, хотя бы?


Тривиально. Но тебе надо именно то, что ты называешь «слишком долго».

Погугли «Security Erase victoria». Смысл в том, что при сбросе пароля инициируется полная очистка, причем автономно, т.е. без использования интерфейса. Быстрее очистить жесткий не получится.
Security Erase victoria. Смысл в том, что при сбросе пароля инициируется полная очистка
Q: Возникла необходимость стереть всю информацию с HDD на максимально возможной скорости. Слышал, что современные диски сами предоставляют такую возможность. Как?
A: Это называется Security Erase (стирание через подсистему безопасности). Его можно выполнить программами для работы с диском на низком уровне. Рассмотрим подробно на примере программы Victoria: .

Ну подождешь дня полтора, зато потом больше не будешь пароли в тектовых файлах хранить.
Смотри в сторону srm если нужно затереть определенные файлы.
Источник
Команда dd Linux
Довольно часто системным администраторам приходится копировать различные двоичные данные. Например, иногда может понадобиться сделать резервную копию жесткого диска, создать пустой файл, заполненный нулями для организации пространства подкачки или другой виртуальной файловой системы.
Для решения всех этих задач используется утилита dd linux, которая просто выполняет копирование данных из одного места в другое на двоичном уровне. Она может скопировать CD/DVD диск, раздел на диске или даже целый жесткий диск. В этой статье мы рассмотрим что из себя представляет команда dd linux, основные ее опции и параметры, а также как ею пользоваться.
Как работает команда dd?
Сначала нужно понять как работает команда dd и что она делает. Фактически, это аналог утилиты копирования файлов cp только для блочных данных. Утилита просто переносит по одному блоку данных указанного размера с одного места в другое. Поскольку в Linux все, в том числе, устройства, считается файлами, вы можете переносить устройства в файлы и наоборот.
С помощью различных опций утилиты можно повлиять на размер блока, а это, в свою очередь, уже влияет на скорость работы программы. Дальше мы рассмотрим основные опции утилиты и ее возможности.
Команда dd
Синтаксис утилиты достаточно необычен, но в то же время очень прост, после того как вы его запомните и привыкнете:
$ dd if= источник_копирования of= место_назначения параметры
С помощью параметра if вам нужно указать источник, откуда будут копироваться блоки, это может быть устройство, например, /dev/sda или файл — disk.img. Дальше, с помощью параметра of необходимо задать устройство или файл назначения. Другие параметры имеют такой же синтаксис, как if и of.
Теперь давайте рассмотрим дополнительные параметры:
- bs — указывает сколько байт читать и записывать за один раз;
- cbs — сколько байт нужно записывать за один раз;
- count — скопировать указанное количество блоков, размер одного блока указывается в параметре bs;
- conv — применить фильтры к потоку данных;
- ibs — читать указанное количество байт за раз;
- obs — записывать указанное количество байт за раз;
- seek — пропустить указанное количество байт в начале устройства для чтения;
- skip — пропустить указанное количество байт в начале устройства вывода;
- status — указывает насколько подробным нужно сделать вывод;
- iflag, oflag — позволяет задать дополнительные флаги работы для устройства ввода и вывода, основные из них: nocache, nofollow.
Это были все основные опции, которые вам могут понадобиться. Теперь перейдем ближе к практике и рассмотрим несколько примеров как пользоваться утилитой dd linux.
Как пользоваться dd?
Обычные пользователи используют команду dd чаще всего для создания образов дисков DVD или CD. Например, чтобы сохранить образ диска в файл можно использовать такую команду:
sudo dd if=/dev/sr0 of=
/CD.iso bs=2048 conv=noerror
Фильтр noerror позволяет отключить реагирование на ошибки. Дальше, вы можете создать образ жесткого диска или раздела на нем и сохранить этот образ на диск. Только смотрите не сохраните на тот же жесткий диск или раздел, чтобы не вызвать рекурсию:
В вашей домашней папке будет создан файл с именем disk1.img, который в будущем можно будет развернуть и восстановить испорченную систему. Чтобы записать образ на жесткий диск или раздел достаточно поменять местами адреса устройств:
Очень важная и полезная опция — это bs. Она позволяет очень сильно влиять на скорость работы утилиты. Этот параметр позволяет установить размер одного блока при передаче данных. Здесь нужно задать цифровое значение с одним из таких модификаторов формата:
- с — один символ;
- b — 512 байт;
- kB — 1000 байт;
- K — 1024 байт;
- MB — 1000 килобайт;
- M — 1024 килобайт;
- GB — 1000 мегабайт;
- G — 1024 мегабайт.
Команда dd linux использует именно такую систему, она сложная, но от этого никуда не деться. Ее придется понять и запомнить. Например, 2b — это 1 килобайт, и 1k, это тоже 1 килобайт, 1М — 1 мегабайт. По умолчанию утилита использует размер блока — 512 байт. Например, чтобы ускорить копирование диска можно брать блоки размером по 5 мегабайт. Для этого применяется такая команда:
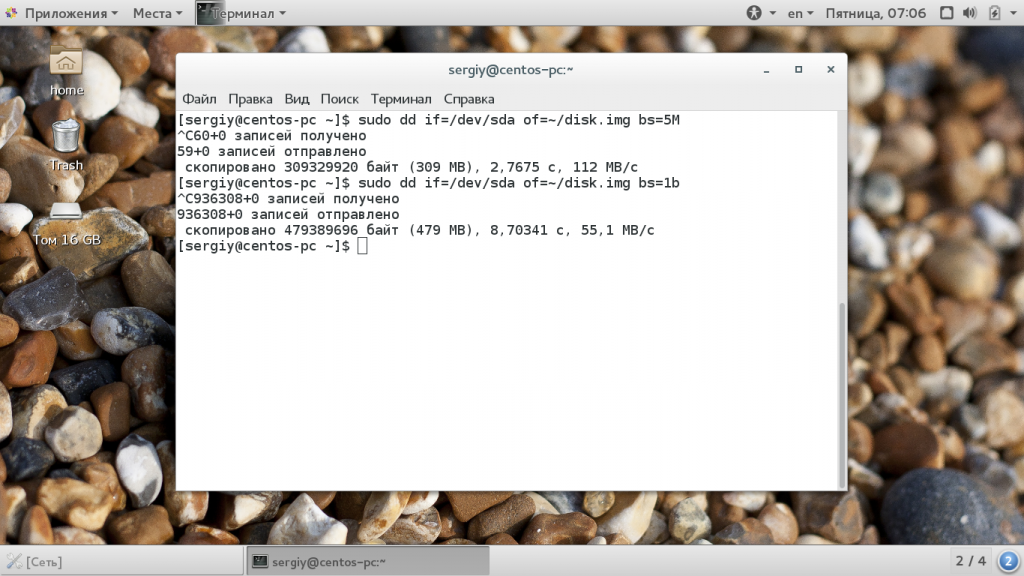
Следующий параметр — это count. С помощью него можно указать сколько блоков необходимо скопировать. Например, мы можем создать файл размером 512 мегабайт, заполнив его нулями из /dev/zero или случайными цифрами из /dev/random:
sudo dd if=/dev/zero of=file.img bs=1M count=512
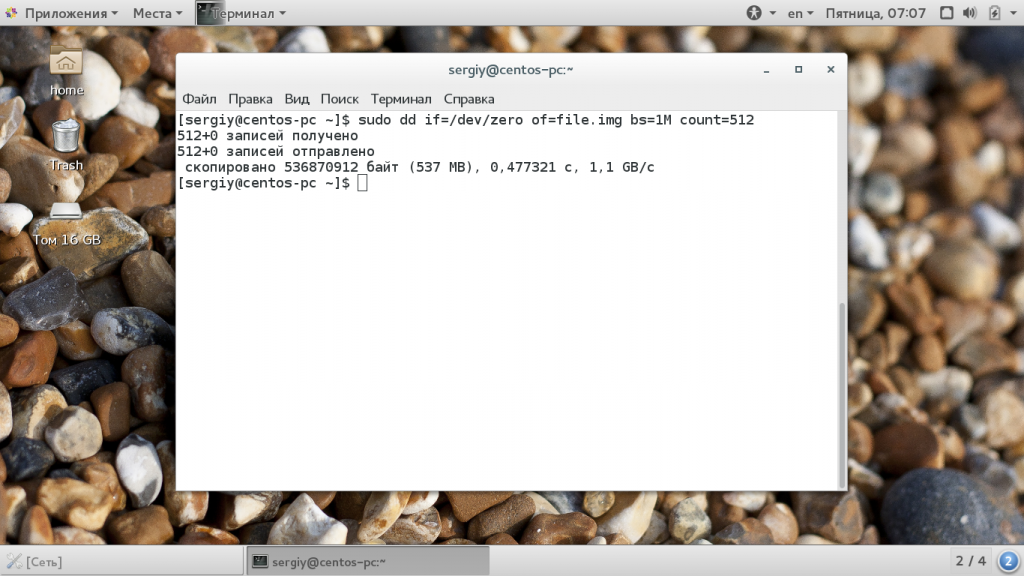
Обратите внимание, что этот параметр указывает не размер в мегабайтах, а всего лишь количество блоков. Поэтому, если вы укажите размер блока 1b, то для создания файла размером 1Кб нужно взять только два блока. С помощью этого параметра также можно сделать резервную копию таблицы разделов MBR. Для этого скопируем в файл первые 512 байт жесткого диска:
sudo dd if=/dev/sda of=mbr.img bs=1b count=1
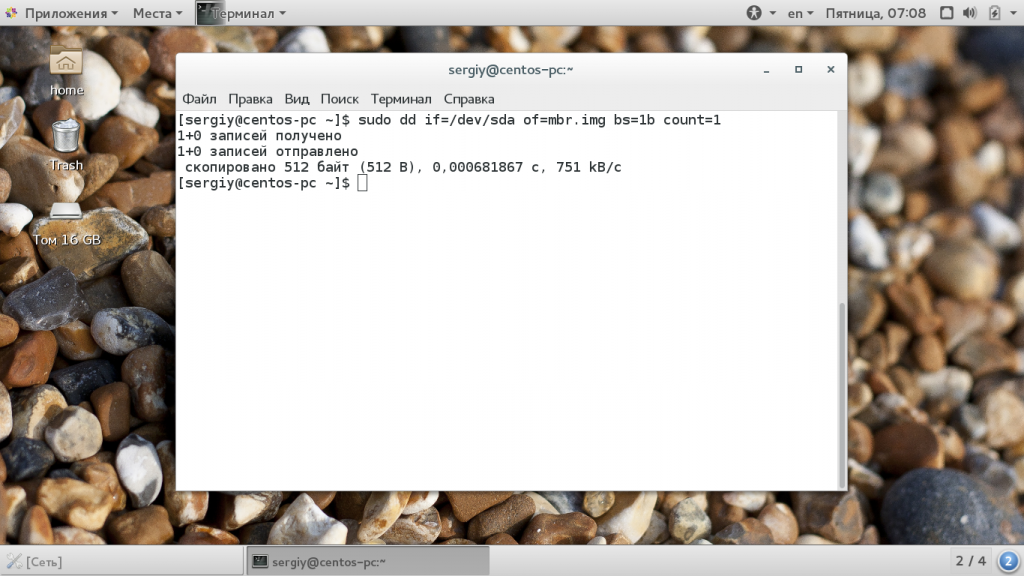
Для восстановления используйте обычную команду развертывания образа на диск.
Если образ диска слишком большой, можно перенаправить весь вывод нестандартный поток вывода утилиты gzip:
dd if =/dev/sda2 | bzip2 disk.img.bz2
Также можно использовать утилиту dd linux для копирования файлов, хотя это и не является ее прямым предназначением:
dd if=/home/sergiy/test.txt of=/home/sergiy/test1.txt
Как вы знаете, команда dd linux пишет данные на диск непосредственно в двоичном виде, это значит, что записываются нули и единицы. Они переопределяют то, что было раньше размещено на устройстве для записи. Поэтому чтобы стереть диск вы можете просто забить его нулями из /dev/zero.
sudo dd if=/dev/zero of=/dev/sdb
Такое использование dd приводит к тому что весь диск будет полностью стерт.
Выводы
В этой статье мы рассмотрели как пользоваться dd linux, для чего можно применять эту утилиту и насколько она может быть полезной. Это почти незаменимый инструмент системного администратора, поскольку с помощью нее можно делать резервные копии целой системы. И теперь вы знаете как. Если у вас остались вопросы, спрашивайте в комментариях!
Источник



