- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Руководство по команде grep в Linux
- Про Linux за 5 минут | Что это или как финский студент перевернул мир?
- Для чего мы пользуемся grep-ом?
- Поиск строк
- Поиск по нескольким параметрам
- Разница между grep, egrep fgrep, pgrep, zgrep
- Разница между find и grep
- Рекурсивный поиск
- Найти пробелы и табуляцию
- Использование регулярных выражений
- Что такое grep и с чем его едят
- Базовые команды Linux для тестировщиков и не только
- Немного о выводе команд
- Базовые команды Linux
- mkdir
- rsync
- telnet
- Решение типовых задач в Linux
- Изменить владельца файла
- Изменить права доступа файла
- Вывести содержимое бинарного файла
- Искать файлы
- Искать текст в файлах
- Смотреть установленные пакеты
- Посмотреть, сколько места занимает дерево директорий
- «Найти и заменить» в файле, в файлах в директории
- Вывести колонку из вывода
- Узнать IP адрес по имени хоста
- Сетевая информация
- Посмотреть открытые порты
- Информация о системе
- Информация о памяти
- Информация о файловых системах (свободное место на дисках)
- Информация о задачах и различной статистике по системе
- Дамп сетевого трафика
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Руководство по команде grep в Linux
Читать между строк
10 минут чтения
То, что система Linux предоставляет пользователю большое многообразие разного функционала уже не секрет. На одном из прошлых материалов мы рассмотрели, как и где можно использовать команду find. В этой же статье мы на примерах разберём команду grep, мощный инструмент системных администраторов.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена

Про Linux за 5 минут | Что это или как финский студент перевернул мир?

Для чего мы пользуемся grep-ом?
Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле. Также можно передать вывод любой команды в grep, что сильно упрощает работу во время поиска и траблшутинга.
Возьмём команду ls. Сама по себе она выводит список всех файлов и папок.
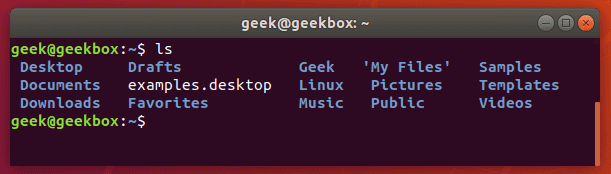
Но если нужно найти конкретную папку или один файл среди сотни других, то мы можем передать вывод команды ls в grep через вертикальную черту (|), а уже grep-у параметром передать нужное слово.
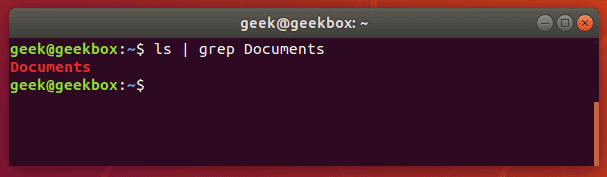
Если команда grep ничего не вернула, значит искомого файла/папки не существует в данной директории.
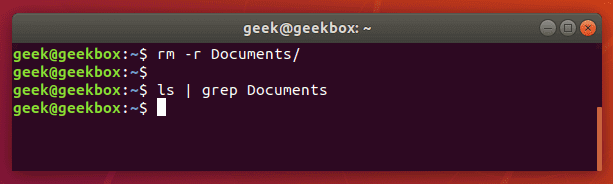
Поиск строк
Если же нужно найти не одно слово, а словосочетание или целое предложение, то параметр команды grep должно быть выделено кавычками. Grep поддерживает как одинарные, так и двойные кавычки.
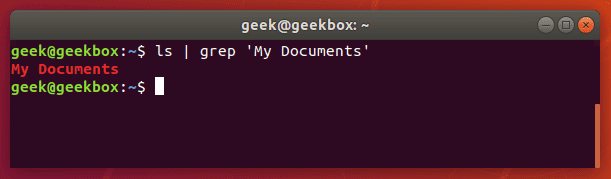
Несмотря на то, что команда grep чаще используется как своего рода фильтр для других команд, но её также можно использовать отдельно как на примере ниже.
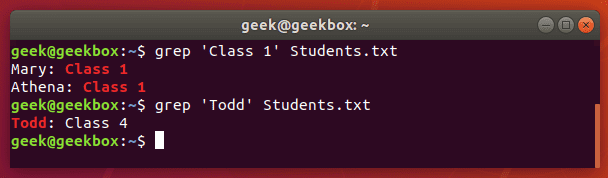
В этом примере мы вели поиск указанных в кавычках слов в файле Students.txt и команда grep успешно справилась со своей задачей.
Поиск по нескольким параметрам
Команде grep можно передавать не один параметр, а несколько. Для этого перед каждым аргументом пишется ключ e. Эту команду система понимает, как «или-или» и выводит все вхождения указанных слов. Заметьте, что кавычками выделена только строка, которая содержит пробел.

Разница между grep, egrep fgrep, pgrep, zgrep
Исторически разные версии Linux-а включали разновидности команды grep. Хотя в современных версия систем базовая команда grep поддерживает все возможности, которыми обладают egrep fgrep, pgrep, zgrep, но все же их тоже стоит рассмотреть.
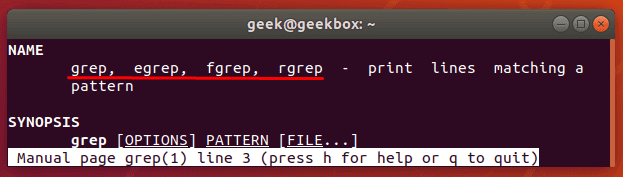
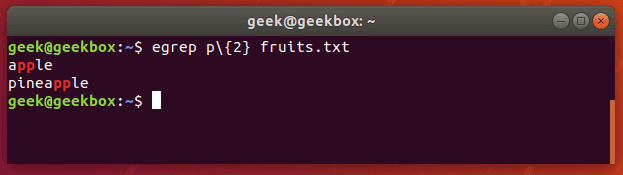
Как видно из вывода man grep (мануал по команде grep), все эти версии всего лишь разные названия основной команды. Например, egrep это тоже самое, что и grep E (помните, командная строка Linux регистрозависимая и команды grep e и grep E интерпретируются по разному). Этой команде в качестве шаблона передается расширенное регулярное выражение. Существует очень много разных ситуаций, где можно воспользоваться этой командой. Например, две команды ниже эквивалентны и выводят все строки, в которых есть две подряд идущих буквы «p».
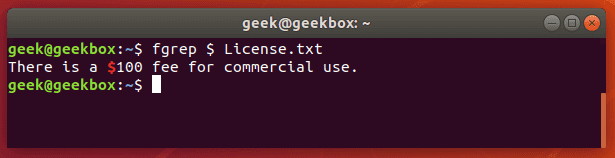
Fgrep это команда grep F, которая обрабатывает переданный шаблон как список фиксированных данных строкового типа. Эта команда полезна, когда в шаблоне используются зарезервированные для регулярных выражений символы, которые при обычно grep пришлось бы экранировать.
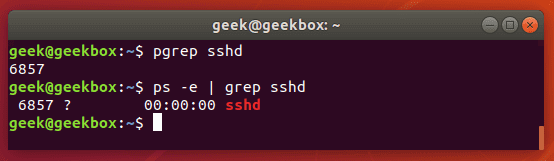
Команда pgrep используется для поиска конкретного процесса, запущенного в системе и возвращает идентификатор указанного процесса (PID). Команда ниже выводит PID процесса sshd. Почти такого же результата можно достичь если запустить команду ps e | grep sshd.
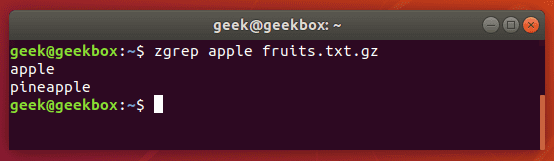
Команда zgrep используется для поиска указанного шаблона в заархивированных файлах, что очень удобно так как не приходится сначала разархивировать файл, а потом уже вести поиск.
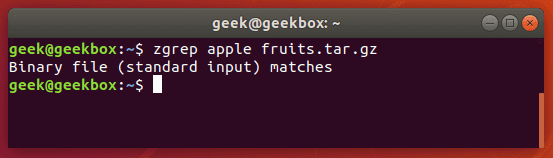
Zgrep также работает с tar архивами, но ограничивается лишь выводом информации о том, нашла ли она соответствие или нет. Это замечание мы сделали потому, что чаще всего gzip-ом архивируются tar файлы.
Разница между find и grep
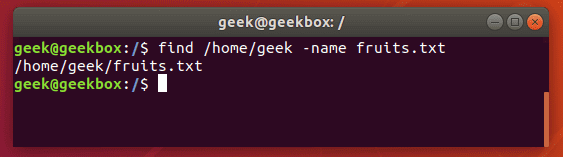
Те, кто только начинает пользоваться командной строкой Linux должны понимать, что find и grep это две разные команды, которые имеют совсем разные функции, даже если оба используются для «поиска» чего-либо.
При поиске файлов grep-ом удобно пользоваться для фильтрации вывода команды find, как и было показано в начале материала. Но если нужно найти какой-то файл в системе по его названию или части названия (при этом используется маска *), то лучше всего обратиться к find. Она выведёт точно расположение искомого файла.
Рекурсивный поиск
Чтобы вести поиск по указанному шаблону среди всех файлов во всех папках и подпапках, команду grep нужно запустить с ключом r. Команда выведет все файлы, где найдено совпадение с указанным шаблоном, а также путь к ним. По умолчанию поиск ведется по текущей директории и поддиректориях.

Найти пробелы и табуляцию
Как и было отмечено ранее, если в шаблоне поиска содержится пробел, то мы должны выделять строку кавычками. Это мы можем использовать для поиска пробелов и знаков табуляции в файле. О том как вставить табуляцию чуть позже.

Есть несколько путей вставки табуляции, но некоторые дистрибутивы могут не поддерживать их. Как известно, в командной строке Linux клавиша TAB сама по себе дополняет введённую команду. Но если комбинировать клавиши ctrl+v, а затем нажать TAB, то система воспримет это как знак табуляции. $ grep » » sample.txt
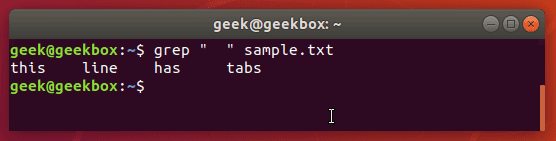
Эта фишка очень помогает при поиске среди конфигурационных файлов системы, так как значения от параметров отделяются табуляцией.
Использование регулярных выражений
Регулярные выражения сильно расширяют возможности команды grep, что позволяет нам вести более гибкий поиск. Далее мы рассмотрим несколько вариантов использования регулярных выражений.
[квадратные скобки] они используются чтобы проверить на соответствие одному из указанных символов.
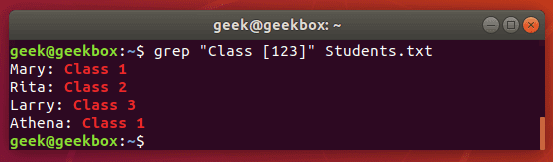
[-] знак дефиса означает диапазон значений. Это могут быть как буквы, так и цифры.
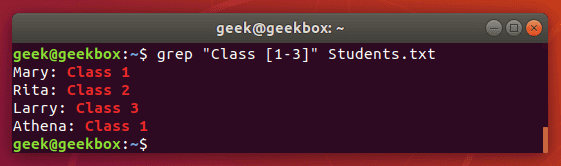
Вторая команда вывела то же, что и первая, но здесь мы обошлись знаком диапазона.
^ каретка используется для поиска строк, которые начинаются с указанного шаблона. Команда ниже выведет все строки, которые начинаются с буквы «А».
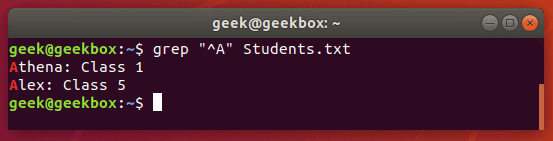
[^] но между квадратными скобками смысл каретки меняется. Здесь он исключает из поиска следующие за ней символы или диапазон символов.
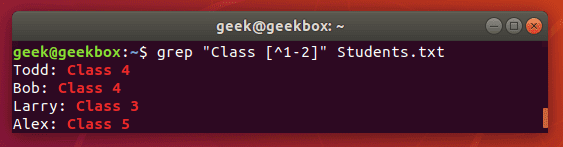
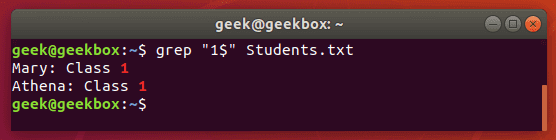
$ знак доллара означает конец строки. Команда выведет только те строки, в конце которых встречает указанный шаблон.
.точка обозначает один любой символ. Чтобы указать несколько любых символов, можно написать символ точку нужное количество раз.
Источник
Что такое grep и с чем его едят
Эта заметка навеяна мелькавшими последнее время на хабре постами двух тематик — «интересные команды unix» и «как я подбирал программиста». И описываемые там команды, конечно, местами интересные, но редко практически полезные, а выясняется, что реально полезным инструментарием мы пользоваться и не умеем.
Небольшое лирическое отступление:
Года три назад меня попросили провести собеседование с претендентами на должность unix-сисадмина. На двух крупнейших на тот момент фриланс-биржах на вакансию откликнулись восемь претендентов, двое из которых входили в ТОП-5 рейтинга этих бирж. Я никогда не требую от админов знания наизусть конфигов и считаю, что нужный софт всегда освоится, если есть желание читать, логика в действиях и умение правильно пользоваться инструментарием системы. Посему для начала претендентам были даны две задачки, примерно такого плана:
— поместить задание в крон, которое будет выполняться в каждый чётный час и в 3 часа;
— распечатать из файла /var/run/dmesg.boot информацию о процессоре.
К моему удивлению никто из претендентов с обоими вопросами не справился. Двое, в принципе, не знали о существовании grep.

Поэтому… Лето… Пятница… Перед шашлыками немного поговорим о grep.
Зная местную публику и дабы не возникало излишних инсинуаций сообщаю, что всё нижеизложенное справедливо для
Это важно в связи с
Для начала о том как мы обычно grep’аем файлы.
Используя cat:
Но зачем? Ведь можно и так:
Или вот так (ненавижу такую конструкцию):
Зачем-то считаем отобранные строки с помощью wc:
Сделаем тестовый файлик:
И приступим к поискам:
Опция -w позволяет искать по слову целиком:
А если нужно по началу или концу слова?
Стоящие в начале или конце строки?
Хотите увидеть строки в окрестности искомой?
Только снизу или сверху?
А ещё мы умеем так
И наоборот исключая эти
Разумеется grep поддерживает и прочие базовые квантификаторы, метасимволы и другие прелести регулярок
Пару практических примеров:
Отбираем только строки с ip:
Работает, но так симпатичнее:
Уберём строку с комментарием?
А теперь выберем только сами ip
Вот незадача… Закомментированная строка вернулась. Это связано с особенностью обработки шаблонов. Как быть? Вот так:
Здесь остановимся на инвертировании поиска ключом -v
Допустим нам нужно выполнить «ps -afx | grep ttyv»
Всё бы ничего, но строка «48798 2 S+ 0:00.00 grep ttyv» нам не нужна. Используем -v
Некрасивая конструкция? Потрюкачим немного:
Также не забываем про | (ИЛИ)
ну и тоже самое, иначе:
Ну и если об использовании регулярок в grep’e помнят многие, то об использовании POSIX классов как-то забывают, а это тоже иногда удобно.
Отберём строки с заглавными символами:
Плохо видно что нашли? Подсветим: 
Ну и ещё пару трюков для затравки.
Первый скорее академичный. За лет 15 ни разу его не использовал:
Нужно из нашего тестового файла выбрать строки содержащие six или seven или eight:
Пока всё просто:
А теперь только те строки в которых six или seven или eight встречаются несколько раз. Эта фишка именуется Backreferences
Ну и второй трюк, куда более полезный. Необходимо вывести строки в которых 504 с обеих сторон ограничено табуляцией.
Ох как тут не хватает поддержки PCRE…
Использование POSIX-классов не спасает:
На помощь приходит конструкция [CTRL+V][TAB]:
Что ещё не сказал? Разумеется, grep умеет искать в файлах/каталогах и, разумеется, рекурсивно. Найдём в исходниках код, где разрешается использование Intel’ом сторонних SFP-шек. Как пишется allow_unsupported_sfp или unsupported_allow_sfp не помню. Ну да и ладно — это проблемы grep’а:
Надеюсь не утомил. И это была только вершина айсберга grep. Приятного Вам чтения, а мне аппетита на шашлыках!
Ну и удачного Вам grep’a!
Источник
Базовые команды Linux для тестировщиков и не только
Всем привет! Меня зовут Саша, и я больше шести лет занимаюсь тестированием бэкенда (сервисы Linux и API). Мысль о статье у меня появилась после очередной просьбы знакомого тестировщика подсказать ему, что можно почитать по командам Linux перед собеседованием. Обычно от кандидата на позицию QA инженера требуют знание основных команд (если, конечно, подразумевается работа с Linux), но как понять, про какие команды стоит почитать во время подготовки к собеседованию, если опыта работы с Linux мало или вовсе нет?
Поэтому, хоть про это уже и много раз написано, я всё же решился написать ещё одну статью «Linux для новичков» и перечислить здесь базовые команды, которые нужно знать перед любым собеседованием в отдел (или компанию), где используют Linux. Я подумал, какие команды и утилиты и с какими параметрами я использую чаще всего, собрал фидбек от коллег, и скомпоновал это всё в одну статью. Статья условно делится на 3 части: сначала краткая информация об основах ввода-вывода в терминале Linux, затем обзор самых базовых команд, а в третьей части описывается решение типовых задач в Linux.
У каждой команды есть много опций, здесь все они перечислены не будут. Всегда можно ввести `man ` или ` —help`, чтобы узнать о команде подробнее.
Если какая-то команда выполняется слишком долго, её можно завершить, нажав в консоли Ctrl+C (процессу посылается сигнал SIGINT).
Немного о выводе команд
Когда запускается процесс в Linux, создаётся 3 стандартных потока данных для этого процесса: stdin, stdout и stderr. Они имеют номер 0, 1 и 2 соответственно. Но нас сейчас интересуют stdout и, в меньшей степени, stderr. Из названий несложно догадаться, что stdout используется для вывода данных, а stderr — для вывода сообщений об ошибках. По умолчанию при запуске команды в Linux stdout и stderr выводят всю информацию на консоль, однако, если вывод команды большой, может быть удобно перенаправить его в файл. Это можно сделать, например, так:
Если мы выведем содержимое файла man_signal, то мы увидим, что оно идентично тому, что было бы при простом запуске команды `man signal`.
Операция перенаправления `>` по умолчанию использует stdout. Можно указать о перенаправлении stdout явно: `1>`. Аналогично можно указать о перенаправлении stderr: `2>`. Можно эти операции скомбинировать и таким образом разделить обычный вывод команды и вывод сообщений об ошибках:
Перенаправить и stdout, и stderr в один файл можно следующим образом:
Операция перенаправления `2>&1` означает перенаправление stderr туда же, куда направлен stdout.
Еще один удобный инструмент для работы с вводом-выводом (а точнее, это удобное средство межпроцессного взаимодействия) — pipe (или конвейер). Конвейеры часто используются для связи нескольких команд: stdout команды перенаправляется в stdin следующей, и так по цепочке:
Базовые команды Linux
Вывести текущую (рабочую) директорию.
Вывести текущую дату и время системы.
Данная команда показывает, кто залогинен в системе. Помимо этого также на экран выводится uptime и LA (load average).
Вывести содержимое директории. Если не передать путь, то выведется содержимое текущей директории.
Лично я часто использую опции -l (long listing format — вывод в колонку с дополнительной информацией о файлах), -t (сортировка по времени изменения файла/директории) и -r (обратная сортировка — в сочетании с -t наиболее «свежие» файлы будут внизу):
Есть 2 специальных имени директории: «.» и «..«. Первое означает текущую директорию, второе — родительскую директорию. Их бывает удобно использовать в различных командах, в частности, ls:
Также есть полезная опция для вывода скрытых файлов (начинаются на «.«) — -a:
И еще можно использовать опцию -h — вывод в human readable формате (обратите внимание на размеры файлов):
Изменить текущую директорию.
Если не передавать имя директории в качестве аргумента, будет использоваться переменная окружения $HOME, то есть домашняя директория. Также может быть удобно использовать `
` — специальный символ, означающий $HOME:
mkdir
Иногда нужно создать определенную структуру директорий: например, директорию в директории, которой не существует. Чтобы не вводить несколько раз подряд mkdir, можно использовать опцию -p — она позволяет создать все недостающие директории в иерархии. Также с этой опцией mkdir не вернет ошибку, если директория существует.
Опция -r позволяет рекурсивно удалять директории со всем их содержимым, опция -f позволяет игнорировать ошибки при удалении (например, о несуществующем файле). Эти опции позволяют, грубо говоря, гарантированно удалить всю иерархию файлов и директорий (если на это есть права у пользователя), поэтому, их нужно использовать с осторожностью (классический пример-шутка — «rm -rf /«, при определенных обстоятельствах удалит вам если не всю систему, то очень много важных для её работоспособности файлов).
Копировать файл или директорию.
У этой команды также есть опции -r и -f, их можно использовать, чтобы гарантированно скопировать иерархию директорий и папок в другое место.
Переместить или переименовать файл или директорию.
Вывести содержимое файла (или файлов).
Также стоит обратить внимание на команды head (вывести n первых строк или байт файла) и tail (о ней — далее).
Вывести n последних строк или байт файла.
Очень полезной является опция -f — она позволяет выводить новые данные в файле в реальном времени.
Иногда текстовый файл слишком большой, и неудобно выводить его командой cat. Тогда можно открыть его с помощью команды less: файл будет выводиться по частям, доступна навигация по этим частям, поиск и прочий простой функционал.
Также может оказаться удобным вариант использования less с конвейером (pipe):
Вывести список процессов.
Я сам обычно использую BSD опции «aux» — вывести все процессы в системе (так как процессов может быть много, я вывел только первые 5 из них, использовав конвейер (pipe) и команду head):
Многие также используют BSD опции «axjf«, что позволяет вывести дерево процессов (здесь я убрал часть вывода для демонстрации):
У этой команды много различных опций, так что при активном использовании рекомендую ознакомиться с документацией. Для большинства же случаев хватит просто знать «ps aux«.
Послать сигнал процессу. По умолчанию посылается сигнал SIGTERM, который завершает процесс.
Так как процесс может иметь обработчики сигналов, kill не всегда приводит к ожидаемому результату — моментальному завершению процесса. Чтобы «убить» процесс наверняка, нужно послать процессу сигнал SIGKILL. Однако это может привести к потере данных (например, если процесс перед завершением должен сохранить какую-то информацию на диск), так что нужно пользоваться такой командой осторожно. Номер сигнала SIGKILL — 9, поэтому короткий вариант команды выглядит так:
Помимо упомянутых SIGTERM и SIGKILL существует еще множество различных сигналов, их список можно легко найти в интернете. И не забывайте, что сигналы SIGKILL и SIGSTOP не могут быть перехвачены или проигнорированы.
Послать хосту ICMP пакет ECHO_REQUEST.
По умолчанию ping работает, пока его не завершить вручную. Поэтому может быть полезна опция -c — количество пакетов, после отправки которых ping завершится самостоятельно. Ещё одна опция, которую я иногда использую — -i, интервал между посылками пакетов.
OpenSSH SSH клиент, позволяет подключаться к удаленному хосту.
Есть много нюансов в использовании SSH, также этот клиент обладает большим количеством возможностей, поэтому при желании (или необходимости) можно почитать про это более подробно.
Копировать файлы между хостами (для этого используется ssh).
rsync
Также для синхронизации директорий между хостами можно использовать rsync (-a — archive mode, позволяет скопировать полностью всё содержимое директории «как есть», -v — вывод на консоль дополнительной информации):
Вывести на экран строку текста.
Здесь заслуживают внимания опции -n — не дополнять строку переносом строки в конце, и -e — включить интерпретацию экранирования с помощью «\».
Также с помощью этой команды можно выводить значения переменных. Например, в Linux exit code последней завершенной команды хранится в специальной переменной $?, и таким образом можно узнать, какая именно ошибка произошла в последнем запущенном приложении:
telnet
Клиент для протокола TELNET. Используется для коммуникации с другим хостом.
Если нужно использовать протокол TLS (напомню, что SSL давно устарел), то telnet для этих целей не подойдёт. Зато подойдёт клиент openssl:
Решение типовых задач в Linux
Изменить владельца файла
Изменить владельца файла или директории можно с помощью команды chown:
В параметр этой команде нужно отдать нового владельца и группу (опционально), разделенных двоеточием. Также при изменении владельца директории может быть полезна опция -R — тогда владельцы изменятся и у всего содержимого директории.
Изменить права доступа файла
Эта задача решается с помощью команды chmod. В качестве примера приведу установку прав «владельцу разрешено чтение, запись и исполнение, группе разрешено чтение и запись, всем остальным — ничего»:
Первая 7 (это 0b111 в битовом представлении) в параметре означает «все права для владельца», вторая 6 (это 0b110 в битовом представлении) — «чтение и запись», ну и 0 — это ничего для остальных. Битовая маска состоит из трёх битов: самый младший («правый») бит отвечает за исполнение, следующий за ним («средний») — за запись, и самый старший («левый») — за чтение.
Также можно выставлять права с помощью специальных символов (мнемонический синтаксис). Например, в следующем примере сначала убираются права на исполнение для текущего пользователя, а затем возвращаются обратно:
У этой команды есть много вариантов использования, поэтому советую прочитать про неё подробнее (особенно про мнемонический синтаксис, например, здесь).
Вывести содержимое бинарного файла
Это можно сделать с помощью утилиты hexdump. Ниже приведены примеры её использования.
С помощью этой утилиты можно вывести данные и в других форматах, однако наиболее часто могут пригодиться именно такие варианты её использования.
Искать файлы
Найти файл по части имени в дереве каталогов можно с помощью команды find:
Также доступны другие опции и фильтры поиска. Например, так можно найти файлы в папке test, созданные более 5 дней назад:
Искать текст в файлах
Справиться с этой задачей поможет команда grep. У неё есть множество вариантов использования, здесь в качестве примера указан самый простой.
Один из популярных способов использования команды grep — использование её в конвейере (pipe):
Опция -v позволяет сделать эффект grep‘а обратным — будут выводиться только строки, не содержащие паттерн, переданный в grep.
Смотреть установленные пакеты
Универсальной команды нет, потому что всё зависит от дистрибутива Linux и используемого пакетного менеджера. Скорее всего вам поможет одна из следующих команд:
Посмотреть, сколько места занимает дерево директорий
Один из вариантов использования команды du:
Можно менять значение параметра -d, чтобы получать более подробную информацию о дереве директорий. Также можно использовать команду в комбинации с sort:
Опция -h у команды sort позволяет сортировать размеры, записанные в human readable формате (например, 1K, 2G), опция -r позволяет отсортировать данные в обратном порядке.
«Найти и заменить» в файле, в файлах в директории
Данная операция выполняется с помощью утилиты sed (без флага g в конце заменится только первое вхождение «old-text» в строке):
Можно использовать её для нескольких файлов сразу:
Вывести колонку из вывода
Справиться с этой задачей поможет awk. В данном примере выводится вторая колонка вывода команды `ps ux`:
При этом надо иметь ввиду, что awk обладает гораздо более богатым функционалом, так что при необходимости работы с текстом в командной строке стоит почитать об этой команде подробнее.
Узнать IP адрес по имени хоста
С этим поможет одна из следующих команд:
Сетевая информация
Можно использовать ifconfig:
При этом, если, например, вас интересует только IPv4, то можно добавить опцию -4:
Посмотреть открытые порты
Для этого используют утилиту netstat. Например, чтобы посмотреть все слушающие TCP и UDP порты с отображением PID’а процесса, слушающего порт, и с числовым представлением порта, нужно использовать ее со следующими опциями:
Информация о системе
Получить данную информацию можно с помощью команды uname.
Чтобы понять, в каком формате производится вывод, можно обратиться к help‘у данной команды:
Информация о памяти
Чтобы понять, сколько оперативной памяти занято или свободно, можно воспользоваться командой free.
Информация о файловых системах (свободное место на дисках)
Команда df позволяет посмотреть, сколько места свободно и занято на примонтированных файловых системах.
Опция -T указывает, что нужно выводить тип файловой системы.
Информация о задачах и различной статистике по системе
Для этого используется команда top. Она способна вывести разную информацию: например, топ процессов по использованию оперативной памяти или топ процессов по использованию процессорного времени. Также она выводит информацию о памяти, CPU, uptime и LA (load average).
Эта утилита обладает богатым функционалом, так что если вам надо часто ей пользоваться, лучше ознакомиться с её документацией.
Дамп сетевого трафика
Для перехвата сетевого трафика в Linux используется утилита tcpdump. Чтобы сдампить трафик на порте 12345, можно воспользоваться следующей командой:
Опция -A говорит о том, что мы ходим видеть вывод в ASCII (поэтому это хорошо для текстовых протоколов), -i any указывает, что нас не интересует сетевой интерфейс, port — трафик какого порта дампить. Вместо port можно использовать host, либо комбинацию host и port (host A and port X). И еще полезной может оказаться опция -n — не конвертировать адреса в хостнеймы в выводе.
Что если трафик бинарный? Тогда нам поможет опция -X — выводить данные в hex и ASCII:
При этом надо учитывать, что в обоих вариантах использования будут выводиться IP пакеты, поэтому в начале каждого из них будут бинарные заголовки IP и TCP. Вот пример вывода для запроса «123» посланного в сервер, слушающий порт 12345:
Источник



