Мониторинг сети Linux
В этой статье мы поговорим про некоторые инструменты командной строки Linux, которые можно использовать для мониторинга использования сети. Мониторинг сети Linux осуществляется множеством способов. Эти инструменты контролируют трафик, проходящий через сетевые интерфейсы, и измеряют скорость, с которой в настоящее время передаются данные. Входящий и исходящий трафик отображается отдельно.
В некоторых командах показана пропускная способность, используемая отдельными процессами. Это упрощает обнаружение процесса, который перегружает пропускную способность сети.
Инструменты имеют разные механизмы формирования отчета о трафике. Некоторые из инструментов, таких как nload, читают файл «/ proc / net / dev» для получения статистики трафика, тогда как некоторые инструменты используют библиотеку pcap для захвата всех пакетов, а затем вычисляют общий размер для оценки нагрузки трафика.
Мониторинг сети Linux
Ниже приведен список команд, отсортированных по их функциям.
- Общая пропускная способность — nload, bmon, slurm, bwm-ng, cbm, спидометр, netload
- Общая пропускная способность (выход пакетного стиля) — vnstat, ifstat, dstat, collectl
- Ширина полосы пропускания для каждого сокета — iftop, iptraf, tcptrack, pktstat, netwatch, trafshow
- Пропускная способность для каждого процесса — nethogs
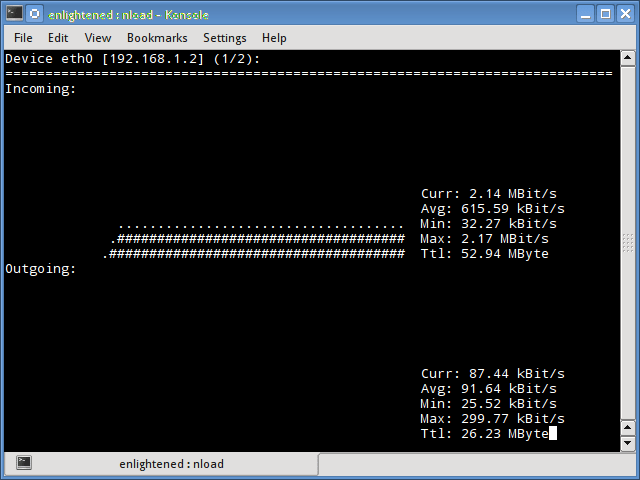
Nload
Nload — это инструмент командной строки, который позволяет пользователям контролировать входящий и исходящий трафик отдельно. Он также выводит график, указывающий то же самое, масштаб которого можно отрегулировать. Прост в использовании и не поддерживает множество опций.
Поэтому, если вам просто нужно быстро взглянуть на использование общей пропускной способности без подробностей отдельных процессов, то достаточно будет ввести nload в терминал.
Чтобы выйти мониторинга сети, достаточно нажать клавишу Q
Установить nload в Debian или Ubuntu можно из репозиториев по-умолчанию:
Пользователи CentOS или Fedora могут установить nload командой:
Если в CentOS при установке возникли проблемы, то скорее всего вам нужно подключить epel
А затем ввести команду установки nload заново.
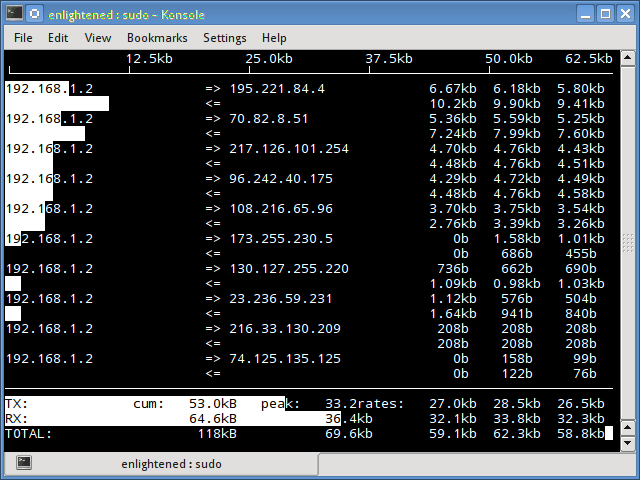
iftop
Мониторинг сети Linux является довольно легким в освоении. Для этого существует огромное количество вариантов. Вы можете выбрать самый удобный для вас. Iftop измеряет данные, проходящие через отдельные соединения сокетов, и работает таким образом, который отличается от Nload. Iftop использует библиотеку pcap для захвата пакетов, перемещающихся в и из сетевого адаптера, а затем суммирует размер и количество, чтобы найти общую используемую ширину полосы пропускания.
Несмотря на то, что iftop сообщает пропускную способность, используемую отдельными соединениями, он не может сообщить имя / идентификатор процесса, участвующего в конкретном подключении сокета. Но, основываясь на библиотеке pcap, iftop может фильтровать трафик и использовать пропускную способность для передачи по выбранным узловым соединениям, как это определено фильтром.
Опция n не позволяет iptop отыскивать IP-адреса на имя хоста, что вызывает дополнительный сетевой трафик.
Установить iftop в Debian или Ubuntu можно из репозиториев по-умолчанию.
Пользователи CentOS или Fedora могут установить iftop командой:
Если в CentOS при установке возникли проблемы, то скорее всего вам нужно подключить Epel
А затем ввести команду установки iftop заново.
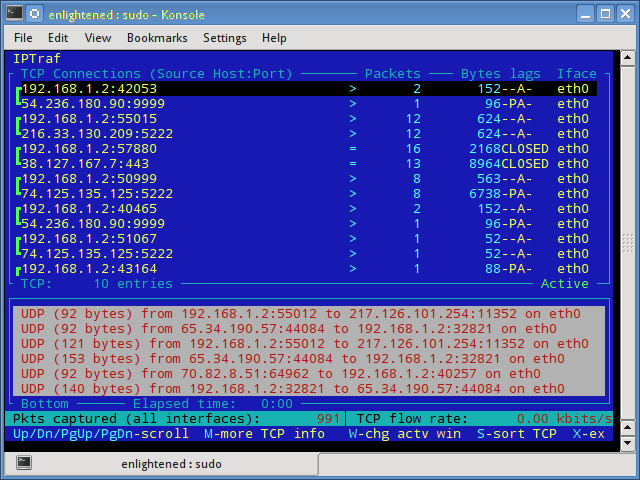
iptraf
Iptraf — это интерактивный и красочный монитор IP Lan. Он показывает индивидуальные соединения и объем данных, передаваемых между хостами. Вот скриншот
Установка iptraf в Ubuntu или Debian:
Установка iptraf в CentOS или Fedora
Если в CentOS при установке возникли проблемы, то скорее всего вам нужно подключить epel
А затем ввести команду установки iptraf заново.
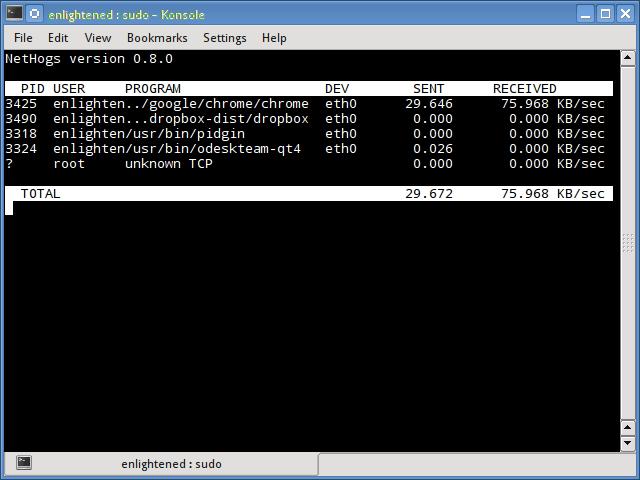
Nethogs
Nethogs — это небольшой инструмент «net top», который показывает пропускную способность, используемую отдельными процессами, и сортирует список, в котором самые интенсивные процессы находятся сверху. В случае внезапного скачка полосы пропускания быстро открывайте nethogs и найдите ответственный за процесс. Nethogs сообщает PID, пользователя и путь программы.
Установка nethogs в Ubuntu или Debian:
Установка nethogs в CentOS или Fedora
Если в CentOS при установке возникли проблемы, то скорее всего вам нужно подключить epel
А затем ввести команду установки nethogs заново.
Bmon (Bandwidth Monitor) — это инструмент, аналогичный nload, который показывает нагрузку на трафик по всем сетевым интерфейсам в системе. Вывод также состоит из графика и раздела с деталями уровня пакета. Bmon поддерживает множество опций и способен создавать отчеты в формате html.
Монитор сети bmon linux
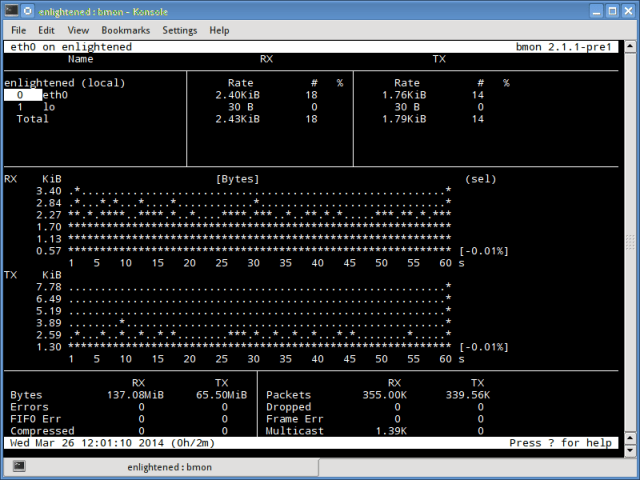
Установка bmon в Ubuntu или Debian:
Установка bmon в Fedora
Slurm
Slurm является еще одним монитором сетевой нагрузки, который показывает статистику устройства вместе с графиком ascii. Он поддерживает 3 разных стиля графиков, каждый из которых может быть активирован с помощью клавиш c, s и l. Простой в функциях, slurm не отображает никаких дополнительных сведений о сетевой нагрузке.
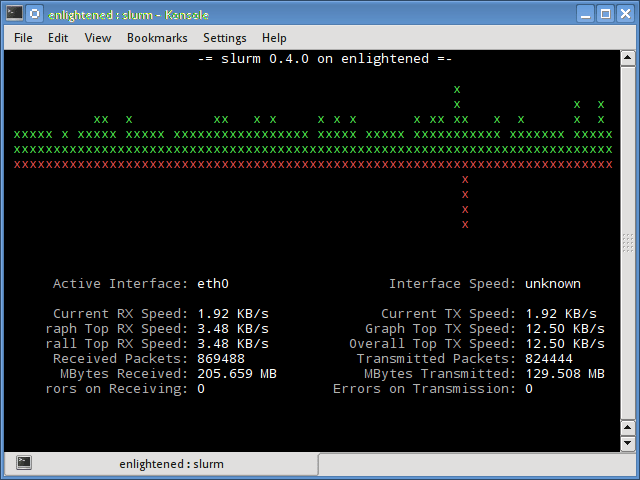
Установить slurm в Debian или Ubuntu
Установить slurm в Fedora или CentOS
Tcptrack
Tcptrack похож на iftop и использует библиотеку pcap для захвата пакетов и вычисления различной статистики, такой как пропускная способность, используемая в каждом соединении. Он также поддерживает стандартные фильтры pcap, которые можно использовать для контроля определенных соединений.
Установка tcptrack в Ubuntu или Debian:
Установка tcptrack в Fedora
Vnstat
Vnstat немного отличается от большинства других инструментов где Мониторинг сети Linux является основой. На самом деле он запускает фоновый сервис / daemon и постоянно фиксирует размер передачи данных. Кроме того, его можно использовать для создания отчета об истории использования сети.
Запуск vnstat без каких-либо параметров просто покажет общий объем передачи данных, который произошел с момента запуска демона.
Чтобы отслеживать использование полосы пропускания в реальном времени, используйте параметр «-l» (режим «вживую»). Затем она покажет общую пропускную способность, используемую входящими и исходящими данными, но очень точным образом, без каких-либо внутренних сведений о хостах или процессах.
Vnstat больше походит на инструмент для получения исторических отчетов о том, как много трафика используется каждый день или в течение последнего месяца. Это не строго инструмент для мониторинга сети в реальном времени.
Vnstat поддерживает множество опций, подробности о которых можно найти на странице руководства.
Установить vnstat в Debian или Ubuntu
Установить vnstat в Fedora или CentOS
Если в CentOS при установке возникли проблемы, то скорее всего вам нужно подключить epel
А затем ввести команду установки vnstat заново.
bwm-ng
Bwm-ng (Bandwidth Monitor Next Generation) является еще одним очень простым монитором сетевой нагрузки в режиме реального времени, который сообщает сводную информацию о скорости передачи данных и из всех доступных сетевых интерфейсов в системе.
Если размер консоли достаточно велик, bwm-ng также может отображать гистограммы для трафика, используя режим вывода curses2.
Установка bwm-ng в Ubuntu или Debian
Установка bwm-ng в Fedora или CentOS
Если в CentOS при установке возникли проблемы, то скорее всего вам нужно подключить epel
А затем ввести команду установки bwm-ng заново.
Небольшой простой монитор пропускной способности, отображающий объем трафика через сетевые интерфейсы. Нет дополнительных параметров, просто статистика трафика отображается и обновляется в реальном времени.
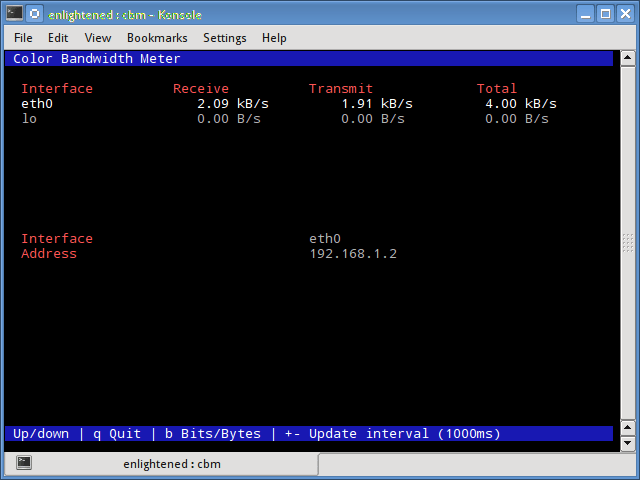
Установка cbm в Ubuntu или Debian
Установка cbm в Fedora или CentOS
Если в CentOS при установке возникли проблемы, то скорее всего вам нужно подключить epel
А затем ввести команду установки cbm заново.
speedometer
Еще один маленький и простой инструмент, который мы должны были добавить в статью про Мониторинг сети Linux, который просто рисует красиво выглядящие графики входящего и исходящего трафика через данный интерфейс.
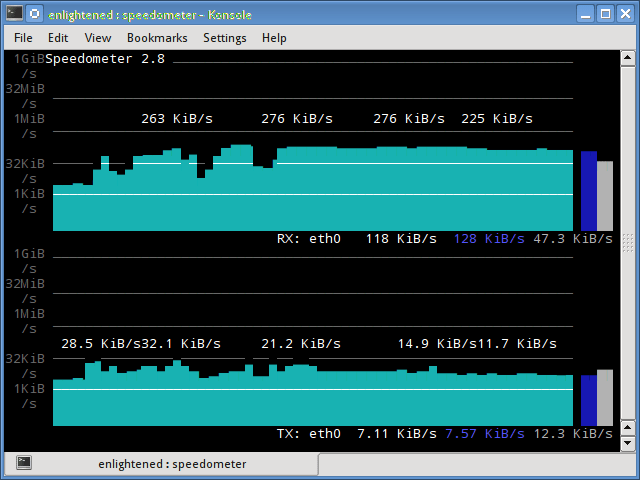
Установка speedometer в Ubuntu или Debian
Pktstat
Pktstat отображает все активные соединения в реальном времени и скорость, с которой данные передаются через них. Он также отображает тип соединения, т. Е. Tcp или udp, а также информацию о HTTP-запросах, если они задействованы.
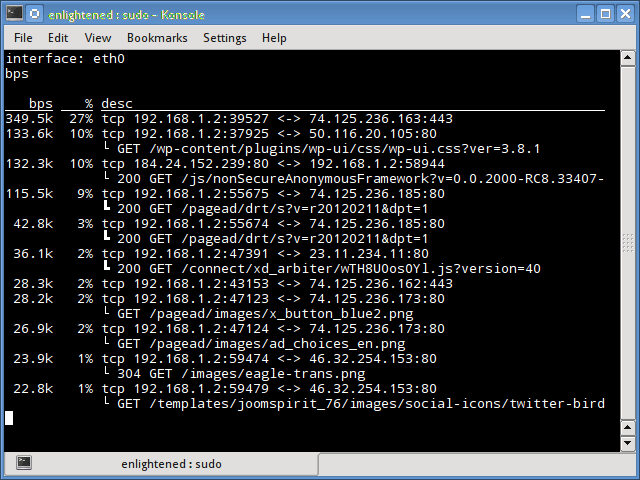
Установка speedometer в Ubuntu или Debian
Netwatch
Netwatch является частью коллекции инструментов netdiag, и она также отображает соединения между локальным хостом и другими удаленными узлами и скорость передачи данных по каждому соединению.
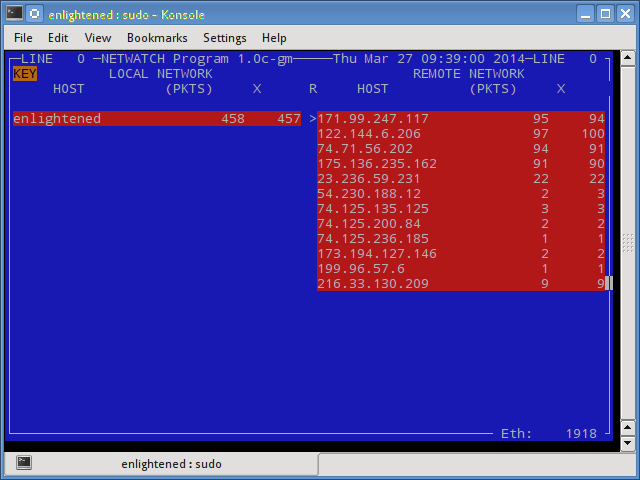
Установка netwatch в Ubuntu или Debian (является частью netdiag)
Trafshow
Как и netwatch и pktstat, trafshow сообщает о текущих активных соединениях, их протоколе и скорости передачи данных в каждом соединении. Он может отфильтровывать соединения, используя фильтры типа pcap.
Кстати, если говорить про Мониторинг сети Linux то здесь можно отметить также и этот способ. Trafshow является таким же удобным как и его аналоги.
Мониторинг только соединений TCP
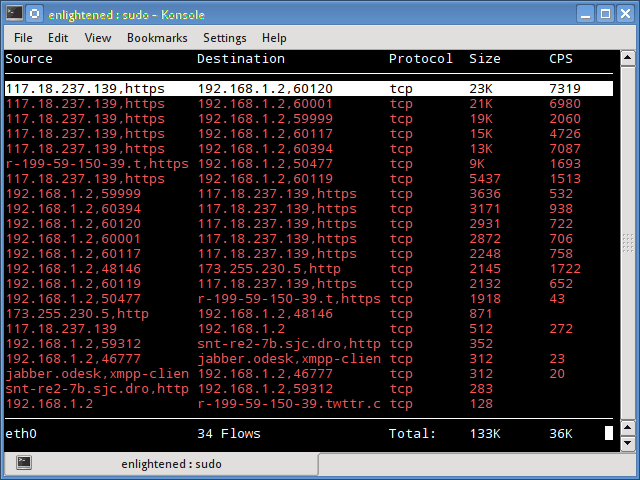
Установка trafshow в Ubuntu или Debian (является частью netdiag)
Установка trafshow в Fedora или Centos
Если в CentOS при установке возникли проблемы, то скорее всего вам нужно подключить epel
А затем ввести команду установки trafshow заново.
Netload
Команда netload просто отображает небольшой отчет о текущей нагрузке на трафик и общее количество байтов, переданных с момента запуска программы. Нет больше функций. Его часть netdiag.
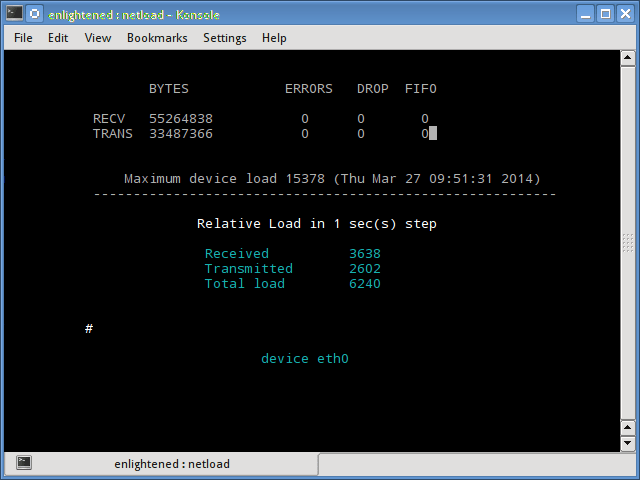
Установка netload в Ubuntu или Debian (является частью netdiag)
ifstat
Ifstat сообщает о пропускной способности сети в режиме пакетного стиля. Выходной файл находится в формате, который легко регистрируется и анализируется с помощью других программ или утилит.
Установка ifstat в Ubuntu или Debian
Установка ifstat в Fedora
Установка ifstat в CentOS. Необходимо сначала подключить RepoForge. Инструкцию можно увидеть здесь. Затем ввести:
dstat
Dstat — это универсальный инструмент (написанный на python), который может отслеживать различные системные статистики и сообщать о них в режиме пакетного стиля или записывать данные в файл csv или аналогичный файл. В этом примере показано, как использовать dstat для передачи информации о пропускной способности сети
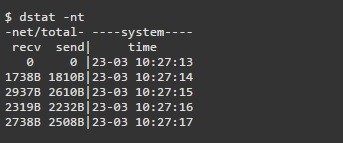
Установка dstat в Ubuntu или Debian
collectl
Collectl сообщает системную статистику в стиле, подобном dstat, и, подобно dstat, собирает статистику о различных различных системных ресурсах, таких как процессор, память, сеть и т. Д. Ниже приведен простой пример того, как использовать его для отчета об использовании сети / пропускной способности .
Установка collectl в Ubuntu или Debian
Установка collectl в Fedora
Выводы
Как и говорили вначале, мы рассказали про несколько удобных команд, для того чтобы быстро проверить пропускную способность сети на вашем Linux-сервере. Однако им нужно, чтобы пользователь заходил на удаленный сервер через ssh. В качестве альтернативы для одной и той же задачи можно использовать веб-инструменты мониторинга.
Ntop и Darkstat — это одни из основных сетевых средств мониторинга сети, доступных для Linux. Помимо этого, инструменты мониторинга уровня предприятия, такие как Nagios, предоставляют множество функций, позволяющих не только контролировать сервер, но и всю инфраструктуру.
Если у вас остались какие-то вопросы по теме «Мониторинг сети Linux» то, пишите нам про них в форму комментариев на сайте. Спасибо за визит!
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Ограничиваем входящий и исходящий трафик в Linux
В данной статье хочу рассказать, как я строил систему ограничения входящего и исходящего трафика в Linux.
Как и учет трафика, ограничение полосы пропускания в сети является очень важной задачей, хотя первое с каждым годом всё быстрее отходит на второй план, шейпинг трафика остается необходимой задачей каждого системного/сетевого администратора.
Какие есть способы ограничения трафика?
Для того, чтобы ответить на этот вопрос нужно определиться для чего этот трафик ограничивать вообще.
Взяв за основу мою сеть из, примерно, 50 рабочих мест, которые выходят в интернет через шлюз, под управлением ОС Ubuntu и некоторые из пользователей пользуются локальными ресурсами на этом сервере по протоколу SMB.
Моя цель ограничить пользователям скорость передачи данных в Интернет со справедливым разделением полосы пропускания между ними.
Исходя из моих задач, для ограничения полосы пропускания можно использовать следующие методы:
1. Ограничение с помощью прокси-сервера Squid.
Данный метод позволяет довольно гибко контролировать весь www,ftp трафик пользователей с возможностью гибкого ограничения скорости пропускания.
2. Использование traffic control из iproute2.
Очень гибкий и оптимальный метод ограничения трафика, но не предоставляющий контроля над WWW трафиком, как в предыдущем методе.
3. Конечно возможно ограничить скорость путём использования модуля –m limit для iptables – но считаю это неприемлемым.
В общем я решил остановиться на методе ограничения трафика с помощью пакета iproute2.
Как уже упоминал, я использую сервер: OS Ubuntu 10.04, ядро 2.6.32-30. В сервере 3 интерфейса: eth0 – внутренняя сеть, eth1 — провайдер 1, eth2 – провайдер 2.
Задача: ограничить скорость входящего и исходящего трафика пользователей с приоритезацией трафика по классам, исходя из некоторых условий. Локальный трафик не ограничивать.
Представим ситуацию, когда пользователь установил соединение с youtube.com и смотрит какой-нибудь ролик в HD-качестве. Основная часть трафика направляется от сервера, в данном случае youtube.com к пользователю. Учитывая, что весь трафик проходит через наш шлюз, мы можем повлиять на скорость передачи этого трафика путем установки шейпера трафика на интерфейсе внутренней сети.
Похожая ситуация происходит, когда пользователь загружает фотоотчет о проведенном отпуске, состоящий из 300 фотографий в разрешении 5000х3500 пикселей на какой-нибудь сервис хранения фотографий в интернете.
Естественно, что при отсутствии системы ограничения трафика этот пользователь займёт весь канал и остальным пользователям не будет предоставлена нормальная скорость работы с Интернет. Но мы не может ограничить скорость отправки данных пользователем на внешнем интерфейсе сервера, т.к. для доступа пользователей в Интернет используется NAT, а, учитывая, что шейпинг трафика выполняется после преобразования адресов, то на внешнем интерфейсе сервера уже не будет пакетов с внутренними адресами сети.
Для решения проблемы ограничения исходящего от клиента трафика я использовал устройство IFB, на которое перенаправлял весь исходящий от клиента трафик.
В теории управления трафиком мы можем ограничивать только исходящий трафик. Следовательно, трафик, который направляется к пользователю внутренней сети, будет исходящим относительно внутреннего интерфейса eth0, а трафик, направляющийся от пользователя внутренней сети – исходящим относительно внешнего интерфейса eth1.
Исходя из вышеизложенного, я ограничивал входящий к пользователю трафик на интерфейсе внутренней сети — eth0, а исходящий от пользователя трафик – на виртуальном интерфейсе ifb0.
Для того чтобы во время занятия пользователем всей полосы пропускания, ограниченной ему на шлюзе, для скачивания какого-нибудь большого объема данных и при этом мог нормально пользоваться ssh и чтобы у него работал ping – я использовал приоритезацию трафика.
Я расставил следующие приоритеты трафика:
- icmp
- udp,ssh
- tcp sport 80
- остальной неклассифицированный трафик
Чем ниже параметр – тем выше приоритет трафика.
Дисциплины, классы, фильтры
Как уже было мной отмечено, входящий к пользователям трафик будет ограничиваться на интерфейсе eth0, а исходящий от пользователей – на виртуальном интерфейсе ifb0.
Для инициализации интерфейса ifb0 нужно сначала загрузить модуль управления интерфейсом:
/sbin/modprobe ifb
После успешной загрузки модуля нужно включить интерфейс:
/sbin/ip link set dev ifb0 up
Затем, после того, как интерфейс будет поднят, нужно организовать переадресацию всего исходящего трафика от пользователей на этот интерфейс:
/sbin/tc qdisc add dev eth0 ingress
/sbin/tc filter add dev eth0 parent ffff: protocol ip u32 match u32 0 0 action mirred egress redirect dev ifb0
Теперь можно смело начинать строить классы и фильтры для входящего к пользователям трафика на интерфейсе eth0, а исходящего – на интерфейсе ifb0.
Для ограничения трафика используется следующий принцип:
- На интерфейсе создается, так называемый корневой обработчик очереди
- К этой дисциплине прикрепляется класс, который одержит информацию о максимальной пропускной способности данных, которые в этот класс попадут
- Добавляется фильтр, который, с помощью определенных параметров, относит каждый пакет к тому или иному классу
Классы могут быть вложенными. То есть, если класс 1: описывает максимальную пропускную способность в 1Мбит, то класс 1:1, который является его подклассом, не может превысить ограничения по скорости его родителя.
Ограничиваем входящий к пользователям трафик
Все манипуляции с трафиком будем проводить на интерфейсе eth0.
Для начала создадим корневой обработчик очереди на интерфейсе:
/sbin/tc qdisc add dev eth0 root handle 1: htb default 900
Тем самым мы привязали корневой обработчик очереди к интерфейсу eth0, присвоили ему номер 1: и указали на использование планировщика HTB с отправкой всего неклассифицированного трафика в класс с номером 900.
Затем создадим дочерний класс 1:1 с шириной канала, равной скорости интерфейса:
/sbin/tc class add dev eth0 parent 1: classid 1:1 htb rate 100Mbit burst 15k
Все последующие классы будут подклассами только что созданного нами класса. Это дает нам более точную приоритезацию и обработку скорости потока данных.
Создадим класс для локального трафика, адресом назначения или исходным адресом которого будет являться внутренний адрес сервера. Это нужно для удобства пользования ресурсами сервера, такими как SSH, SMB, FTP, WWW и так далее. Скорость, описанная классом – 50Mbit, но в случае, если скорость потока родительского класса не меньше 100Mbit, то разрешаем использовать 80Mbit, в качестве максимальной скорости передачи данных.
/sbin/tc class add dev eth0 parent 1:1 classid 1:10 htb rate 50Mbit ceil 80Mbit burst 15k
Далее создаем класс, скорость которого будет равно ширине полосы пропускания, которую нам предоставляет провайдер. В моем случае – это 15Mbit.
/sbin/tc class add dev eth0 parent 1:1 classid 1:100 htb rate 15Mbit burst 15k
Даже если провайдер предоставляет большую скорость, к примеру 18Mbit, я рекомендую снижать эту скорость для шейпера на 1-2 Mbit для более «мягкого» ограничения трафика.
Далее создадим класс, в который будут отправляться все пакеты данных, которые не попадут ни в один из созданных ранее классов.
/sbin/tc class add dev eth0 parent 1:1 classid 1:900 htb rate 56Kbit ceil 128Kbit
Для каждого пользователя я создавал отдельный подкласс, с выделенной полосой пропускания, а затем создавал подклассы этого класса для приоритезации трафика:
/sbin/tc class add dev eth0 parent 1:100 classid 1:101 htb rate 4Mbit ceil 6Mbit
Данной командой мы указали на создание класса с номером 1:101, который является подклассом класса с номером 1:100 и указали пропускную способность класса в 4Mbit, а в случае свободной полосу пропускания у родительского класса, разрешить максимальное прохождение данных по классу на скорости 6Mbit.
Далее создаем подклассы для приоритезации трафика:
# PRIO 1 -> icmp traffic — самый низкий приоритет
/sbin/tc class add dev eth0 parent 1:101 classid 1:102 htb rate 33kbit ceil 6Mbit prio 1
# PRIO 2 -> udp, ssh
/sbin/tc class add dev eth0 parent 1:101 classid 1:103 htb rate 33kbit ceil 6Mbit prio 2
# PRIO 3 -> tcp sport 80 – WWW трафик из мира
/sbin/tc class add dev eth0 parent 1:101 classid 1:104 htb rate 33kbit ceil 6Mbit prio 3
# PRIO 4 -> unclassified traffic – трафик, который не попал под условия, указанные в предыдущих классах
/sbin/tc class add dev eth0 parent 1:101 classid 1:105 htb rate 33kbit ceil 6Mbit prio 4
После создания классов пришло время создания фильтров, которые будут классифицировать трафик по определенным критериям.
Есть несколько способов классифицировать трафик.
Самые удобные из них – это u32 классификаторы, позволяющие классифицировать пакеты исходя из адреса назначения или отправителя, используемого протокола, номера порта и так далее, и классификаторы на основе меток iptables. Для использования последних необходимо сначала маркировать пакеты при помощи iptables в цепочке PREROUTING, на основе каких-либо условий, а затем при помощи tc направлять пакеты с соответствующей меткой в нужные классы.
Я предпочел использовать u32 классификатор.
Присваиваем icmp-трафику самый низкий приоритет и отправляем его в класс 1:102
/sbin/tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32 match ip dst 192.168.10.78 \
match ip protocol 1 0xff flowid 1:102
UDP и SSH трафик отправляем в класс 1:103
/sbin/tc filter add dev eth0 protocol ip parent 1:0 prio 2 u32 match ip dst 192.168.10.78 \
match ip protocol 17 0xff flowid 1:103
/sbin/tc filter add dev eth0 protocol ip parent 1:0 prio 2 u32 match ip dst 192.168.10.78 \
match ip protocol 6 0xff match ip sport 22 0xffff flowid 1:103
WWW-трафик, пришедший с tcp-порта 80 отправляем в класс 1:104
/sbin/tc filter add dev eth0 protocol ip parent 1:0 prio 3 u32 match ip dst 192.168.10.78 \
match ip protocol 6 0xff match ip sport 80 0xffff flowid 1:104
Трафик, не соответствующий ни одному из условий отправляем в класс 1:105
/sbin/tc filter add dev eth0 protocol ip parent 1:0 prio 4 u32 match ip dst 192.168.10.78 flowid 1:105
Приоритезация работает по такому принципу, что каждому классу выделяется по минимальной полосе пропускания с возможностью заимствования у родительского класса максимальной полосы пропускания, в зависимости от приоритета трафика, поэтому, если класс будет забит WWW-трафиком с tcp-порта 80, при прохождении icmp пакета с более низким приоритетом, чем у WWW-трафика, он будет пропущен вне очереди, учитывая его приоритет.
Ограничиваем исходящий трафик
Для ограничения исходящего от пользователей трафика выполняются такие же действия как и для входящего, только в ход идет виртуальный интерфейс ifb0. Также нужно изменить назначение следования трафика: вместо dst 192.168.10.78 – нужно указать src 192.168.10.78 соответственно.
Автоматизация и принцип работы скриптов
Для начала, для автоматизации процесса ограничения скорости нужно создать файл, в котором будет перечислены адреса пользователей, для которых нужно устанавливать ограничения с указанием этих ограничений.
Файл представляет из себя поля, разделенный знаком табуляции либо пробелом со следующими значениями:
CLIENT – Имя пользователя. Нужно для удобства предоставления данных
IP – адрес пользователя в сети
DOWN – скорость потока данных к пользователю
CEIL – максимальная скорость входящего трафика к пользователю при доступности данной полосы у родительского класса
UP — скорость потока данных от пользователя
CEIL – то же, что и у CEIL для входящего трафика к пользователю
PROVIDER – какой из провайдеров используется для обслуживания запросов пользователя (при наличии нескольких)
ID – номер класса для пользователя. Подробнее о номерах классов ниже.
Также я использую несколько bash-скриптов.
root@steel:/etc/rc.d/shape# cat ./rc.shape
#!/bin/bash
. /etc/init.d/functions
/sbin/modprobe ifb
/sbin/ip link set dev ifb0 up
TC=»/sbin/tc»
DEV_P1_DOWN=»eth0″
DEV_P1_UP=»ifb0″
stop() <
$TC qdisc del dev $DEV_P1_DOWN root
$TC qdisc del dev $DEV_P1_UP root
$TC qdisc del dev $DEV_P1_DOWN ingress
>
start() <
# Удаляем все обработчики на интерфейсе
$TC qdisc del dev $DEV_P1_DOWN root
$TC qdisc del dev $DEV_P1_UP root
$TC qdisc del dev $DEV_P1_DOWN ingress
## Перенаправляем весь исходящий от пользователей трафик на виртуальный интерфейс ifb0
$TC qdisc add dev $DEV_P1_DOWN ingress
$TC filter add dev $DEV_P1_DOWN parent ffff: protocol ip u32 match u32 0 0 action mirred egress redirect dev $DEV_P1_UP
# Подгружаем скрипты с описанием классов входящего и исходящего трафика
# Весь трафик, который следует на шлюз или от него ограничиваем в 50Мбит с максимумом в 80Мбит.
$TC filter add dev $DEV_P1_UP protocol ip parent 1:0 prio 1 u32 match ip dst 10.0.0.1 flowid 1:10
$TC filter add dev $DEV_P1_DOWN protocol ip parent 1:0 prio 1 u32 match ip src 10.0.0.1 flowid 1:10
# Подгружаем скрипт с описанием фильтров
. /etc/rc.d/shape/rc.shape.filters
>
Далее код, который подгружается:
root@steel:/etc/rc.d/shape# cat ./rc.shape.down.classes
#!/bin/bash
## DOWNLOAD CLASSES
##########################################################
# Создаем корневой обработчик очереди
$TC qdisc add dev $DEV_P1_DOWN root handle 1: htb default 900
# Описание классов для входящего к пользователям трафика
$TC class add dev $DEV_P1_DOWN parent 1: classid 1:1 htb rate 100Mbit burst 15k
# Локльный трафик (SERVER -> CLIENTS)
$TC class add dev $DEV_P1_DOWN parent 1:1 classid 1:10 htb rate 50Mbit ceil 80Mbit burst 15k
# Трафик от провайдера (SERVER -> CLIENTS)
$TC class add dev $DEV_P1_DOWN parent 1:1 classid 1:100 htb rate 15Mbit burst 15k
# Неклассифицированный трафик будет отправлен в этот класс (SERVER -> CLIENTS)
$TC class add dev $DEV_P1_DOWN parent 1:1 classid 1:900 htb rate 128Kbit ceil 128Kbit
root@steel:/etc/rc.d/shape# cat ./rc.shape.up.classes
#!/bin/bash
## UPLOAD CLASSES
#############################################################
# Создаем корневой обработчик очереди
$TC qdisc add dev ifb0 root handle 1: htb default 900
# Описание классов для исходящего от пользователей трафика
$TC class add dev ifb0 parent 1: classid 1:1 htb rate 100Mbit burst 15k
# Локальный трафик (CLIENTS -> SERVER)
$TC class add dev $DEV_P1_UP parent 1:1 classid 1:10 htb rate 50Mbit ceil 80Mbit burst 15k
# Трафик к провайдеру (CLIENTS -> SERVER)
$TC class add dev $DEV_P1_UP parent 1:1 classid 1:100 htb rate 5Mbit burst 15k
# Неклассифицированный трафик будет отправлен в этот класс (CLIENTS -> SERVER)
$TC class add dev $DEV_P1_UP parent 1:1 classid 1:900 htb rate 128Kbit ceil 128Kbit
root@steel:/etc/rc.d/shape# cat ./rc.shape.filters
#!/bin/bash
# читаем построчно файл “users”
while read LINE
do
set — $LINE
if [[ $1 =
# создаем отдельный подкласс для пользователя
$TC class add dev $DEV_P1_DOWN parent 1:100 classid 1:$<8>1 htb rate $CLIENT_DOWN_RATE ceil $CLIENT_DOWN_CEIL
# PRIO 1 -> icmp traffic
$TC class add dev $DEV_P1_DOWN parent 1:$<8>1 classid 1:$<8>2 htb rate 33kbit ceil $CLIENT_DOWN_CEIL prio 1
# PRIO 2 -> udp, ssh
$TC class add dev $DEV_P1_DOWN parent 1:$<8>1 classid 1:$<8>3 htb rate 33kbit ceil $CLIENT_DOWN_CEIL prio 2
# PRIO 3 -> tcp sport 80
$TC class add dev $DEV_P1_DOWN parent 1:$<8>1 classid 1:$<8>4 htb rate 33kbit ceil $CLIENT_DOWN_CEIL prio 3
# PRIO 4 -> unclassified traffic
$TC class add dev $DEV_P1_DOWN parent 1:$<8>1 classid 1:$<8>5 htb rate 33kbit ceil $CLIENT_DOWN_CEIL prio 4
# фильтруем icmp-пакеты в ранее созданный нами класс для icmp-трафика с приоритетот 1
$TC filter add dev $DEV_P1_DOWN protocol ip parent 1:0 prio 1 u32 match ip dst $CLIENT_IP \
match ip protocol 1 0xff flowid 1:$<8>2
# фильтрация udp
$TC filter add dev $DEV_P1_DOWN protocol ip parent 1:0 prio 2 u32 match ip dst $CLIENT_IP \
match ip protocol 17 0xff flowid 1:$<8>3
# ssh
$TC filter add dev $DEV_P1_DOWN protocol ip parent 1:0 prio 2 u32 match ip dst $CLIENT_IP \
match ip protocol 6 0xff match ip sport 22 0xffff flowid 1:$<8>3
# WWW, sport 80
$TC filter add dev $DEV_P1_DOWN protocol ip parent 1:0 prio 3 u32 match ip dst $CLIENT_IP \
match ip protocol 6 0xff match ip sport 80 0xffff flowid 1:$<8>4
# самый высокий приоритет – трафику, не попавшему под предыдущие фильтры
$TC filter add dev $DEV_P1_DOWN protocol ip parent 1:0 prio 4 u32 match ip dst $CLIENT_IP flowid 1:$<8>5
### ТАКИЕ ЖЕ ПРАВИЛА И ДЛЯ ИСХОДЯЩЕГО ТРАФИКА
$TC class add dev $DEV_P1_UP parent 1:100 classid 1:$<8>1 htb rate $CLIENT_UP_RATE ceil $CLIENT_UP_CEIL
# PRIO 1 -> icmp traffic
$TC class add dev $DEV_P1_UP parent 1:$<8>1 classid 1:$<8>2 htb rate 1kbit ceil $CLIENT_UP_CEIL prio 1
# PRIO 2 -> udp, ssh
$TC class add dev $DEV_P1_UP parent 1:$<8>1 classid 1:$<8>3 htb rate 1kbit ceil $CLIENT_UP_CEIL prio 2
# PRIO 3 -> unclassified traffic
$TC class add dev $DEV_P1_UP parent 1:$<8>1 classid 1:$<8>4 htb rate 1kbit ceil $CLIENT_UP_CEIL prio 3
$TC filter add dev $DEV_P1_UP protocol ip parent 1:0 prio 1 u32 match ip src $CLIENT_IP \
match ip protocol 1 0xff flowid 1:$<8>2
$TC filter add dev $DEV_P1_UP protocol ip parent 1:0 prio 2 u32 match ip src $CLIENT_IP \
match ip protocol 17 0xff flowid 1:$<8>3
$TC filter add dev $DEV_P1_UP protocol ip parent 1:0 prio 2 u32 match ip src $CLIENT_IP \
match ip protocol 6 0xff match ip dport 22 0xffff flowid 1:$<8>3
$TC filter add dev $DEV_P1_UP protocol ip parent 1:0 prio 3 u32 match ip src $CLIENT_IP flowid 1:$<8>4
Данные скрипты нужно положить в один каталог, Выполнить:
chmod +x ./rc.shape
Я описал один из методов ограничения трафика. Утилита tc – очень мощная вещь в вопросах об ограничениях трафика. Рекомендую ознакомиться с документом: LARTC-HOWTO для более глубокого изучения данного вопроса.
Источник



