- Bash. Замена символов в переменной. Как?
- 9.2. Работа со строками
- 9.2.1. Использование awk при работе со строками
- 9.2.2. Дальнейшее обсуждение
- Строковые операции в Bash
- Получить длину строки
- Соединение двух строк
- Поиск подстрок
- Извлечение подстрок
- Замена подстрок
- Удаление подстрок
- Преобразование прописных и строчных букв в строку
- Основные приёмы обработки строк в bash
- Термины
- Сравнение строковых переменных
- Основные операторы сравнения
- Пример скрипта для сравнения двух строковых переменных
- Создание тестового файла
- Основы работы с grep
- Синтаксис команды
- Основные опции
- Практическое применение grep
- Поиск подстроки в строке
- Вывод нескольких строк
- Чтение строки из файла с использованием регулярных выражений
- Рекурсивный режим поиска
- Точное вхождение
- Поиск нескольких слов
- Количество строк в файле
- Вывод только имени файла
- Использование sed
- Синтаксис
- Распространенные конструкции с sed
- Замена слова
- Редактирование файла
- Удаление строк из файла
- Нумерация строк
- Удаление всех чисел из текста
- Замена символов
- Обработка указанной строки
- Работа с диапазоном строк
Bash. Замена символов в переменной. Как?
Как сделать, чтобы замена была глобальной?

Может быть как-то так: echo $X|sed «что то непонятное» ?
Ну, тогда уже tr.
Но хочется средствами bash’а. Зачем новый процесс дёргать?
> Но хочется средствами bash’а. Зачем новый процесс дёргать?
А объясни, на что нацелена экономия?
X=«`echo $X | sed s/aaaa/bbb/g`»
Сколько раз в секунду понадобится это делать?
Не знаю. Но выбор баша для time critical applications в любом случае плохая идея.
>X=«`echo $X | sed s/aaaa/bbb/g`»
элементарно короче, даже если не считать потери на вызове внешнего процесса
Но выбор баша для time critical applications в любом случае плохая идея.
Кроме белого и чёрного есть ещё много цветов.

Да, bash — необычайно богатый скриптовый язык. Чего ни пожелай, на все собственный синтаксис найдется.
> Кроме белого и чёрного есть ещё много цветов.
Именно поэтому надо использовать не только баш, а awk, python, perl.
>Именно поэтому надо использовать не только баш, а awk, python, perl.
Чтобы побольше машину загрузить и чтобы побольше кнопок нажать при написании выражения? 🙂
Источник
9.2. Работа со строками
Bash поддерживает на удивление большое количество операций над строками. К сожалению, этот раздел Bash испытывает недостаток унификации. Одни операции являются подмножеством операций подстановки параметров, а другие — совпадают с функциональностью команды UNIX — expr. Это приводит к противоречиям в синтаксисе команд и перекрытию функциональных возможностей, не говоря уже о возникающей путанице.
Длина строки
$ <#string>expr length $string expr «$string» : ‘.*’
Пример 9-10. Вставка пустых строк между параграфами в текстовом файле
Длина подстроки в строке (подсчет совпадающих символов ведется с начала строки)
expr match «$string» ‘$substring’
expr «$string» : ‘$substring’
где $substring — регулярное выражение.
Index
expr index $string $substring
Номер позиции первого совпадения в $string c первым символом в $substring.
Эта функция довольно близка к функции strchr() в языке C.
Извлечение подстроки
Извлекает подстроку из $string, начиная с позиции $position.
Если строка $string — » * » или » @ » , то извлекается позиционный параметр (аргумент), [1] с номером $position.
Извлекает $length символов из $string, начиная с позиции $position.
Если $string — » * » или » @ » , то извлекается до $length позиционных параметров (аргументов), начиная с $position.
expr substr $string $position $length
Извлекает $length символов из $string, начиная с позиции $position.
expr match «$string» ‘\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение.
expr «$string» : ‘\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение.
expr match «$string» ‘.*\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение. Поиск начинается с конца $string.
expr «$string» : ‘.*\($substring\)’
Находит и извлекает первое совпадение $substring в $string, где $substring — это регулярное выражение. Поиск начинается с конца $string.
Удаление части строки
Удаление самой короткой, из найденных, подстроки $substring в строке $string. Поиск ведется с начала строки
Удаление самой длинной, из найденных, подстроки $substring в строке $string. Поиск ведется с начала строки
Удаление самой короткой, из найденных, подстроки $substring в строке $string. Поиск ведется с конца строки
Удаление самой длинной, из найденных, подстроки $substring в строке $string. Поиск ведется с конца строки
Пример 9-11. Преобразование графических файлов из одного формата в другой, с изменением имени файла
Замена подстроки
Замещает первое вхождение $substring строкой $replacement.
Замещает все вхождения $substring строкой $replacement.
Подстановка строки $replacement вместо $substring. Поиск ведется с начала строки $string.
Подстановка строки $replacement вместо $substring. Поиск ведется с конца строки $string.
9.2.1. Использование awk при работе со строками
В качестве альтернативы, Bash-скрипты могут использовать средства awk при работе со строками.
Пример 9-12. Альтернативный способ извлечения подстрок
9.2.2. Дальнейшее обсуждение
Дополнительную информацию, по работе со строками, вы найдете в разделе Section 9.3 и в секции, посвященной команде expr. Примеры сценариев:
Источник
Строковые операции в Bash
Главное меню » Linux » Строковые операции в Bash

Если вы знакомы с переменными в bash, вы уже знаете, что не существует отдельных типов данных для строк, int и т. д. Все является переменной.
Но это не значит, что у вас нет функций манипулирования строками.
На этой неделе вы узнаете, как управлять строками, используя различные строковые операции. Вы узнаете, как получить длину строки, объединить строки, извлечь подстроки, заменить подстроки и многое другое!
Получить длину строки
Начнем с получения длины строки в bash.
Строка – это не что иное, как последовательность (массив) символов. Создадим строку с именем distro и инициализируем ее значением «Ubuntu».
Теперь, чтобы получить длину строки дистрибутива, вам просто нужно добавить #перед именем переменной. Вы можете использовать следующий оператор эха:
Обратите внимание, что команда echo предназначена для печати значения <#string>это то, что дает длину строки.
Соединение двух строк
Вы можете добавить строку в конец другой строки; этот процесс называется конкатенацией строк.
Для демонстрации давайте сначала создадим две строки str1 и str2 следующим образом:
Теперь вы можете объединить обе строки и присвоить результат новой строке с именем str3 следующим образом:
Не может быть проще, не так ли?
Поиск подстрок
Вы можете найти позицию (индекс) конкретной буквы или слова в строке. Для демонстрации давайте сначала создадим строку с именем str следующим образом:
Теперь вы можете получить конкретную позицию (индекс) подстроки cool. Для этого используйте команду expr:
Результат 9 – это индекс, с которого начинается слово «Cool» в строке str.
Мы сознательно избегаем использования условных операторов, таких как if, else, потому что в этой серии статей для начинающих bash условные операторы будут рассмотрены позже.
Извлечение подстрок
Вы также можете извлекать подстроки из строки; другими словами, вы можете извлечь букву, слово или несколько слов из строки.
Для демонстрации давайте сначала создадим строку с именем foss следующим образом:
Теперь предположим, что вы хотите извлечь первое слово «Fedora» в строке foss. Вам необходимо указать начальную позицию (индекс) желаемой подстроки и количество символов, которые вам нужно извлечь.
Следовательно, чтобы извлечь подстроку «Fedora», вы будете использовать 0 в качестве начальной позиции, и вы извлечете 6 символов из начальной позиции:
Обратите внимание, что первая позиция в строке равна нулю, как и в случае с массивами в bash. Вы также можете указать только начальную позицию подстроки и опустить количество символов. В этом случае будет извлечено все, от начальной позиции до конца строки.
Например, чтобы извлечь подстроку «свободная операционная система» из строки foss ; нам нужно только указать начальную позицию 12:
Замена подстрок
Вы также можете заменить подстроку другой подстрокой; например, вы можете заменить «Fedora» на «Ubuntu» в строке foss следующим образом:
Давайте рассмотрим другой пример, давайте заменим подстроку «бесплатно» на «популярные»:
Поскольку вы просто печатаете значение с помощью команды echo, исходная строка не изменяется.
Удаление подстрок
Вы также можете удалить подстроки. Чтобы продемонстрировать, давайте сначала создадим строку с именем fact следующим образом:
Теперь вы можете удалить подстроку big из строки fact:
Создадим еще одну строку с именем cell:
Теперь предположим, что вы хотите удалить все тире из строки ячейки; следующий оператор удалит только первое вхождение тире в строке ячейки:
Чтобы удалить все дефисы из строки ячейки , вы должны использовать двойную косую черту следующим образом:
Обратите внимание, что вы используете эхо-операторы, поэтому строка ячейки не повреждена и не изменена; вы просто демонстрируете желаемый результат!
Чтобы изменить строку, вам нужно вернуть результат в строку следующим образом:
Преобразование прописных и строчных букв в строку
Вы также можете преобразовать строку в строчные или прописные буквы. Сначала создадим две строки с именами легенда и актер:
Вы можете преобразовать все буквы в строке легенды в верхний регистр:
Вы также можете преобразовать все буквы в строке актера в нижний регистр:
Вы также можете преобразовать только первый символ строки легенды в верхний регистр следующим образом:
Точно так же вы можете преобразовать только первый символ строки актера в нижний регистр следующим образом:
Вы также можете изменить некоторые символы в строке на верхний или нижний регистр; например, вы можете изменить буквы jи nна верхний регистр в строке легенды следующим образом:
На этом мы подошли к концу этой статьи из серии bash для начинающих. Надеюсь, вам понравилось манипулировать строками в bash.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник
Основные приёмы обработки строк в bash
Работа со строками в bash осуществляется при помощи встроенных в оболочку команд.
Термины
- Консольные окружения — интерфейсы, в которых работа выполняется в текстовом режиме.
- Интерфейс — механизм взаимодействия пользователя с аппаратной частью компьютера.
- Оператор — элемент, задающий законченное действие над каким-либо объектом операционной системы (файлом, папкой, текстовой строкой и т. д.).
- Текстовые массивы данных — совокупность строк, записанных в переменную или файл.
- Переменная — поименованная область памяти, позволяющая осуществлять запись и чтение данных, которые в нее записываются. Она может принимать любые значения: числовые, строковые и т. д.
- Потоковый текстовый редактор — программа, поддерживающая потоковую обработку текстовой информации в консольном режиме.
- Регулярные выражения — формальный язык поиска части кода или фрагмента текста (в том числе строки) для дальнейших манипуляций над найденными объектами.
- Bash-скрипты — файл с набором инструкций для выполнения каких-либо манипуляций над строкой, текстом или другими объектами операционной системы.
Сравнение строковых переменных
Для выполнения операций сопоставления 2 строк (str1 и str2) в ОС на основе UNIX применяются операторы сравнения.
Основные операторы сравнения
- Равенство « = »: оператор возвращает значение «истина» («TRUE»), если количество символов в строке соответствует количеству во второй.
- Сравнение строк на эквивалентность « == »: возвращается «TRUE», если первая строка эквивалентна второй ( дом == дом ).
- Неравенство «str1 != str2»: «TRUE», если одна строковая переменная не равна другой по количеству символов.
- Неэквивалентность «str1 !== str2»: «TRUE», если одна строковая переменная не равна другой по смысловому значению ( дерево !== огонь ).
- Первая строка больше второй «str1 > str2»: «TRUE», когда str1 больше str2 по алфавитному порядку. Например, « дерево > огонь » , поскольку литера «д» находится ближе к алфавитному ряду, чем «о».
- Первая строка меньше второй «str1 str2»: «TRUE», когда str1 меньше str2 по алфавитному порядку. Например, « огонь », поскольку «о» находится дальше к началу алфавитного ряда, чем «д».
- Длина строки равна 0 « -z str2»: при выполнении этого условия возвращается «TRUE».
- Длина строки отлична от нулевого значения « -n str2»: «TRUE», если условие выполняется.
Пример скрипта для сравнения двух строковых переменных
- Чтобы сравнить две строки, нужно написать bash-скрипт с именем test .

- Далее необходимо открыть терминал и запустить test на выполнение командой:
- Предварительно необходимо дать файлу право на исполнение командой:
- После указания пароля скрипт выдаст сообщение на введение первого и второго слова. Затем требуется нажать клавишу «Enter» для получения результата сравнения.


Создание тестового файла
Обработка строк не является единственной особенностью консольных окружений Ubuntu. В них можно обрабатывать текстовые массивы данных.
- Для практического изучения команд, с помощью которых выполняется работа с текстом в интерпретаторе bash, необходимо создать текстовый файл txt .
- После этого нужно наполнить его произвольным текстом, разделив его на строки. Новая строка не должна сливаться с другими элементами.
- Далее нужно перейти в директорию, в которой находится файл, и запустить терминал с помощью сочетания клавиш — Ctrl+Alt+T.
Основы работы с grep
Поиск строки в файле операционной системы Linux Ubuntu осуществляется посредством специальной утилиты — grep . Она позволяет также отфильтровать вывод информации в консоли. Например, вывести все ошибки из log-файла утилиты ps или найти PID определенного процесса в ее отчете.
Команда grep работает с шаблонами и регулярными выражениями. Кроме того, она применяется с другими командами интерпретатора bash.
Синтаксис команды
Для работы с утилитой grep необходимо придерживаться определенного синтаксиса
- grep [options] pattern [file_name1 file_name2 file_nameN] (где «options» — дополнительные параметры для указания настроек поиска и вывода результата; «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет осуществляться поиск; «file_name1 file_name2 file_nameN» — имя одного или нескольких файлов, в которых производится поиск).
- instruction | grep [options] pattern (где «instruction» — команда интерпретатора bash, «options» — дополнительные параметры для указания настроек поиска и вывода результата, «pattern» — шаблон, представляющий строку поиска или регулярное выражение, по которым будет производиться поиск).
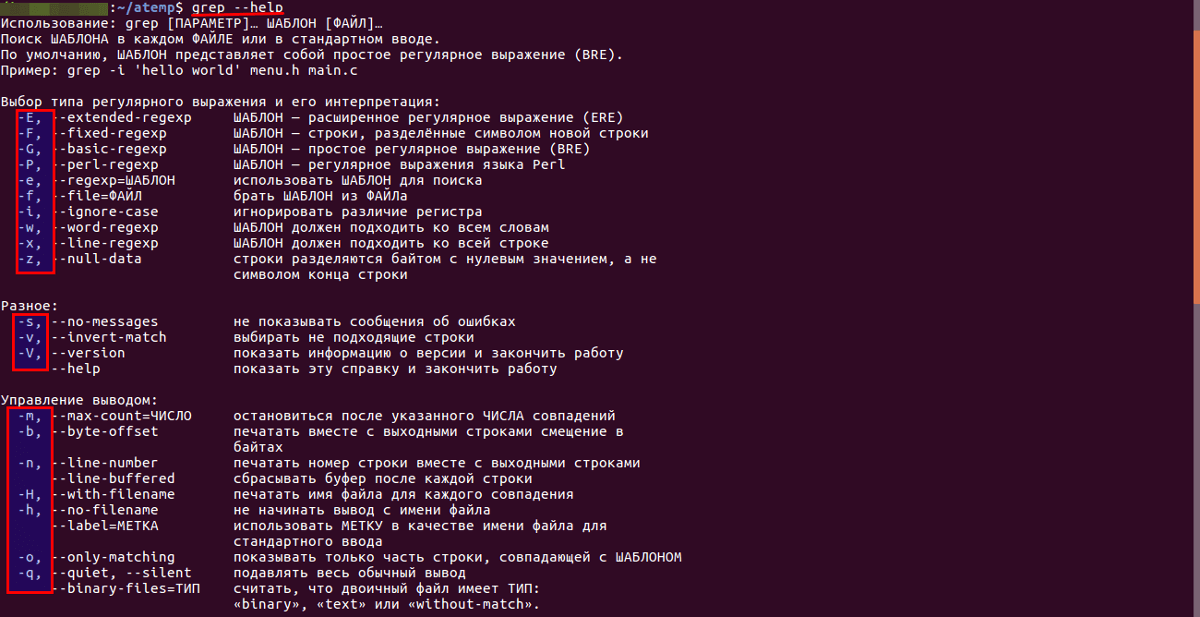
Основные опции
- Отобразить в консоли номер блока перед строкой — -b .
- Число вхождений шаблона строки — -с .
- Не выводить имя файла в результатах поиска — -h .
- Без учета регистра — -i .
- Отобразить только имена файлов с совпадением строки — -l .
- Показать номер строки — -n .
- Игнорировать сообщения об ошибках — -s .
- Инверсия поиска (отображение всех строк, в которых не найден шаблон) — -v .
- Слово, окруженное пробелами, — -w .
- Включить регулярные выражения при поиске — -e .
- Отобразить вхождение и N строк до и после него — -An и -Bn соответственно.
- Показать строки до и после вхождения — -Cn .
Практическое применение grep
Поиск подстроки в строке

В окне терминала выводятся все строки, содержащие подстроку. Найденные совпадения подсвечиваются другим цветом.
- С учетом регистра:
- Без учета регистра:
Вывод нескольких строк
- Строка с вхождением и две после нее:
- Строка с вхождением и три до нее:
- Строка, содержащая вхождение, и одну до и после нее:
Чтение строки из файла с использованием регулярных выражений
Регулярные выражения расширяют возможности поиска и позволяют выполнить разбор строки на отдельные элементы. Они активируются при помощи ключа -e.
- Вывод строки, в начале которой встречается слово «Фамилия».
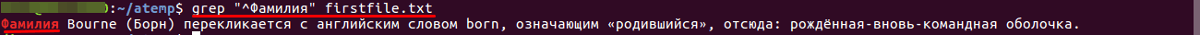 В регулярных выражения для обозначения начала строки используется специальный символ «^».
В регулярных выражения для обозначения начала строки используется специальный символ «^». Чтобы вывести первый символ строки, нужно воспользоваться конструкцией
grep «оболочка$» firstfile.txt Если требуется вывести символ конца строки, то следует применять конструкцию
grep «а.$» firstfile.txt . В этом случае будут выведены все строки, заканчивающиеся на литеру «а».

Если воспользоваться числовыми интервалами, то можно вывести все строки, в которых встречаются числа:
Рекурсивный режим поиска
- Чтобы найти строку или слово в нескольких файлах, расположенных в одной папке, нужно использовать рекурсивный режим поиска:
- Если нет необходимости выводить имена файлов, содержащих искомую строку, то можно воспользоваться ключом-параметром деактивации отображения имен:
Точное вхождение
При поиске союза «и» grep будет выводить все строки, в которых он содержится. Чтобы этого избежать, требуется использовать специальный ключ « w »:
Поиск нескольких слов
Утилита «w» позволяет искать не только одно слово, но и несколько одновременно
Количество строк в файле
При помощи grep можно определить число вхождений строки или подстроки в текстовом файле и вывести ее номер.

- Число вхождений:
- Номера строк с совпадениями:
Инверсия
Если в тексте требуется найти определенные строки, которые не содержат какого-либо слова или подстроки, то рекомендуется использовать инверсионный режим поиска.
Вывод только имени файла
Чтобы не выводить все строки с совпадением, а вывести только имя файла, нужно воспользоваться конструкцией:
Использование sed
Потоковый текстовый редактор « sed » встроен в bash Linux Ubuntu. Он использует построчное чтение, а также позволяет выполнить фильтрацию и преобразование текста.
Синтаксис
Для работы с потоковым текстовым редактором sed используется следующий синтаксис:
sed [options] instructions [file_name] (где «options» — ключи-опции для указания метода обработки текста, «instructions» — команда, совершаемая над найденным фрагментом текста, «file_name» — имя файла, над которым совершаются действия).
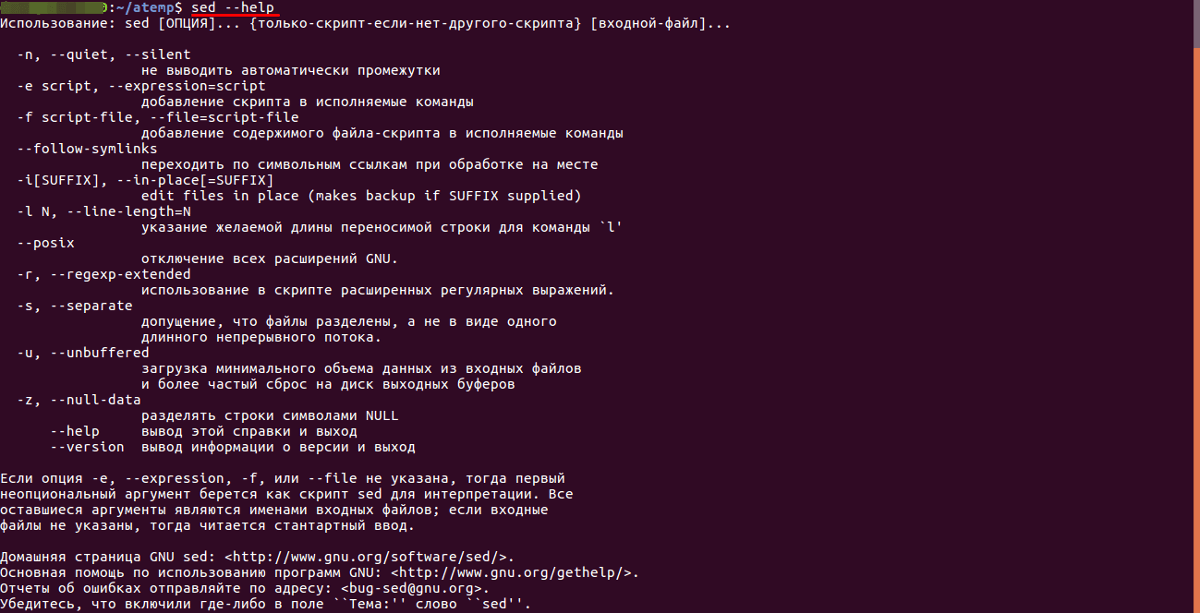
Для вывода всех опций потокового текстового редактора нужно воспользоваться командой:
Распространенные конструкции с sed
Замена слова
Например, если требуется заменить строку в файле или слово с «команды» на «инструкции». Для этого нужно воспользоваться следующими конструкциями:
- Для первого вхождения:
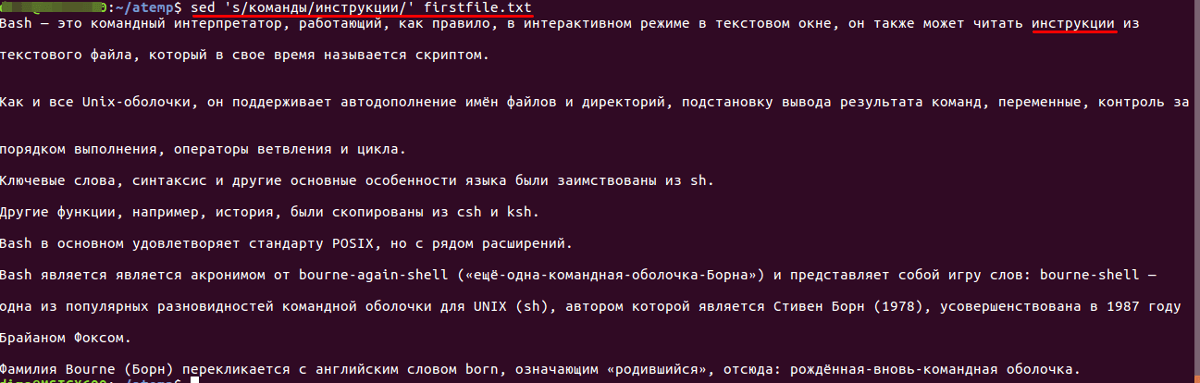
Произвести замену только в строках, которые заканчиваются на«Bash»:
Редактирование файла
Чтобы записать строку в файл, нужно указать параметр замены одной строки на другую, воспользовавшись ключом — -i :
После выполнения команды произойдет замена слова «команды» на «инструкции» с последующим сохранением файла.
Удаление строк из файла
- Удалить первую строку из файла:
- Удалить строку из файла, содержащую слово«окне»:
После выполнения команды будет удалена первая строка, поскольку она содержит указанное слово.
Нумерация строк
Строки в файле будут пронумерованы следующим образом: первая строка — 1, вторая — 2 и т. д.
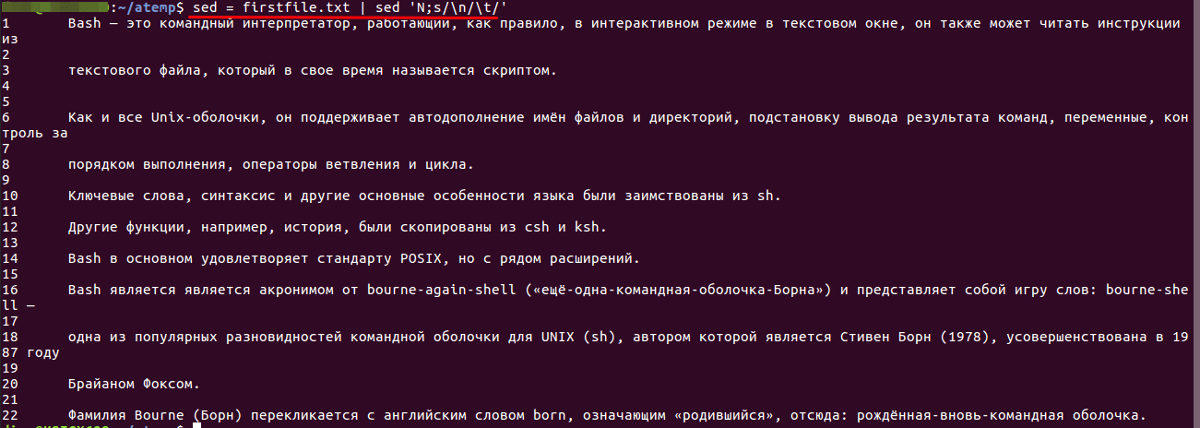
Следует обратить внимание, что нумерация начинается не с «0», как в языках программирования.
Удаление всех чисел из текста
Замена символов
Чтобы заменить набор символов, нужно воспользоваться инструкцией, содержащей команду « y »:
Обработка указанной строки
Утилита производит манипуляции не только с текстом, но и со строкой, указанной в правиле шаблона (3 строка):
Работа с диапазоном строк
Для выполнения замены только в 3 и 4 строках нужно использовать конструкцию:
Вставка содержимого файла после строки
Иногда требуется вставить содержимое одного файла (input_file.txt) после определенной строки другого (firstfile.txt). Для этой цели используется команда:
sed ‘5r input_file.txt’ firstfile.txt (где «5r» — 5 строка, «input_file.txt» — исходный файл и «firstfile.txt» — файл, в который требуется вставить массив текста).
Начни экономить на хостинге сейчас — 14 дней бесплатно!
Источник



