- 8-битные кодировки: ASCII, КОИ-8R и CP1251
- Приложения
- Кодировки Windows-1251, KOI8-R и ISO 8859-5
- Что такое кодировки?
- Почему кодировки — это важно?
- Предпосылки появления кодировок
- Компьютеры и числа
- Компьютеры и символы
- Распространение компьютеров
- ASCII как первый стандарт кодирования информации
- Телетайп и терминал
- ASCII
- Кодировки для других языков
- Переход к Unicode
- Кодировки на основе Unicode
8-битные кодировки: ASCII, КОИ-8R и CP1251
Первые таблицы кодировки, созданные в США, не использовали восьмой бит в байте. Текст представлялся как последовательность байт, но восьмой бит не учитывался (он применялся в служебных целях). Общепризнанным стандартом стала таблица ASCII (American Standard Code for Information Interchange ).
Первые 32 символа таблицы ASCII (от 00 до 1F ) использовались для непечатаемых символов. Они были предназначены для управления печатающим устройством и т.п. Остальная часть – от 20 до 7F – обычные (печатаемые) символы.
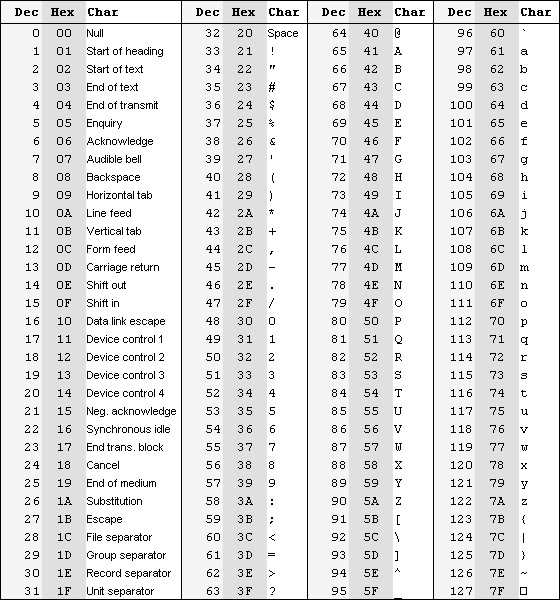
Как легко заметить, в этой кодировке представлены только латинские буквы, причём те, которые используются в английском языке. Есть также арифметические и другие служебные символы. Но нет ни русских букв, ни даже специальных латинских для немецкого или французского языка.
Это легко объяснить – кодировка разрабатывалась имено как американский стандарт. Когда компьютеры стали применяться во всём мире, потребовалось кодировать и другие символы.
Для этого было принято решение использовать восьмой бит в каждом байте. Тем самым оказались доступны ещё 128 значений (от 80 до FF), которые можно было использовать для кодирования символов.
Первая из восьмибитных таблиц – “расширенный ASCII” (Extended ASCII) – включала в себя различные варианты латинских символов, применяемые в некоторых языках Западной Европы. Также в ней были другие дополнительные символы, включая псевдографику.
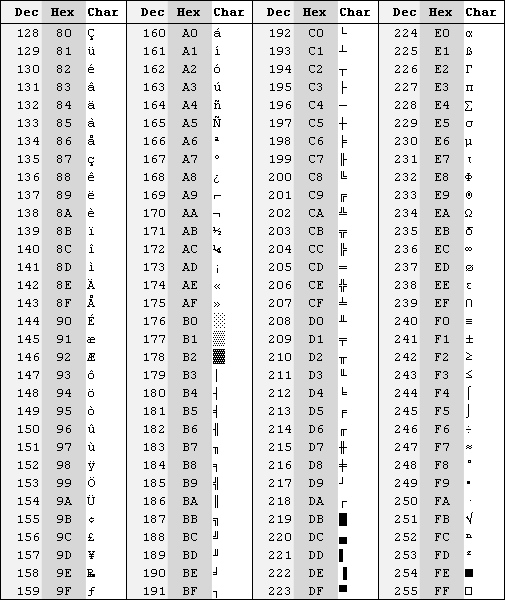
Таблица 2. Extended ASCII
Псевдографические символы позволяют, выводя на экран только текстовые символы, обеспечивать некоторое подобие графики. При помощи псевдографики работает, например, програма для управления файлами FAR Manager.
Русских букв в таблице Extended ASCII не было. В России (ранее – СССР) и в других государствах создавались свои кодировки, позволяющие представлять в 8-битных текстовых файлах специфические “национальные” символы – латинские буквы польского и чешского языков, кириллицу (включая русские буквы ) и другие алфавиты.
Во всех кодировках, получивших распространение, первые 127 символов (т.е. значения байта при восьмом бите, равном 0) совпадают с ASCII. Таким образом, файл в формате ASCII работает в любой из этих кодировок; буквы английского языка в них представлены одинаково.
Организация ISO (International Standardization Organization – Международная Организация по Стандартам) приняла группу стандартов ISO 8859. Она определяет 8-битные кодировки для разных групп языков. Так, ISO 8859-1 – это Extended ASCII, таблица для США и Западной Европы. А ISO 8859-5 – таблица для кириллицы (включая русский язык).
Однако по историческим причинам кодировка ISO 8859-5 не прижилась. Реально для русского языка применяются следующие кодировки:
– Code Page 866 (CP866), она же “ DOS ”, она же “альтернативная кодировка ГОСТ”. Широко применялась до середины 90-х годов; теперь используется ограниченно. Практически не применяется для распространения текстов в Интернете .
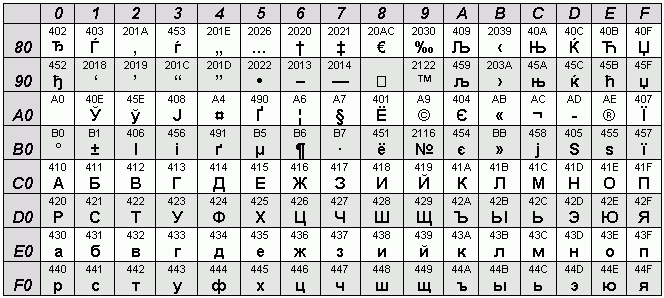
– КОИ-8. Разработана в 70-80-е годы. Является общепринятым стандартом для передачи почтовых сообщений в российском Интернете. Широко применяется также в операционных системах семейства Unix, включая Linux. Вариант КОИ-8, рассчитанный на русский язык, называется КОИ-8R; существуют версии для иных кириллических языков (так, KOI8-U – вариант для украинского языка).
– Code Page 1251, CP1251, Windows-1251. Разработана компанией Microsoft для поддержки русского языка в системе Windows.
Основным достоинством CP866 было сохранение символов псевдографики на тех же местах, что и в Extended ASCII; поэтому могли без изменений работать зарубежные текстовые программы, например, знаменитый Norton Commander. Ныне CP866 используется для программ под Windows, работающих в текстовых окнах или в полноэкранном текстовом режиме, включая FAR Manager.
Тексты в CP866 в последние годы встречаются довольно редко. Поэтому мы подробнее остановимся на двух других кодировках – КОИ-8R и CP1251.
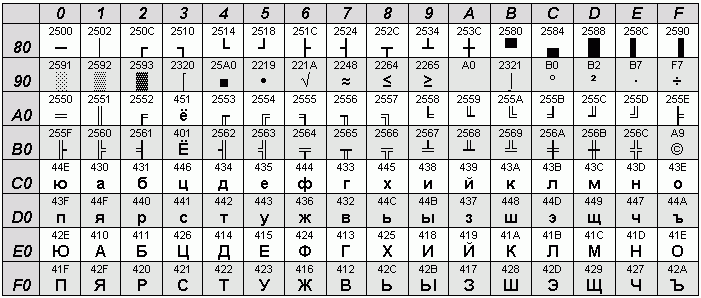
Как можно заметить, в таблице кодировки CP1251 русские буквы расположены в алфавитном порядке (за исключением, правда, буквы Ё). Благодаря такому расположению компьютерным программам очень просто осуществлять сортировку по алфавиту.
А вот в КОИ-8R порядок русских букв кажется случайным. Но на самом деле это не так.
Во многих старых программах при обработке или передаче текста терялся 8-й бит. (Сейчас такие программы практически “вымерли”, но в конце 80-х – начале 90-х годов они были широко распространены). Чтобы получить из 8-битного значения 7-битное, достаточно отнять от старшей цифры 8; например, E1 превращается в 61 .
А теперь сравните КОИ-8R с таблицей ASCII (табл.1). Вы обнаружите, что русские буквы поставлены в чёткое соответствие с латинскими. Если исчезнет восьмой бит, строчные русские буквы превращаются в заглавные латинские, а заглавные русские – в строчные латинские. Так, E1 в КОИ-8 – это русское “А”, тогда как 61 в ASCII – латинское “a”.
Итак, КОИ-8 позволяет сохранять читаемость русского текста при потере 8-го бита. “Привет всем” превращается в “pRIWET WSEM”.
В последнее время и алфавитный порядок расположения символов в таблице кодировки, и читаемость при потере 8-го бита потеряли решающее значение. Восьмой бит в современных компьютерах не теряется ни при передаче, ни при обработке. А сортировка по алфавиту производится с учётом кодировки, а не простым сравнением кодов. (Кстати, коды CP 1251 расположены не полностью по алфавиту – буква Ё не находится на своём месте).
Из-за того, что распространённых кодировок оказалось две, при работе с Интернетом (почта, просмотр Web-сайтов) иногда можно вместо русского текста увидеть бессмысленный набор букв. Например, “Я СБЮФЕМХЕЛ”. Это всего лишь слова “с уважением”; но они были закодированы в кодировке CP1251, а компьютер декодировал текст по таблице КОИ-8. Если те же слова были, наоборот, закодированы в КОИ-8, а компьютер декодировал текст по таблице CP1251, результатом будет “У ХЧБЦЕОЙЕН”.
Иногда бывает, что компьютер расшифровывает русскоязычные письма и вовсе по таблице, не предназначенной для русского языка. Тогда вместо русских букв появляются бессмысленный набор символов (например, латинские буквы восточно-европейских языков); их часто называют “крокозябрами”.
В большинстве случаев современные программы справляются с определением кодировок документов Интернета (электронных писем и Web-страниц) самостоятельно. Но иногда они “дают осечку”, и тогда можно увидеть странные последовательности русских букв или же “крокозябры”. Как правило, чтобы в такой ситуации вывести на экран настоящий текст, достаточно выбрать кодировку вручную в меню программы.
Приложения
Кодировки Windows-1251, KOI8-R и ISO 8859-5
ASCII (American Standard Code for Information Interchange) — одна из самых старых компьютерных кодировок, в которой каждому символу соответствует строго определенное число. Например, символу «a» соответствует число 97, а символу «A» — число 65.
Всего в стандартной кодировке ASCII определено 256 символов, из которых первые 128 приходятся на символы латинского алфавита, а последующие — на умляуты и символы для создания псевдографических изображений.
Именно символы, занимающие позиции 128-255, в эпоху MS-DOS заменялись на символы кириллицы. Так возникли вариации стандартной кодировки ASCII, получившие названия KOI8-R (долгое время считалась стандартной русскоязычной кодировкой де-факто), DOS CP-866 (использовалась в русскоязычных версиях операционной системы MS-DOS), ISO 8859-5 (стандарт ISO, который практически нигде не используется), Macintosh Cyrillic (поддержка кириллицы для компьютеров Apple) и т. д.
Все эти кодировки присваивали разные численные обозначения одному и тому же символу кириллицы, из-за чего были частично или полностью несовместимы между собой.
В настоящее время проблема множества несовместимых кодировок практически решена путем постепенного вытеснения всех прочих кодировок стандартной кодировкой MS Windows, носящей название Windows 1251. Кроме того, постепенно происходит переход к стандартной двухбайтовой кодировке UTF-8 (Unicode), в которую изначально включены все символы не только латиницы и кириллицы, но и множества других алфавитов.
Что такое кодировки?
Unicode и история развития кодировок
Содержание
Почему кодировки — это важно?
Компьютеры постоянно работают с текстами: это ленты новостных сайтов, фондовые биржи, сообщения в социальных сетях и мессенджерах, банковские приложения и многое другое. Сегодня мы не можем представить жизнь без передачи информации. Но так было не всегда. Компьютеры научились работать с текстом благодаря появлению кодировок. Кодировки прошли большой путь от таблиц символов, созданных отдельно для каждого компьютера, до единой кодировки, принятой во всём мире.
Сейчас Unicode — это основной стандарт кодирования символов, включающий в себя знаки почти всех письменных языков мира. Unicode применяется везде, где есть текст. Информация на страницах в социальных сетях, записи в базах данных, компьютерные программы и мобильные приложения — всё это работает с использованием Unicode.
В этом гайде мы рассмотрим, как появился Unicode и какие проблемы он решает. Узнаем, как хранилась и передавалась информация до введения единого стандарта кодирования символов, а также рассмотрим примеры кодировок, основанных на Unicode.
Предпосылки появления кодировок
Исторически компьютер создавался как машина для ускорения и автоматизации вычислений. Само слово computer с английского можно перевести как вычислитель, а в 20 веке в СССР, до распространения термина компьютер, использовалась аббревиатура ЭВМ — электронно вычислительная машина.
Всё, чем компьютеры оперировали — числа. Основным заказчиком и драйвером появления первых моделей были оборонные предприятия. На компьютерах проводили расчёты параметров полёта баллистических ракет, самолётов, спутников. В 1950-е годы вычислительные мощности компьютеров стали использовать для:
- прогноза погоды;
- вычислений экспериментальной и теоретической физики;
- расчета заработной платы сотрудников (например, компьютер LEO применялся для нужд компании, владеющей сетью чайных магазинов);
- прогнозирование результатов выборов президента США (1952 год, компьютер UNIVAC).
Компьютеры и числа
Цели, для которых разрабатывались компьютеры, привели к появлению архитектуры, предназначенной для работы с числами. Они хранятся в компьютере следующим образом:
- Число из десятичной системы счисления переводится в двоичную, т.е. набор нулей и единиц. Например, 3 в двоичной системе счисления можно записать в виде 11, а 9 как 1001. Подробнее о системах счисления читайте в соответствующем гайде.
- Полученный набор нулей и единиц хранится в ячейках памяти компьютера. Например, наличие тока на элементе памяти означает единицу, его отсутствие — ноль.

В конце 1950-х годов происходит замена ламп накаливания на полупроводниковые элементы (транзисторы и диоды). Внедрение новой технологии позволило уменьшить размеры компьютеров, увеличить скорость работы и надёжность вычислений, а также повлияло на конечную стоимость. Если первые компьютеры были дорогостоящими штучными проектами, которые могли себе позволить только государства или крупные компании, то с применением полупроводников начали появляться серийные компьютеры, пусть даже и не персональные.
Компьютеры и символы
Постепенно компьютеры начинают применяться для решения не только вычислительных или математических задач. Возникает необходимость обработки текстовой информации, но с буквами и другими символами ситуация обстоит сложнее, чем с числами. Символы — это визуальный объект. Даже одна и та же буква «а» может быть представлена двумя различными символами «а» и «А» в зависимости от регистра.
Также число «один» можно представить в виде различных символов. Это может быть арабская цифра 1 или римская цифра I. Значение числа не меняется, но символы используются разные.
Компьютеры создавались для работы с числами, они не могут хранить символы. При вводе информации в компьютер символы преобразуются в числа и хранятся в памяти компьютера как обычные числа, а при выводе информации происходит обратное преобразование из чисел в символы.
Правила преобразования символов и чисел хранились в виде таблицы символов (англ. charset). В соответствии с такой таблицей для каждого компьютера конструировали и своё уникальное устройство ввода/вывода информации (например, клавиатура и принтер).

Распространение компьютеров
В начале 1960-х годов компьютеры были несовместимы друг с другом даже в рамках одной компании-производителя. Например, в компании IBM насчитывалось около 20 конструкторских бюро, и каждое разрабатывало свою собственную модель. Такие компьютеры не были универсальными, они создавались для решения конкретных задач. Для каждой решаемой задачи формировалась необходимая таблица символов, и проектировались устройства ввода/вывода информации.
В этот период начинают формироваться сети, соединяющие в себе несколько компьютеров. Так, в 1958 году создали систему SAGE (Semi-Automatic Ground Environment), объединившую радарные станций США и Канады в первую крупномасштабную компьютерную сеть. При этом, чтобы результаты вычислений одних компьютеров можно было использовать на других компьютерах сети, они должны были обладать одинаковыми таблицами символов.
В 1962 году компания IBM формирует два главных принципа для развития собственной линейки компьютеров:
- Компьютеры должны стать универсальными. Это означало переход от производства узкоспециализированных компьютеров к машинам, которые могут решать разные задачи.
- Компьютеры должны стать совместимыми друг с другом, то есть должна быть возможность использовать данные с одного компьютера на другом.
Так в 1965 году появились компьютеры IBM System/360. Это была линейка из шести моделей, состоящих из совместимых модулей. Модели различались по производительности и стоимости, что позволило заказчикам гибко подходить к выбору компьютера. Модульность систем привела к появлению новой отрасли — производству совместимых с System/360 вычислительных модулей. У компаний не было необходимости производить компьютер целиком, они могли выходить на рынок с отдельными совместимыми модулями. Всё это привело к ещё большему распространению компьютеров.
ASCII как первый стандарт кодирования информации
Телетайп и терминал
Параллельно с этим развивались телетайпы. Телетайп — это система передачи текстовой информации на расстоянии. Два принтера и две клавиатуры (на самом деле электромеханические печатные машинки) попарно соединялись друг с другом проводами. Текст, набранный на клавиатуре у первого пользователя, печатается на принтере у второго пользователя и наоборот. Таким образом, например, была организована «горячая линия» между президентом США и руководством СССР вплоть до начала 1970-х годов.
Телетайпы также преобразуют текстовую информацию в некоторые сигналы, которые передаются по проводам. При этом не всегда используется бинарный код, например, в азбуке Морзе используются 3 символа — точка, тире и пауза. Для телетайпов необходимы таблицы символов, соответствие в которых строится между символами и сигналами в проводах. При этом для каждого телетайпа (пары, соединённых телетайпов) таблицы символов могли быть свои, исходя из задач, которые они решали. Отличаться, например, мог язык, а значит и сам набор символов, который отправлялся с помощью устройства. Для оптимизации работы телетайпа самые популярные (часто встречающиеся) символы кодировались наиболее коротким набором сигналов, а значит и в рамках одного языка, набор символов мог быть разным.
На основе телетайпов разработали терминалы доступа к компьютерам. Такой телетайп отправлял сообщения не второму пользователю, а информация вводилась на некоторый удалённый компьютер, который после обработки указанных команд, возвращал результат в виде ответного сообщения. Это нововведение позволило использовать тогда ещё очень дорогие вычислительные мощности компьютеров, не имея физического доступа к самому компьютеру. Например, компьютер мог размещаться в отдельном вычислительном центре корпорации или института, а сотрудники из других филиалов или городов получали доступ к вычислительным мощностями компьютера посредством установленных у них терминалов.
ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году. Таблицу из 128 символов назвали ASCII — American standard code for information interchange (Американский стандарт кодов для обмена информацией).

Первые 32 символа в ASCII являются управляющими. Они использовались для того, чтобы, например, управлять печатающим устройством телетайпа и получать некоторые составные символы. Например:
- символ Ø можно было получить так: печатаем O, затем с помощью управляющего кода BS (BackSpace) передвигаем печатную головку на один символ назад и печатаем символ /,
- символ à получался как a BS `
- символ Ç получался как C BS ,
Введение управляющих символов позволяло получать новые символы как комбинацию существующих, не вводя дополнительные таблицы символов.
Однако введение стандарта ASCII решило вопрос только в англоговорящих странах. В странах с другой письменностью, например, с кириллической в СССР, проблема оставалась.
Кодировки для других языков
В течение более чем 20 лет вопрос решали введением собственных локальных стандартов, например, в СССР на основе таблицы ASCII разработали собственные варианты кодировок КОИ 7 и КОИ 8, где 7 и 8 указывают на количество бит, необходимых для кодирования одного символа, а КОИ расшифровывается как Коды Обмена Информацией.
С дальнейшим развитием систем начали использовать восьмибитные кодировки. Это позволило использовать наборы, содержащие по 256 символов. Достаточно распространён был подход, при котором первые 128 символов брали из стандарта ASCII, а оставшиеся 128 дополнялись собственными символами. Такое решение, в частности, было использовано в кодировке KOI 8.
Однако единым стандартом указанные кодировки так и не стали. Например, в MS-DOS для русских локализаций использовалась кодировка cp866, а далее в среде MS Windows стали использоваться кодировки cp1251. Для греческого языка применялись кодировки cp851 и cp1253. В результате документы, подготовленные с использованием старой кодировки, становились нечитаемыми на новых.
Свои кодировки необходимы и для других стран с уникальным набором символов. Это приводило к путанице и сложностям в обмене информацией. Ниже приведён пример текста, который написали в кодировке KOI8-R, а читают в cp851.
| KOI8-R | cp851 |
|---|---|
| English text. | English text. |
| Это — русский текст :-). | ΰΨΣ — ΦΩΧΧ╦╔╩ Ψ┼╦ΧΨ :-). |

Обе кодировки основаны на стандарте ASCII, поэтому знаки препинания и буквы английского алфавита в обеих кодировках выглядят одинаково. Кириллический текст при этом становится совершенно нечитаемым.
При этом компьютерная память была дорогой, а связь между компьютерами медленной. Поэтому выгоднее было использовать кодировки, в которых размер в битах каждого символа был небольшим. Таблица символов состоит из 256 символов. Это значит, что нам достаточно 8 бит для кодирования любого из них (2^8 = 256).
Переход к Unicode
Развитие интернета, увеличение количества компьютеров и удешевление памяти привели к тому, что проблемы, которые доставляла путаница в кодировках, стали перевешивать некоторую экономию памяти. Особенно ярко это проявлялось в интернете, когда текст написанный на одном компьютере должен был корректно отображаться на многих других устройствах. Это доставляло огромные проблемы как программистам, которые должны были решать какую кодировку использовать, так и конечным пользователям, которые не могли получить доступ к интересующим их текстам.
В результате в октябре 1991 года появилась первая версия одной общей таблицы символов, названной Unicode. Она включала в себя на тот момент 7161 различный символ из 24 письменностей мира.
В Unicode постепенно добавлялись новые языки и символы. Например, в версию 1.0.1 в середине 1992 года добавили более 20 000 идеограмм китайского, японского и корейского языков. В актуальной на текущий момент версии содержится уже более 143 000 символов.
Кодировки на основе Unicode
Unicode можно себе представить как огромную таблицу символов. В памяти компьютера записываются не сами символы, а номера из таблицы. Записывать их можно разными способами. Именно для этого на основе Unicode разработаны несколько кодировок, которые отличаются способом записи номера символа Unicode в виде набора байт. Они называются UTF — Unicode Transformation Format. Есть кодировки постоянной длины, например, UTF-32, в которой номер любого символа из таблицы Unicode занимает ровно 4 байта. Однако наибольшую популярность получила UTF-8 — кодировка с переменным числом байт. Она позволяет кодировать символы так, что наиболее распространённые символы занимают 1-2 байта, и только редко встречающиеся символы могут использовать по 4 байта. Например, все символы таблицы ASCII занимают ровно по одному байту, поэтому текст, написанный на английском языке с использованием кодировки UTF-8, будет занимать столько же места, как и текст, написанный с использованием таблицы символов ASCII.
На сегодняшний день Unicode является основной кодировкой, которую используют в работе все, кто связан с компьютерами и текстами. Unicode позволяет использовать сотни тысяч различных символов и отображать их одинаково на всех устройствах от мобильных телефонов до компьютеров на космических станциях.



