- Команда Grep в Linux (поиск текста в файлах)
- Командный синтаксис grep
- Искать строку в файлах
- Инвертировать соответствие (исключить)
- Использование Grep для фильтрации вывода команды
- Рекурсивный поиск
- Показать только имя файла
- Поиск без учета регистра
- Искать полные слова
- Показать номера строк
- Подсчет совпадений
- Бесшумный режим
- Основное регулярное выражение
- Расширенные регулярные выражения
- Поиск нескольких строк (шаблонов)
- Строки печати перед матчем
- Печатать строки после матча
- Выводы
- Примеры команды grep в Linux
- Используем команду grep в Linux
- Подготовительные работы
- Стандартный поиск по содержимому
- Поиск с захватом строк
- Поиск ключевых слов в начале и в конце строк
- Поиск чисел
- Анализ всех файлов директории
- Точный поиск по словам
- Поиск строк без определенного слова
Команда Grep в Linux (поиск текста в файлах)
Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
В этой статье мы покажем вам, как использовать команду grep на практических примерах и подробных объяснениях наиболее распространенных опций GNU grep .
Командный синтаксис grep
Синтаксис команды grep следующий:
Пункты в квадратных скобках необязательны.
- OPTIONS — Ноль или более вариантов. Grep включает ряд опций , управляющих его поведением.
- PATTERN — Шаблон поиска.
- FILE — Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из файла /etc/passwd , вы должны выполнить следующую команду:
Результат должен выглядеть примерно так:
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
Инвертировать соответствие (исключить)
Чтобы отобразить строки, не соответствующие шаблону, используйте параметр -v (или —invert-match ).
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
Вы также можете объединить несколько каналов по команде. Как вы можете видеть в выходных данных выше, также есть строка, содержащая процесс grep . Если вы не хотите, чтобы эта строка отображалась, передайте результат другому экземпляру grep как показано ниже.
Рекурсивный поиск
Для рекурсивного поиска шаблона вызовите grep с параметром -r (или —recursive ). Когда используется этот параметр, grep будет искать все файлы в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы следовать по всем символическим ссылкам , вместо -r используйте параметр -R (или —dereference-recursive ).
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете опцию -R , grep будет следовать по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается с -r потому что файлы внутри каталога с sites-enabled Nginx являются символическими ссылками на файлы конфигурации внутри каталога с sites-available .
Показать только имя файла
Чтобы подавить вывод grep по умолчанию и вывести только имена файлов, содержащих совпадающий шаблон, используйте параметр -l (или —files-with-matches ).
Приведенная ниже команда выполняет поиск по всем файлам, заканчивающимся на .conf в текущем рабочем каталоге и выводит только имена файлов, содержащих строку linuxize.com :
Результат будет выглядеть примерно так:
Параметр -l обычно используется в сочетании с рекурсивным параметром -R :
Поиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep с параметром -i (или —ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
Но если вы выполните поиск без учета регистра с использованием параметра -i , он будет соответствовать как заглавным, так и строчным буквам:
Указание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или —word-regexp ).
Если вы запустите ту же команду, что и выше, включая параметр -w , команда grep вернет только те строки, где gnu включен как отдельное слово.
Показать номера строк
Параметр -n (или —line-number ) указывает grep показывать номер строки, содержащей строку, соответствующую шаблону. Когда используется эта опция, grep выводит совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
Результат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Подсчет совпадений
Чтобы вывести количество совпадающих строк в стандартный вывод, используйте параметр -c (или —count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, в которых в качестве оболочки используется /usr/bin/zsh .
Бесшумный режим
-q (или —quiet ) указывает grep работать в тихом режиме, чтобы ничего не отображать на стандартном выводе. Если совпадение найдено, команда завершает работу со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте символ ^ (каретка) для сопоставления выражения в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Используйте символ $ (доллар), чтобы найти выражение в конце строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом конце строки.
Используйте расширение . (точка) символ, соответствующий любому одиночному символу. Например, чтобы сопоставить все, что начинается с kan затем имеет два символа и заканчивается строкой roo , вы можете использовать следующий шаблон:
Используйте [ ] (скобки) для соответствия любому одиночному символу, заключенному в квадратные скобки. Например, найдите строки, содержащие accept или « accent , вы можете использовать следующий шаблон:
Используйте [^ ] для соответствия любому одиночному символу, не заключенному в квадратные скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих co(any_letter_except_l)a , например coca , cobalt и т. Д., Но не будет соответствовать строкам, содержащим cola ,
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или —extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Вот несколько примеров:
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
Параметр -o используется для печати только соответствующей строки.
Поиск нескольких строк (шаблонов)
Два или более шаблонов поиска можно объединить с помощью оператора ИЛИ | .
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
Если вы используете опцию расширенного регулярного выражения -E , то оператор | не следует экранировать, как показано ниже:
Строки печати перед матчем
Чтобы напечатать определенное количество строк перед совпадающими строками, используйте параметр -B (или —before-context ).
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
Печатать строки после матча
Чтобы напечатать определенное количество строк после совпадающих строк, используйте параметр -A (или —after-context ).
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
Выводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Подробнее о Grep можно узнать на странице руководства пользователя Grep .
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Источник
Примеры команды grep в Linux

Иногда пользователи сталкиваются с необходимостью осуществления поиска определенной информации внутри каких-либо файлов. Часто конфигурационные документы или другие объемные данные вмещают в себе большое количество строк, поэтому вручную отыскать нужные данные не получается. Тогда на помощь приходит одна из встроенных команд в операционные системы на Linux, которая позволит выполнить нахождение строк буквально за считанные секунды.
Используем команду grep в Linux
Что касается различий между дистрибутивами Линукс, в этом случае они не играют никакой роли, поскольку интересующая вас команда grep по умолчанию доступна в большинстве сборок и применяется абсолютно одинаково. Сегодня мы бы хотели обсудить не только действие grep, но и разобрать основные аргументы, которые позволяют значительно упростить процедуру поиска.
Подготовительные работы
Все дальнейшие действия будут производиться через стандартную консоль, она же позволяет открывать файлы только путем указания полного пути к ним либо если «Терминал» запущен из необходимой директории. Узнать родительскую папку файла и перейти к ней в консоли можно так:
- Запустите файловый менеджер и переместитесь в нужную папку.
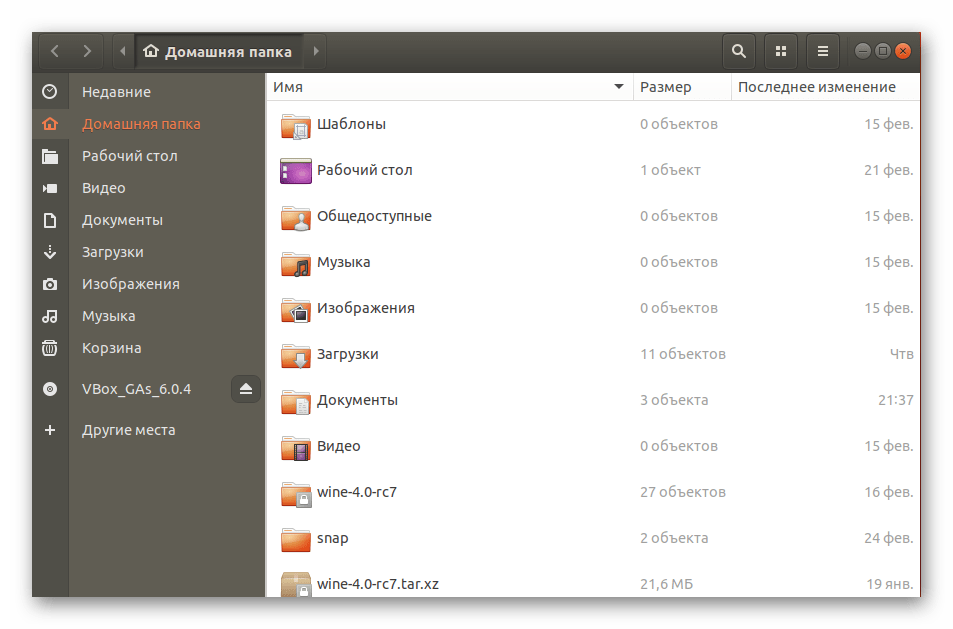
Нажмите правой кнопкой мыши на требуемом файле и выберите пункт «Свойства».
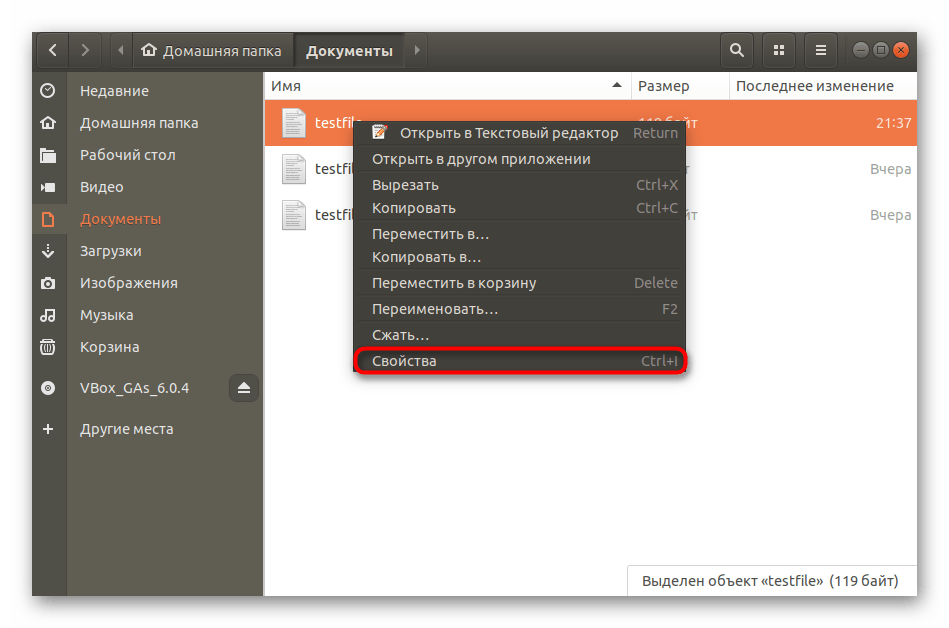
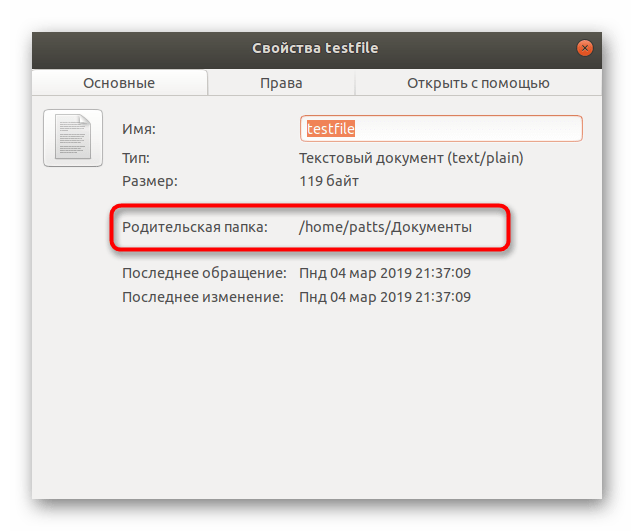
Теперь запустите «Терминал» удобным методом, например, через меню или зажатием комбинации клавиш Ctrl + Alt + T.
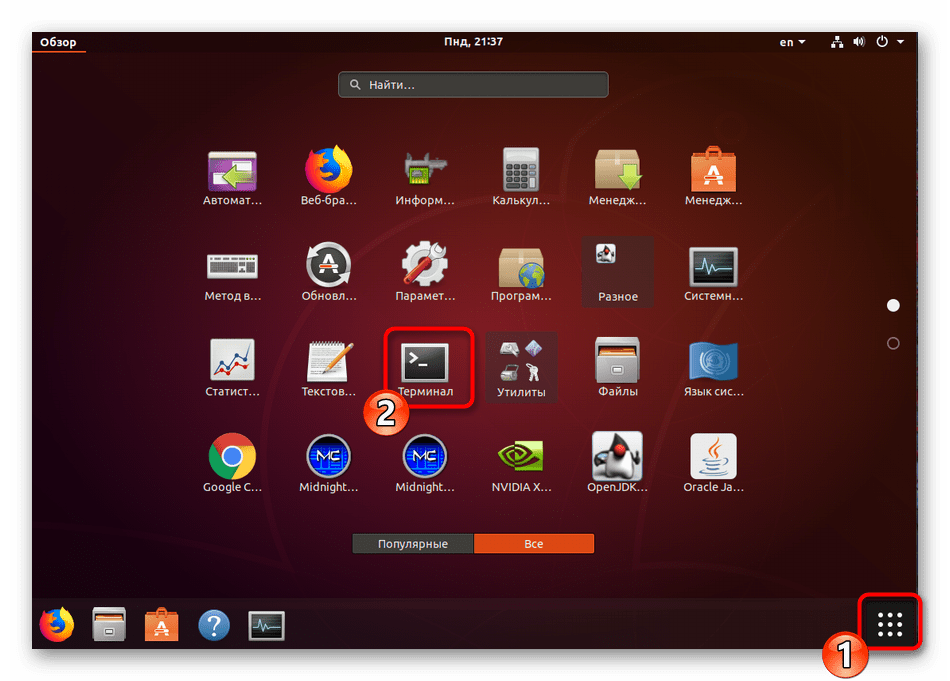
Здесь перейдите к директории через команду cd /home/user/folder , где user — имя пользователя, а folder — название папки.
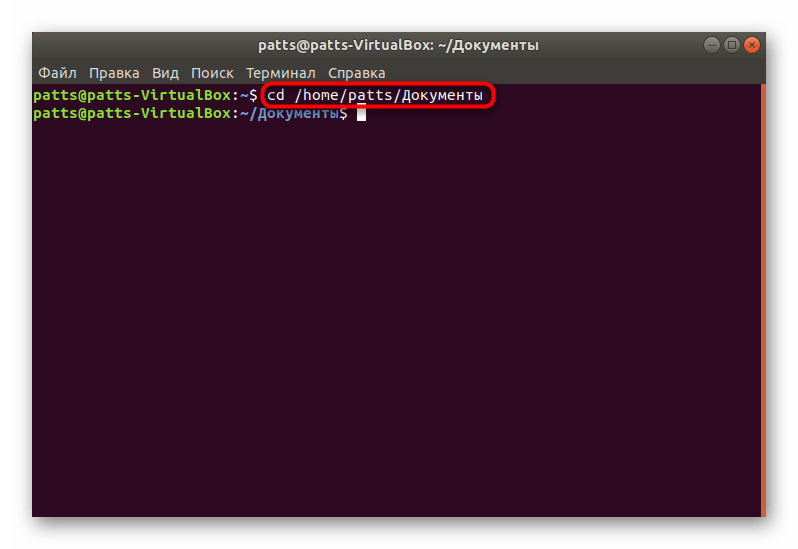
Задействуйте команду cat + название файла , если хотите просмотреть полное содержимое. Детальные инструкции по работе с этой командой ищите в другой нашей статье по ссылке ниже.
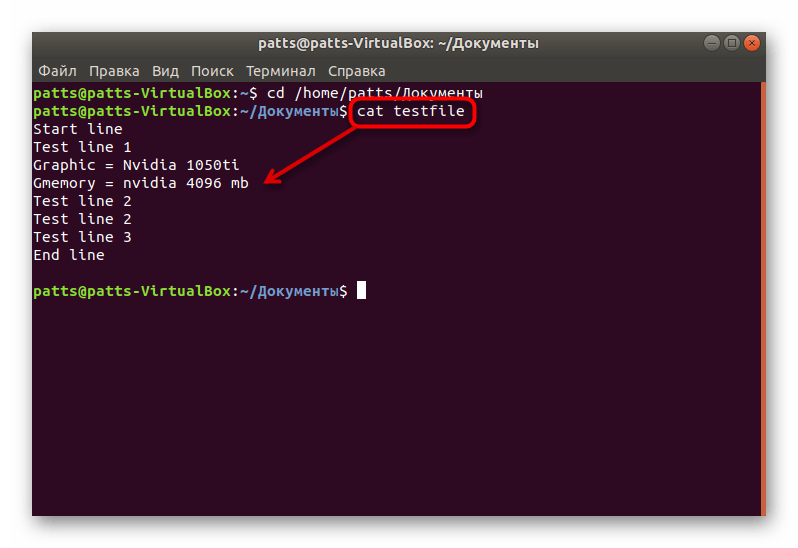
Благодаря выполнению приведенных выше действий вы можете использовать grep, находясь в нужной директории, без указания полного пути к файлу.
Стандартный поиск по содержимому
Прежде чем переходить к рассмотрению всех доступных аргументов, важно отметить и обычный поиск по содержимому. Он будет полезен в тех моментах, когда необходимо найти простое совпадение по значению и вывести на экран все подходящие строки.
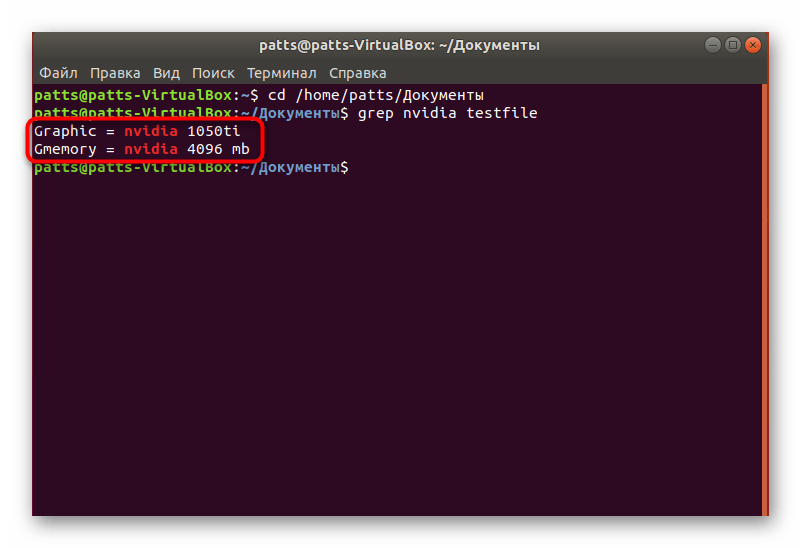
- В командной строке введите grep word testfile , где word — искомая информация, а testfile — название файла. Когда производите поиск, находясь за пределами папки, укажите полный путь по примеру /home/user/folder/filename . После ввода команды нажмите на клавишу Enter.
Осталось только ознакомиться с доступными вариантами. На экране отобразятся полные строки, а ключевые значения будут выделены красным цветом.
Важно учитывать и регистр букв, поскольку кодировка Linux не оптимизирована для поиска без учета больших или маленьких символов. Если вы хотите обойти определение регистра, впишите grep -i «word» testfile .
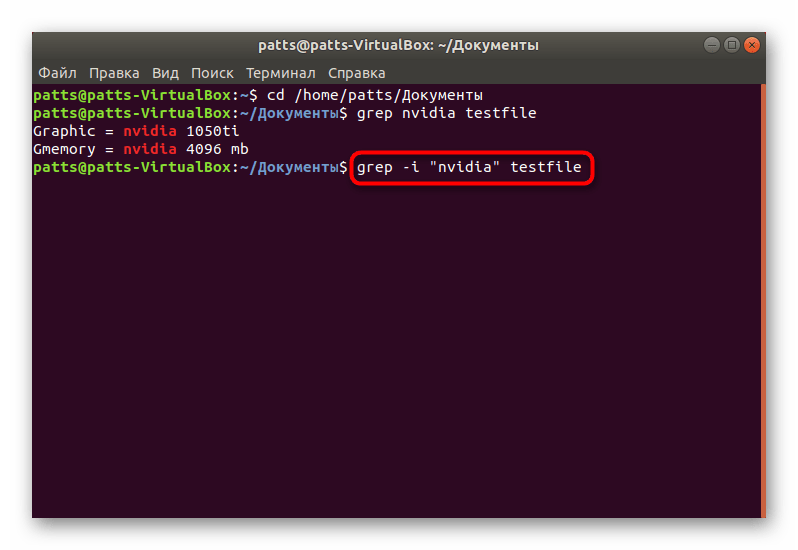
Как видите, на следующем скриншоте результат изменился и добавилась еще одна новая строка.
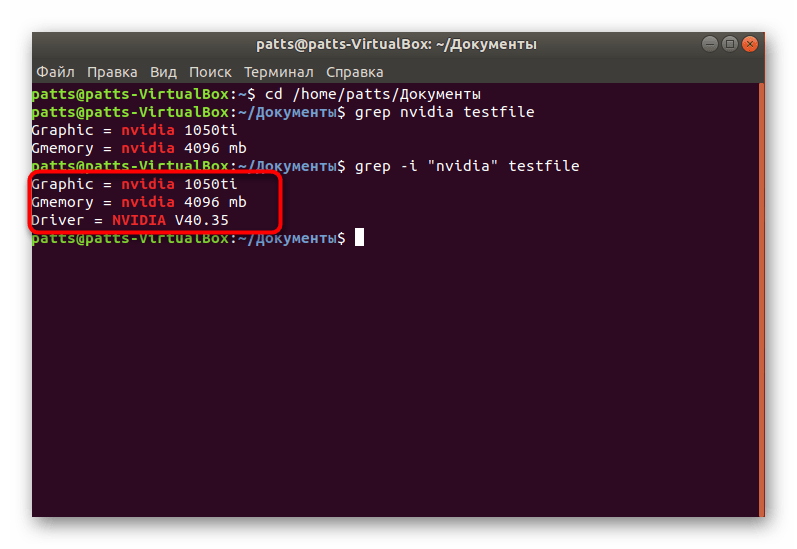
Поиск с захватом строк
Иногда пользователям необходимо найти не только точное совпадение по строкам, но и узнать информацию, которая идет после них, например, при отчете об определенной ошибке. Тогда правильным решением будет применить атрибуты. Впишите в консоль grep -A3 «word» testfile , чтобы включить в результат и три следующие строки после совпадения. Вы можете написать -A4 , тогда будут захвачены четыре строки, ограничений никаких не имеется.
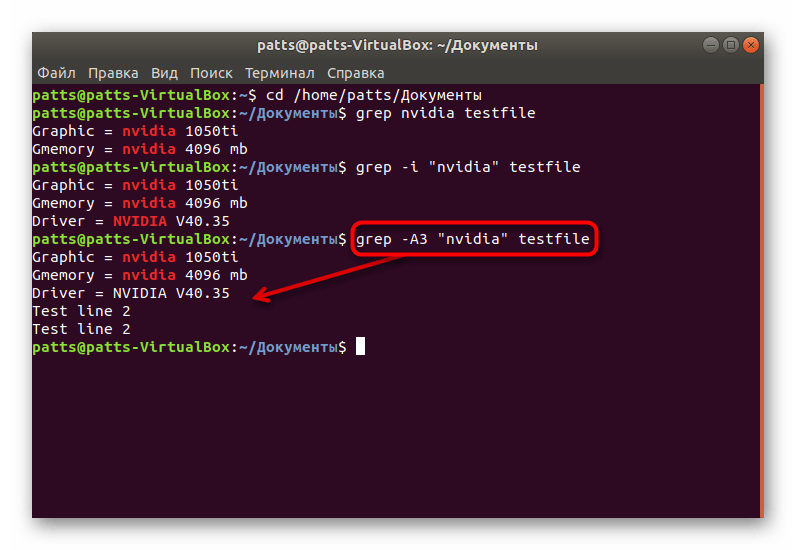
Если вместо -A вы примените аргумент -B + количество строк , в результате отобразятся данные, находящиеся до точки вхождения.
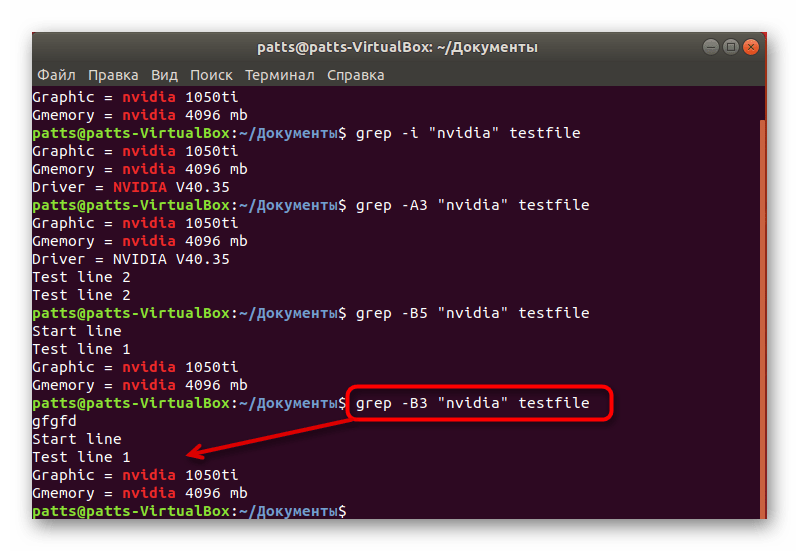
Аргумент -С , в свою очередь, захватывает строки вокруг ключевого слова.
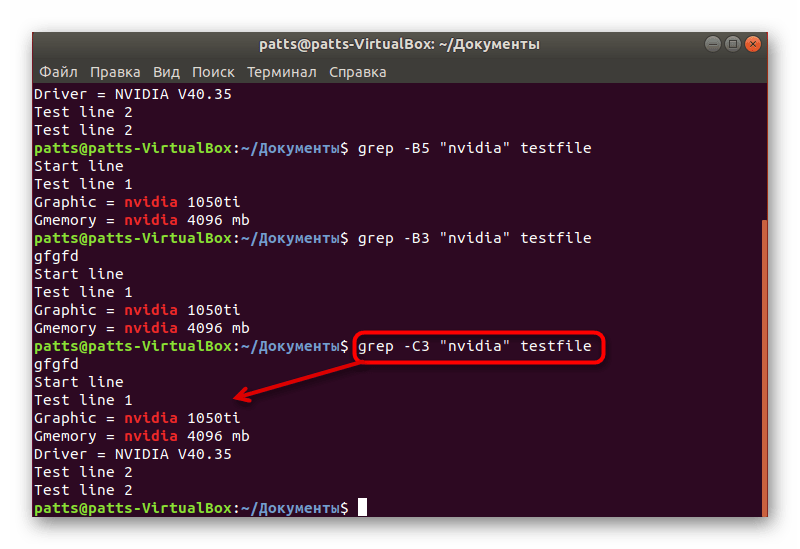
Ниже вы можете увидеть примеры присваивания указанных аргументов. Обратите внимание, что обязательно нужно учитывать регистр и проставлять двойные кавычки.
grep -B3 «word» testfile
grep -C3 «word» testfile
Поиск ключевых слов в начале и в конце строк
Надобность определения ключевого слова, которое стоит в начале или в конце строки, чаще всего возникает во время работы с конфигурационными файлами, где каждая линия отвечает за один параметр. Для того чтобы увидеть точное вхождение в начале, необходимо прописать grep «^word» testfile . Знак ^ как раз и отвечает за применение этой опции.
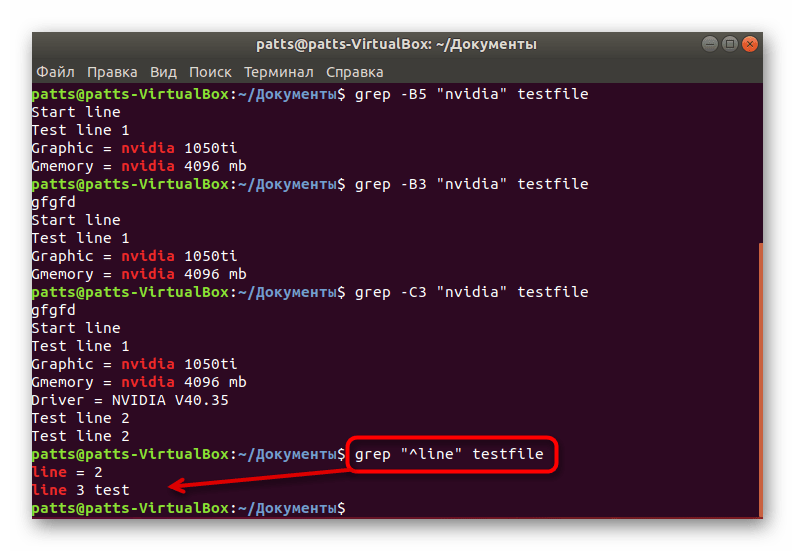
Поиск содержимого в конце строк происходит примерно по такому же принципу, только в кавычках следует добавить знак $, и команда обретет такой вид: grep «word$» testfile .
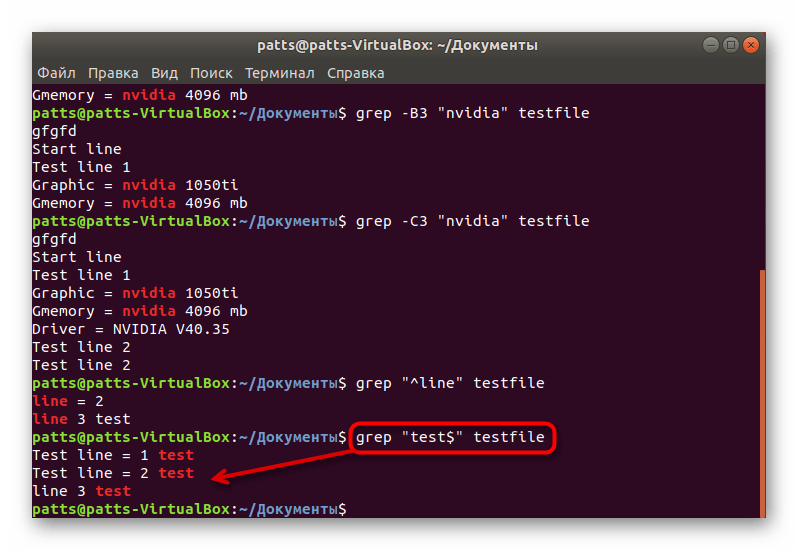
Поиск чисел
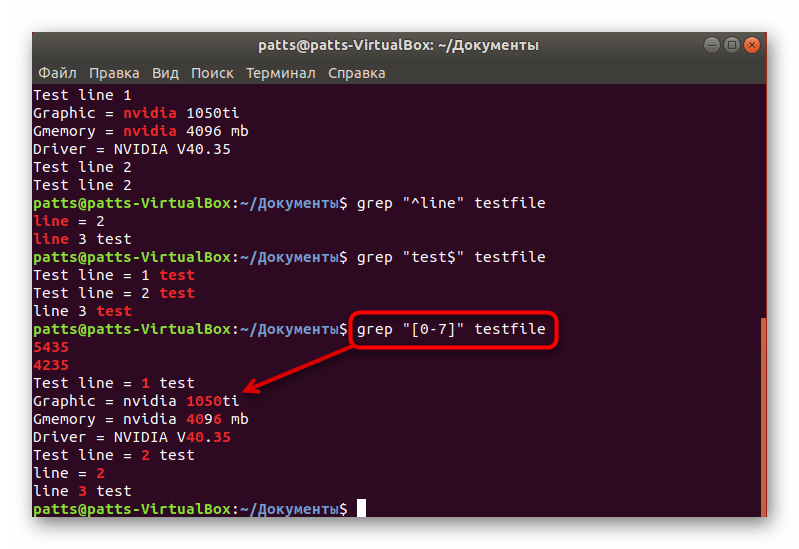
При поиске нужных значений пользователь не всегда имеет информацию касательно точного слова, присутствующего в строке. Тогда процедуру поиска можно производить через числа, что иногда значительно упрощает задачу. Надо лишь задействовать рассматриваемую команду в виде grep «4» testfile , где «6» — диапазон значений, а testfile — название файла для сканирования.
Анализ всех файлов директории
Сканирование всех объектов, находящихся в одной папке, называется рекурсивным. Юзеру требуется применить только один аргумент, который проведен анализ всех файлов папки и выведет на экран подходящие строки и их расположение. Понадобится ввести grep -r «word» /home/user/folder , где /home/user/folder — путь к директории для сканирования.
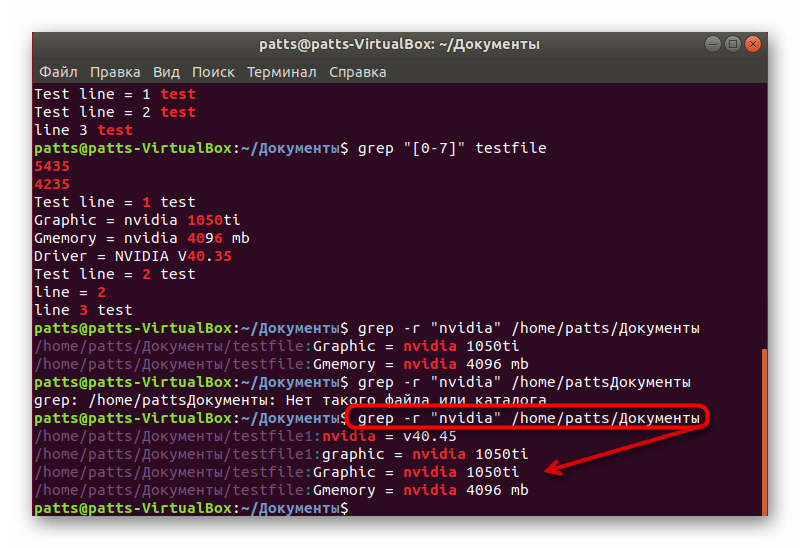
Голубым цветом будет отображаться место хранения файла, а если хотите получить строки без этой информации, присвойте еще один аргумент, чтобы команда получилась такой grep -h -r «word» + путь к папке .
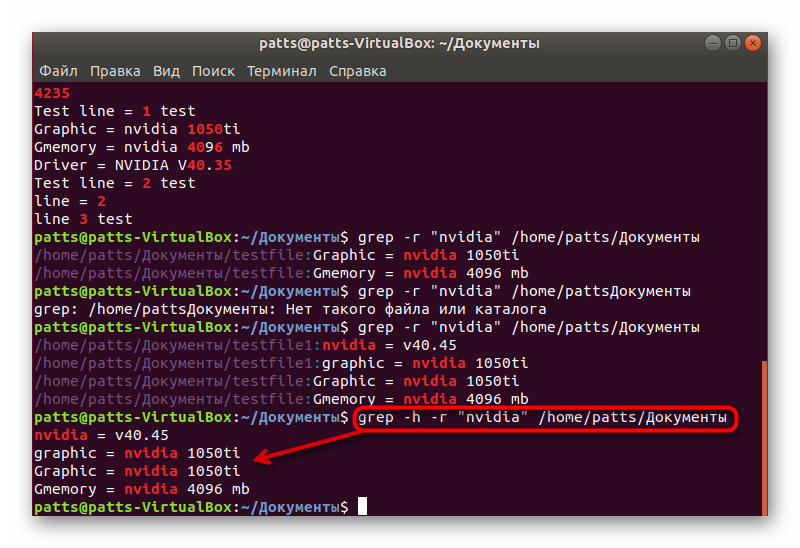
Точный поиск по словам
В начале статьи мы уже говорили об обычном поиске по словам. Однако при таком методе в результатах будут высвечиваться дополнительные комбинации. Например, вы находите слово User, но команда отобразит еще и User123, PasswordUser и другие совпадения, если такие имеются. Чтобы избежать такого результата, присвойте аргумент -w ( grep -w «word» + имя файла или его расположение ).
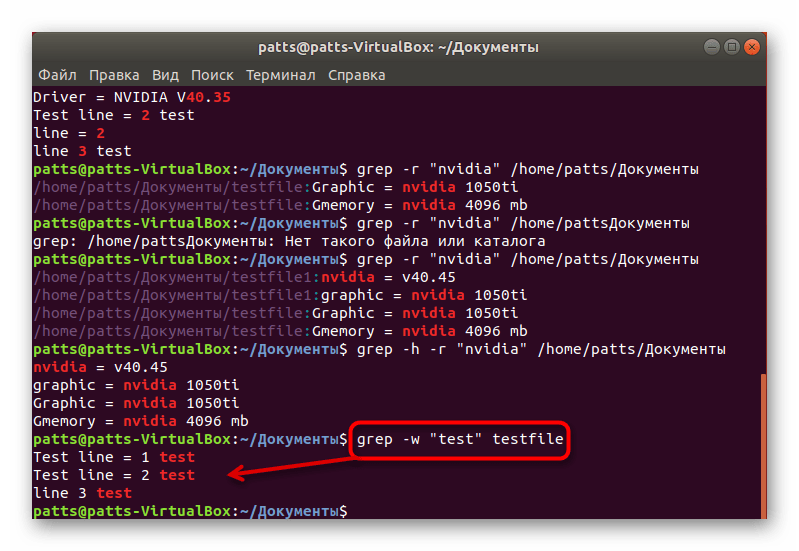
Выполняется эта опция и при надобности поиска сразу нескольких точных ключевых слов. В таком случае введите egrep -w ‘word1|word2’ testifile . Обратите внимание, что в этом случае к grep добавляется буква e, а кавычки ставятся одинарные.
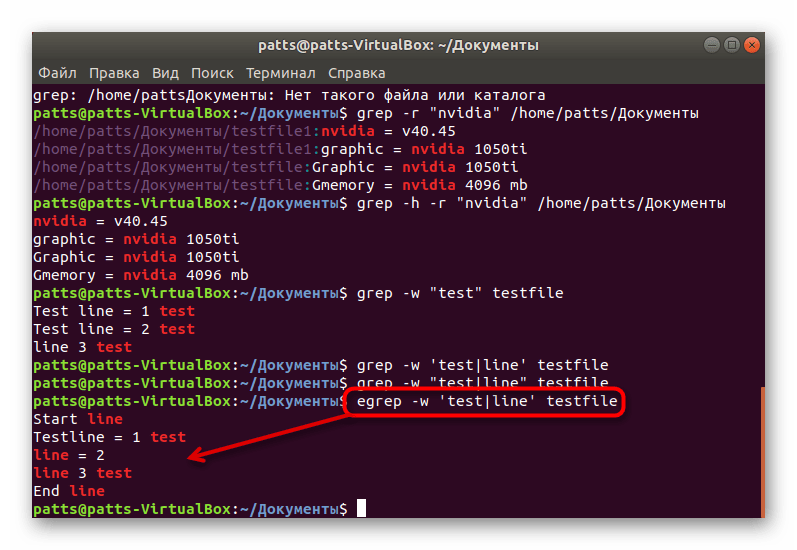
Поиск строк без определенного слова
Рассматриваемая утилита умеет не только находить слова в файлах, но и выводить строки, в которых отсутствует заданное пользователем значение. Тогда перед введением ключевого значения и файла добавляется -v . Благодаря ей при активации команды вы увидите только соответствующие данные.
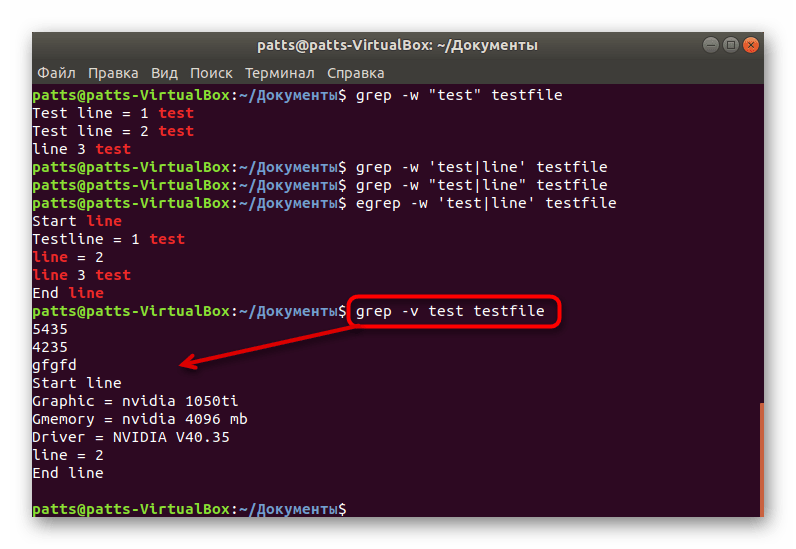
Синтаксис grep собрал в себе еще несколько аргументов, о которых можно вкратце рассказать:
- -I — показывать только названия файлов, подходящих под критерий поиска;
- -s — отключить уведомления о найденных ошибках;
- -n — отображать номер строки в файле;
- -b — показывать номер блока перед строчкой.
Ничто не мешает вам применять несколько аргументов для одного нахождения, просто вводите их через пробел, не забывая учитывать регистр.
Сегодня мы детально разобрали команду grep, доступную в дистрибутивах на Linux. Она является одной из стандартных и часто использующихся. Прочитать о других популярных инструментах и их синтаксисе вы можете в отдельном нашем материале по следующей ссылке.
Помимо этой статьи, на сайте еще 12315 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Источник



