Что такое куча
В программировании есть два разных понятия, которые обозначаются одним и тем же словом «куча». Одно про выделение памяти, второе — про организацию данных. Разберём оба и закроем этот вопрос.
Это про данные
Эта статья из цикла про типы данных. Уже было:
Ещё бывают связанные списки, очереди, множества, хеш-таблицы, карты и кучи. Вот сегодня про кучи.
Куча и работа с памятью
Каждая запущенная программа использует собственную область оперативной памяти. Эта область делится на несколько частей: в одной хранятся данные, в другой — сам код программы, в третьей — константы. Ещё в эту область входят стек вызовов и куча. Про стек вызовов мы уже рассказывали в отдельной статье, теперь поговорим про кучу.
В отличие от стека, который строго упорядочен и все элементы там идут друг за другом, данные в куче могут храниться как угодно. Технически куча — это область памяти, которую компьютер выделяет программе и говорит: вот тебе свободная память для переменных, делай с ней что хочешь.
То, как программист распорядится этой памятью и каким образом будет с ней работать, влияет на быстродействие и работоспособность всей программы.
Аналогия со стройплощадкой
Представьте, что мы строим дом, а куча — это огромная площадка для хранения стройматериалов. Площадка может быть большой, но она не безграничная, поэтому важно как-то по-умному ей пользоваться. Например:
На стройке: мы выгрузили кирпич на один участок, использовали этот кирпич. Теперь нужно сказать, что этот участок можно снова использовать под стройматериалы. Новый кирпич можно разгрузить сюда же, а не искать новое место на площадке.
В программе: мы выделили память для переменной, использовали переменную, она больше не нужна. Можно сказать «Эта память свободна» и использовать её снова.
На стройке: мы храним определённый вид труб на палете №53. Мы говорим крановщику: «Поднимайте на этаж то, что лежит на палете 53». Если мы ошибёмся с номером, то крановщик поднимет на этаж не те трубы.
В программе: в некоторых языках мы можем обратиться к куче напрямую через специальный указатель. Если мы ошиблись и сказали обратиться не к тому участку памяти, программа заберёт не те данные, а дальше будет ошибка.
👉 Прямой доступ к памяти есть не во всех языках программирования. Многие компиляторы и интерпретаторы ставят между программистом и памятью своеобразного администратора — диспетчера памяти. Он сам решает, какие переменные нужны, а какие нет; когда чистить память; сколько памяти на что выделить.
С одной стороны, это удобно: программист просто говорит «храни данные». А где они будут храниться и как их получить — это вопрос другой системы.
С другой стороны, автоматические диспетчеры памяти бывают менее эффективными, чем если управлять памятью вручную. Поэтому драйвера или софт для высоконагруженных систем чаще пишут в «ручном режиме».
Куча и организация данных
Второй вид кучи в программировании — это организация данных.
Куча — это такой вид дерева, у которого есть одно важное свойство:
если узел A — это родитель узла B, то ключ узла A больше ключа узла B (или равен ему).
Если мы представим какой-то набор данных в виде кучи, он может выглядеть, например, так:
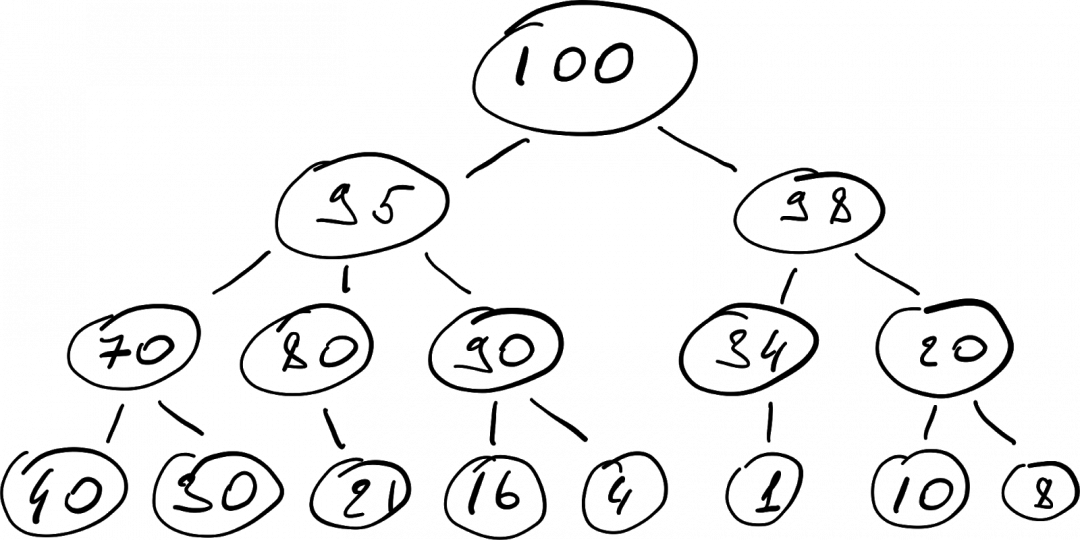
У кучи нет ограничений на число потомков у каждого родителя, но на практике чаще всего используются бинарные кучи. Бинарные — значит, у каждого родителя может быть не больше двух потомков.
Для чего нужны кучи данных
Так как данные в куче упорядочены заранее понятным образом, то их можно использовать для быстрого нахождения нужного элемента или оптимальной последовательности действий, например:
- для пирамидальной сортировки большого количества данных, когда объём требуемой памяти не зависит от размера массива, который мы сортируем;
- для нахождения самого быстрого пути из точки A в точку B, когда мы знаем промежуточные расстояния между ними и точками по пути;
- для поиска нужного элемента по каким-то критериям за минимальное время;
- для вычисления оптимальной последовательности действий, если мы знаем параметры и условия для каждого действия.
Зачем это знать
Если вы просто пишете веб-приложения на JS — в принципе, это знать не нужно. Вы не можете из JS напрямую управлять памятью, а для простых задач вам вряд ли придётся часто обходить деревья и делать сложные сортировки.
Понимание структур данных нужно для глубокой экспертной работы с софтом. Это как понимание принципов работы механизма внутреннего сгорания. Вам необязательно в этом разбираться, если вы просто хотите водить автомобиль, но обязательно — если хотите собирать гоночные болиды.
Основные принципы программирования: стек и куча
Мы используем всё более продвинутые языки программирования, которые позволяют нам писать меньше кода и получать отличные результаты. За это приходится платить. Поскольку мы всё реже занимаемся низкоуровневыми вещами, нормальным становится то, что многие из нас не вполне понимают, что такое стек и куча, как на самом деле происходит компиляция, в чём разница между статической и динамической типизацией, и т.д. Я не говорю, что все программисты не знают об этих понятиях — я лишь считаю, что порой стоит возвращаться к таким олдскульным вещам.
Сегодня мы поговорим лишь об одной теме: стек и куча. И стек, и куча относятся к различным местоположениям, где происходит управление памятью, но стратегия этого управления кардинально отличается.
Стек — это область оперативной памяти, которая создаётся для каждого потока. Он работает в порядке LIFO (Last In, First Out), то есть последний добавленный в стек кусок памяти будет первым в очереди на вывод из стека. Каждый раз, когда функция объявляет новую переменную, она добавляется в стек, а когда эта переменная пропадает из области видимости (например, когда функция заканчивается), она автоматически удаляется из стека. Когда стековая переменная освобождается, эта область памяти становится доступной для других стековых переменных.
Из-за такой природы стека управление памятью оказывается весьма логичным и простым для выполнения на ЦП; это приводит к высокой скорости, в особенности потому, что время цикла обновления байта стека очень мало, т.е. этот байт скорее всего привязан к кэшу процессора. Тем не менее, у такой строгой формы управления есть и недостатки. Размер стека — это фиксированная величина, и превышение лимита выделенной на стеке памяти приведёт к переполнению стека. Размер задаётся при создании потока, и у каждой переменной есть максимальный размер, зависящий от типа данных. Это позволяет ограничивать размер некоторых переменных (например, целочисленных), и вынуждает заранее объявлять размер более сложных типов данных (например, массивов), поскольку стек не позволит им изменить его. Кроме того, переменные, расположенные на стеке, всегда являются локальными.
В итоге стек позволяет управлять памятью наиболее эффективным образом — но если вам нужно использовать динамические структуры данных или глобальные переменные, то стоит обратить внимание на кучу.
Куча — это хранилище памяти, также расположенное в ОЗУ, которое допускает динамическое выделение памяти и не работает по принципу стека: это просто склад для ваших переменных. Когда вы выделяете в куче участок памяти для хранения переменной, к ней можно обратиться не только в потоке, но и во всем приложении. Именно так определяются глобальные переменные. По завершении приложения все выделенные участки памяти освобождаются. Размер кучи задаётся при запуске приложения, но, в отличие от стека, он ограничен лишь физически, и это позволяет создавать динамические переменные.
24 апреля в 10:00, Онлайн, Беcплатно
Вы взаимодействуете с кучей посредством ссылок, обычно называемых указателями — это переменные, чьи значения являются адресами других переменных. Создавая указатель, вы указываете на местоположение памяти в куче, что задаёт начальное значение переменной и говорит программе, где получить доступ к этому значению. Из-за динамической природы кучи ЦП не принимает участия в контроле над ней; в языках без сборщика мусора (C, C++) разработчику нужно вручную освобождать участки памяти, которые больше не нужны. Если этого не делать, могут возникнуть утечки и фрагментация памяти, что существенно замедлит работу кучи.
В сравнении со стеком, куча работает медленнее, поскольку переменные разбросаны по памяти, а не сидят на верхушке стека. Некорректное управление памятью в куче приводит к замедлению её работы; тем не менее, это не уменьшает её важности — если вам нужно работать с динамическими или глобальными переменными, пользуйтесь кучей.
Заключение
Вот вы и познакомились с понятиями стека и кучи. Вкратце, стек — это очень быстрое хранилище памяти, работающее по принципу LIFO и управляемое процессором. Но эти преимущества приводят к ограниченному размеру стека и специальному способу получения значений. Для того, чтобы избежать этих ограничений, можно пользоваться кучей — она позволяет создавать динамические и глобальные переменные — но управлять памятью должен либо сборщик мусора, либо сам программист, да и работает куча медленнее.
Куча Windows и семейство функций GlobalAlloc




![]()
![]()
Куча (heap) — это пул памяти какого-либо процесса. Когда программе требуется блок памяти, онавызывает функцию, выделяющую память из кучи, а чтобы освободить ранее выделенную память, — функцию, парную первой. Выравнивание по границам, кратным 4 Кб, в этом случае не производится; диспетчер кучи использует пространство на выделенных ранее страницах или обращается к VirtualAlloc, чтобы получить дополнительные страницы. Одна из двух куч, с которыми программа работает, — куча Windows. Для выделения из нее памяти служит функция HeapAlloc, а для освобождения — функция HeapFree. HeapAlloc особенно удобна для выделения «крупных» блоков памяти.
Может быть, приложение и не будет явно вызывать НеарАlloc, но за него это сделает функция GlobalAlloc, унаследованная от Winl6. В идеальном мире 32-разрядных программ функция GlobalAlloc не понадобилась бы, но мы имеем дело с реальным миром. Все еще остается колоссальный объем кода, перенесенного из Winl6, в том числе OLE, в котором вместо 32-разрядных адресов применяются параметры типа «описатель памяти» (HGLOBAL).
Работа функции GlobalAlloc зависит от передаваемых ей атрибутов. Если ей указывается GMEM_FIXED, она просто вызывает НеарАlloс и возвращает адрес, приводя тип данных к 32-битному значению HGLOBAL. Если же ей передается GMEM_MOVEABLE, возвращаемое значение HGLOBAL является указателем на элемент «таблицы описателей» в данном процессе. В этом элементе содержится указатель на память, выделенную функцией HeapAlloc.
Зачем нужна «перемещаемая» (moveable) память, если она вводит еще один слой «непрямого управления»? Здесь мы встречаемся с наследием Winl6, в котором операционная система когда-то действительно перемещала блоки памяти. В Win32 перемещаемые блоки памяти существуют лишь для поддержки GlobalReAlloc, которая выделяет новый блок памяти, копирует в него содержимое старого блока, освобождает последний и помещает адрес нового блока в существующий элемент таблицы описателей.
К сожалению, многие библиотечные функции используют в качестве параметров и возвращаемых значений HGLOBAL, а не адреса памяти. Если такая функция возвращает HGLOBAL, приложение должно считать, что данная память выделена с атрибутом GMEM_MOVEABLE, и, следовательно, чтобы получить адрес памяти, надо вызвать функцию GlobalLock. (В случае фиксированной памяти GlobalLock просто возвращает переданный ей описатель как адрес.) Если от приложения требуется передать параметр HGLOBAL, то следует получить это значение с помощью GlobalAlloc(GMEM_MOVEABLE. ) — на тот случай, если вызываемая функция обращается к GlobalReAlloc и ожидает, что значение описателя не изменится.
Буфер обмена Windows использует фиксированную память, тем самым можно передавать адреса, возвращенные HeapAlloc, и приводить возвращаемые значения HGLOBAL к void-указателям. Можно также передавать фиксированный адрес OLE-функции, которая принимает параметр типа HGLOBAL, однако значения HGLOBAL, возвращаемые OLE-функциями, являются перемещаемыми, поэтому приложение должны вызывать GlobalLock.
Куча библиотеки С периода выполнения, _heapmin и С++-операторы new и delete
Однако, куча Windows (и функция HeapAlloc) – это не та куча, с которой приложение будете работать чаще всего. Существует еще одна куча — ею управляет библиотека С периода выполнения (С RunTime library, CRT). Доступ к CRT-куче реализуется функциями malloc и free, напрямую вызываемыми операторами C++ new и delete. Эта куча оптимизирована для выделения блоков малого размера.
Конечно, функция malloc вызывает VirtualAlloc, но делает это очень хитро. При первом вызове она резервирует регион размером 1 Мб (в будущих версиях Visual C++ эти значения могут измениться) и передает блок памяти, размер которого кратен 64 Кб (если malloc вызван чтобы выделить память размером 64 Кб или менее, выделяется один 64-килобайтный блок. При последующих вызовах память выделяется по возможности из этого блока; в ином случае диспетчер кучи вызывает VirtualAlloc, чтобы передать дополнительную память. После того, как весь регион размером 1 Мб израсходован, malloc резервирует еще один регион размер 2 Мб, потом другой, но уже размером 4 Мб и т.д., передавая память по мере необходимости.

При вызове функции free диспетчер кучи помещает дескрипторы блоков памяти в односвязный циклический список свободных блоков памяти (free list), находящийся вне CRT кучи. Функция malloc использует этот список для последующего выделения памяти (если это возможно). Так как данный список весьма компактен, поиск свободных страниц ocyществляется быстро, без просмотра большого числа страниц виртуальной памяти.
Если процесс выделил много памяти из CRT-кучи, а потом освободил большую часть этой памяти, все страницы остаются переданными. Хотя оперативная память при этом может быть и не выделена, процесс занимает страницы в файле подкачки, которые остаются недоступными другим процессам. При вызове другой CRT-функции, _heapmin, диспетчер кучи возвращает все свободные страницы и, более того, освобождает любые, полностью возвращенные регионы.



