- Кодировка windows 1251 таблица с двоичными кодами
- Таблица кодов кириллицы в Unicode, UTF-8 и Windows-1251
- Таблицы кодировок ASCII, CP1251 (windows1251), ISO-8859-5
- Таблица ASCII
- Таблица CP1251 (windows-1251)
- Таблица IS0-8859-5
- Кодировка UTF-8 (Unicode Transformation Format)
- Кодировки UTF-8 и Windows 1251 — просто о сложном
- Немного теории
- Недостатки и достоинства
- Базы банных
- Htaccess
Кодировка windows 1251 таблица с двоичными кодами
БлогNot. Таблица кодов кириллицы в Unicode, UTF-8 и Windows-1251
Таблица кодов кириллицы в Unicode, UTF-8 и Windows-1251
Во-первых, напомню, что Юникод — не кодировка, а стандарт кодирования, кодировки — это UTF-8, UTF-16 и т.д., но, в силу инерции, разработчики и пользователи часто говорят о «кодировке Юникод», имея в виду распространённую именно в их деревне форму представления символов 🙂
Во-вторых, на самом деле кодирование там довольно замудрённое, возьмём, скажем русскую заглавную «Ж».
Представляемые в Юникоде символы кодируются целыми числами без знака, их можно называть «кодами символов Unicode».
Так, для буквы «Ж» Unicode = 104610 или 041616 или 10000 0101102. Unicode в двоичном виде разбивается на две части: пять левых бит и шесть правых. Левая часть в старших разрядах дополняется до байта признаком 110 двухбайтного кода UTF-8, получаем 11010000. К правой части в старших разрядах приписываются два бита 10 признака продолжения многобайтного кода, получаем 10010110. Окончательно код буквы «Ж» в UTF-8 будет иметь вид 11010000 100101102 или D0 9616.
Именно последний код мы увидим в любом 16-ричном вьюере файла, например, создав в текстовом редакторе файл со словом «Жора» и сохранив его в UTF-8 (только не из Блокнотика Windows, который добавит в начало файла 3-байтовую метку BOM):
То есть, каждая буква кодируется как бы дважды, сначала в 11-битный Unicode, затем в 16-битный UTF-8.
Ниже приведена таблица кодов кириллицы в Unicode, UTF-8 и однобайтовой кодировке Windows-1251.
| Символ | Unicode | UTF-8 | Windows-1251 | ||
|---|---|---|---|---|---|
| 16-ричн. | 10-тичн. | 16-ричн. | 10-тичн. | ||
| А | 0410 | 1040 | D090 | 208 144 | 192 |
| Б | 0411 | 1041 | D091 | 208 145 | 193 |
| В | 0412 | 1042 | D092 | 208 146 | 194 |
| Г | 0413 | 1043 | D093 | 208 147 | 195 |
| Д | 0414 | 1044 | D094 | 208 148 | 196 |
| Е | 0415 | 1045 | D095 | 208 149 | 197 |
| Ж | 0416 | 1046 | D096 | 208 150 | 198 |
| З | 0417 | 1047 | D097 | 208 151 | 199 |
| И | 0418 | 1048 | D098 | 208 152 | 200 |
| Й | 0419 | 1049 | D099 | 208 153 | 201 |
| К | 041A | 1050 | D09A | 208 154 | 202 |
| Л | 041B | 1051 | D09B | 208 155 | 203 |
| М | 041C | 1052 | D09C | 208 156 | 204 |
| Н | 041D | 1053 | D09D | 208 157 | 205 |
| О | 041E | 1054 | D09E | 208 158 | 206 |
| П | 041F | 1055 | D09F | 208 159 | 207 |
| Р | 0420 | 1056 | D0A0 | 208 160 | 208 |
| С | 0421 | 1057 | D0A1 | 208 161 | 209 |
| Т | 0422 | 1058 | D0A2 | 208 162 | 210 |
| У | 0423 | 1059 | D0A3 | 208 163 | 211 |
| Ф | 0424 | 1060 | D0A4 | 208 164 | 212 |
| Х | 0425 | 1061 | D0A5 | 208 165 | 213 |
| Ц | 0426 | 1062 | D0A6 | 208 166 | 214 |
| Ч | 0427 | 1063 | D0A7 | 208 167 | 215 |
| Ш | 0428 | 1064 | D0A8 | 208 168 | 216 |
| Щ | 0429 | 1065 | D0A9 | 208 169 | 217 |
| Ъ | 042A | 1066 | D0AA | 208 170 | 218 |
| Ы | 042B | 1067 | D0AB | 208 171 | 219 |
| Ь | 042C | 1068 | D0AC | 208 172 | 220 |
| Э | 042D | 1069 | D0AD | 208 173 | 221 |
| Ю | 042E | 1070 | D0AE | 208 174 | 222 |
| Я | 042F | 1071 | D0AF | 208 175 | 223 |
| а | 0430 | 1072 | D0B0 | 208 176 | 224 |
| б | 0431 | 1073 | D0B1 | 208 177 | 225 |
| в | 0432 | 1074 | D0B2 | 208 178 | 226 |
| г | 0433 | 1075 | D0B3 | 208 179 | 227 |
| д | 0434 | 1076 | D0B4 | 208 180 | 228 |
| е | 0435 | 1077 | D0B5 | 208 181 | 229 |
| ж | 0436 | 1078 | D0B6 | 208 182 | 230 |
| з | 0437 | 1079 | D0B7 | 208 183 | 231 |
| и | 0438 | 1080 | D0B8 | 208 184 | 232 |
| й | 0439 | 1081 | D0B9 | 208 185 | 233 |
| к | 043A | 1082 | D0BA | 208 186 | 234 |
| л | 043B | 1083 | D0BB | 208 187 | 235 |
| м | 043C | 1084 | D0BC | 208 188 | 236 |
| н | 043D | 1085 | D0BD | 208 189 | 237 |
| о | 043E | 1086 | D0BE | 208 190 | 238 |
| п | 043F | 1087 | D0BF | 208 191 | 239 |
| р | 0440 | 1088 | D180 | 209 128 | 240 |
| с | 0441 | 1089 | D181 | 209 129 | 241 |
| т | 0442 | 1090 | D182 | 209 130 | 242 |
| у | 0443 | 1091 | D183 | 209 131 | 243 |
| ф | 0444 | 1092 | D184 | 209 132 | 244 |
| х | 0445 | 1093 | D185 | 209 133 | 245 |
| ц | 0446 | 1094 | D186 | 209 134 | 246 |
| ч | 0447 | 1095 | D187 | 209 135 | 247 |
| ш | 0448 | 1096 | D188 | 209 136 | 248 |
| щ | 0449 | 1097 | D189 | 209 137 | 249 |
| ъ | 044A | 1098 | D18A | 209 138 | 250 |
| ы | 044B | 1099 | D18B | 209 139 | 251 |
| ь | 044C | 1100 | D18C | 209 140 | 252 |
| э | 044D | 1101 | D18D | 209 141 | 253 |
| ю | 044E | 1102 | D18E | 209 142 | 254 |
| я | 044F | 1103 | D18F | 209 143 | 255 |
| Символы вне общего правила | |||||
| Ё | 0401 | 1025 | D081 | 208 129 | 168 |
| ё | 0451 | 1105 | D191 | 209 145 | 184 |
23.09.2018, 12:37; рейтинг: 43069
Таблицы кодировок ASCII, CP1251 (windows1251), ISO-8859-5
Таблица ASCII
Таблица ASCII (American standard code for information interchange) является мировым стандартом для кодирования букв английского алфавита, популярных спец символов (! $ # % & и т.д.) и некоторых непечатных символов (например, возврат каретки 0x0D и перенос строки 0х0А).
Таблица создавалась те времена, когда возникла необходимость связать символы и числа. А такое соответствие необходимо было для того что бы с помощью чисел можно было передать текстовое сообщение между разными устройствами с цифровой связью.
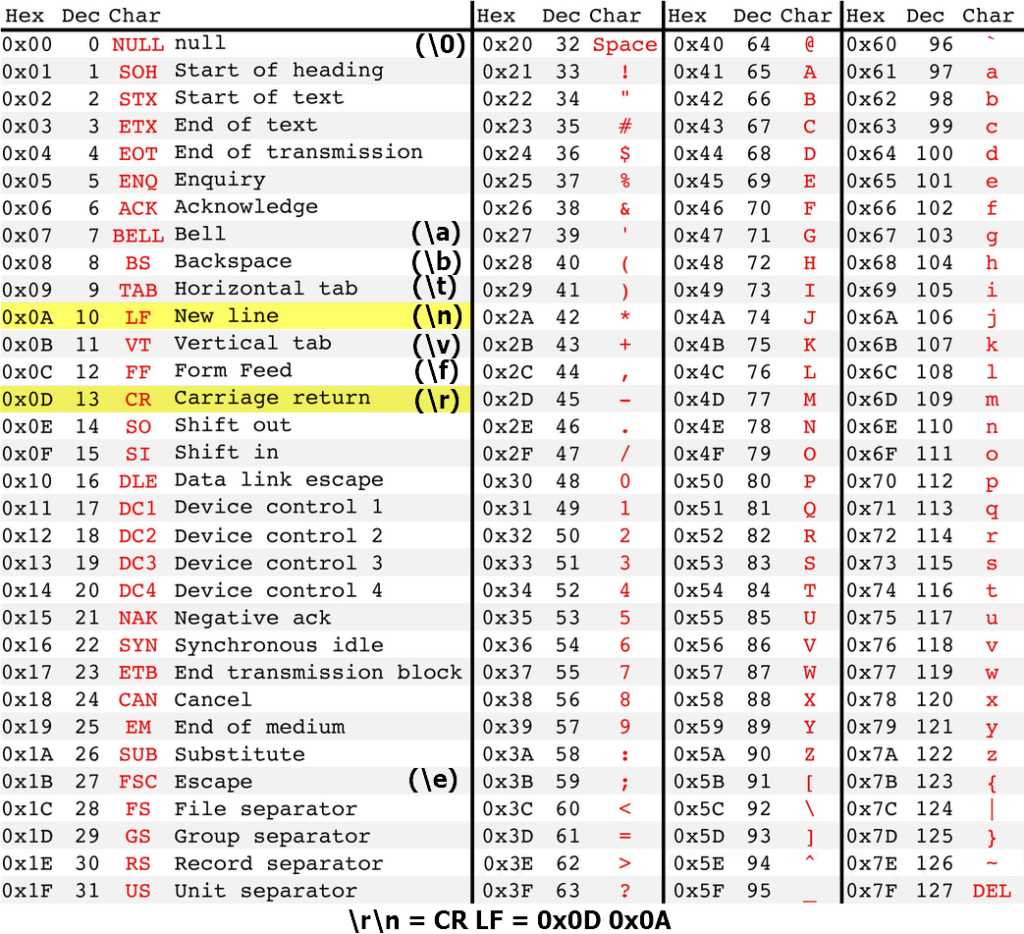
Таблица CP1251 (windows-1251)
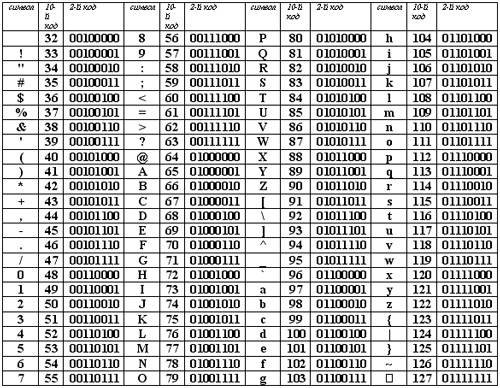
Эта кодировочная таблица может называться или CP1251 или Windows-1251 Это стандарт кодирования кириллических символов в операционных системах windows с русскоязычным интерфейсом.
Первая часть этой таблицы (до байта 0x7F) повторяет таблицу ASCII, а вторая часть (от 0x80 до 0xFF) кодирует кириллические символы в алфавитном порядке.
Таблица IS0-8859-5
Эта кодировка применяется в дисплеях Nextion для кодирования кириллических символов.
Стоит обратить внимание, что в данной таблице кириллические символы расположены в алфавитном порядке и сдвинуты ровно на 16 байт по сравнению с кодировочной таблицей windows-1251.

Кодировка UTF-8
(Unicode Transformation Format)
Очень распространенный формат кодирования символов, позволяющий кодировать символы переменным количеством байт.
Например, если для кодирования номера символа требуется 21 бит, то используется 4 байта для кодировки. Если для кодирования достаточно 11 бит, то используют 2 байта. А если номер символа может быть закодирован 7 битами, то используется один байт.
Все ASCII символы в кодировке UTF8 закодированы без изменений, то есть 1 байтом, как в стандартной таблице ASCII.
А вот остальные символы закодированы количеством байт от 2 до 4.
Кириллические символы закодированы двумя байтами.
Кодировки UTF-8 и Windows 1251 — просто о сложном

Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, как посмотреть код страницы в браузере, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.

Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.

UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
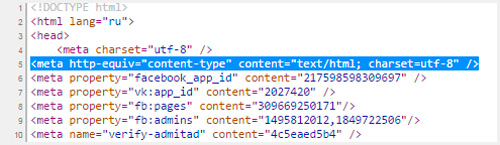
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова « Создание и Раскрутка сайта от А до Я ».

Он содержит в себе очень много – 256 уроков, затрагивающих HTML, CSS, JavaScript, PHP, MySQL и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.

Что-то я отошел от темы. Давайте вернемся к кодировкам.
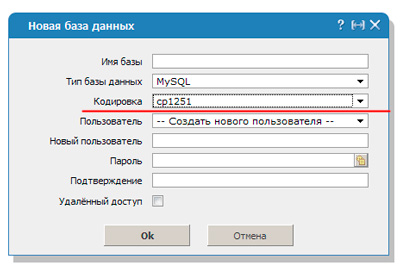
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251»
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее создавать правильные сайты, где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.



