- 16 команд мониторинга Linux-сервера, которые вам действительно нужно знать
- iostat
- meminfo и free
- mpstat
- netstat
- ps и pstree
- strace
- tcpdump
- uptime
- vmstat
- Wireshark
- Кто перезагрузил сервер линукс
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Как узнать причину перезагрузки Linux
- Проверка времени перезагрузки
- Проверка системных журналов
- Проверка журнала auditd
- Анализ журнала systemd
- Заключение
16 команд мониторинга Linux-сервера, которые вам действительно нужно знать
Хотите знать, что самом деле происходит на с вашим сервером? Тогда вы должны знать эти основные команды. Как только вы их освоите, вы станете администратором-экспертом в системах Linux.
В зависимости от дистрибутива Linux, вы можете с помощью программы с графическим интерфейсом получить больше информации, чем могут дать эти команды, запускаемые из командной оболочки. В SUSE Linux, например, есть отличное графическое инструментальное средство YaST , предназначенное для конфигурирования и управления системой; также в KDE есть отличное инструментальное средство KDE System Guard .
Однако, основное правило администратора Linux состоит в том, что вы должны работать с графическим интерфейсом на сервере только в случае, когда это вам абсолютно необходимо. Это обусловлено тем, что графические программы на Linux занимают системные ресурсы, которые было бы лучше использовать в другом месте. Поэтому хотя программа с графическим интерфейсом и может отлично подходить для базовой проверки состояния сервера, если вы хотите знать, что происходит на самом деле, отключите графический интерфейс и воспользуйтесь инструментальными средствами, работающими из командной строки Linux.
Это также означает, что вы должны запускать графический интерфейс на сервере только тогда, когда это действительно необходимо; не оставляйте его работать. Чтобы достичь оптимальной производительности, сервер Linux должен работать на уровне runlevel 3 , на котором, когда компьютер загружается, полностью поддерживается работа в сети и многопользовательский режим, но графический интерфейс не запускается. Если вам действительно нужно графический рабочий стол, вы всегда можете его открыть с помощью команды startx , выполненной из командной строки.
Если ваш сервер при загрузке запускается в графическом режиме, то вам это нужно изменить. Для этого откройте терминальное окно, с помощью команды su перейдите в режим пользователя root и с помощью вашего любимого текстового редактора откройте файл /etc/inittab .
Как только вы это сделаете, найдите строку initdefault и измените ее с id:5:initdefault: на id:3:initdefault:
Если файла inittab нет, то создайте его и добавьте строку id:3 . Сохраните файл и выйдите из редактора. В следующий раз при загрузке ваш сервер будет загружаться на уровне запуска 3. Если вы после этого изменения не захотите перезагружать сервер, вы также можете с помощью команды init 3 непосредственно задать уровень запуска вашего сервера.
Как только ваш сервер станет работать на уровне запуска init 3, вы для того, чтобы увидеть, что происходит внутри вашего сервера, можете начать пользоваться следующими программами командной оболочки.
iostat
Команда iostat подробно показывает, что к чему в вашей подсистеме хранения данных. Как правило, вы должны использовать команду iostat для того, чтобы следить, что ваша подсистема хранения работают в целом хорошо и прежде, чем ваши клиенты заметят, что сервер работает медленно, выявлять те места, из-за медленного ввода/вывода которых возникают проблемы. Поверьте мне, вам следует обнаруживать эти проблемы раньше, чем это сделают ваши пользователи!
meminfo и free
Команда meminfo предоставит вам подробный список того, что происходит в памяти. Как правило, доступ к данным meminfo можно получить с помощью другой программы, например, cat или grep . Так, например, с помощью команды
вы в любой момент будете знать все, что происходит в памяти вашего сервера.
Вы можете воспользоваться командой free для быстрого «фактографического» взгляда на память. Если кратко, то с помощью команды free вы получите обзор состояния памяти, а с помощью команды meminfo вы узнаете все подробности.
mpstat
Команда mpstat сообщает о действиях каждого из доступных процессоров в многопроцессорных серверах. В настоящее время почти во всех серверах используются многоядерные процессоры. Команда mpstat также сообщает об усредненной загрузке всех процессоров сервера. Это позволяет отображать общую статистику по процессорам во всей системе или для каждого процессора отдельно. Эти значения могут предупредить вас о возможных проблемах с приложением прежде, чем они станут раздражать пользователей.
netstat
Команда netstat , точно также, как и ps , является инструментальным средством Linux, которым администраторы пользуются каждый день. Она отображает большое количество информации о состоянии сети, например, об использовании сокетов, маршрутизации, интерфейсах, протоколах, показывает сетевую статистику и многое другое. Некоторые из наиболее часто используемых параметров:
-a — Показывает информацию о всех сокетах
-r — Показывает информацию, касающуюся маршрутизации
-i — Показывает статистику, касающуюся сетевых интерфейсов
-s — Показывает статистику, касающуюся сетевых протоколов
Команда nmon , сокращение от Nigel’s Monitor, является популярным инструментальным средством с открытым исходным кодом, которое предназначено для мониторинга производительности систем Linux. Команда nmon следит за информацией о производительности нескольких подсистем, таких как использование процессоров, использование памяти, выдает информацию о работе очередей, статистику дисковых операций ввода/вывода, статистику сетевых операций, активности системы подкачки и метрические характеристики процессов. Затем вы через «графический» интерфейс команды curses можете в режиме реального времени просматривать информацию, собираемую командой nmon.
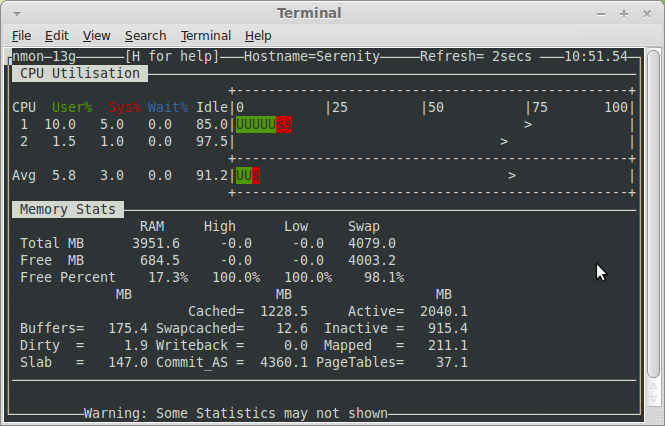
Чтобы команда nmon работала, вы должны ее запустить из командной строки. После этого вы можете с помощью нажатий на отдельные клавиши выбирать подсистемы, за работой которых вы хотите проследить. Например, чтобы получить статистику по процессору, памяти и дискам, наберите c , m и d . Вы также можете использовать команду nmon с флагом -f для того, чтобы сохранить статистику в файле CSV для последующего анализа.
Я считаю, что для повседневного мониторинга серверов команда nmon является одной из самых полезных программ в моем инструментальном наборе, предназначенном для систем Linux.
Команда pmap сообщает об объеме памяти, которые используются процессами на вашем сервере. Вы можете использовать этот инструмент для того, чтобы определить, для каких процессов на сервере выделяется память и как эти процессы ее используют.
ps и pstree
Команды ps и pstree являются двумя самыми лучшими командами администратора Linux. Они обе выдают список всех запущенных процессов. Команда ps показывает, сколько памяти и процессорного времени используют программы, работающие на сервере. Команда pstree выдает меньше информации, но указывает, какие процессы являются потомками других процессов. Имея эту информацию, вы можете обнаружить неуправляемые процессы и уничтожить их с помощью команды kill , предназначенной для «безусловного уничтожения» процессов в Linux.
Программа sar является инструментальным средством мониторинга, столь же универсальным как швейцарский армейский нож. Команда sar , на самом деле, состоит из трех программ: sar , которая отображает данные, и sa1 и sa2 , которые собирают и запоминают данные. После того, как программа sar установлена, она создает подробный отчет об использовании процессора, памяти подкачки, о статистике сетевого ввода/вывода и пересылке данных, создании процессов и работе устройств хранения данных. Основное отличие между sar и nmon в том, что первая команда лучше при долгосрочном мониторинге системы, в то время, как я считаю, nmon лучше для того, чтобы мгновенно получить информацию о состоянии моего сервера.
strace
Команду strace часто рассматривают, как отладочное средство программиста, но, на самом деле, ее можно использовать не только для отладки. Команда перехватывает и записывает системные вызовы, которые происходят в процессе. Т.е. она полезна в диагностических, учебных и отладочных целях. Например, вы можете использовать команду strace для того, чтобы выяснить, какой на самом деле при запуске программы используется конфигурационный файл.
tcpdump
Tcpdump является простой и надежной утилитой мониторинга сети. Ее базовые возможности анализа протокола позволяют получить общее представление о том, что происходит в вашей сети. Однако, чтобы по-настоящему разобраться в том, что происходит в вашей сети, вам следует воспользоваться программой Wireshark (см. ниже).
Команда top показывает, что происходит с вашими активными процессами. По умолчанию она отображает самые ресурсоемкие задачи, запущенные на сервере, и обновляет список каждые пять секунд. Вы можете отсортировать процессы по PID (идентификатор процесса), времени работы, можете сначала указывать новые процессы, затраты по времени, по суммарному затраченному времени, а также по используемой памяти и по общему времени использования процессора с момента запуска процесса. Я считаю, что это быстрый и простой способ увидеть, что некоторый процесс начинает выходить из-под контроля и из-за этого все движется к проблеме.
uptime
Используйте команду uptime для того, чтобы узнать, как долго работает сервер и сколько пользователей было зарегистрировано в системе. Эта команда также покажет вам среднюю загрузку сервера. Оптимальное значение равно 1 или меньше, что означает, что каждый процесс немедленно получает доступ к процессору и потери циклов процессора отсутствуют.
vmstat
Вы можете использовать команду vmstat , в основном, для контроля того, что происходит с виртуальной памятью. Для того, чтобы получить наилучшую производительность системы хранения данных, Linux постоянно обращается к виртуальной памяти.
Если ваши приложения занимают слишком много памяти, вы получите чрезмерное значение затрат страниц памяти (page-outs) — программы перемещаются из оперативной памяти в пространство подкачки вашей системы, которое находится на жестком диске. Ваш сервер может оказаться в таком состоянии, когда он тратит больше времени на управление памятью подкачки, а не на работу ваших приложений; это состояние называемое пробуксовкой (thrashing). Когда компьютер находится в состоянии пробуксовки, его производительность падает очень сильно. Команда vmstat , которая может отображать либо усредненные данные, либо фактические значения, может помочь вам определить программы, которые занимают много памяти, прежде, чем из-за них ваш процессор перестанет шевелиться.
Wireshark
Программа wireshark , ранее известная как ethereal (и до сих пор часто называют именно так), является «старшим братом» команды tcpdump , хотя она более сложная и с более расширенными возможностями анализа и отчетности по используемым протоколам. У wireshark есть как графический интерфейс, так и интерфейс командной оболочки. Если вам требуется серьезное администрирование сетей, вам следует использовать программу ethereal. И, если вы используете wireshark/ethereal, я настоятельно рекомендую воспользоваться книгой Practical Packet Analysis Криса Сандера (Chris Sander), рассказывающей о том, как с помощью практического анализа пакетов можно получить максимальную отдачу от этой полезной программы.
Это обзор всего лишь нескольких наиболее значимых систем мониторинга из многих, имеющихся для Linux. Тем не менее, если вы сможете освоить эти программы, они помогут вам на пути к вершинам системного администрирования Linux.
Источник
Кто перезагрузил сервер линукс

Всем привет, сегодня небольшая заметка для начинающих системных администраторов, рассмотрим вопрос как определить кто перезагрузил сервер Windows. Бывают ситуации, что по какой то причине отваливается сервер его удаленно перезагрузили, зайдя на которой вы не видите что у него был синий экран BSOD, и значит надо искать кто то его отправил в ребут. Вам необходимо выяснить кто это был.
И так рассматривать кто перезагрузил сервер Windows я буду на примере Windows Server 2008 R2, но все действия абсолютно одинаковы в любой версии Windows начиная с Vista. Поможет нам в реализации нашей задачи оснастка Просмотр событий. Открыть его можно Пуск-Администрирование-Просмотр событий или нажать WIN+R и ввести там evenvwr.msc.
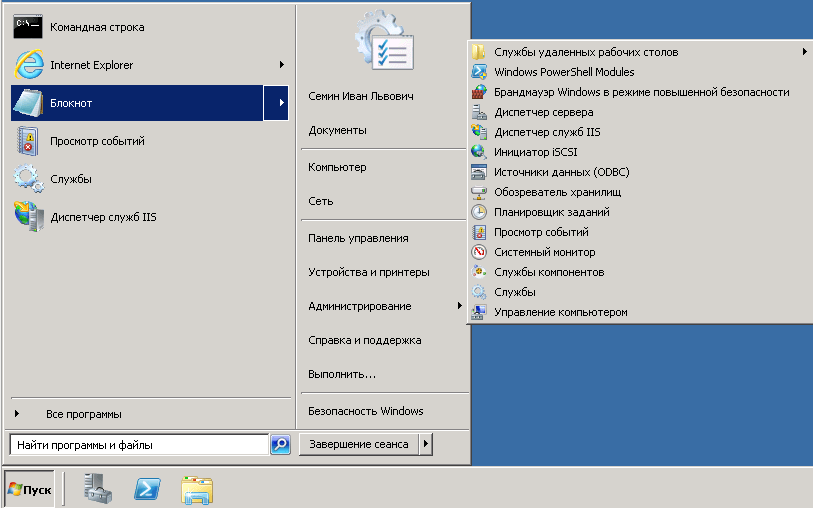
у вас откроется оснастка Просмотр событий. Вам нужно выбрать журнал Windows Система. В нем как раз и находится нужная нам информация в виде события. Проблема в том что их генерируется порой очень много, для этого придумали фильтр. Жмем справа в колонке действия Фильтр текущего журнала.
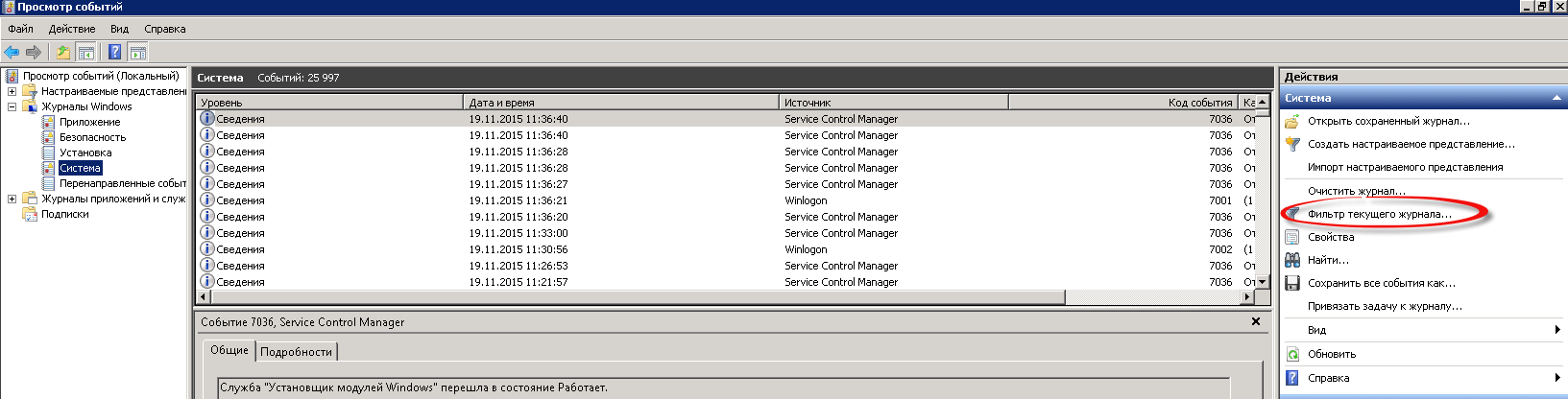
В открывшемся окне вам нужно отфильтровать данный журнал. Задаем дату, я выставил период за последнюю неделю,
можете выставить и меньше и больше. Выбираем уровень событий, ставим все и самое главное какой будет источник событий. В источнике событий выбираете USER32, он и хранит нужный лог.
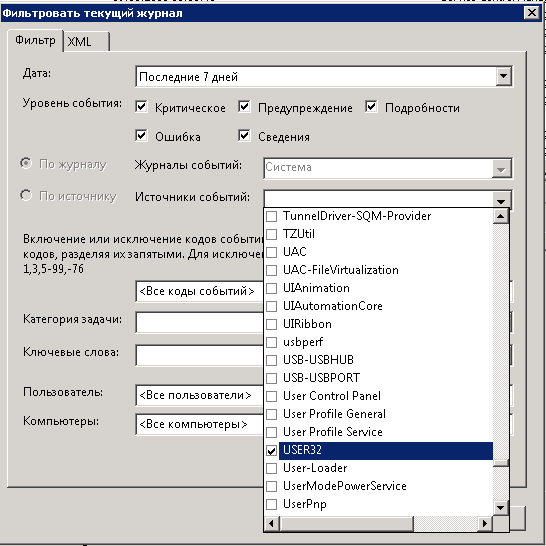
В итоге у меня получилась вот такая картина
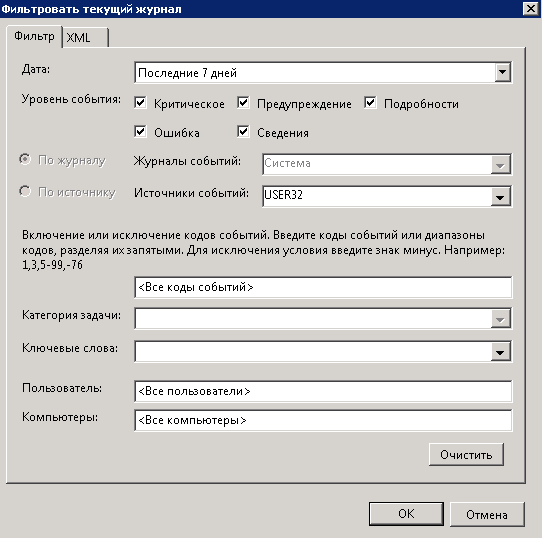
После нажатия кнопки ок вы получите отфильтрованный журнал система, у меня нашлось одно событие. Код события 1074 о том что сервер с Windows Server 2008 R2 был перезагружен системой после установки программы Microsoft SOAP Toolkit.
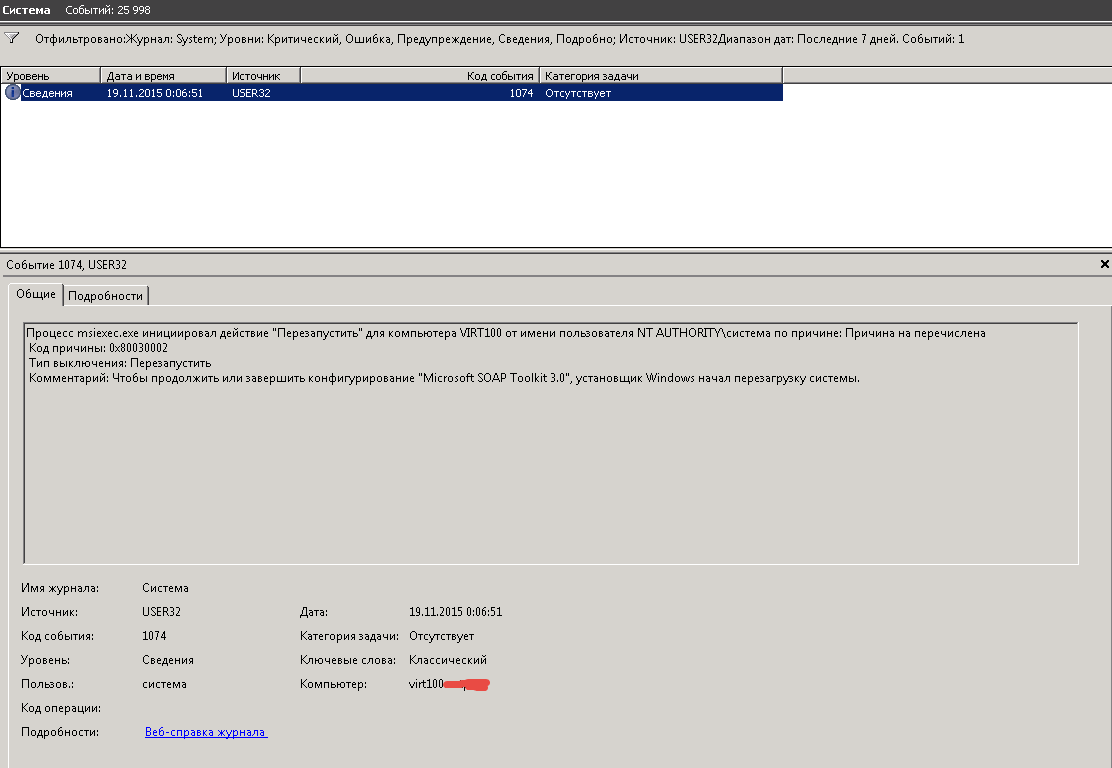
Мне этого мало и нужно понять кто начал установку данного приложения. Для этого так же переходив уже в журнал Приложения, делаем фильтр, дату ставим например тоже неделю
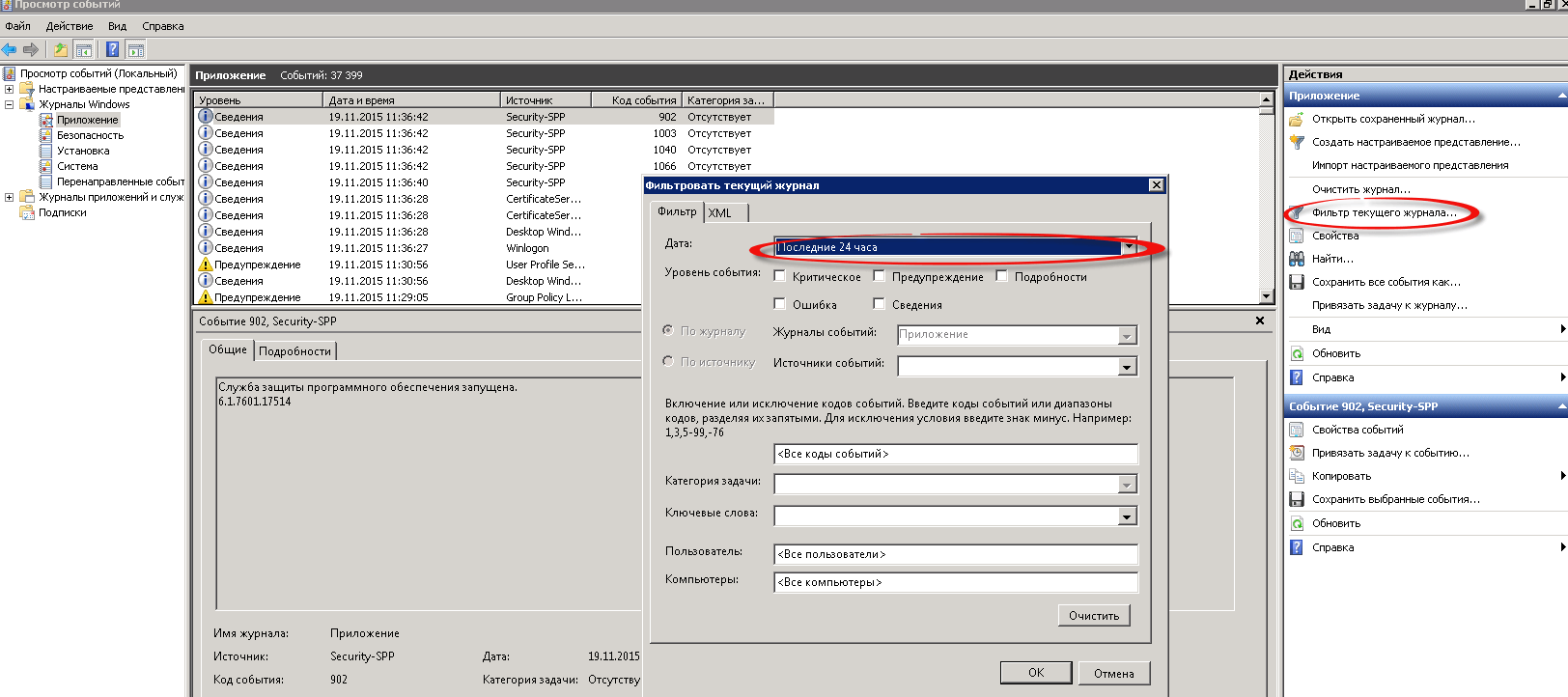
Еще отфильтруем по кодам событий с 1035-1040
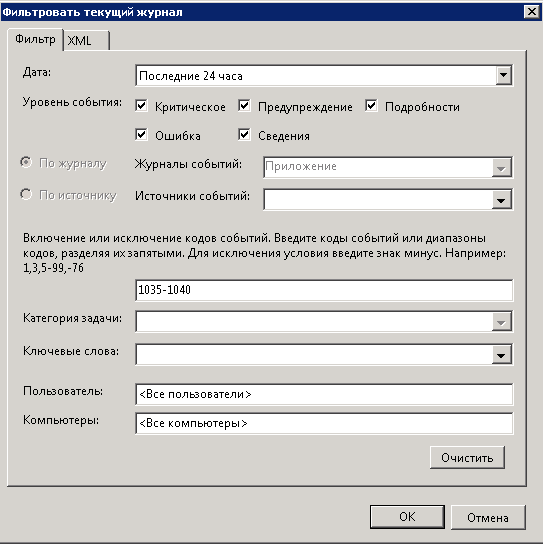
И в итоге мы видим вот такое событие

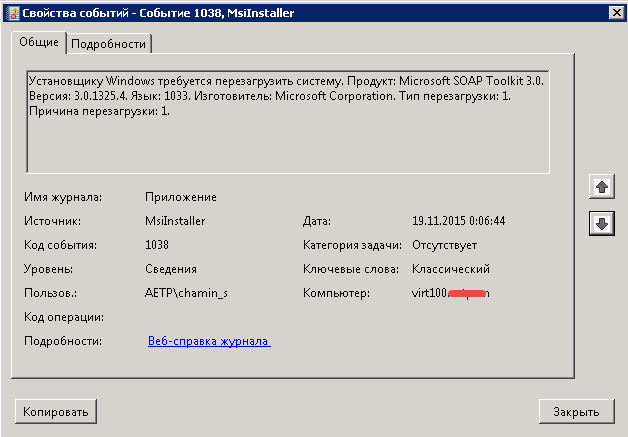
Вот мы и выяснили кто он мистер Х. В качестве эксперимента можете удаленно перезагрузить тестовую машину или например я рассказывал как перезагрузить компьютер через командную строку.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Как узнать причину перезагрузки Linux
Что вызвало ребут?
4 минуты чтения
Часто бывает, что на системе Linux произошла незапланированная или по неизвестным очевидным причинам, перезагрузка. Поиск и устранение первопричины может помочь предотвратить повторение таких проблем и избежать незапланированных простоев.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Есть несколько способов выяснить, что вызвало перезагрузку. В этой статье мы обсудим эти способы и способы использования доступных утилит и журналов в системе Linux для устранения таких сценариев.
Проверка времени перезагрузки
Чтобы посмотреть, когда именно произошла перезагрузка системы можно воспользоваться командами who и last

Проверка системных журналов
Кроме того, можно сопоставить время перезагрузки, которую требуется диагностировать, с системными сообщениями.
Для систем CentOS/RHEL журналы можно найти по адресу /var/log/messages , а для систем Ubuntu/Debian — по адресу /var/log/syslog . Для фильтрации или поиска конкретных данных можно использовать команду tail или любимый текстовый редактор.
Как видно из приведенных ниже журналов, такие записи предполагают завершение работы или перезагрузку, инициированную администратором или пользователем root . Эти сообщения могут варьироваться в зависимости от типа ОС и способа запуска перезагрузки или завершения работы, но вы всегда найдете полезную информацию, просматривая системные журналы, хотя этого не всегда может быть достаточно, чтобы определить причину.
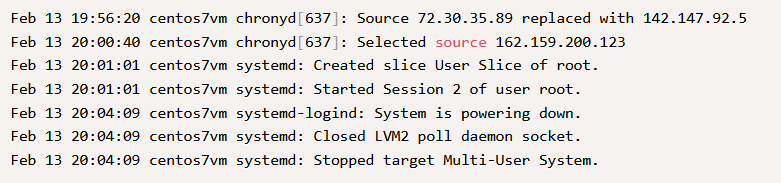
Ниже приведена одна такая команда, которую можно использовать для фильтрации системных журналов:
Зафиксированные события не всегда могут быть конкретными. Всегда отслеживайте события, которые дают признаки предупреждений или ошибок, которые могут привести к выключению или сбою системы.
Проверка журнала auditd
Для систем, использующих auditd – это отличное место для проверки различных событий с помощью инструмента ausearch . Используйте приведенную ниже команду для проверки последних двух записей из журналов аудита.
Появится сообщение о двух последних остановках или перезагрузках. Если это сообщает о SYSTEM_SHUTDOWN , за которым следует SYSTEM_BOOT , все должно быть хорошо. Но, если он сообщает две строки SYSTEM_BOOT подряд или только одно сообщение SYSTEM_BOOT , то, скорее всего, система некорректно завершила работу. Вывод при нормальной работе должен быть примерно следующим:
В приведенных ниже выходных данных перечислены два последовательных сообщения SYSTEM_BOOT , которые могут указывать на аварийное завершение работы, хотя результаты нужно скорректировать с данными системного журнала.
Анализ журнала systemd
Чтобы сохранить журнал системных логов на диске, необходимо иметь постоянный системный журнал, иначе логи будут очищаться при перезагрузке. Для этого можно либо внести изменения в /etc/systemd/journald.conf , либо создать каталог самостоятельно с помощью следующих команд:
После этого можно дополнительно перезагрузить систему для ввода нескольких записей перезагрузки в журнал, хотя это и не требуется.
Приведенную ниже команда позволяет выводить список записанных событий о загрузке из журнала:
Вот его выходные данные на моем сервере:

Как видно на рисунке, в системе есть несколько событий загрузки. Для дальнейшего анализа причины конкретной перезагрузки используйте:
Здесь
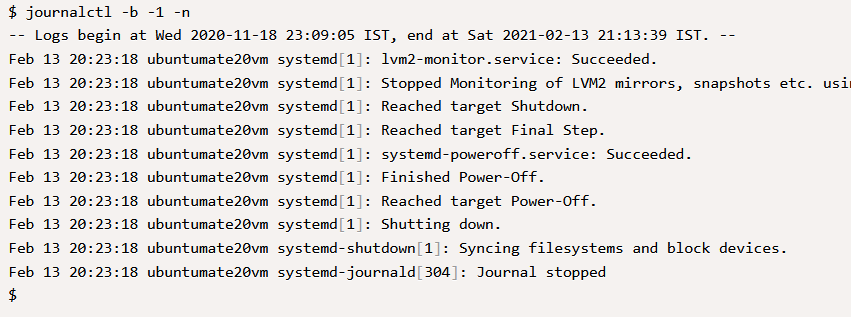
В приведенных выше выходных данных можно просмотреть сообщения, зарегистрированные в журнале, и отследить аномалии, если таковые имеются.
Заключение
Не всегда можно определить причину перезагрузки Linux с помощью одной команды или из одного файла журнала. Поэтому всегда удобно знать команды и журналы, которые фиксируют события, связанные с системой, и могут сократить время, необходимое для поиска первопричины.
Приведенные выше примеры дают вам возможность начать поиск и устранение неисправностей. Используя комбинацию таких инструментов и журналов, вы можете быть уверены в том, что произошло и как перезагрузилась ваша система.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена
Источник



