- Отличие utf-8 и windows 1251
- О разнице между двумя кодировками utf-8 и windows 1251
- О кодировках utf-8 и windows 1251
- Чем отличаются utf-8 и windows 1251
- Что такое кодировка windows 1251
- Что такое кодировка UTF-8
- Пример вывода текста в кодировках utf-8 латиницы
- Чем отличается текст в кодировках utf-8 и windows 1251
- Пример вывода текста в кодировках utf-8 кириллицы
- Пример отличия в кодировках utf-8 и windows 1251
- Что делать, если функция для кириллицы на utf-8 не работают?
- Кодировки UTF-8 и Windows 1251 — просто о сложном
- Немного теории
- Недостатки и достоинства
- Базы банных
- Htaccess
- Какая кодировка лучше UTF-8 или cp1251
- Содержание
- Введение
- Страхи перед UTF-8
- Неоспоримые плюсы UTF-8
- Ответы на частые вопросы и заблуждения по кодировкам
- У меня сайт только на русском языке и на всякие китайские языки я переходить не намерен
- Терминалы не поддерживают utf-8 (ssh, ssl, terminal)
- Постоянная проблемы с BOM заголовком
- Постоянный геморрой в PHP с использованием функций mb_
- Если у меня старый проект на cp1251 работает стабильно, нужно ли переносить на UTF?
- UTF это бред, так как мой редактор его не поддерживает
- Все браузеры по умолчанию настроены на cp1251
- В cp1251 одна буква, так одна буква, а в юникоде это xAB и uABCD
- Написал charset utf-8 сайт все равно открывается в cp1251
- Вывод
- Дополнительная информация по теме
Отличие utf-8 и windows 1251
Поддержи проект. 
Отличие utf-8 и windows 1251. Рассмотрим, чем отличаются две кодировки «utf-8 и windows 1251» в теории и на практике. И как победить некоторые проблемы для кириллицы в utf-8!?
О разнице между двумя кодировками utf-8 и windows 1251
О кодировках utf-8 и windows 1251
Самое главное. что нас интересует, как и меня — в чем же отличие кодировок utf-8 и windows 1251. И отличается только кириллица!
Чем отличаются utf-8 и windows 1251
UTF-8 — это много-байтовая кодировка, а Windows- 1251 однобайтовая. И более того, отличие только в кириллице.
Количество байтов кириллицы в UTF-8 будет в 2 раза больше, чем 1). латиницы в UTF-8 и 2). латиницы + кириллицы в Windows- 1251 → пример
Главное отличие кодировок – это используемый набор символов. В UTF-8 гораздо больше количество символов возможно представить, чем в Windows- 1251. Кодировка Windows- 1251 однобайтовая, т.е. представить в ней можно только 255 символов. Для кириллицы, впрочем, этого вполне достаточно, именно поэтому однобайтовые кодировки до сих пор так массово применяются.
Что такое кодировка windows 1251
Windows-1251 – набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Пользуется довольно большой популярностью. Windows-1251 выгодно отличается от других 8‑битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста; она также содержит все символы для близких к русскому языку языков: украинского, белорусского, сербского и болгарского.
Что такое кодировка UTF-8
UTF-8 – в настоящее время распространённая кодировка, реализующая представление Юникода, совместимое с 8-битным кодированием текста. Нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт.
Символ в кодировке UTF-8 может кодироваться аж 6 байтами (пока используется только 4 и больше не планируется). Для русского языка, например, символ занимает 2 байта. Все символы, которые есть в таблице символов – поддерживаются этой кодировкой. К примеру, если вам нужен знак копирайта (©), то вам не нужно искать особый шрифт или же изображать символов в графическом формате.
Пример вывода текста в кодировках utf-8 латиницы
А если вы еще и поняли о чем идет речь, то вы вообще Эйнштейн!  , то и смысла особого вам читать дальше нет.
, то и смысла особого вам читать дальше нет.
А для всех остальных продолжим.
Чем отличается текст в кодировках utf-8 и windows 1251
Теория — это конечно классно и круто, но как обстоит дело на практике!
Как показать отличие двух кодировок!?
У нас на сайте основная кодировка utf-8, и мы не напрягаясь можем посмотреть, что творится с текстом в этой кодировке!
Нам понадобится какой-то текст на латинице:
И. нам нужно такое слово, чтобы имело одинаковое количество букв в слове, ну пусть это будет моё имя.
Пусть это будет слово — «Marat!»
Далее нам потребуется функция var_dump.
И выведем прямо здесь вот такую конструкцию :
Что мы здесь можем прочитать!?
Что это строка, и что в ней 5 элементов.
Пример вывода текста в кодировках utf-8 кириллицы
Теперь, проделаем тоже самое со строкой на кириллице:
У нас все таже кодировка utf-8.
Но теперь нам понадобится текст на кириллице:
Пусть это будет слово — «Марат!»
И выведем прямо здесь вот такую конструкцию :
И что мы здесь видим!?
Что количество элементов в строке 10. Если вы читали теорию внимательно, то вот вам показатель того, что одна буква состоит из двух символов, а латиницы это не касается.
Поэтому, и возникают проблемы с текстов в кодировке utf-8 кириллицы, множество функций тупо не работают.
Как пример. как-то я задолбался со strtolower в utf-8 для кириллицы, что решил написать собственную функцию strtolower, чтобы каждый раз не городить этажерку из нескольких функций.
Пример отличия в кодировках utf-8 и windows 1251
Если вы поленились прочитать два верхних пункта, то ещё раз выведем результаты вывода текста на латинице и на кириллице с одним количеством букв.
Результат вывода var_dump(‘Marat’); :
string(5) «Marat»
Результат var_dump(‘Марат’); :
string(10) «Марат»
Что делать, если функция для кириллицы на utf-8 не работают?
Поскольку я давно занимаюсь сайтами, то могу сказать, что на самом деле таких случаев не так много, когда нужна какая-то специальная функция для обработки кириллицы на utf-8.
Но если уж она возникала, то есть несколько вариантов решения!
Это функции с приставкой «mb_», естественно надо проверять, работает ли она у вас на хостинге.
Второй вариант, это написать собственную функцию, которая будет работать и для латиницы и кириллицы? как это я показал на функции strtolower
Пусть это будет функция str_split и её аналог mb_str_split
Кодировки UTF-8 и Windows 1251 — просто о сложном

Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
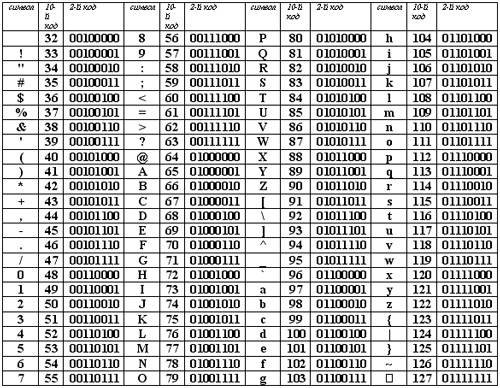
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
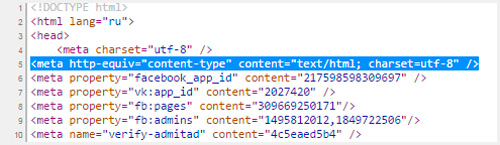
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
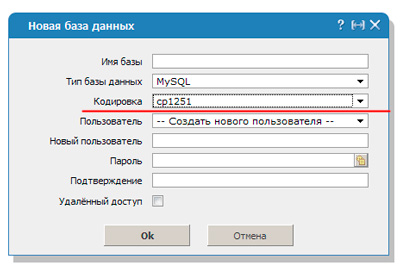
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251»
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.
Какая кодировка лучше UTF-8 или cp1251
Содержание
Введение
Читая на просторах интернета споры про кодировки UTF-8 и cp1251 решил подытожить и всю муть изложить коротко.
Сразу и смело можно перефразировать вопрос и знающие люди поймут. UTF или не UTF? То есть, я за UTF-8 — однозначно!
Страхи перед UTF-8
- Не поддержка старых (рабочих) проектов кодировки UTF-8. (Давайте еще ДОС вспомним). Ориентироваться на старые продукты, считаю полностью утопично.
- Один символ кириллицы в cp1251 занимает 1 байт, а в utf-8 — 2 байта. Как ни странно данный факт сильно отталкивает, и отталкивал меня долгое время от начало использования данной кодировки. Как показала практика в среднем UTF страница на русском языке больше, чем стандартная cp1251 всего на 20-30 процентов. Если текст на английском, то страница одинакового размера. Чаще всего — основной вес страницы составляет HTML код, JavaScript, Flash, картинки, CSS и так далее. Тем, кто заботится о «весе», следовало бы в первую очередь выкинуть из кода подстановки для тех символов, которым они не нужны, например, «- » для длинного тире или для неразрывного пробела (ой, как часто я вижу это в страницах новичков). Видим, что вместо 1 знака длинного тире мы пишем 6, вместо 1 знака неразрывного пробела мы пишем 5 знаков. И где же экономия? Действительно, иногда доходит до маразма — некто упирается: «Не буду делать страницы в UTF-8, потому что они от этого увеличиваются» — а сам при этом ваяет код с жуткими атрибутами и подстановками, который без них мог бы быть в пять раз короче. Также у 90 процентов WEB программистов HTML страницы просто не оптимизированы, даже пробелы не убраны из кода. А пробел это тоже байтик!
- отображения крокозябликов в любимых стареньких программах, таких как Far. Не знаю почему, но far так не сумел приучить читать корректно данную кодировку даже в последнем beta релизе Far 2.0.
Неоспоримые плюсы UTF-8
- старые кодировки, таких как cp1251 или KOI8R, предоставляли не более 256 символов, а в Unicode есть свыше 100 000 символов, среди них — типографские знаки (тире, кавычки, многоточие, апостроф, неразрывный пробел неразрывный дефис и прочие прикольные символы);
- специальные символы №, §, ©, ‰, «», …, × и прочее. Например, это очень актуально на сайтах с кулинарной тематикой, где употребляются различные дробные меры такие как ½, ⅓, ¼, ⅔, ¾ и так далее. А как же быть с финансовой тематикой? Сейчас сложно представить нормальный сайт, где бы не указывался значки валют в ценниках, например, ȼ ¥ £ €. Повторите тоже самое на cp1251 или будете целые картинки подгружать вместо одного символа?
- буквы с диакритическими знаками и лигатуры (é, è, Ü, Æ, ø, fi и прочее);
- символы почти всех существующих в мире алфавитов (α, Ω, א, ת,, 伲, 儻 и прочее);
- пиктограммы и значки (→, ■, ♥, ☺ и прочее);
- множество других полезных символов.
Самое классное в этом всем это то, что все эти символы можно вставлять непосредственно в редакторе (из таблицы символов или с помощью горячих клавиш), что делает код куда более читабельным, нежели использование кракозяб вроде µ — или π (альтернативы в cp1251).
- Универсальность! Благодаря utf-8 можно создавать сайты без каких-либо переделок как для американцев, так и для немцев (с их буквочками вроде Ü), так и для арабов, так и для китайцев! И все равно, какая кодировка у них установлена, а какая нет, ибо Юникод у них установлен 100 процентов. Например, если у вас сайт публикует новости сразу на русском и немецком языке, то эту UTF с этим легко справляется, а вот уже на cp1251 это сделать невозможно.
- Юникод является стандартом для работы таких часто используемых ныне функций PHP , как json_encode/json_decode, а так же используемого в AJAX XHttpRequest. Причем, начиная с 6й версии PHP Юникод станет стандартом для всех строковых функций. Поэтому на много быстрее и удобнее скармливать данные уже в UTF кодировке а не конвертировать постоянно, потому как все равно функции PHP и JavaScript будут это требовать. То есть, если вы хотите работать с такими технологиями как XML, JSON, AJAX и прочие современные технологии, то вам придется переходить на UTF-8, ибо со времен своего основания они работают только в этой кодировке.
- Поисковые системы значительно лучше относятся к сайтам на UTF-8 кодировке, чем на какой-либо другой. Многие скажут, что это спорный момент, однако проводился эксперимент, на 10 сайтах. Один и тот же контент, тот же дизайн, тот же хостер, разные были только кодировки. Не поверите, но сайт на UTF кодировке стоял выше в поисковых позициях. Вот такой вот фокус.
- Для быстрой индексации сайта в поисковых системах Yandex и Google используется файлик sitemap.xml, как ни странно, но работает он только если сделан в UTF, иначе поисковые системы ругаются.
- И напоследок, многие ссылаются на то, что люди постепенно переходят на utf-8 потому, что «кто-то умный сказал, что это хорошо». Соглашусь, кто-то умный это сказал уже давно, а именно — Консорциум W3C (кому-то эти 3 буквы что-то говорят? И рекомендует он использовать для создания WEB страниц ни что иное, как utf-8. Для тех, кто знает английский (а есть программисты, кто его не знает? Можете почитать.
Ответы на частые вопросы и заблуждения по кодировкам
У меня сайт только на русском языке и на всякие китайские языки я переходить не намерен
Очень интересное заблуждение. Если у Вас один проект, то тут соглашусь, что особо не стоит заморачиваться на эту тему. Если проектов много то уже очень скоро столкнетесь с проблемами. Ведь UTF это не только разные языки, но и как я уже говорил, это довольно сложные математические функции и многое другое 🙂 А математика есть в любом языке, в том числе и на русском.
Терминалы не поддерживают utf-8 (ssh, ssl, terminal)
Какой бред. Я вам ответственно заявляю, как программист, что все терминалы не испытывают никаких проблем с utf, да им это особо и не требуется, так как в основном они пишут все на английском языке.
Постоянная проблемы с BOM заголовком
Никаких проблем вообще не возникает. Напомню, что BOM заголовок в текстовых документах был придумал как дополнение, чтобы по быстрому определяться и в дальнейшем определять в какой кодировке записан текстовой документ. BOM заголовок это принятый стандарт, если вы программист, то научитесь обрабатывать грамотно всего три байта. Если вы профи, то я думаю вы справитесь с этой «мега» задачей в три байта. Если Вы обычный пользователь, то не заморачивайтесь на счет этого заголовка, просто его не прописывайте.
Постоянный геморрой в PHP с использованием функций mb_
1. Если у вас вызывает неприятность функции в добавлением всего 2 буковок, может программирование не ваш конек?
2. В PHP 5.0 обычные функции strpos и подобные легко и прекрасно работают с кодировкой UTF. Смотрите подробнее init_charset в PHP. Есть ряд переключателей которые легко переключают весь PHP движок на работу с нужной кодировкой по умолчанию.
3. В PHP 6.0, как я уже говорил (смотрите официальный сайт PHP) UTF-8 будет кодировкой по умолчанию. Вам нужен лишний геморрой в дальнейшем при переносе проектов? В свое время тоже все считали, что PHP 3.0 удовлетворяет всем потребностям, но не заметили как уже докатились до PHP 5.0.
4. JavaScript с самого момента своего создания работал только с кодировкой UTF. Все, что вы видите на JS в cp1251 это метаморфозы на уровне ядра. Об этом можете легко прочитать на официальном сайте JavaScript на Sun Мастерс.
5. Основная в базах данных также по умолчанию теперь только UTF-8. Смотрите и читайте соответствующие спецификации.
Если у меня старый проект на cp1251 работает стабильно, нужно ли переносить на UTF?
Если рассуждать рационально, то нет. Но если вы в дальнейшем планируете свой старый проект еще перерабатывать и дополнять новыми функциями, то стоит обдумать, но перед этим 1000 раз все взвешать.
UTF это бред, так как мой редактор его не поддерживает
Ваш редактор не пуп земли. И если у вас есть такой редактор, который не поддерживает данной кодировки, то это уже бездарность. Напомню, что начиная с выпуска Windows XP даже пресловутый Windows блокнот знает и корректно открывает текстовые документы в UTF кодировке. А также начиная с системы Windows Vista кодировка UTF считается кодировкой по умолчанию. Не питайте иллюзий, что Windows до сих пор сидит на своей родной кодировке cp1251. Это было сделано только для поддержки старых программ не более. Рекомендую по чаще заходить на сайт Microsoft и интересоваться ихними направлениями развития и технологиями. Откроете для себя много интересного, а главное, ваши знания будут уже не на уровне только слухов.
Все браузеры по умолчанию настроены на cp1251
Мда, как тут все запущено. В любом браузере есть галочка, авто определение кодировки. Какой тег на странице у вас будет прописан такую кодировку и будет браузер применять по умолчанию. Напоминаю код который управляет кодировкой на странице:
В cp1251 одна буква, так одна буква, а в юникоде это xAB и uABCD
Ребята, не нужно путать теплое с мягким. А именно не нужно путать отображение и фактическим состоянием. То есть, UTF он как шифровался в 1-2 байт так и шифруется (UTF-16 не беру в данном случае в расчет), а отображается может хоть как. Как говорится на заборе тоже написано «…», но за забором то картошка. Не плохо было бы иногда все таки заглядывать за забор.
Это все к тому, что та же единица (1) может отображаться как:
- 00000001 — двоичная система
- 01 — шестнадцатеричная система счисления
- 1 — десятичная
и так далее. Здесь тоже самое.
Написал charset utf-8 сайт все равно открывается в cp1251
Вариантов может быть много, но есть частые ошибки.
1. Неправильно прописан meta http-equiv. Нужно писать charset=utf-8, у многих charset=utf8. Как ни странно, но тире играет большую роль почему то.
2. Прописав charset=utf-8 в мета, требуется еще и саму страницу конвертировать в эту кодировку, но многие считают, что типа этого делать не нужно.
3. Проблема при выводе информации из базы данных MySQL при помощи PHP. Более детально эта, ошибка расписана в статье «Как вывести данные в PHP из таблицы MySQL?»
Вот коротко ответил на самые частые утверждения, вопросы и заблуждения. По мере поступления буду дополнять и отвечать здесь.
Вывод
Люди утверждающие, что cp1251 лучше, чем UTF-8, это как те аборигены, которые в свое время считали, что земля плоская и человек есть пуп земли. А именно у таких людей преобладает лень к стремлению к новым вершинам, или тяжело ломать старые стереотипы, или тупо, боязнь того что, как это у других может быть лучше, чем у меня, нет уж если я в дерьме, то и новички тоже пускай в дерьме сидят, а то одному то скучно 😉 Ээх человечество.
Дополнительная информация по теме
Описание основной разницы между кавычками, а также наглядные примеры разницы в скорости работы при употреблении разных кавычек
Сравнительный рейтинг мониторов различных классов с актуальностью на начало 2015 года
В статье составлен рейтинг лучших кофеварок для дома, описаны все достоинства и недостатки представленных моделей, на основе чего и выбрана лучшая кофеварка
Статья о положении дел на рынке мониторов, рейтинге мониторов на начало 2015 года, о смене старых технологий на новые



