- Кодировка в Gedit
- Содержание
- Описание проблемы
- Настройка Gedit на автоопределение кодировки
- Смена кодировки открытого файла
- Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
- Программы для определения кодировки в Linux
- Команда file -i показывает неверную кодировку
- Программа enca для определения кодировки файла
- Как определить кодировку строки
- Изменение кодировки в Linux
- Использование команды iconv
- Конвертирование файлов из windows-1251 в UTF-8 кодировку
- Изменение кодировки программой enca
- Конвертация строки в правильную кодировку
- Кодировками ubuntu для windows
- Стандарты кодировки и Microsoft
- Установка приоритетов кодировок в GEdit
- Последние материалы
- Конвертирование кодировок текстовых файлов
- Конвертирование кодировок текстовых файлов: 11 комментариев
- Добавить комментарий Отменить ответ
Кодировка в Gedit
Содержание
Описание проблемы
Ubuntu по умолчанию использует кодировку текстовых файлов UTF-8, однако некоторые операционные системы используют другие кодировки (например, русская версия Microsoft Windows использует CP-1251). Из-за разницы в кодировках могут возникнуть проблемы при открытии текстовых файлов в редакторе Gedit — они будут нечитаемыми. Данная статья предлагает несколько простых способов решения этой проблемы.
Настройка Gedit на автоопределение кодировки
Gedit может автоматически определить нужную кодировку. Для этого его нужно немного настроить.
Есть 3 варианта:
Вариант 1.
Запускаем dconf-editor и переходим в
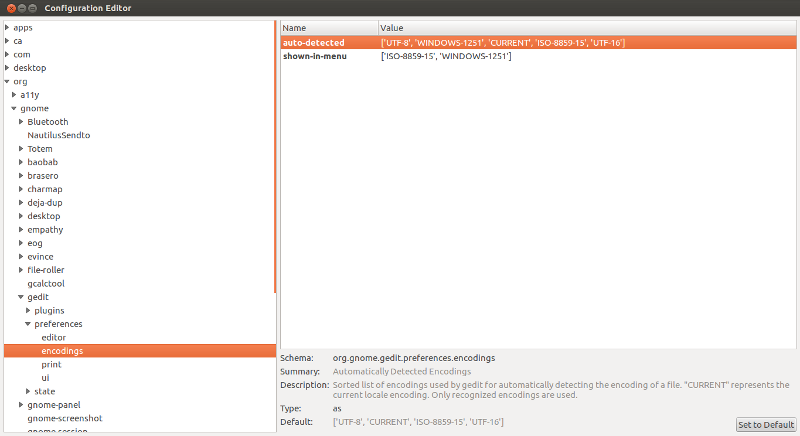
Редактируем ключ auto_detected 3) , вписывая нужную нам кодировку
Вариант 2.
Выполните в терминале команду:
Откроется Редактор Конфигурации GNOME. В нем откройте для редактирования ключ auto_detected 4) . 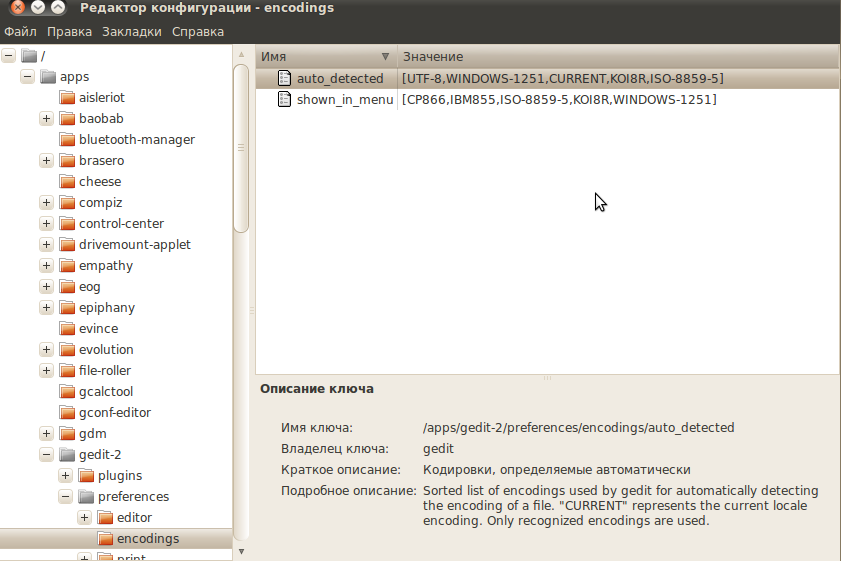 В появившемся окне редактирования переместите нужную вам кодировку вверх, так, чтобы она находилась сразу после UTF-8. Нажмите OK и закройте редактор.
В появившемся окне редактирования переместите нужную вам кодировку вверх, так, чтобы она находилась сразу после UTF-8. Нажмите OK и закройте редактор. 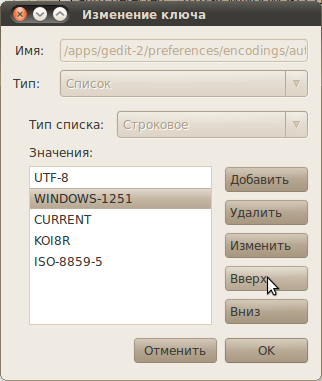
Вариант 3. Выполните в терминале команду:
Для Ubuntu 16.04:
Для Ubuntu Mate 16.04:
Данный способ является самым быстрым.
Теперь, если вы откроете файл с кодировкой WINDOWS-1251 — он будет правильно отображаться в Gedit.
Смена кодировки открытого файла
С помощью системы плагинов можно добавить возможность выбора кодировки уже открытого файла.
/.local/share/gedit/plugins (если такой папки нет, то её нужно создать)
После этого в главном меню Файл появляется пункт «Encoding», который позволяет менять кодировку в уже открытом документе.
Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
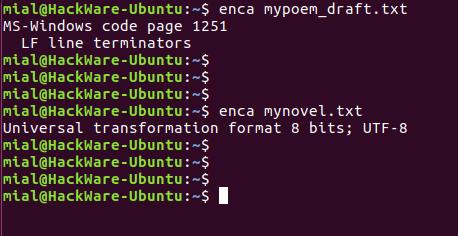
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
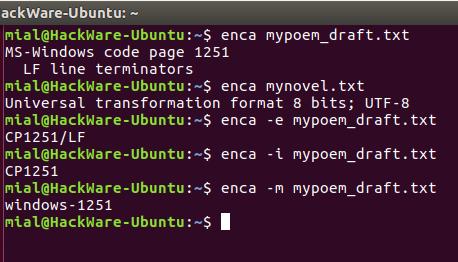
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
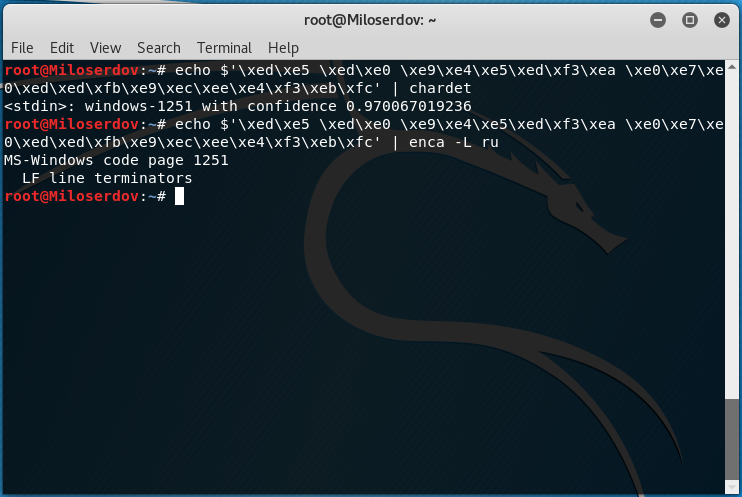
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
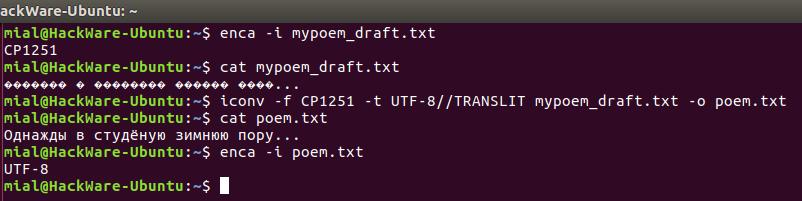
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
Кодировками ubuntu для windows
Открывая тестовый файл, который ранее был создан в Windows через программу Блокнот, вы скорее всего наткнетесь на проблему некорректного отображения русских символов в текстовом редакторе, используемом в Ubuntu по умолчанию (по умолчанию в Ubuntu используется редактор GEdit). К счастью, данную «проблему» легко решить. Ведь тут вся проблема, как вы, наверное, уже догадались, кроется всего-навсего в кодировке самого файла.

Стандарты кодировки и Microsoft
Давным-давно известно, что компания Microsoft «любит» использовать собственные стандарты, отказываясь при этом от общемировых, а если кто-то не хочет с этим фактом считаться, то Microsoft попросту это игнорирует. Но Microsoft может это себе позволить, будучи хоть и платной, но самой распространенной операционной системой в мире.
Яркий пример по установлению компанией Microsoft собственных стандартов — это пакет Microsoft Office, который включает в себя такие известные программы, как MS Word и MS Excel. Если пользователь не сможет открыть файл, созданный в одном из этих редакторов на используемой им операционной системе (например, Android, Linux или Mac OS X), то ему скорее всего это доставит огромные неудобства и в конечном счете заставит отказаться от использования операционной системы, но не от самого распространенного в мире формата текстовых и табличных документов.
При этом тут как бы отходит на второй план то факт, что формат файлов ODT линуксового Open Office в отличие от DOC и тем более DOCX является общепринятым. Мир не заставишь в одночасье отказаться от Windows, а значит, и от ее фирменного пакета Microsoft Office.
В случае с текстовым файлом Microsoft как всегда проигнорировала общепринятый стандарт кодировки символов UTF-8, используемый в операционной системе Ubuntu. Операционная система Windows по умолчанию сохраняет русский текст при использовании блокнота в кодировке Windows 1251, которая уже очень устарела. Вместо кодировки Windows 1251 сейчас принято использовать другую кодировку под названием Koi8-r.
Но поскольку кодировки Windows 1251 и Koi8-r похожи как близнецы, то редактор GEdit попросту не может распознать используемую в текстовом файле, сохраненном в Блокноте из под Windows, кодировку. Правда, эту проблему очень легко побороть — для этого нужно всего-навсего установить приоритеты кодировок в программе GEdit. Иначе говоря, нужно просто попросить GEdit вначале пробовать открыть файл в кодировке Windows 1251, а затем уже пробовать открытие в кодировке Koi8-r.
Установка приоритетов кодировок в GEdit
Для задания приоритета кодировок выполните запустите программу Терминал.

А затем наберите в Терминале команду, которая указана ниже:
gsettings set org.gnome.gedit.preferences.encodings auto-detected «[‘UTF-8’, ‘WINDOWS-1251’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]»

После успешного выполнения указанной выше команды ваш текстовый файл из Windows откроется без иероглифов в читабельном виде.

На этом все. Вопросы как всегда в комментариях.
Upd 24.01.2019
В Ubuntu 18.04 для изменения приоритета кодировок в текстовом редакторе GEdit необходимо выполнять в Терминале команду
Gedit gsettings set org.gnome.gedit.preferences.encodings candidate-encodings «[‘UTF-8’, ‘WINDOWS-1251’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]»

- Вы здесь:
- Главная

- Разное
- Операционная система Ubuntu
- Кодировка редактора Gedit в Ubuntu
Последние материалы
- Установка MS EDGE в Ubuntu и Kubuntu
Как читать проектную декларацию застройщика
Индукционная электрическая плитка LEBEN 288-021
Застройщики и новостройки Смоленска
Статистика коронавируса COVID-19 в терминале Linux
Конвертирование кодировок текстовых файлов
Есть ещё люди использующие Windows! И иногда они могут прислать вам текстовые файлы с расширением txt (они же не знают что текстовые файлы и без расширения бывают 🙂 ) или что-то типа такого. Если попытаться открыть эти файлы в gedit, без применения специального волшебства, то вместо русских букв будут каракули.
А что делать, если нужно не просто прочитать эти файлы, а работать с ними? Правильно, их нужно перекодировать в нормальную кодировку. Есть несколько рецептов этой магии:
1. Использовать встроенную утилиту iconv — это путь настоящего линуксойда, посему man iconv
2. Использовать другую утилиту: recode. Это путь тех, кто любит немного попроще. Но её сначала нужно установить:
Использование этой утилиты немногим сложнее её установки:
где:
CP1251 — кодировка в которой сейчас находится файл;
UTF8 — в какой кодировке файл должен быть;
file.txt — файл, который нужно перекодировать.
3. Использовать gedit. Этот способ я бы порекомендовал в случае если нужно перекодировать всего несколько файлов, причём внося в них изменения.
Открываем файл в «родной» кодировке:
Вносим все необходимые изменения, и в меню gedit выбираем Файл — Сохранить как…. В открывшемся окне указываем нужное имя файла и нормальную кодировку.
Замечание: С кодировкой CP1251 gedit не захотел открывать файл находящийся в кодировке windows-1251!
Если кто ещё знает способы — делитесь! Так как плюрализм способов решения задачи — это то что отличает Linux от других ОС.
Конвертирование кодировок текстовых файлов: 11 комментариев
спасибо. Не знал про iconv и recode.
Обычно я правлю в gconf-editor строки /apps/gedit-2/preferences/encodings/auto_detected и shown_in_menu добавляя WINDOWS-1251 сразу после UTF-8
чем же iconv сложнее второго?
iconv -f … -t …. и в пайп
Подобными прогами можно пользоваться только тогда, когда точно известна кодировка исходного файла. А когда нет? Мне часто приходится работать с текстовыми файлами в причудливых кодировках. Я делаю проще пользуюсь самым лучшим текстовым редактором Kate, там нажимаю на Tools, потом Encodings и выбираю кодировку — выбираю до тех пор, пока не найду нужную. Но это в KDE на десктопе, а на нетбуке стоит GNOME и Kate — КDE’шную программу ставить туда не хочется, там я пользуюсь Geany, тоже неплохая прожка, но меняется кодировка там по другому (сам, кстати, не сразу нашел) — File, Open as. Потом все файлы сохраняю в UTF8.
Вот это лучше всего.
Зачем засырать другим и себе мозг. Leafpad понимает все кодировки. Почему его не делают редактором по умолчанию-? Наверное, из вредности.
@gidiara
Я о таком редакторе ничего не слышал. Спасибо за наводку, попробуем!
gidiara, в нем даже банальной подсветки синтаксиса нет!
Эти способы хороши, если нужно конвертировать всего несколько файлов (можно вручную открывать и kate, и gedit и т.п. и сохранять; kate здесь удобнее, т.к. уже уже открытый файл с абракадаброй хорошо перекодирует через Tool —> Encoding —> Autodetect), или если все файлы в одной известной кодировке. А если нужно перекодировать много файлов, а они в разных кодировках (практически, это koi8-r и window-1251)?
Через Synaptic устанавливаем пакет enca. Пример использования:
enconv -L ru -x UTF-8 *.txt
Эта команда конвертирует все текстовые файлы (*.txt) из различных русских кодировок (-L ru) в кодировку юникод (-x UTF-8). enconv входит в пакет enca.
Leafpad хорош, по функциональности схож с Notepad’ом: не умеет вообще ничего, кроме, собственно, печатания и чтения текста. Зато с кодировками проблем не имеет. Как раз то, что надо обычному юзеру.
я написал простецкий скрипт, который показывает как выглядят первые строчки файла если перекодировать из cp1251 и предлагает выбор: перекодировать или следующую кодировку попробовать. мне кажется из консоли таки быстрее и удобне получается.
Александр, а поделиться ссылкой на скрипт с примерами использования?
Добавить комментарий Отменить ответ
Этот сайт использует Akismet для борьбы со спамом. Узнайте, как обрабатываются ваши данные комментариев.



