Мой компилятор для Lisp
Очень рад объявить о завершении моего первого компилятора для языка программирования! Malcc — это инкрементальный AOT -компилятор Lisp, написанный на C.
Вкратце расскажу о его многолетней разработке и что я узнал в процессе. Альтернативное название статьи: «Как написать компилятор за десять лет или меньше».
(В конце есть TL;DR, если вас не волнует предыстория).
Демо компилятора
Успешные неудачи
Почти десять лет я мечтал написать компилятор. Меня всегда очаровывала работа языков программирования, особенно компиляторов. Хотя я представлял компилятор как тёмную магию и понимал, что сделать его с нуля невозможно простому смертному вроде меня.
Но я всё равно попытался и учился по ходу!
Во-первых, интерпретатор
В 2011 году я начал работу над простым интерпретатором для вымышленного языка Airball (airball можно перевести как «мазила»). По названию можете оценить степень моей неуверенности, что он будет работать. Это была довольно простая программа на Ruby, которая анализировала код и ходила по абстрактному синтаксическому дереву (AST). Когда интерпретатор всё-таки заработал, я переименовал его в Lydia и переписал на C, чтобы сделать быстрее.
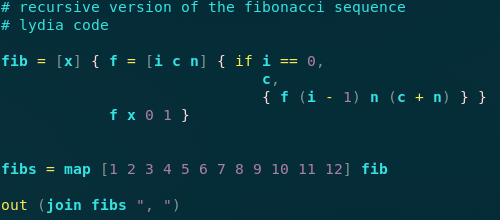
Помню, синтаксис Lydia казался мне очень умным! До сих пор наслаждаюсь его простотой.
Хотя Lydia была далека от идеального компилятора, но она вдохновила меня продолжить эксперименты. Впрочем, меня по-прежнему мучили вопросы, как заставить компилятор работать: во что компилировать? нужно ли изучать ассемблер?
Во-вторых, компилятор и интерпретатор байт-кода
В качестве следующего шага в 2014 году я начал работу над scheme-vm — виртуальной машиной для Scheme, написанной на Ruby. Я думал, что виртуальная машина с собственным стеком и байт-кодом станет переходным этапом от интерпретатором с AST-проходами и полноценным компилятором. И поскольку Scheme формально определена, не придётся ничего изобретать.
Я возился со scheme-vm более трёх лет и многое узнал о компиляции. В конце концов, я понял, что не смогу закончить этот проект. Код превратился в настоящий хаос, а конца не было видно. Без наставника или опыта, я словно блуждал в темноте. Как выяснилось, спецификация языка — не то же самое, что руководство по нему. Урок усвоен!
К концу 2017 года я отложил scheme-vm в поисках чего-то лучшего.
Встреча с Mal
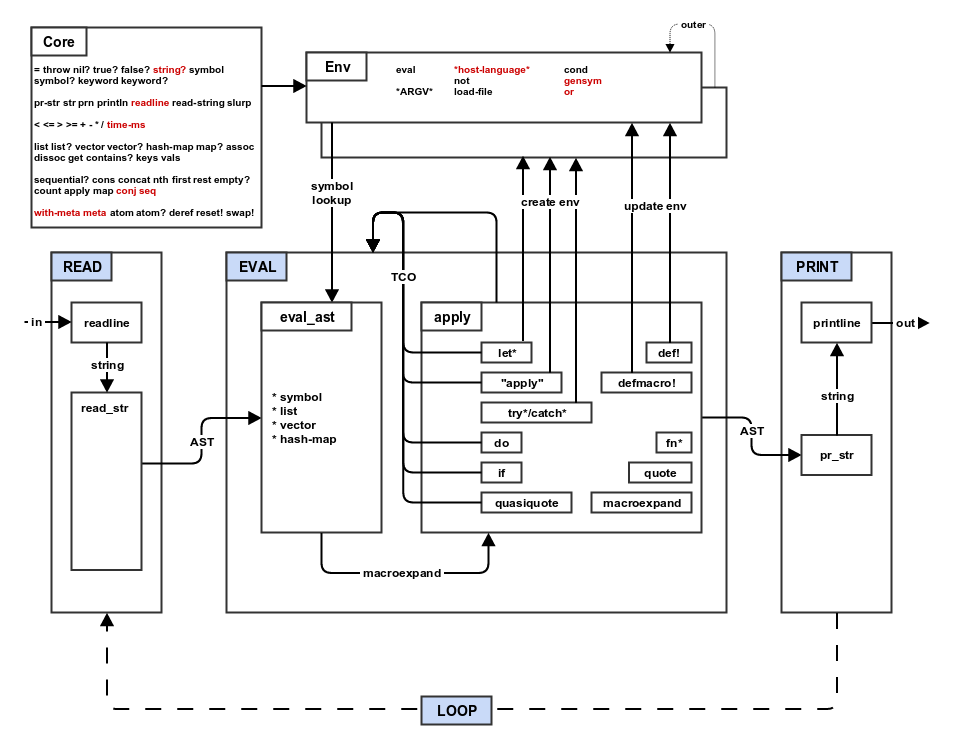
Где-то в 2018 году мне попался Mal — интерпретатор Lisp в духе Clojure.
Mal изобретён Джоэлом Мартином как учебный инструмент. С тех пор разработано более 75 реализаций на разных языках! Когда я смотрел на эти реализации, то понимал, что они очень помогают: если я застрял, то могу пойти поискать подсказки в версии Ruby или Python. Наконец хоть кто-то говорит на моём языке!
Я также подумал, что если смогу написать интерпретатор для Mal, то смогу повторить те же шаги — и сделать компилятор для Mal.
Интерпретатор Mal на Rust
Сначала я приступил к разработке интерпретатора согласно пошаговому руководству. В то время я активно изучал Rust (оставлю это для другой статьи), поэтому написал собственную реализацию Mal на Rust: mal-rust. Подробнее об этом эксперименте см. здесь.
Это была совершенное наслаждение! Не знаю, как выразить благодарность или похвалить Джоэла за создание превосходного руководства по Mal. Каждый шаг описан детально, есть блок-схемы, псевдокод и тесты! Всё, что нужно разработчику, чтобы создать язык программирования от начала до конца.
К концу руководства я сумел запустить свою Mal-реализацию для Mal, написанную на Mal, поверх моей реализации на Rust. (два уровня глубины, ух). Когда она сработала в первый раз, я от волнения запрыгнул на стул!
Компилятор Mal на C
Как только я доказал жизнеспособность mal-rust, то сразу начал исследовать, как написать компилятор. Компилировать в ассемблер? Смогу ли я компилировать непосредственно машинный код?
Я видел ассемблер x86, написанный на Ruby. Он меня заинтриговал, но мысль о работе с ассемблером заставила остановиться.
В какой-то момент я наткнулся на этот комментарий на Hacker News, где упоминался Tiny C Compiler как «бэкенд компиляции». Это показалось отличной идеей!
У TinyCC есть тестовый файл, показывающий, как использовать libtcc для компиляции кода C из программы C. Это стартовая точка для “hello world”.
Опять вернувшись к пошаговому руководству Mal, вспоминая свои знания C, за пару месяцев свободных вечеров и выходных я смог написать компилятор Mal. Это было сплошное удовольствие.
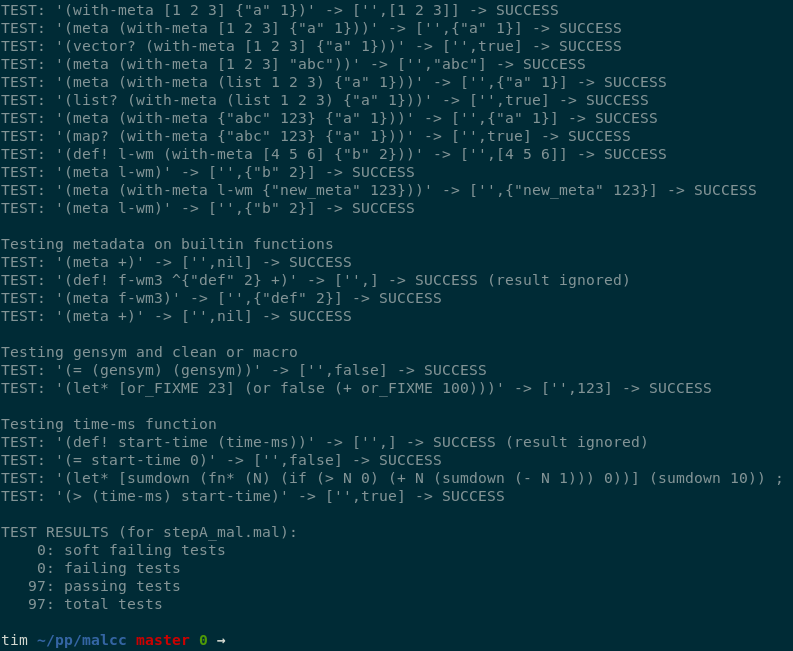
Если вы привыкли к разработке через тестирование, то оце́ните наличие предварительного набора тестов. Тесты ведут к рабочей реализации.
Не могу много сказать об этом процессе, разве что повторю: руководство по Mal — настоящее сокровище. На каждом шагу я точно знал, что нужно делать!
Трудности
Оглядываясь назад, вот некоторые сложности при написании компилятора Mal, где пришлось повозиться:
- Макросы должны компилироваться на лету и быть готовы к выполнению во время компиляции программы. Это слегка озадачивает.
- Нужно обеспечить «окружение» (дерево хэшей / ассоциативных массивов / словарей с переменными и их значениями) как для кода компилятора, так и для итогового кода скомпилированной программы. Это позволяет определять макросы во время компиляции.
- Поскольку среда доступна во время компиляции, изначально Malcc во время компиляции ловил неопределённые ошибки (доступ к переменной, которая не была определена), и в паре мест это нарушило ожидания набора тестов. В конце концов, чтобы пройти тесты, я отключил эту функцию. Было бы здорово добавить её обратно в качестве дополнительного флага компилятора, поскольку так можно заранее выловить много ошибок.
- Я скомпилировал код C, записывая в три строки структуры:
- top : код верхнего уровня — здесь функции
- decl : объявление и инициализация переменных, используемых в теле
- body : тело, где производится основная работа
- Целый день я размышлял, не написать ли собственный сборщик мусора, но решил оставить это упражнение на потом. Библиотека сборщика мусора Boehm-Demers-Weiser легко подключается и доступна для многих платформ.
- Важно просматривать код, который пишет ваш компилятор. Всякий раз, когда компилятор встречал переменную окружения DEBUG , он выдавал скомпилированный код C, где можно просмотреть ошибки.
Что я бы сделал иначе
Теперь совет
Мне нравится, что на компилятор ушло почти десятилетие. Нет, правда. Каждый шаг на пути — это приятное воспоминание, как я постепенно становился всё лучшим программистом.
Но это не значит, что я «закончил». Есть ещё много сотен методов и инструментов, которые нужно изучить, чтобы чувствовать себя настоящим автором компилятора. Но могу уверенно сказать: «Я сделал это».
Вот весь процесс в сжатом виде, как сделать собственный компилятор Lisp:
- Выберите язык, на котором вы чувствуете себя комфортно. Вы же не хотите одновременно изучать новый язык и то, как написать другой новый язык.
- Следуя руководству Mal напишите интерпретатор.
- Порадуйтесь!
- Снова следуйте инструкциям, но вместо выполнения кода напишите код, который выполняет код. (Не просто «рефакторинг» существующего интерпретатора. Надо начать с нуля, хотя копипаст не запрещён).
Я считаю, что этот метод можно использовать с любым языком программирования, который компилируется в исполняемый файл. Например, вы можете:
- Написать интерпретатор Mal на Go.
- Модифицировать ваш код, чтобы:
- создать строку кода Go и записать её в файл;
- скомпилировать этот результирующий файл с помощью go build .
В идеале, лучше контролировать компилятор Go как библиотеку, но это тоже способ сделать компилятор!
С помощью руководства Mal и своей изобретательности вы можете всё это сделать. Если даже я смог, то и вы сможете!
LISP-интерпретатор на чистом C
Я люблю язык C за его простоту и эффективность. Тем не менее, его нельзя назвать гибким и расширяемым. Есть другой простой язык, обладающий беспрецедентной гибкостью и расширяемостью, но проигрывающий C в эффективности использования ресурсов. Я имею в виду LISP. Оба языка использовались для системного программирования и имеют давнюю и славную историю.
Уже достаточно долго я размышляю над идеей, объединяющей подходы обоих этих языков. Её суть заключается в реализации языка программирования на основе LISP, решающего те же задачи, что и C: обеспечение высокой степени контроля над оборудованием (включая низкоуровневый доступ к памяти). На практике это будет система LISP-макросов, генерирующая бинарный код. Возможности LISP для препроцессирования исходного кода, как мне кажется, обеспечат небывалую гибкость, в сравнении с препроцессором C или шаблонами C++, при сохранении исходной простоты языка. Это даст возможность на базе такого DSL надстраивать новые расширения, повышающие скорость и удобство разработки. В частности, на этом языке может реализовываться и сама LISP-система.
Написание компилятора требуют наличие кодогенератора, а в конечном итоге — ассемблера. Поэтому практические изыскания стоит начинать с реализации ассемблера (для подмножества инструкций целевого процессора). Мне было интересно минимизировать какие-либо зависимости от конкретных технологий, языков программирования и операционной системы. Поэтому я решил с нуля реализовать на C простейший интерпретатор импровизированного LISP-диалекта, а также написать к нему систему макрорасширений, позволяющих удобно кодировать на подмножестве ассемблера x86. Венцом моих усилий должен стать результирующий загрузочный образ, выводящий «Hello world!» в реальном режиме процессора.
На текущий момент мною реализован работающий интерпретатор (файл int.c, около 900 строк C-кода), а также набор базовых функций и макросов (файл lib.l, около 100 строк LISP-кода). Кому интересны принципы выполнения LISP-кода, а также подробности реализации интерпретатора, прошу под кат.
Базовой единицей LISP-вычислений является точечная пара (dotted pair). В классическом лиспе Маккарти точечная пара и символ — единственные два типа данных. В практических реализациях этот набор приходится расширять, как минимум, числами. Кроме того, к базовым типам также добавляют строки и массивы (первые являются разновидностью вторых). В стремлении к упрощению есть искушение рассматривать строки в качестве списка чисел, но я сознательно отказался от этой идеи, как от резко ограничивающей возможности языка в реальном мире. В качестве контейнера для чисел решил использовать double.
Итак мы имеем следующие базовые типы данных: точечная пара, символ, число, строка (pascal style, т.к. это даст возможность хранения произвольных бинарных данных в неизменном виде). Поскольку я работаю над интерпретатором (а не над компилятором), можно было ограничиться этим набором (функции и макросы могут быть представлены обычными s-выражениями), но для удобства реализации были добавлены 4 дополнительных типа: функция, макрос, встроенная функция и встроенный макрос. Итак, имеем следующую структуру для s-выражения:
Данная структура не оптимальна с точки зрения экономии ресурсов и производительности, но я не ставил себе цели построить эффективную реализацию. Прежде всего, была важна простота и лаконичность кода. Пришлось даже отказаться от управления памятью: вся память выделяется без освобождения. На самом деле, для моей практической задачи это решение допустимо: интерпретатор не будет работать длительное время: его задача заключается лишь в трансляции кода в бинарную форму.
Как видно из вышеприведённого кода, функция (и макрос) ссылаются на структуру l_env. Она является базовым элементом лексического окружения, хранимого в виде списка. Конечно, это неэффективно, поскольку предполагает последовательный доступ к символам. Зато это очень простая и удобная структура для поддержки локальных переменных: они добавляются в голову списка, когда как глобальные — в хвост. От локальных переменных очень легко избавляться (при выходе из функции или из блока let), просто игнорируя переднюю часть этого списка. Собственное лексическое окружение у функции позволяет реализовывать замыкания.
На базе вышеприведённой структуры s-выражения легко построить функцию его вычисления:
Если вычислимое выражение является символом, мы просто ищем его значение в текущем лексическом окружении (find_symbol). Если вызов функции: вначале вычисляем фактические параметры, используя текущее лексическое окружение (map_eval), затем привязываем их к символам формальных параметров (apply_args) уже в лексическом окружении самой функции. Далее последовательно вычисляем элементы тела на основе полученного лексического окружения, возвращая значение последнего выражения (eval_list). Для вызова макроса порядок вычисления несколько иной. Фактические параметры не вычисляются, а передаются в неизменном виде. Кроме того, результирующее выражение макроса (макроподстановка) подвергается дополнительному вычислению. Числа, строки, функции и макросы вычисляются сами в себя.
Я решил ввести более лаконичные названия для базовых и произвольных функций и макросов. В классическом LISP (и, особенно, в Common Lisp) меня немного напрягает многословность базовых примитивов. С одной стороны, я не хотел усложнять парсер, потому quote и backquote синтаксис им не поддерживается, только скобочная нотация. С другой стороны, стремился компенсировать избыточную скобочность широким использованием специальных символов для лаконичности. Кому-то это покажется весьма спорным решением.
Имена я старался подбирать в соответствии с их ассоциативным рядом:
- _ — заменяет nil
- ! — заменяет lambda
- # — аналогично !, но объявляет безымянный макрос
- ? — заменяет if с обязательным третим параметром
- ^ — заменяет cons
- @ — заменяет car
- % — заменяет cdr
- = — заменяет setq
Соответственно, имена производных функций и макросов во многом стали производными от имён базовых:
- !! — заменяет defun
- ## — заменяет defmacro
- ^^ — заменяет list
- @% — заменяет cadr
- %% — заменяет cddr
- : — заменяет let для одной переменной
- :: — заменяет let без избыточных скобок
- & — заменяет and
- | — заменяет or
Теперь рассмотрим производные определения. Вначале определим базовые сокращения:
Обратите внимание на точечную нотацию списка формальных аргументов. Символ после точки захватывает оставшиеся фактические параметры. Случай, когда все аргументы необязательны, описывается специальной нотацией: (_ . rest-args). Далее определим классический map и два парных разбиения списка:
Определяем два варианта let:
Классический reverse и левую свёртку:
Теперь логические операторы на основе if:
И, наконец, операторы сравнения на основе встроенного > (greater):
Обратите внимание, что в последнем блоке определений явно используется замыкание.



