Символы кириллицы в консоли Windows
Ходят упорные слухи, что в Linux нет проблем с работой с кириллицей в консоли. Эта статья для тех, кому повезло меньше — для виндузятников.
Проблема заключается в том, что когда в Microsoft придумывали Windows, то попутно придумали новую кодировку для кириллицы. Трудно сказать зачем, но придумали. А старую кодировку, которая использовалась в MS DOS, оставили. Видимо в целях обратной совместимости. И случилась жопа. С выходом новых версий Windows ситуация только ухудшилась. Т.к. консоль, уже как часть операционной системы, унаследовала кодировку кириллицы от MS DOS.
В итоге сейчас для кириллицы имеем две кодировки: cp866 — старая досовская кодировка и cp1251 (она же windows-1251) — новая, от Windows. В настоящее время дело осложняется тем, что окончательно созрел Unicode, что дает еще несколько кодировок не совместимых с cp1251 и с cp866, и не совсем совместимых между собой. Но о Unicode как-нибудь в другой раз.
Кстати, буковки «cp» в названии кодировки означает codepage — кодовая страница в смысле «страница кодировки символов».
Кроме того, консоль имеет собственную настройку кодовой страницы. Для России по умолчанию — cp866. (Локализация самой винды, по видимому, роли не играет). Настройка кодовой страницы консоли может быть изменена командой chcp .
Итак, при написании программ строки могут встречаться в двух различных кодировках в следующих местах:
- В исходных текстах программ в виде литералов.
- Вывод на консоль.
- Ввод с консоли.
- Вывод в файл.
- Ввод из файла.
Кроме того, винда при вводе и выводе кириллицы где-то в своих глубинах может делать некие преобразования кодировок, выдавая результаты, не поддающиеся расшифровке.
Первое правило при работе с национальными алфавитами: все строки должны быть в единой кодировке.
При несоблюдении этого правила будет невозможно сравнение и сортировка строк (а также и символов), и будет затруднён корректный ввод и вывод строк на консоль или в файл.
Еще один подводный камень:
В окне консоли, использующем растровые шрифты (Raster fonts), корректно отображается только кодовая страница оригинального производителя оборудования (OEM), установленная с Windows XP. Другие кодовые страницы отображаются корректно в полноэкранном режиме или в окне консоли, которое использует шрифты True Type.
При этом в самой консоли отображение кириллицы при вводе (в командной строке) работает даже при использовании растровых шрифтов.
Второе правило при работе с национальными алфавитами: в настройках консоли установите для вывода шрифт True Type.
Сделать это можно следующим способом:
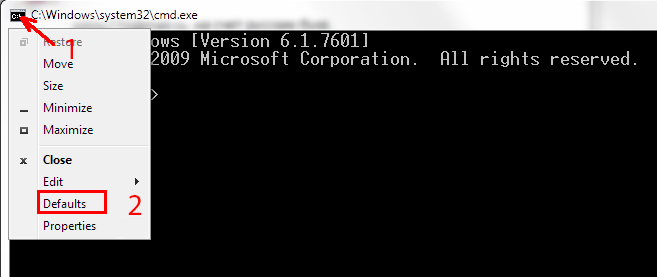
- Запустите командную строку
- Откройте контекстное меню и зайдите в настройки консоли

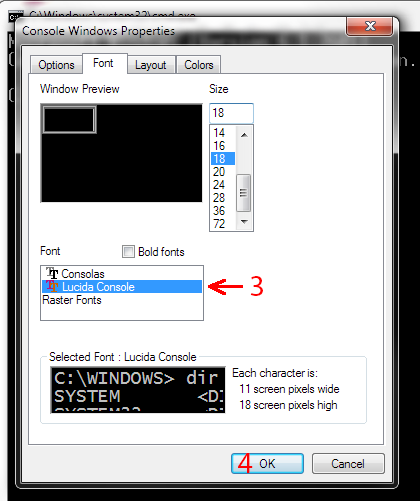
- Измените шрифт на Lucida Console.
И еще. Похоже, что ни Unicode, ни UTF-8, ни мультибайтовые строки в консоли напрямую не поддерживаются. По крайней мере, у меня с ними ничего путного не вышло.
Далее несколько советов для борьбы с этими проблемами.
Самый простой (и самый неудобный) способ
Работать в «родной» для консоли кодовой странице, в cp866. Т.е. все строки с кириллицей в исходном коде программы должны быть написаны в кодировке cp866. В этой же кодировке должны быть все входные файлы для программы. И в этой же кодировке будут и все выходные файлы. Полное впечатление, что мы вернулись на 20 лет назад, в MS DOS.
Если под рукой есть IDE, которая работает в консоли — особых проблем не возникнет. Если же использовать среду разработки под Windows GUI, то возникают вполне понятные сложности, поскольку IDE обычно работают в кодировке cp1251, «родной» для Windows. Кстати, как бы ни хаяли MS Visual Studio, она умеет работать с исходными текстами программ в различных кодировках, корректно их отображая в своем редакторе.
Вывод на консоль Windows 7
Способ подходит, если необходим только вывод кириллицы на консоль, и вы работаете под Windows 7. Под Windows XP это не работает (прим. редактора — все работает).
Самое простое — использовать функцию setlocale() :
Функция setlocale() устанавливает или изменяет для текущей программы информацию о национальной специфике (то, что задается в апплете Region and Language в Control panel). Описание функции можно найти в MSDN.
Также популярен урезанный вариант вызова:
Здесь используется, что символ LC_ALL равен 0 и подразумевается, что в операционной системе установлена страна пребывания Россия (локализация самой Винды роли не играет). Но лучше все-таки использовать полную форму.
Функция достаточно капризная. Это касается второго параметра. Некоторые значения, которые указаны в документации, могут на каких-то системах (компиляторах?) не работать.
Ввод и вывод на консоль
Для корректного ввода и вывода кириллицы на консоль надо использовать пару функций: SetConsoleOutputCP() и SetConsoleCP() . Описания в MSDN здесь и здесь соответственно.
В качестве единственного параметра обеим функциям передается номер кодовой страницы. В нашем случае (кириллица) — это 1251.
Этот способ работает и для Windows XP, и для Windows 7. Опробовано с Dev-C++ 5.6.3 (компилятор TDM-GCC 4.8.1 и MS Visual Studio 2012.
Следующая тестовая программа демонстрирует вывод кириллицы на консоль, ввод кириллической строки с консоли, контрольный вывод введенной строки, сравнение введенной строки с эталонной и вывод введенной строки в файл.
Исходный текст в кодировке cp1251:
Эта программа также удобна для экспериментов с различными кодовыми таблицами и их сочетаниями.
Для практических целей можно использовать шаблон:
Здесь я намеренно оставил закомментированный вызов setlocale(LC_ALL, «Russian»); . На ввод-вывод кириллицы он уже не влияет, но может потребоваться для других национальных настроек (разделитель дробной части числа, формат даты, времени и пр.)
Функции перекодировки
В Windows API есть две (а точнее, четыре пары) функции, осуществляющие перекодировку OEM ANSI (так сказано в документации). Проще говоря, в контексте рассматриваемого вопроса, это перекодировка между cp866 (OEM) и cp1251 (ANSI).
«Опасные» функции без контроля длины строки:
В качестве параметров получают указатели на входной и выходной буферы. Нулевой символ считается концом входной строки.
«Безопасные» функции с контролем длины строки:
В качестве параметров получают указатели на входной и выходной буферы и количество символов для входной строки. Нулевые символы не считаются концом строки. Преобразуется указанное количество символов.
На самом деле перечисленные функции являются макросами, которые раскрываются, к примеру для CharToOemBuff , в CharToOemBuffW (при поддержке Unicode) или в CharToOemBuffA (ANSI — без поддержки Unicode). Но о таких тонкостях обычно можно не вспоминать.
Эти функции полезны, когда вывод идёт в одной кодировке, а ввод — в другой. Такая ситуация складывается, например, при использовании только функции setlocale() : вывод осуществляется в cp1251, а ввод — в cp866. Следуя первому правилу, введенную строку надо преобразовать к cp1251. Для этого используется OemToCharBuff() .
Также эти функции могут быть использованы перед выводом строки в файл или после ввода строки из файла, в случае, если кодировки не совпадают.
P. S. Не судите строго — это мой первый опыт в написании статьи. Я так посмотрел, люди пишут, а чем я хуже? Тем более, что появилось чем поделиться. А оказалось, что это трудно. И написать, и ошибки проверить, и иллюстрации подготовить.
На написание статьи меня сподвиг вопрос о «кракозябрах в XP». Под это дело из руин даже был извлечен старый комп с XP. И оказалось, что проблема действительно имеет место. Пришлось провести небольшое исследование, результаты которого я здесь и изложил. Также скомпилировал доступную информацию по этой теме из материалов сайта, что бы все было в одном месте. Насколько у меня это получилось — решать вам. Буду рад замечаниям и дополнениям в комментариях к статье.
Русский язык в консоли
Учу C++ по книжке Страуструпа, не выводятся русские символы. Вот код:
«Повторяющееся слово: » — отображается нормально благодаря setlocale. То что после — крякозяблы, хотя повторяющееся слова находит. setlocale пробовал разные (0, «»), «», «Rus» и пр.
В Code::Blocks всё работает и без крякозяблов. Даже без setlocale.

5 ответов 5
Для данной задачи существует множество решений. Если вам нужно быстрое и не обязательно универсальное решение, чтобы сильно не разбираться, прокручивайте к разделу «Менее правильные, но пригодные решения».
Правильное, но сложное решение
Для начала, проблема у консоли Windows состоит в том, что её шрифты, которые стоят «по умолчанию», показывают не все символы. Вам следует сменить шрифт консоли на юникодный, это позволит работать даже на английской Windows. Если вы хотите поменять шрифт только для вашей программы, в её консоли нажмите на иконку в левом верхнем углу → Свойства → Шрифт. Если хотите поменять для всех будущих программ, то же самое, только заходите в Умолчания, а не Свойства.
Lucida Console и Consolas справляются со всем, кроме иероглифов. Если ваши консольные шрифты позволят, вы сможете вывести и 猫 , если нет, то лишь те символы, которые поддерживаются.
Дальнейшее рассмотрение касается лишь Microsoft Visual Studio. Если у вас другой компилятор, пользуйтесь предложенными на свой страх и риск, никакой гарантии нету.
Теперь, кодировка входных файлов компилятора. Компилятор Microsoft Visual Studio (по крайней мере, версии 2012 и 2013) компилирует исходники в однобайтных кодировках так, как будто бы они на самом деле в ANSI-кодировке, то есть для случая русской системы — CP1251. Это означает, что кодировка исходников в CP866 — неправильна. (Это важно, если вы используете L». » -строки.) С другой стороны, если вы храните исходники в CP1251, то эти же исходники не будут нормально собираться на нерусской Windows. Поэтому стоит хранить исходники в Unicode (например, UTF-8).
Настроив среду, перейдём к решению собственно задачи.
Правильным решением является уйти от однобайтных кодировок, и использовать Unicode в программе. При этом вы получите правильный вывод не только кириллицы, но и поддержку всех языков (изображение отсутствующих в шрифтах символов будет отсутствовать, но вы сможете с ними работать). Для Windows это означает переход с узких строк ( char* , std::string ) на широкие ( wchar_t* , std::wstring ), и использование кодировки UTF-16 для строк.
(Ещё одна проблема, которую решает использование широких строк: узкие строки при компиляции кодируются в однобайтную кодировку используя текущую системную кодовую страницу, то есть, ANSI-кодировку. Если вы компилируете вашу программу на английской Windows, это приведёт к очевидным проблемам.)
Вам нужно _setmode(_fileno(. ), _O_U16TEXT); для переключения режима консоли:
Такой способ должен работать правильно с вводом и выводом, с именами файлов и перенаправлением потоков.
Важное замечание: потоки ввода-вывода находятся либо в «широком», либо в «узком» состоянии — то есть, в них выводится либо только char* , либо только wchar_t* . После первого вывода переключение не всегда возможно. Поэтому такой код:
вполне может не сработать. Используйте только wprintf / wcout .
Если очень не хочется переходить на Unicode, и использовать однобайтную кодировку, будут возникать проблемы. Для начала, символы, не входящие в выбранную кодировку (например, для случая CP1251 — базовый английский и кириллица), работать не будут, вместо них будет вводиться и выводиться абракадабра. Кроме того, узкие строковые константы имеют ANSI-кодировку, а это значит, что кириллические строковые литералы на нерусской системе не сработают (в них будет зависимая от системной локали абракадабра). Держа в голове эти проблемы, переходим к изложению следующей серии решений.
Менее правильные, но пригодные решения
В любом случае, поставьте юникодный шрифт в консоли. (Это первый абзац «сложного» решения.)
Убедитесь, что ваши исходники в кодировке CP 1251 (это не само собой разумеется, особенно если у вас не русская локаль Windows). Если при добавлении русских букв и сохранении Visual Studio ругается на то, что не может сохранить символы в нужной кодировке, выбирайте CP 1251.
(1) Если компьютер ваш, вы можете поменять кодовую страницу консольных программ на вашей системе. Для этого сделайте вот что:
- Запустите Regedit.
- На всякий пожарный экспортируйте куда-нибудь реестр (этот шаг все почему-то пропускают, так что когда всё сломается, мы вас предупреждали).
- В разделе HKEY_CURRENT_USER\Console найдите ключ CodePage (если нету, создайте ключ с таким названием и типом DWORD ).
- Установите значение по ключу (левая клавиша/изменить/Система счисления = десятичная) на 1251.
- Не забудьте перегрузиться после изменений в реестре.
Преимущества способа: примеры из книг начнут работать «из коробки». Недостатки: смена реестра может повлечь за собой проблемы, кодировка консоли меняется глобально и перманентно — это может повлиять сломать другие программы. Плюс эффект будет только на вашем компьютере (и на других, у которых та же кодировка консоли). Плюс общие проблемы неюникодных способов.
Примечание. Установка глобальной кодовой страницы консоли через параметр реестра HKEY_CURRENT_USER\Console\CodePage не работает в Windows 10, вместо него будет использована кодовая страница OEM — предположительно баг в conhost. При этом установка кодовой страницы консоли на уровне конкретного приложения ( HKEY_CURRENT_USER\Console\(путь к приложению)\CodePage ) работает.
(2) Вы можете поменять кодировку только вашей программы. Для этого нужно сменить кодировку консоли программным путём. Из вежливости к другим программам не забудьте потом вернуть кодировку на место!
Это делается либо при помощи вызова функций
в начале программы, либо про помощи вызова внешней утилиты
(То есть, у вас должно получиться что-то вроде
и дальше обыкновенный код программы.)
Можно обернуть эти вызовы в класс, чтобы воспользоваться плюшками автоматического управления временем жизни объектов C++.
(если выполняете задание из Страуструпа можно вставить в конец заголовочного файла std_lib_facilities.h )
Если вам нужен не русский, а какой нибудь другой язык, просто замените 1251 на идентификатор нужной кодировки (список указан ниже в файле), но, разумеется, работоспособность не гарантируется.
Остались методы, которые тоже часто встречаются, приведём их для полноты.
Методы, которые работают плохо (но могут помочь вам)
Метод, который часто рекомендуют — использование конструкции setlocale(LC_ALL, «Russian»); У этого варианта (по крайней мере в Visual Studio 2012) гора проблем. Во-первых, проблема с вводом русского текста: введённый текст передаётся в программу неправильно! Нерусский текст (например, греческий) при этом вовсе не вводится с консоли. Ну и общие для всех неюникодных решений проблемы.
Ещё один метод, не использующий Unicode — использование функций CharToOem и OemToChar . Этот метод требует перекодировки каждой из строк при выводе, и (кажется) слабо поддаётся автоматизации. Он также страдает от общих для неюникодных решений недостатков. Кроме того, этот метод не будет работать (не только с константами, но и с runtime-строками!) на нерусской Windows, т. к. там OEM-кодировка не будет совпадать с CP866. В дополнение можно так же сказать что эти функции поставляются не со всеми версиями Visual Studio — например в некоторых версиях VS Express их просто нет.
Поэтому стоит хранить исходники в Unicode (например, UTF-8).
Причем сохранить следует с сигнатурой
Ситуацию частично спасает пересохранение исходников в кодировке UTF-8 с обязательным символом BOM, без него Visual Studio начинает интерпретировать «широкие» строки с кириллицей весьма своеобразно. Однако, указав BOM (Byte Order Mark — метка порядка байтов) кодировки UTF-8 — символ, кодируемый тремя байтами 0xEF, 0xBB и 0xBF, мы получаем узнавание кодировки UTF-8 в любой системе
Стоит пояснить кое-что для тех, кто ищет правильный ответ по поводу функции setlocale:
Метод, который часто рекомендуют — использование конструкции setlocale(LC_ALL, «Russian»); У этого варианта (по крайней мере в Visual Studio 2012) гора проблем. Во-первых, проблема с вводом русского текста: введённый текст передаётся в программу неправильно! Нерусский текст (например, греческий) при этом вовсе не вводится с консоли. Ну и общие для всех неюникодных решений проблемы.
Я добавлю по этому методу побольше информации: Его вообще не правильно рекомендуют!
Начнём с первого: Во втором параметре функция принимает не название страны или языка, хотя в некоторых случаях она сработает, а языковый идентификатор, согласно ISO 3166-1. Поэтому правильно и корректно указывать: «ru-RU». Теперь второе: в документации к этой функции написано чёрным по белому: «If execution is allowed to continue, the function sets errno to EINVAL and returns NULL.» Что буквально толкуется: при возникновении ошибки, функция устанавливает значение переменной errno в EINVAL и возвращает NULL.
В случае возникновения ошибки, errno всегда будет равен EINVAL, что означает: не верный аргумент. Поэтому её проверять нет смысла, а вот исполнение функции должно быть проверено. Поэтому правильный вызов функции setlocale выглядит следующим образом:
И не забывайте, что setlocale устанавливает локальную таблицу только для ANSI кодировки, поэтому и не будут отображаться греческие, испанские, китайские и даже японские знаки. Для русского языка это будет таблица номер 1251.
И важно: почему эта функция является надёжней, нежели прямая установка таблицы символов через SetConsoleCP, ибо потому, что она переключает все внутренние надстройки именно для раскладки под язык. Начиная от стандарта отображения даты, заканчивая знаками разделителя.
И да, не стоит устанавливать языковый указатель виде «ru», так как в зависимости от сборки самой ось и имеющихся языковых пакетов, может установиться ru-BY, ru-UA, ru-MO и другие языковые стандарты, значительно отличающиеся от ru-RU. И категорично нельзя указывать «Russia», «Russian», «Russian Federation» (да, такую вакханалию уже встречал пару раз). Хотя функция производит проверку и по названию региона, не всегда в таблице локализации это указано, или может быть указано «Россия» или «Русский» уже на нашей раскладке. Это и есть основная ошибка, из-за которой функция setlocale зачастую отказывается работать.
И да, для приложения, работающего в режиме юникогда, стоит использовать функцию _wsetlocale. Она идентична, и также устанавливает базовые настройки для локализации. Кроме того, если проект приложения в Visual Studio настроен в режим юникода, то и будет работать только _wsetlocale, так как setlocale, по документации, не приспособлена к работе с юникодом вообще никак.
UPD.
Совсем забыл указать, что функция setlocale и _wsetlocale, в случае успеха вернёт именно идентификатор региона. То есть, в нашем случае строку «ru_RU\0».



