Работаем с модулями ядра в Linux

Ядро — это та часть операционной системы, работа которой полностью скрыта от пользователя, т. к. пользователь с ним не работает напрямую: пользователь работает с программами. Но, тем не менее, без ядра невозможна работа ни одной программы, т.е. они без ядра бесполезны. Этот механизм чем-то напоминает отношения официанта и клиента: работа хорошего официанта должна быть практически незаметна для клиента, но без официанта клиент не сможет передать заказ повару, и этот заказ не будет доставлен.
В Linux ядро монолитное, т.е. все его драйвера и подсистемы работают в своем адресном пространстве, отделенном от пользовательского. Сам термин «монолит» говорит о том, что в ядре сконцентрировано всё, и, по логике, ничего не может в него добавляться или удаляться. В случае с ядром Linux — это правда лишь отчасти: ядро Linux может работать в таком режиме, однако, в подавляющем большинстве сборок возможна модификация части кода ядра без его перекомпиляции, и даже без его выгрузки. Это достигается путем загрузки и выгрузки некоторых частей ядра, которые называются модулями. Чаще всего в процессе работы необходимо подключать модули драйверов устройств, поддержки криптографических алгоритмов, сетевых средств, и, чтобы уметь это правильно делать, нужно разбираться в строении ядра и уметь правильно работать с его модулями. Об этом и пойдет речь в этой статье.
В современных ядрах при подключении оборудования модули подключаются автоматически, а это событие обрабатывается демоном udev, который создает соответствующий файл устройства в каталоге «/dev». Все это выполняется в том случае, если соответствующий модуль корректно установлен в дерево модулей. В случае с файловыми системами ситуация та же: при попытке монтирования файловой системы ядро подгружает необходимый модуль автоматически, и выполняет монтирование.
Если необходимость в модуле не на столько очевидна, ядро его не загружает самостоятельно. Например, для поддержки функции шифрования на loop устройстве нужно вручную подгрузить модуль «cryptoloop», а для непосредственного шифрования — модуль алгоритма шифрования, например «blowfish».
Поиск необходимого модуля
Модули хранятся в каталоге «/lib/modules/ » в виде файлов с расширением «ko». Для получения списка всех модулей из дерева можно выполнить команду поиска всех файлов с расширением «ko» в каталоге с модулями текущего ядра:
find /lib/modules/`uname -r` -name ‘*.ko’
Полученный список даст некоторое представление о доступных модулях, их назначении и именах. Например, путь «kernel/drivers/net/wireless/rt2x00/rt73usb.ko» явно указывает на то, что этот модуль — драйвер устройства беспроводной связи на базе чипа rt73. Более детальную информацию о модуле можно получить при помощи команды modinfo:
filename: /lib/modules/2.6.38-gentoo-r1/kernel/drivers/net/wireless/rt2x00/rt73usb.ko
license: GPL
firmware: rt73.bin
description: Ralink RT73 USB Wireless LAN driver.
version: 2.3.0
author: rt2x00.serialmonkey.com
depends: rt2x00lib,rt2x00usb,crc-itu-t
vermagic: 2.6.38-gentoo-r1 SMP preempt mod_unload modversions CORE2
parm: nohwcrypt:Disable hardware encryption. (bool)
Поле «firmware» указывает на то, что этот модуль сам по себе не работает, ему нужна бинарная микропрограмма устройства в специальном файле «rt73.bin». Необходимость в файле микропрограммы появилась в связи с тем, что интерфейс взаимодействия с устройством закрыт, и эти функции возложены на файл прошивки (firmware). Взять firmware можно с сайта разработчика, установочного диска, поставляемого вместе с устройством, или где-нибудь в репозиториях дистрибутива, затем нужно его скопировать в каталог «/lib/firmware», при чем имя файла должно совпадать с тем, что указано в модуле.
Следующее поле, на которое нужно обратить внимание — это поле «depends». Здесь перечислены модули, от которых зависит данный. Логично предположить, что модули друг от друга зависят, например модуль поддержки USB накопителей зависит от модуля поддержки USB контроллера. Эти зависимости просчитываются автоматически, и будут описаны ниже.
Последнее важное поле — «param». Здесь описаны все параметры, которые может принимать модуль при загрузке, и их описания. В данном случае возможен только один: «nohwcrypt», который, судя по описанию, отключает аппаратное шифрование. В скобках указан тип значения параметра.
Более подробную информацию о модуле можно прочитать в документации к исходным кодам ядра (каталог Documentation) в дереве исходных кодов. Например, найти код нужного видеорежима драйвера «vesafb» можно в файле документации «Documentation/fb/vesafb.txt» относительно корня дерева исходных кодов.
Загрузка и выгрузка модулей
Загрузить модуль в ядро можно при помощи двух команд: «insmod» и «modprobe», отличающихся друг от друга возможностью просчета и удовлетворения зависимостей. Команда «insmod» загружает конкретный файл с расширением «ko», при этом, если модуль зависит от других модулей, еще не загруженных в ядро, команда выдаст ошибку, и не загрузит модуль. Команда «modprobe» работает только с деревом модулей, и возможна загрузка только оттуда по имени модуля, а не по имени файла. Отсюда следует область применения этих команд: при помощи «insmod» подгружается файл модуля из произвольного места файловой системы (например, пользователь скомпилировал модули и перед переносом в дерево ядра решил проверить его работоспособность), а «modprobe» — для подгрузки уже готовых модулей, включенных в дерево модулей текущей версии ядра. Например, для загрузки модуля ядра «rt73usb» из дерева ядра, включая все зависимости, и отключив аппаратное шифрование, нужно выполнить команду:
# modprobe rt73usb nohwcrypt=0
Загрузка этого модуля командой «insmod» произойдет следующим образом:
# insmod /lib/modules/2.6.38-gentoo-r1/kernel/drivers/net/wireless/rt2x00/rt73usb.ko nohwcrypt=0
Но нужно помнить, что при использовании «insmod» все зависимости придется подгружать вручную. Поэтому эта команда постепенно вытесняется командой «modprobe».
После загрузки модуля можно проверить его наличие в списке загруженных в ядро модулей при помощи команды «lsmod»:
# lsmod | grep rt73usb
| Module | Size | Used by | |
| rt73usb | 17305 | 0 | |
| crc_itu_t | 999 | 1 | rt73usb |
| rt2x00usb | 5749 | 1 | rt73usb |
| rt2x00lib | 19484 | 2 | rt73usb,rt2x00usb |
Из вывода команды ясно, что модуль подгружен, а так же в своей работе использует другие модули.
Чтобы его выгрузить, можно воспользоваться командой «rmmod» или той же командой «modprobe» с ключем «-r». В качестве параметра обоим командам нужно передать только имя модуля. Если модуль не используется, то он будет выгружен, а если используется — будет выдана ошибка, и придется выгружать все модули, которые от него зависят:
# rmmod rt2x00usb
ERROR: Module rt2x00usb is in use by rt73usb
# rmmod rt73usb
# rmmod rt2x00usb
После выгрузки модуля все возможности, которые он предоставлял, будут удалены из таблицы ядра.
Для автоматической загрузки модулей в разных дистрибутивах предусмотрены разные механизмы. Я не буду вдаваться здесь в подробности, они для каждого дистрибутива свои, но один метод загрузки всегда действенен и удобен: при помощи стартовых скриптов. В тех же RedHat системах можно записать команды загрузки модуля прямо в «/etc/rc.d/rc.local» со всеми опциями.
Файлы конфигурация модулей находится в каталоге «/etc/modprobe.d/» и имеют расширение «conf». В этих файлах преимущественно перечисляются альтернативные имена модулей, их параметры, применяемые при их загрузке, а так же черные списки, запрещенные для загрузки. Например, чтобы вышеупомянутый модуль сразу загружался с опцией «nohwcrypt=1» нужно создать файл, в котором записать строку:
options rt73usb nohwcrypt=1
Черный список модулей хранится преимущественно в файле «/etc/modules.d/blacklist.conf» в формате «blacklist ». Используется эта функция для запрета загрузки глючных или конфликтных модулей.
Сборка модуля и добавление его в дерево
Иногда нужного драйвера в ядре нет, поэтому приходится его компилировать вручную. Это так же тот случай, если дополнительное ПО требует добавление своего модуля в ядро, типа vmware, virtualbox или пакет поддержки карт Nvidia. Сам процесс компиляции не отличается от процесса сборки программы, но определенные требования все же есть.
Во первых, нужен компилятор. Обычно установка «gcc» устанавливает все, что нужно для сборки модуля. Если чего-то не хватает — программа сборки об этом скажет, и нужно будет доустановить недостающие пакеты.
Во вторых, нужны заголовочные файлы ядра. Дело в том, что модули ядра всегда собираются вместе с ядром, используя его заголовочные файлы, т.к. любое отклонение и несоответствие версий модуля и загруженного ядра ведет к невозможности загрузить этот модуль в ядро.
Если система работает на базе ядра дистрибутива, то нужно установить пакеты с заголовочными файлами ядра. В большинстве дистрибутивов это пакеты «kernel-headers» и/или «kernel-devel». Для сборки модулей этого будет достаточно. Если ядро собиралось вручную, то эти пакеты не нужны: достаточно сделать символическую ссылку «/usr/src/linux», ссылающуюся на дерево сконфигурированных исходных кодов текущего ядра.
После компиляции модуля на выходе будет получен один или несколько файлов с расширением «ko». Можно попробовать их загрузить при помощи команды «insmod» и протестировать их работу.
Если модули загрузились и работают (или лень вручную подгружать зависимости), нужно их скопировать в дерево модулей текущего ядра, после чего обязательно обновить зависимости модулей командой «depmod». Она пройдется рекурсивно по дереву модулей и запишет все зависимости в файл «modules.dep», который, в последствие, будет анализироваться командой «modprobe». Теперь модули готовы к загрузке командой modprobe и могут загружаться по имени со всеми зависимостями.
Стоит отметить, что при обновлении ядра этот модуль работать не будет. Нужны будут новые заголовочные файлы и потребуется заново пересобрать модуль.
«Слушаем» что говорит ядро
При появлении малейших неполадок с модулем, нужно смотреть сообщения ядра. Они выводятся по команде «dmesg» и, в зависимости от настроек syslog, в файл «/var/log/messages». Сообщения ядра могут быть информативными или отладочными, что поможет определить проблему в процессе работы модуля, а могут сообщать об ошибке работы с модулем, например недостаточности символов и зависимостей, некорректных переданных параметрах. Например, выше рассмотренный модуль «rt73usb» требует параметр типа bool, что говорит о том, что параметр может принимать либо «0», либо «1». Если попробовать передать «2», то система выдаст ошибку:
# modprobe rt73usb nohwcrypt=2
FATAL: Error inserting rt73usb (/lib/modules/2.6.38-gentoo-r1/kernel/drivers/net/wireless/rt2x00/rt73usb.ko): Invalid argument
Ошибка «Invalid argument» может говорить о чем угодно, саму ошибку ядро на консоль написать не может, только при помощи функции «printk» записать в системный лог. Посмотрев логи можно уже узнать в чем ошибка:
# dmesg | tail -n1
rt73usb: `2′ invalid for parameter `nohwcrypt’
В этом примере выведена только последняя строка с ошибкой, чтобы не загромаждать статью. Модуль может написать и несколько строк, поэтому лучше выводить полный лог, или хотя бы последние строк десять.
Ошибку уже легко найти: значение «2» неприемлемо для параметра «nohwcrypt». После исправления, модуль корректно загрузится в ядро.
Из всего сказанного можно сделать один вывод: ядро Linux играет по своим правилам и занимается серьезными вещами. Тем не менее — это всего лишь программа, оно, по сути, не сильно отличается от других обычных программ. Понимание того, что ядро не так уж страшно, как кажется, может стать первым шагом к пониманию внутреннего устройства системы и, как результат, поможет быстро и эффективно решать задачи, с которыми сталкивается любой администратор Linux в повседневной работе.
Источник
Конфигурирование и компиляция ядра Linux
Когда возникает необходимость создания мощной и надёжной системы на основе Linux (будь то обслуживание технологических процессов, веб-хостинга и т. д.), то очень часто приходится настраивать системное ядро таким образом, чтобы вся система работала более эффективно и надёжно. Ядро Linux хоть и является универсальным, однако бывают ситуации, когда его необходимо «подтюнинговать» по объективным причинам. Да и сама архитектура ядра это предполагает благодаря своей открытости. Таким образом, системные администраторы Linux – это те люди, которым важно знать и понимать некоторые общие аспекты конфигурирования ядра Linux.
Способы конфигурации ядра Linux
За время развития Linux постепенно сложились четыре основных способа для конфигурирования её ядра:
- модификация настраиваемых параметров ядра;
- сборка ядра из исходных кодов с внесением нужных изменений и/или дополнений в тексты исходных кодов ядра;
- динамическое подключение новых компонентов (функциональных модулей, драйверов) к существующей сборке ядра;
- передача специальных инструкций ядру во время начальной загрузки и/или используя загрузчик (например GRUB).
В зависимости от конкретной ситуации следует использовать тот или иной способ. Но сразу необходимо отметить, что на самом деле самым простым является первый — настройка параметров ядра. Самым же сложным является компиляция ядра из исходных кодов.
Настраиваемые параметры ядра
Системное ядро Linux разрабатывалось таким образом, чтобы всегда была возможность его максимально гибко (впрочем, как и всё в системах UNIX и Linux) настроить, адаптируя его к требуемым условиям эксплуатации и аппаратному окружению. Причём так, чтобы это было возможно динамически на готовой сборке ядра. Другими словами, системные администраторы могут в любой момент времени вносить корректирующие параметры, влияющие на работу как самого ядра, так и его отдельных компонентов.
Для реализации этой задачи между ядром и программами пользовательского уровня существует специальный интерфейс, основанный на информационных каналах. Через эти каналы и направляются инструкции, задающие значения для параметров ядра.
Но как и всё в системах UNIX и Linux, настройка параметров ядра по информационным каналам завязана на файловой системе. Чтобы просматривать конфигурацию ядра и управлять ею, в файловой системе в каталоге /proc/sys существуют специальные файлы. Это обычные файлы, но они играют роль посредников в предоставления интерфейса для динамического взаимодействия с ядром. Однако документация, касающаяся этого аспекта, в частности об описании конкретных параметров и их значений довольно скудна. Одним из источников, из которого можно почерпнуть некоторые сведения по этой теме, является подкаталог Documentation/sysent в каталоге с исходными кодами ядра.
Для наглядности стоит рассмотреть небольшой пример, показывающий, как через параметр ядра настроить максимальное число одновременно открытых файлов в системе:
Как можно видеть, к такому приёму можно довольно быстро привыкнуть и это не будет казаться чем-то очень сложным. Такой метод хоть и удобен, однако изменения не сохраняются после перезапуска системы.
Также можно использовать специализированную утилиту sysctl. Она позволяет получить значения переменных прямо из командной строки, либо список пар вида переменная=значение из файла. На этапе начальной загрузки утилита считывает начальные значения некоторых параметров, которые заданы в файле /etc/sysctl.conf. Более подробную информацию об утилите sysctl можно найти на страницах man-руководства.
В следующей таблице приводятся некоторые настраиваемые параметры ядра:
| Каталог | Файл/параметр | Назначение |
| С | autoeject | Автоматическое открывание лотка с компакт-диском при размонтировании устройства CD-ROM |
| F | file-max | максимальное число открытых файлов. Для систем, которым приходится работать с большим количеством файлов, можно увеличивать это значение до 16384 |
| F | inode-max | Максимальное число открытых индексных дескрипторов в одном процессе. Полезно для приложений, которые открывают десятки тысяч дескрипторов файлов |
| К | ctrl-alt-del | Перезагрузка системы при нажатии комбинации клавиш . |
| К | printk ratelimit | Минимальный интервал между сообщениями ядра, в секундах |
| К | printk_ratelimi_burst | Количество сообщений, которые должны быть получены, перед тем как значение минимального интервала между сообщениями printk станет активным |
| К | shmmax | Максимальный размер совместно используемой памяти |
| N | conf/default/rp_filter | Включает механизм проверки маршрута к исходному файлу |
| N | icmp_echo_ ignore_all | Игнорирование ICMP-запросов, если значение равно 1 |
| N | icmp_echo_ broadcasts | Игнорирование широковещательных ICMP-запросов, если значение равно 1. |
| N | ip_forward | Перенаправление IP-пакетов, если значение равно 1. Например, когда машина на Linux используется как маршрутизатор, то это значение нужно устанавливать равным 1 |
| N | ip_local_port_ range | Диапазон локальных портов, выделяемый при конфигурировании соединений. Для повышения производительности серверов, инициирующих много исходящих соединений, этот параметр нужно расширить до 1024-65000 |
| N | tcp_fin_timeout | Интервал для ожидания (в секундах) заключительного RN-пакета. В целях повышения производительности серверов, которые пропускают большие объемы трафика, нужно устанавливать более низкие значения (порядка 20) |
| N | tcp_syncookies | Защита от атак волнового распространения SYN-пакетов. Нужно включать при наличии вероятности DOS-атак |
Условные обозначения: F — /proc/sys/fs, N — /proc/sys/net/ipv4, К — /proc/sys/kernel, С — /proc/sys/dev/cdrom.
В результате выполнения этой команды будет отключено перенаправление IP-пакетов. Есть одна особенность для синтаксиса этой команды: символы точки в «net.ipv4.ip_forward» заменяют символы косой черты в пути к файлу ip_forward.
Когда нужно собирать новую версию ядра?
В настоящее время ядро Linux развивается очень быстро и бурно. Зачастую производители дистрибутивов не успевают внедрять в свои системы новые версии ядер. Как правило все новомодные «фишки» больше понадобятся любителям экзотики, энтузиастам, обладателям новинок устройств и оборудования и просто любопытствующим — т. е. преимущественно тем, в чьём распоряжении имеется обычный пользовательский компьютер.
Для серверных машин, однако, мода вряд ли имеет какое-то значение, а новые технологии внедряются только после того как на практике доказали свою надёжность и эффективность на тестовых стендах или даже платформах. Каждый опытный системный администратор знает, что гораздо надёжнее один раз настроить то, что может и должно хорошо и безотказно работать, чем пытаться бесконечно модернизировать систему. Ведь для этого необходимы многие часы работы (ведь приходится собирать ядро из исходных кодов, что довольно сложно) и обслуживания, что довольно дорогостоящее занятие, поскольку, вдобавок ко всему прочему требует глубокого резервирования — сервера не должны останавливаться без организации «горячего» (а уж тем более без «холодного») резерва.
Поэтому всегда стоит взвешивать все факторы и оценить, стоит ли вообще обновляться ради несущественных заплат, не влияющих на работу системы или внедрённых новых драйверов для устройств, коих в данный момент в системе нет и нескоро предвидится.
Если же принято решение обновить версию ядра путём его самостоятельной сборки, то нужно выяснить, является ли данная версия стабильной. Раньше система нумерования версий ядра Linux была организована таким образом, что чётные номера версий означали стабильный выпуск, нечётные — ещё «сырой». В настоящее время этот принцип соблюдается далеко не всегда и выяснять этот момент следует из информации на официальном сайте kernel.org.
Конфигурирование параметров ядра
Конфигурация для будущей сборки ядра Linux хранится в файле .config. Мало кто занимается ручным созданием и редактированием этого файла, поскольку, во-первых: это сложный синтаксис, который далеко не самый «человекопонятный», и во-вторых: существуют способы для автоматической генерации конфигурации сборки ядра с удобным графическим (или псевдографическим) интерфейсом. Список основных команд для конфигурирования сборки ядра:
- make xconfig – рекомендуется, если используется графическая среда KDE. Весьма удобный инструмент;
- make gconfig – лучший вариант для использования в графической среде GNOME;
- make menuconfig – данную утилиту следует использовать в псевдографическом режиме. Она не так удобна, как две предыдущие, однако со своими функциями справляется достойно;
- make config – самый неудобный «консольный» вариант, выводящий запросы на задание значений каждого параметра ядра. Не позволяет изменить уже заданные параметры.
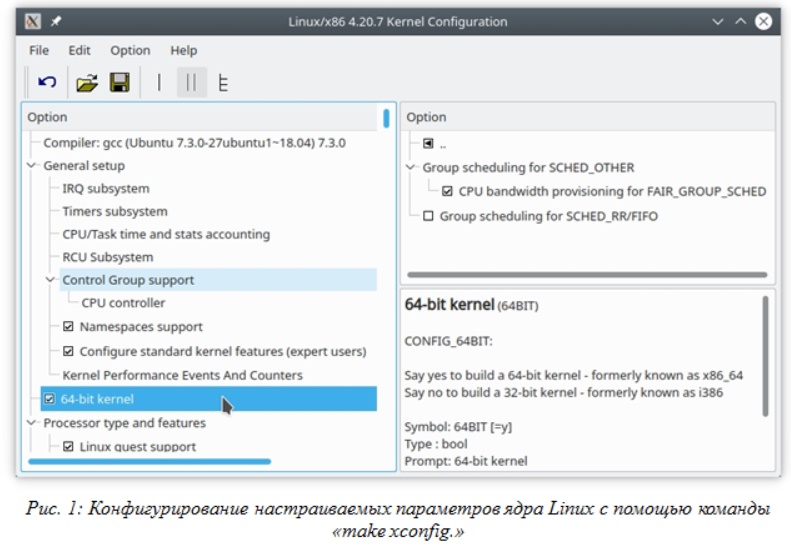
Практически все варианты (за исключением последнего) позволяют получать краткую справку по каждому параметру, производить поиск нужного параметра (или конфигурационного раздела), добавлять в конфигурацию дополнительные компоненты, драйверы, а также показывают, каким образом конкретный компонент может быть сконфигурирован — как компонент, встроенный в ядро или как загружаемый модуль, а также поддерживает ли он вообще вариант компиляции в качестве загружаемого модуля.

Очень полезной может оказаться команда make oldconfig, предназначенная для переноса существующей конфигурации с другой версии (сборки) ядра в новый билд. Эта команда читает конфигурацию из перенесенного из другой сборки файла .config со старой сборкой, определяет, какие новые параметры доступны для актуальной сборки и предлагает их включить или оставить как есть.
Для выполнения конфигурации сборки ядра Linux нужно перейти в каталог с исходными кодами и запустить одну из команд генерации конфигурации.
В результате работы вышеуказанных команд будет сгенерирован файл .conf, фрагмент содержимого из которого может быть следующим:
Как можно видеть, в данном коде нет ничего привлекательного для ручного редактирования, о чём даже упоминает запись комментария в начале файла .config. Символ «y» в конце какой-либо из строк указывает, что соответствующий компонент будет скомпилирован в составе ядра, «m» — как подключаемый модуль. Расшифровки или описания о каждом компоненте или параметре в файле .config не содержится — по этим вопросам следует изучать соответствующую документацию.
Компиляция ядра
Самое сложное в компиляции ядра Linux – это создание конфигурации сборки, поскольку нужно знать, какие компоненты подключать. Хотя использование команд make xconfig, make gconfig, make menuconfig и обеспечивает задание стандартной рабочей конфигурации, с которой система будет работать на большинстве аппаратных платформ и конфигураций. Вопрос лишь в том, чтобы грамотно задать конфигурацию ядра без ненужных и занимающих лишние ресурсы компонентов при его работе.
Итак, для успешного конфигурирования и компиляции ядра нужно выполнить следующие действия:
- перейти в каталог с исходными кодами ядра. Обычно «исходники» для ядра Linux помещаются в каталог /usr/src, либо можно скачать с сайта kernel.org в любое удобное место;
- выполнить команду make xconfig, make gconfig или make menuconfig;
- выполнить команду make dep (можно не выполнять для ядер версии 2.6.x и более поздних);
- выполнить команду make clean (для очистки от всего того, что может помешать успешной сборке);
- выполнить команду make;
- выполнить команду make modules_install;
- скопировать файл /arch/имя_архитектуры/boot/bzImage в /boot/vmlinuz. Здесь каталог /arch находится в каталоге с исходными кодами ядра Linux, имя_архитектуры — каталог, имеющий имя соответствующей архитектуры (указанной на этапе конфигурирования). Имя собранного бинарного образа ядра bzImage может быть другим;
- скопировать файл /arch/имя_архитектуры/boot/System.map в /boot/System.map;
- внести изменения в конфигурационные файлы системных загрузчиков /etc/lilo.conf (для LILO) или /boot/grub/grub.conf — для GRUB, а также добавить в них соответствующие конфигурационные и параметры загрузки для нового ядра.
Далее остаётся протестировать загрузку и работу нового ядра. В случае проблем обычно подбираются нужные параметры для системных загрузчиков.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник



