- Руководство по созданию ядра для x86-системы. Часть 1. Просто ядро
- Как загружается x86-система?
- Что нам нужно?
- Задаём точку входа на ассемблере
- Ядро на Си
- Связующая часть
- Grub и Multiboot
- Строим ядро
- Настраиваем grub и запускаем ядро
- Насколько сложный программный код у Windows?
- Кен Грегг (Ken Gregg), разработчик в составе группы Windows NT
- Насколько сложна Windows в программном коде?
- Кен Грегг (Ken Gregg)
- Как менялся программный код Windows?
- Как база кода Windows NT развивалась с 1993 года
- Кен Грегг (Ken Gregg)
- Несколько слов про ядро Windows NT
- Ядро Windows
Руководство по созданию ядра для x86-системы. Часть 1. Просто ядро
Давайте напишем простое ядро, которое можно загрузить при помощи бутлоадера GRUB x86-системы. Это ядро будет отображать сообщение на экране и ждать.

Как загружается x86-система?
Прежде чем мы начнём писать ядро, давайте разберёмся, как система загружается и передаёт управление ядру.
В большей части регистров процессора при запуске уже находятся определённые значения. Регистр, указывающий на адрес инструкций (Instruction Pointer, EIP), хранит в себе адрес памяти, по которому лежит исполняемая процессором инструкция. EIP по умолчанию равен 0xFFFFFFF0. Таким образом, x86-процессоры на аппаратном уровне начинают работу с адреса 0xFFFFFFF0. На самом деле это — последние 16 байт 32-битного адресного пространства. Этот адрес называется вектором перезагрузки (reset vector).
Теперь карта памяти чипсета гарантирует, что 0xFFFFFFF0 принадлежит определённой части BIOS, не RAM. В это время BIOS копирует себя в RAM для более быстрого доступа. Адрес 0xFFFFFFF0 будет содержать лишь инструкцию перехода на адрес в памяти, где хранится копия BIOS.
Так начинается исполнение кода BIOS. Сперва BIOS ищет устройство, с которого можно загрузиться, в предустановленном порядке. Ищется магическое число, определяющее, является ли устройство загрузочным (511-ый и 512-ый байты первого сектора должны равняться 0xAA55).
Когда BIOS находит загрузочное устройство, она копирует содержимое первого сектора устройства в RAM, начиная с физического адреса 0x7c00; затем переходит на адрес и исполняет загруженный код. Этот код называется бутлоадером.
Бутлоадер загружает ядро по физическому адресу 0x100000. Этот адрес используется как стартовый во всех больших ядрах на x86-системах.
Все x86-процессоры начинают работу в простом 16-битном режиме, называющимся реальным режимом. Бутлоадер GRUB переключает режим в 32-битный защищённый режим, устанавливая нижний бит регистра CR0 в 1. Таким образом, ядро загружается в 32-битном защищённом режиме.
Заметьте, что в случае с ядром Linux GRUB видит протоколы загрузки Linux и загружает ядро в реальном режиме. Ядро самостоятельно переключается в защищённый режим.
Что нам нужно?
- x86-компьютер;
- Linux;
- ассемблер NASM;
- gcc;
- ld (GNU Linker);
- grub;
Исходники можно найти на GitHub.
Задаём точку входа на ассемблере
Как бы не хотелось ограничиться одним Си, что-то придётся писать на ассемблере. Мы напишем на нём небольшой файл, который будет служить исходной точкой для нашего ядра. Всё, что он будет делать — вызывать внешнюю функцию, написанную на Си, и останавливать поток программы.
Как же нам сделать так, чтобы этот код обязательно был именно исходной точкой?
Мы будем использовать скрипт-линковщик, который соединяет объектные файлы для создания конечного исполняемого файла. В этом скрипте мы явно укажем, что хотим загрузить данные по адресу 0x100000.
Вот код на ассемблере:
Первая инструкция, bits 32 , не является x86-ассемблерной инструкцией. Это директива ассемблеру NASM, задающая генерацию кода для процессора, работающего в 32-битном режиме. В нашем случае это не обязательно, но вообще полезно.
Со второй строки начинается секция с кодом.
global — это ещё одна директива NASM, делающая символы исходного кода глобальными. Таким образом, линковщик знает, где находится символ start — наша точка входа.
kmain — это функция, которая будет определена в файле kernel.c . extern значит, что функция объявлена где-то в другом месте.
Затем идёт функция start , вызывающая функцию kmain и останавливающая процессор инструкцией hlt . Именно поэтому мы заранее отключаем прерывания инструкцией cli .
В идеале нам нужно выделить немного памяти и указать на неё указателем стека ( esp ). Однако, похоже, что GRUB уже сделал это за нас. Тем не менее, вы всё равно выделим немного места в секции BSS и переместим на её начало указатель стека. Мы используем инструкцию resb , которая резервирует указанное число байт. Сразу перед вызовом kmain указатель стека ( esp ) устанавливается на нужное место инструкцией mov .
Ядро на Си
В kernel.asm мы совершили вызов функции kmain() . Таким образом, наш «сишный» код должен начать исполнение с kmain() :
Всё, что сделает наше ядро — очистит экран и выведет строку «my first kernel».
Сперва мы создаём указатель vidptr , который указывает на адрес 0xb8000. С этого адреса в защищённом режиме начинается «видеопамять». Для вывода текста на экран мы резервируем 25 строк по 80 ASCII-символов, начиная с 0xb8000.
Каждый символ отображается не привычными 8 битами, а 16. В первом байте хранится сам символ, а во втором — attribute-byte . Он описывает форматирование символа, например, его цвет.
Для вывода символа s зелёного цвета на чёрном фоне мы запишем этот символ в первый байт и значение 0x02 во второй. 0 означает чёрный фон, 2 — зелёный цвет текста.
Вот таблица цветов:
В нашем ядре мы будем использовать светло-серый текст на чёрном фоне, поэтому наш байт-атрибут будет иметь значение 0x07.
В первом цикле программа выводит пустой символ по всей зоне 80×25. Это очистит экран. В следующем цикле в «видеопамять» записываются символы из нуль-терминированной строки «my first kernel» с байтом-атрибутом, равным 0x07. Это выведет строку на экран.
Связующая часть
Мы должны собрать kernel.asm в объектный файл, используя NASM; затем при помощи GCC скомпилировать kernel.c в ещё один объектный файл. Затем их нужно присоединить к исполняемому загрузочному ядру.
Для этого мы будем использовать связывающий скрипт, который передаётся ld в качестве аргумента.
Сперва мы зададим формат вывода как 32-битный Executable and Linkable Format (ELF). ELF — это стандарный формат бинарных файлов Unix-систем архитектуры x86. ENTRY принимает один аргумент, определяющий имя символа, являющегося точкой входа. SECTIONS — это самая важная часть. В ней определяется разметка нашего исполняемого файла. Мы определяем, как должны соединяться разные секции и где их разместить.
В скобках после SECTIONS точка (.) отображает счётчик положения, по умолчанию равный 0x0. Его можно изменить, что мы и делаем.
Смотрим на следующую строку: .text : < *(.text) >. Звёздочка (*) — это специальный символ, совпадающий с любым именем файла. Выражение *(.text) означает все секции .text из всех входных файлов.
Таким образом, линковщик соединяет все секции кода объектных файлов в одну секцию исполняемого файла по адресу в счётчике положения (0x100000). После этого значение счётчика станет равным 0x100000 + размер полученной секции.
Аналогично всё происходит и с другим секциями.
Grub и Multiboot
Теперь все файлы готовы к созданию ядра. Но остался ещё один шаг.
Существует стандарт загрузки x86-ядер с использованием бутлоадера, называющийся Multiboot specification. GRUB загрузит наше ядро, только если оно удовлетворяет этим спецификациям.
Следуя им, ядро должно содержать заголовок в своих первых 8 килобайтах. Кроме того, этот заголовок должен содержать 3 поля, являющихся 4 байтами:
- магическое поле: содержит магическое число 0x1BADB002 для идентификации ядра.
- поле flags: нам оно не нужно, установим в ноль.
- поле checksum: если сложить его с предыдущими двумя, должен получиться ноль.
Наш kernel.asm станет таким:
Строим ядро
Теперь мы создадим объектные файлы из kernel.asm и kernel.c и свяжем их, используя наш скрипт.
Эта строка запустит ассемблер для создания объектного файла kasm.o в формате ELF-32.
Опция «-c» гарантирует, что после компиляции не произойдёт скрытого линкования.
Это запустит линковщик с нашим скриптом и создаст исполняемый файл, называющийся kernel.
Настраиваем grub и запускаем ядро
GRUB требует, чтобы имя ядра удовлетворяло шаблону kernel- . Поэтому переименуйте ядро. Своё я назвал kernel-701.
Теперь поместите его в директорию /boot. Для этого понадобятся права суперпользователя.
В конфигурационном файле GRUB grub.cfg добавьте следующее:
Не забудьте убрать директиву hiddenmenu , если она есть.
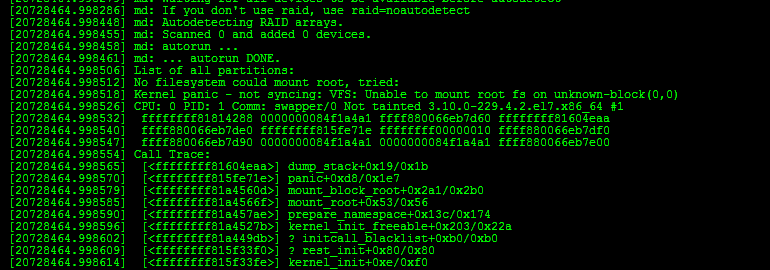
Перезагрузите компьютер, и вы увидите список ядер с вашим в том числе. Выберите его, и вы увидите:

Это ваше ядро! В следующей части добавим систему ввода / вывода.
Насколько сложный программный код у Windows?

Чтобы разобраться вопросе, насколько может быть сложным программный код «Виндовс» мы обратились к одному из разработчиков команды Windows NT в компании Microsoft — Кену Греггу (Ken Gregg).
Кен Грегг (Ken Gregg), разработчик в составе группы Windows NT
«Могу сказать вам, что у меня был доступ к исходному коду, когда я был в команде Windows NT (NT является основой для всех настольных версий Windows начиная с XP), во время проектов разработки NT 3.1 и NT 3.5. Всё было в рамках стандартов кодирования NT Workbook — эдакой «библии» для всей проектной команды.
. Хотя я и не читал каждую строку кода, но то, с чем мне пришлось работать, было очень:
Нужно исходить из того, что именно понимается под сложностью кода. Это понимание сугубо субъективное, ведь так? Благо существует множество различных метрик, используемых и комбинируемых для измерения сложности программного обеспечения в тех или иных ситуациях (та же самая модульность, многоуровневость и обслуживаемость).

Насколько сложна Windows в программном коде?
Конечно, чтобы прочитать и понять код, вам нужно было бы иметь представление об общей архитектуре Windows NT.
Вероятно, лучшим источником информации о внутренностях Windows сегодня являются книги Windows Internals 6th Edition (в двух томах).
Некоторые люди просто приравнивают сложность кода к размеру. У этого сравнения тоже есть метрика — строки кода (LOC).
Измерение LOC зависит от используемых инструментов и критериев. Их выбирают для точного определения строк кода на каждом языке программирования.

Кен Грегг (Ken Gregg)
«Существует много споров о методах, используемых для подсчета строк кода (LOC). Если использовать одни и те же критерии от одного выпуска к следующему, то получится относительное изменение размера базы кода.
Сравнивать эти числа с цифрами другой ОС, которая использовала другой метод подсчета строк кода, всё равно что сравнивать яблоки с апельсинами. То есть это некорректный подход».

Как менялся программный код Windows?
Здесь приводятся некоторые лакомые кусочки, дающие представление о размерах современной кодовой базы Windows. Строки кода здесь являются приблизительными и неофициальными, но основаны на достаточно надёжных источниках, о которых говорит Кен Грегг .
Как база кода Windows NT развивалась с 1993 года
MLOC — это количество миллионов строк исходного кода. По ним можно определить относительную сложность операционной системы, если опираться на размеры кода (LOC-методика).
- Windows NT 3.1 (1993) — 5,6 MLOC
- Windows NT 3.5 (1994) — 8,4 MLOC
- Windows NT 3.51 (1995) — 10,2 MLOC
- Windows NT 4.0 (1996) — 16 MLOC
- Windows 2000 (2000) — 29 MLOC
- Windows XP (2001) — 35 MLOC
- Windows Vista (2007) — 45 MLOC
- Windows 7 (2009) — 42 MLOC
- Windows 8 (2012) — 50 MLOC
- Windows 10 (2015) — 55 MLOC
Исходный код Windows состоит в основном из C и C++, а также небольшого количества кода на ассемблере.
Некоторые из утилит пользовательского режима и другие подобные службы пишутся на Си Шарп, но это относительно небольшой процент от общей базы кода.
Кен Грегг (Ken Gregg)
«Я намеренно не включил в список 16-битные версии ОС, выпущенные с 1985 по 2000 годы. Windows NT была основой для всех современных 32-бит и 64-бит версий Windows. Количество строк кода в серверных версиях было таким же, как и в несерверных версиях, выпущенных в том же году (то есть они имели одинаковую базу исходного кода)».

Несколько слов про ядро Windows NT
По словам Кена, работа над ядром NT началась в 1988 году. Ядро было создано с нуля в качестве 32-разрядной упреждающей многозадачной ОС.
Ядро NT впервые загрузилось в июле 1989 года на процессоре Intel i860 RISC. С самого начала был сильный толчок к тому, чтобы новая ОС была совместимой с различными архитектурами центральных процессоров и не была привязана только к архитектуре Intel x86 (IA-32).
NT в конечном итоге работал на MIPS, DEC Alpha, PowerPC, Itanium и, конечно, Intel x86 и x64.
Некоторая сложность была добавлена в базу кода на уровне абстрагирования оборудования (HAL). Это было нужно для поддержки неинтеловских архитектур.
А как вы оцениваете перспективы Windows в плане кода? Узнайте, какие версии Windows актуальны сейчас и какие ОС можно рассмотреть в качестве альтернативы.
Есть проблемы при использовании Windows и непонятен программный код для внедрения новых бизнес-инструментов в ОС от Microsoft? Проконсультируйтесь с экспертами по ИТ-аутсорсингу и получите поддержку по любым техническим вопросам и задачам.
Ядро Windows
Ядро состоит из набора функций, находящихся в файле Ntoskrnl.exe. Этот набор предоставляет основные механизмы (службы диспетчеризации потоков и синхронизации), используемые компонентами исполняющей системы, а также поддержкой архитектурно-зависимого оборудования низкого уровня (например, диспетчеризацией прерываний и исключений), которое имеет отличия в архитектуре каждого процессора. Код ядра написан главным образом на C, с ассемблерным кодом, предназначенным для задач, требующих доступа к специальным инструкциям и регистрам процессора, доступ к которым из кода на языке C затруднен. Подобно различным вспомогательным функциям, ряд функций ядра документированы в WDK (и их описание может быть найдено при поиске функций, начинающихся с префикса Ke), поскольку они нужны для реализации драйверов устройств.
Ядро предоставляет низкоуровневую базу из четко определенных, предсказуемых примитивов и механизмов операционной системы, позволяющую высоко уровневым компонентам исполняющей системы выполнять свои функции. Само ядро отделено от остальной исполняющей системы путем реализации механизмов операционной системы и уклонения от выработки политики. Оно оставляет почти все политические решения, за исключением планирования и диспетчеризации потоков, реализуемых ядром, за исполняющей системой. За пределами ядра исполняющая система представляет потоки и другие ресурсы совместного использования в виде объектов. Эти объекты требуют некоторых издержек, например, на дескрипторы для управления ими, на проверки безопасности для их защиты и на ресурсные квоты, выделяемые при их создании. В ядре, реализующем набор менее сложных объектов, называемых «объектами ядра», подобные издержки исключены, что помогает ядру управлять основной обработкой и поддерживать создание исполняющих объектов. Большинство объектов уровня исполнения инкапсулируют один или несколько объектов ядра, принимая их, определенные в ядре свойства. Один набор объектов ядра, называемых «управляющими объектами», определяет семантику управления различными функциями операционной системы. В этот набор включены объекты асинхронного вызова процедур — APC, отложенного вызова процедур — deferred procedure call (DPC), и несколько объектов, используемых диспетчером ввода-вывода, например, объект прерывания.
Еще один набор объектов ядра, известных как «объекты-диспетчеры», включает возможности синхронизации, изменяющие или влияющие на планирование потоков. Объекты-диспетчеры включают поток ядра, мьютекс (называемый среди специалистов «мутантом»), событие, пару событий ядра, семафор, таймер и таймер ожидания. Исполняющая система использует функции ядра для создания экземпляров объектов ядра, работы с ними и создания более сложных объектов, предоставляемых в пользовательском режиме. Область ядра, относящаяся к управлению процессором, и блок управления (KPCR и KPRCB). Для хранения специфических для процессора данных ядром используется структура данных, называемая областью, относящейся к управлению процессором, или KPCR (KernelProcessorControlRegion). KPCR содержит основную информацию, такую как процессорная таблица диспетчеризации прерываний (interrupt dispatch table, IDT), сегмент состояния задачи (task-state segment, TSS) и таблица глобальных дескрипторов (globaldescriptortable, GDT). Она также включает состояние контроллера прерываний, которое используется вместе с другими модулями, такими как ACPI-драйвер и HAL.
Для обеспечения простого доступа к KPCR ядро хранит указатель на эту область в регистре fs на 32-разрядной системе Windows и в регистре gs на Windows-системе x64. На системах IA64 KPCR всегда находится по адресу 0xe0000000ffff0000. KPCR также содержит вложенную структуру данных, которая называется блоком управления процессором (kernelprocessorcontrolblock, KPRCB). В отличие от области KPCR, которая документирована для драйверов сторонних производителей и для других внутренних компонентов ядра Windows, KPRCB является закрытой структурой, используемой только кодом ядра, который находится в файле Ntoskrnl.exe. В этом блоке содержится:
— информация о планировании (такая как текущий, следующий и приостановленный потоки, предназначенные для выполнения на процессоре);
— предназначенная для процессора база данных диспетчера (включающая готовые очереди для каждого приоритетного уровня);
— информация о производителе центрального процессора и идентификационная информация (модель, степпинг, скорость, биты особенностей);
— информация о топологии центрального процессора и о технологии доступа к неоднородной памяти — NUMA (информация об узле, о количестве логических процессоров в каждом ядре и т. д.);
— информация о размерах кэш-памяти;
— информация об учете времени (такая как время DPC и обработки прерывания) и многое другое.
В KPRCB также содержится вся статистика процессора, такая как статистика ввода-вывода, статистика диспетчера кэша, статистика DPC и статистика диспетчера памяти. И наконец, KPRCB иногда используется для хранения структур выравнивания границ кэша для каждого процессора, необходимых для оптимизации доступа к памяти, особенно на NUMA-системах. Например, система не выгружаемого и выгружаемого пула со стороны выглядит как списки, хранящиеся в KPRCB.



