- Выставляем кодировку UTF-8
- PHP Кодировка страницы
- Кодировки скриптов (шаг 1)
- Кодировка таблиц MySQL. (шаг 2)
- Кодировка самой HTML страницы. (Шаг 3)
- Локаль используемая браузером пользователя. (Шаг 4)
- Читайте также похожие статьи:
- Определение кодировки текста в PHP вместо mb_detect_encoding
- Методика тестирования
Выставляем кодировку UTF-8
На сколько бы это глупо не казалось, но для удачного выставления кодировки необходимо выполнить целых 11(!) правил.
Хочу зарание предупредить, если какая-то из настроек в .htaccess повлечет за собой ошибку 500, это значит, что хостинг запретил менять этот параметр на сервере. В таком случае проверьте тот факт, что у Вас UTF-8 и в случае чего обратитесь к админам хостинга.
И для тех, кто попал на эту страницу с вопросами об Ajax: Ajax работает в кодировке UTF-8.
Правило №1: Указываем в HTML верстке в теге первой строчкой, кроме случаев, где мы будем использовать тег , так как он так же как и кодировка имеет приоритет над расположением, следующий код:
Правило №2: Указываем кодировку для PHP и самого файла, для этого нам необходимо выставить заголовок функцией header(). Выставляем его в самом начале нашего файла (абсолютно в самом начале), сразу после указания уровня вывода ошибок:
Правило №3: Кодировка для подключения к к БД MySQL. Устанавливается после подключения к БД и выбора бд (mysql_connect, mysql_select_db). Если у нас модуль mysql:
или улучшенный модуль mysqli:
Правило №4: Кодировка в .htaccess:
Правило №5: Кодировка для библиотеки mb, начиная с версии php 5.4 можно не указывать, так как по умолчанию будет использоваться именно UTF-8. Ну а пока прописываем её в файле .htaccess:
Либо в самом PHP, что в итоге выполнит одни и те же действия:
Правило №6: При сохранении файлов (обязательно ВСЕХ!) выбрать кодировку UTF-8 without BOM, повторюсь, without BOM — это необходимая настройка, в противном случае Ваш сайт не будет работать как надо. Для тех, кто пользуется удобной программой DreamWeaver:
Modify => Page Properties => Title/Encoding и выставляем «Encoding: UTF-8», после чего нажимаем ReLoad, убираем галочку с BOM «Include Unicode Signature (BOM)». Apply + OK.
Модификации => Свойства страницы => Заголовок/Кодировка и выставляем кодировку UTF-8. Нажимаем «перезагрузить», убрали галочку с Подключить Юникод Сигнатуры (BOM). Применить и OK.
Правило №7: если на данный момент какой-то из текстов был введён на странице или в БД — его необходимо перенабрать. Дело в том, что символ в одной кодировке представляет один набор бит для русских символов, а в другой — другой. Именно поэтому необходимо его либо перенабрать, либо перекодировать. Современные программы имеют возможность перевести текст из одной кодировки в другую. Об этой возможности интересуйтесь в мануалах Ваших программ.
Правило №8: Есть исключение, когда текст приходит к Вам на страницу с другого сайта в другой кодировке. Тогда на PHP есть удобная функция для перевода из одной кодировки в другую:
Правило №9: Для строковых функций strlen, substr, необходимо использовать их аналоги на библиотеке mb_, а именно: mb_strlen, mb_substr, то есть к функции дописываем mb_ .
Правило №10: Для работы с регулярными выражениями необходимо указывать модификатор u . Это обязательный параметр!
Правило №11: Для CSS файлов указывается кодировка так:
В заключение скажу, что символы в кодировке WIN-1251 состоят из 1 байта, то есть 8 бит, а в свою очередь в кодировке UTF-8 символы могут состоять от 1 до 4 байт, всё дело в том, что кодировка UTF-8 позволяет создавать мультиязычные сайты, так как все существующие в мире символы в ней присутствуют.
Ради любопытства русская буква в кодировке UTF-8 занимает 2 байта, именно поэтому за 1 символ функция strlen возвращает длину 2, то есть 2 байта, а mb_strlen возвращает уже правильную длину в 1 символ.
PHP Кодировка страницы

Здравствуй уважаемый читатель блога LifeExample, кодировка веб страницы это очень интересный зверь, и за частую хищный для начинающих веб мастеров. Я уверен в том, что все новички сталкиваются с проблемой правильного отображения текста на страницах своего сайта. Ты дорогой читатель, наверное встречал в сети интернета ресурсы, на страницах которых отображался не читаемый текст, а кракозябры.
Кракозябрами в среде программирования веб сайтов принято называть символы не соответствующие тем, которые должны быть выведены на страницу. Например, на созданной вами странице должно отображаться приветствие: «Здравствуй читатель моего блога!», а на деле получаете непонятный набор закорючек «Р—РґСЂР°РІСЃС‚РІСѓР№ читатеРСЊ моего Р±РРѕРіР°!» – вот такие закорючки и есть злые КРАКОЗЯБРЫ.
В данной статье мы разберем эту проблему с ног до головы, чтобы больше не возвращаться к танцам с бубном вокруг нечитаемого текста.
И так, чтобы понять откуда появляются подобного рода иероглифы, нам нужно познакомиться с понятием кодировка страницы. Любой текст на компьютере представляется в виде набора байтов, в каждом из этих байтов определенным кодом — закодирован только один единственный символ. Так вот для того чтобы правильно расшифровать или раскодировать набор байтов и представить его в понятном человеку виде, браузеру нужно провести соответствие с одной из кодовых таблиц. Базовой кодировкой является ASCII кодировка, она содержит в себе коды 128 символов латинского алфавита и спец символов вроде скобок и решеток. Именно из ASCII появились первые русскосимвольные кодировки CP866 и KOI8-R, а из них вышла известная сегодняшним вебмастерам кодировка windows-1251. Не смотря на то, что все эти кодировки призваны для отображения русского текста, они все отличаются друг от друга кодами для одинаковых символов. Если текст писался в кодировке CP866, а браузер пытается раскодировать ее с помощью таблицы кодов windows-1251, то в результате мы получим не читаемые слова. Такое часто происходит при отправке сообщений через почтовый сервер.
Приведенные здесь названия кодировок далеко не все что существуют и используются в разных случаях, их намного больше чем вы думаете. С таким обилием кодовых таблиц образовалась проблема совместимости кодировок, и веб мастерам пришлось вставть на борьду с универсализацией кода, что занимало много времени и нервов. На сегодняшний день изобретена панацея для данной проблемы в виде универсальной кодировки utf-8, со временем она вытесняет используемые ранее кодовые таблицы символов, и сейчас уже не для кого не встает вопрос о том в какой кодировке лучше сохранять данные.
Много было сказано относительно эволюции кодировок, и постановке самой задачи, пришло время поговорить о практических моментах.
Существует четыре места на кухне программирования сайта, которые требуют соблюдения единого стандатра кодирования текста.
- Кодировки скриптов.
- Кодировка таблиц MySQL.
- Кодировка самой HTML страницы.
- Локаль используемая браузером пользователя.
Во всех этих составляющих сайта, должна использоваться единая кодировка, какая – решать вам, но я рекомендую utf-8, всетаки она универсальная)
И так теперь подробнее рассмотрим, что нужно сделать для того, чтобы привести к одной кодировке всеперечисленые составляющие.
Кодировки скриптов (шаг 1)
Для того чтобы все скрипты имели одну кодировку, нужно при создании нового скрипта указать желаемую кодировку в настройках вашего редактора. Приведу пример данной процедуры в NotePad++ . При создании нового PHP файла сразу идем в раздел Encoding, он находится в меню, и выбираем Convert to UTF-8 without BOM.
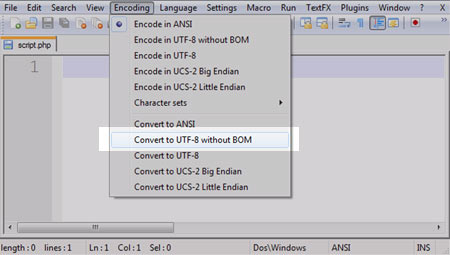
Выбираем именно Convert to UTF-8 without BOM, а не просто Convert to UTF‑8. Приставка without BOM означает то что в первых двух байтах файла будет зашифрована специальная информация о параметре кодировки, в скриптах нам не нужна никакая лишняя информация. В большенстве случаев сохранение с BOM не окажется криминальным, но когданить один из скриптов откажется правильно работать и одной из причин может отазаться именно информация заключенная в первых байтах файла.
Кодировка таблиц MySQL. (шаг 2)
Для того, чтобы узнать какие кодировки используются в ваше MySQL базе, воспользуемся интерфейсом phpMyAdmin. В разделе SQL напишем запрос:
Выглядеть это должно вот так:
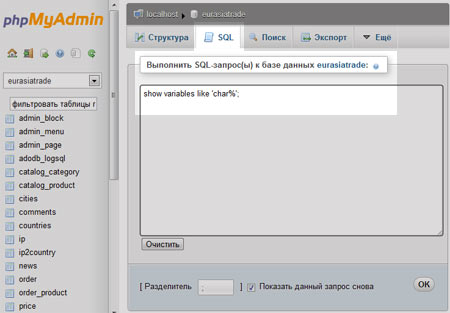
Жмем ОК и получаем информацию о кодировках таблицы
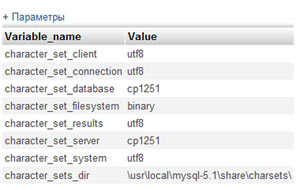
Значения на против character_set_client и character_set_results должны совпадать, так как эти параметры отвечают за кодировку, в которой данные поступают в базу и за кодировку в которой данные берутся из базы.
Если они у вас различаются, то нужно в PHP коде в ручную установить нужную кодировку. Делается это вот такой строчкой:
После этого три переменные character_set_client, character_set_connection и character_set_results примут значение utf8.
Подробнее о том как с помощью PHP работать с базой данных можно прочесть в статье PHP работа с базой данных (Часть 1-3).
Кодировка самой HTML страницы. (Шаг 3)
Теперь данные взятые с базы и данные обрабатываемые в php скрипте, будут совпадать по кодировке, и выводиться в понятном для человека тексте. Но это еще не все, нужно указать кодировку в разделе для мета тегов:
Либо в cкрипте настроек php командой:
Если кодировка HTML будет задана сразу двумя способами, то приоритетным будет задание кодировки из php скрипта.
Также можно глобально задать правило кодировки HTML в файле .htaccess добавив в него строку:
Локаль используемая браузером пользователя. (Шаг 4)
Еще одна важная деталь при корректном отображении текста это установка локали:
При установки такой локали, пердставители других стран использующие другую кодовую страницу в своей операционной системе, будут видеть русский текст.
Мы рассмотрели основные моменты возникновения противоречий в кодировках веб страницы, подведем итоги. Для того чтобы ваш рускоязычный сайт был всегда доступен для чтения, необходимо прописать в PHP скрипте настроек такие строки:
Если у тебя дорогой читатель остались вопросы по данной статье о PHP кодировке страниц, то смело задавай их в комментариях.
Читайте также похожие статьи:

Чтобы не пропустить публикацию следующей статьи подписывайтесь на рассылку по E-mail или RSS ленту блога.
Определение кодировки текста в PHP вместо mb_detect_encoding
Существует несколько кодировок символов кириллицы.
При создании сайтов в Интернете обычно используют:
- utf-8
- windows-1251
- koi8-r
Еще популярные кодировки:
- iso-8859-5
- ibm866
- mac-cyrillic
Вероятно это не весь список, это те кодировки с которыми я часто сталкиваюсь.
Иногда появляется необходимость определить кодировку текста. И в PHP даже функция для этого есть:
Я протестировал функцию определения кодировки по кодам символов, результат меня удовлетворил и я использовал эту функцию пару лет.
Недавно решил переписать проект где использовал эту функцию, нашел готовый пакет на packagist.org cnpait/detect_encoding, в котором кодировка определяется методом m00t
При этом указанный пакет был установлен более 1200 раз, значит не у меня одного периодически возникает задача определения кодировки текста.
Мне бы установить этот пакет и успокоиться, но я решил «заморочиться».
В общем, сделал свой пакет: onnov/detect-encoding.
Как его использовать написано в README.md
А о его тестировании и сравнении с пакетом cnpait/detect_encoding напишу.
Методика тестирования
Берем большой текст: Tolstoy — Anna Karenina
Всего — 1’701’480 знаков
Убираем все лишнее, оставляем только кириллицу:
Осталось 1’336’252 кирилистических знаков.
В цикле берем часть текста (5, 15, 30,… символов) преобразуем в известную кодировку и пытаемся определить кодировку скриптом. Затем сравниваем правильно или нет.
Вот таблица в которой слева кодировки, сверху количество символов по которому определяем кодировку, в таблице результат достоверности в %%
| letters -> | 5 | 15 | 30 | 60 | 120 | 180 | 270 |
|---|---|---|---|---|---|---|---|
| windows-1251 | 99.13 | 98.83 | 98.54 | 99.04 | 99.73 | 99.93 | 100.0 |
| koi8-r | 99.89 | 99.98 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| iso-8859-5 | 81.79 | 99.27 | 99.98 | 100.0 | 100.0 | 100.0 | 100.0 |
| ibm866 | 99.81 | 99.99 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| mac-cyrillic | 12.79 | 47.49 | 73.48 | 92.15 | 99.30 | 99.94 | 100.0 |
Наихудшая точность с мак-кириллицей, вам нужно как минимум 60 символов, чтобы определить эту кодировку с точностью 92,15%. Кодировка Windows-1251 также имеет очень низкую точность. Это связано с тем, что номера их символов в таблицах сильно пересекаются.
К счастью, кодировки mac-cyrillic и ibm866 не используются для кодирования веб-страниц.
Попробуем без них:
| letters -> | 5 | 10 | 15 | 30 | 60 |
|---|---|---|---|---|---|
| windows-1251 | 99.40 | 99.69 | 99.86 | 99.97 | 100.0 |
| koi8-r | 99.89 | 99.98 | 99.98 | 100.0 | 100.0 |
| iso-8859-5 | 81.79 | 96.41 | 99.27 | 99.98 | 100.0 |
Точность определения высока даже в коротких предложениях от 5 до 10 букв. А для фраз из 60 букв точность определения достигает 100%. А еще, определение кодировки выполняется очень быстро, например, текст длиной более 1 300 000 символов кириллицы проверяется за 0.00096 секунд. (на моем компьютере)
А какие результаты покажет статистический способ описанный m00t:
| letters -> | 5 | 10 | 15 | 30 | 60 |
|---|---|---|---|---|---|
| windows-1251 | 88.75 | 96.62 | 98.43 | 99.90 | 100.0 |
| koi8-r | 85.15 | 95.71 | 97.96 | 99.91 | 100.0 |
| iso-8859-5 | 88.60 | 96.77 | 98.58 | 99.93 | 100.0 |
Как видим результаты определения кодировки хорошие. Скорость работы скрипта высокая, особенно на коротких текстах, на огромных текстах скорость значительно уступает. Текст длиной более 1 300 000 символов кириллицы проверяется за 0.32 секунд. (на моем компьютере).



