- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Загрузка ЦПУ в Linux — насколько варит ваш котелок
- Методы проверки
- Проверяем загрузку процессора с помощью команды top
- Немного более модный способ: htop
- Прочие способы проверки степени загрузки ЦПУ
- Как настроить оповещения о слишком высокой нагрузке на процессор
- Заключение
- Полезно?
- Почему?
- Более чем 80 средств мониторинга системы Linux
- Network related monitoring
- System related monitoring
- Log monitoring tools
- System tools
- Infrastructure monitoring tools
- Бонус
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Загрузка ЦПУ в Linux — насколько варит ваш котелок
Понимать состояние ваших серверов с точки зрения их загрузки и производительности — крайне важная задача. В этой статье мы опишем несколько самых популярных методов для проверки и мониторинга загрузки ЦПУ на Linux хосте.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена


Методы проверки
Проверяем загрузку процессора с помощью команды top
Отличным способом проверки загрузки является команда top. Вывод этой команды выглядит достаточно сложным, зато если вы в нем разберетесь, то точно сможете понять какие процессы занимают большую часть ваших вычислительных мощностей.
Команда состоит всего из трех букв: top
У вас откроется окно в терминале, которое будет отображать запущенные сервисы в реальном времени, долю системных ресурсов, которую эти сервисы потребляют, общую сводку по загрузке CPU и т.д
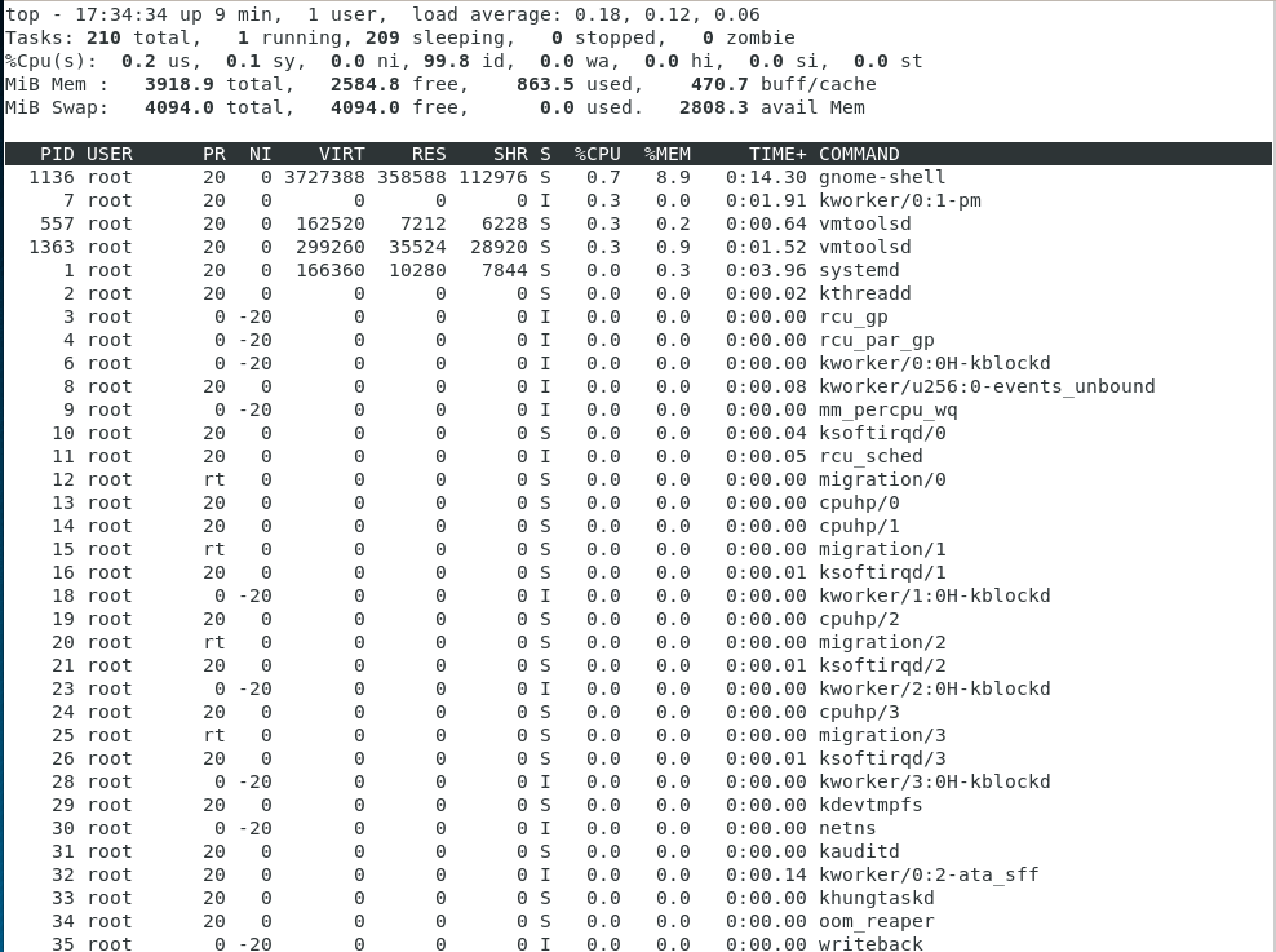
Будем идти по порядку: первая строчка отображает системное время, аптайм, количество активных пользовательских сессий и среднюю загруженность системы. Средняя загруженность для нас особенно важна, т.к дает понимание о среднем проценте утилизации ресурсов за некоторые промежутки времени.
Три числа показывают среднюю загрузку: за 1, 5 и 15 минут соответственно. Считайте, что эти числа — это процентная загрузка, т.е 0.2 означает 20%, а 1.00 — стопроцентную загрузку. Это звучит и выглядит достаточно логично, но иногда там могут проскакивать странные значения — вроде 2.50. Это происходит из-за того, что этот показатель не прямое значение загрузки процессора, а нечто вроде общего количества «работы», которое ваша система пытается выполнить. К примеру, значение 2.50 означает, что текущая загрузка равна 250% и ваша система на 150% перегружена.
Вторая строчка достаточна понятна и просто показывает количество задач, запущенных в системе и их текущий статус.
Третья строчка позволит вам отследить загрузку ЦПУ с подробной статистикой. Но здесь нужно сделать некоторые комментарии:
- us: процент времени, когда ЦПУ был загружен и которое было затрачено на user space (созданные/запущенные пользователем процессы)
- sy: процент времени, когда ЦПУ был загружен и которое было затрачено на на kernel (системные процессы)
- ni: процент времени, когда ЦПУ был загружен и которое было затрачено на приоритезированные пользовательские процессы (системные процессы)
- id: процент времени, когда ЦПУ не был загружен
- wa: процент времени, когда ЦПУ ожидал отклика от устройств ввода — вывода (к примеру, ожидание завершения записи информации на диск)
- hi: процент времени, когда ЦПУ получал аппаратные прерывания (например, от сетевого адаптера)
- si: процент времени, когда ЦПУ получал программные прерывания (например, от какого-то приложения адаптера)
- st: сколько процентов было «украдено» виртуальной машиной — в случае, если гипервизору понадобилось увеличить собственные ресурсы
Следующие две строчки показывают сколько занято/свободно оперативно памяти и файла подкачки, и не так релевантны относительно задачи проверки нагрузки на процессор. Под информацией о памяти вы увидите список процессов и процент ЦПУ, который они тратят.
Также вы можете нажимать на кнопку t, чтобы прокручивать между различными вариантами вывода информации и использовать кнопку q для выхода из top
Немного более модный способ: htop
Существует более удобная утилита под названием htop, которая предоставляет достаточно удобный интерфейс с красивым форматированием. Установка утилиты экстремально проста:
Для Ubuntu и Debian:
sudo apt-get install htop
Для CentOS и Red Hat:
yum install htop
dnf install htop
После установки просто введите команду ниже:

Как видно на скриншоте, htop гораздо лучше подходит для простой проверки степени загрузки процессора. Выход также осуществляется кнопкой q
Прочие способы проверки степени загрузки ЦПУ
Есть еще несколько полезных утилит, и одна из них (а точнее целый набор) называется sysstat.
Установка для Ubuntu и Debian:
sudo apt-get install sysstat
Установка для CentOS и Red Hat:
yum install sysstat
Как только вы установите systat, вы сможете выполнить команду mpstat — опять же, практически тот же вывод, что и у top, но в гораздо лаконичнее.

Следующая утилита в этом пакете это sar. Она наиболее полезна, если вы ее вводите вместе с каким-нибудь числом, например 6. Это определяет временной интервал, через который команда sar будет выводить информацию о загрузке ЦПУ.

К примеру, проверяем загрузку ЦПУ каждые 6 секунд:
Если же вы хотите остановить вывод после нескольких итераций, например 10, добавьте еще одно число:
Так вы также увидите средние значения за 10 выводов.
Как настроить оповещения о слишком высокой нагрузке на процессор
Одним из самых правильных способов является написание простого bash скрипта, который будет отправлять вам алерты о слишком высокой степени утилизации системных ресурсов.
Скрипт будет использовать обработчик sed и среднюю загрузку от команды sar. Как только нагрузка на сервер будет превышать 85%, администратор будет получать письмо на электронную почту. Соответственно, значения в скрипте можно изменить под ваши требования — к примеру поменять тайминги, выводить алерт в консоль, отправлять оповещения в лог и т.д.
Естественно, для выполнения этого скрипта нужно будет запустить его по крону:
Для ежеминутного запуска введите:
Заключение
Соответственно, лучшим способом будет комбинировать эти способы — например использовать htop при отладке и экспериментах, а для постоянного контроля держать запущенным скрипт.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Полезно?
Почему?
😪 Мы тщательно прорабатываем каждый фидбек и отвечаем по итогам анализа. Напишите, пожалуйста, как мы сможем улучшить эту статью.
😍 Полезные IT – статьи от экспертов раз в неделю у вас в почте. Укажите свою дату рождения и мы не забудем поздравить вас.
Источник
Более чем 80 средств мониторинга системы Linux
Ниже будет приведен список инструментов мониторинга. Есть как минимум 80 способов, с помощью которых ваша машинка будет под контролем.

1. первый инструмент — top
Консольная команда top- удобный системный монитор, простой в использовании, с помощью которой выводится список работающих в системе процессов, информации о этих процессах. Данная команда в реальном времени сортирует их по нагрузке на процессор, инструмент предустановлен во многих системах UNIX.
2. htop
htop — системный монитор, как альтернатива команде top, показывает динамический список всех (в отличие от top) системных процессов, время непрерывной работы, использование процессоров и памяти.
atop — интерактивный монитор, аналогичен top, выводит новые изменения об активных процессах в системе. Хороший инструмент для отслеживания узких мест, контроль загрузки центрального процессорного устройства, RAM, компьютерной сети. Из-за того, что работает непрерывно может грузить сервер. Сочетает в себе возможности top, netstat, iostat, accounting и другие. Сохраняет данные в файл собственного двоичного формата (записывает состояние системы в сжатый файл).
apachetop — консольная утилита, мониторит трафик в реальном времени, разбивает логи apache и показывает вывод на экран, одним словом показывает подробную картину использования ваших сайтов.
утилита ftptop дает основную информацию о всех текущих ftp-соединениях с сервером, информацию об общем количестве сеансов, количество загрузок и скачиваний, кто клиент. Позволяет увидеть подключенных к ftp серверу пользователей.
Интересная, удобна и полезная утилита под названием mytop. Подобна утилите top для систем Unix, mytop просматривает все обращения к MySQL серверу в реальном времени.
powertop — утилита, позволяющая обнаружить в системе компоненты, которые потребляют больше энергии чем нужно на вашем ноутбуке, и показывает общее электропотребление (в Вт), информация считывается с различных источников ядра. Это позволит управлять /эксперементировать с настройками по управлению электропитанием, эффективно настроить потребление энергии под вашу машину.
iotop — утилита подобна утилите top, но отображает использование не CPU и памяти, а работу процессов с дисками, написана на Python. Поможет вам определить какой процесс обращается к жесткому диску в Linux. Отображает активные процессы, которые в данный момент выполняют операции I/O с диском, собирает статистику за определенное время.
Network related monitoring
ntopng является следующим поколением ntop, инструмент позволяет мониторить сколько, что и какой IP прокачал через интерфейс на шлюзе, показывает распределение IP-трафика, геолокации хостов, анализ сетевого трафика.
iftop — выводит информацию об активных сетевых соединениях, скорость сетевой закачки/отдачи, мониторит трафик онлайн, разделяет трафик по протоколам, интерфейсам и хостам.
iftop аналогичен top по части использования сети.
jnettop визуализирует сетевой трафик аналогично iftop, мониторит сетевую активность. Утилита для мониторинга трафика в реальном времени.
bandwidthd — утилита для контроля трафика конечных пользователей, строит сводные таблицы (html) и графики по каждому пользователю по IP и по подсети с разбивкой по дням, неделям и месяцам.
EtherApe — показывает сетевой трафик в виде графика, показывает не только соединения, но и поток по каждому из них, вид протокола по номеру порта, сетевую активность разных хостов. На графике узлы выведены в виде кольца, а соединения в виде линий, так вот, чем интенсивнее трафик, тем толще соединительные линии, различные типы трафика обозначены различными цветами.
ethtool — утилита настройки сетевых интерфейсов в Linux. Это означает, что bond0, tun0 и другие устройства, которые не являются физическими, с помощью ethtool ни просматривать, ни редактировать их параметры нельзя.
NetHogs — утилита, которая отслеживает любую сетевую активность всех процессов на компьютере, аналогична top только для сети. Утилита есть в стандартных репозиториях и устанавливается всего одной командой:
Запустить утилиту можно только с правами root-пользователя:
iptraf — утилита наблюдения за сетевыми интерфейсами, мониторит трафик по всем TCP соединениям, приводит статистику по загрузке сетевых интерфейсов, по протоколам, по портам, по размерам пакетов.
ngrep — тотже grep только на сетевом уровне, служит для выборки и просмотра содержимого пакетов, является pcap-совместимой утилитой, дает возможность использовать шестнадцатиричные строки при определении шаблонов.
MRTG — утилита мониторит сетевые линки. MRTG на выходе генерирует html страницы с графиками в png.
bmon — утилита для мониторинга сразу нескольких сетевых интерфейсов в режиме реального времени, поддерживает разные методы ввода/вывода и фильтры, показывает загруженность сетевого интерфейса в виде графика, суммарная загрузка сетевого интерфейса выводится в виде таблицы.
traceroute — утилита с помощью которой можно определить на каком участке IP-сети произошел сбой, «исследовать» IP-сети (маршрутизацию, серверы DNS, магистральный канал передачи данных, он же бэкбон, систему подсетей и т.д.)
IPTState — выводит статистику открытых портов в виде таблицы с указанием IP адресов. Эффективный инструмент, мониторит IP трафик, выводит как общую статистику для всех сетевых интерфейсов, так и детализированную статистику для отдельного взятого интерфейса.
darkstat — мониторит сетевой трафик, выводит статистику использования сети, отправляет отчеты по http. Собранная информация о скорости, количестве переданных пакетов, байтах, посещенных хостах и данных о хостах выводится в виде веб странички.
vnStat — утилита для учета сетевого трафика, сохраняет историю сетевого трафика для выбранных интерфейсов, трафик считается как входящий, так и исходящий для каждого интерфейса. vnStat получает данные из ядра Linux.
netstat — утилита используется для проверки активных TCP соединений, выводит информацию о используемом протоколе, локальном адресе и номере порта, внешнем адресе и номере порта, а также информацию о состоянии соединения.
ss — утилита, можно использовать вместо netstat, она способна показывать более детальную информацию и быстрее, если хотите вывести суммарную статистику — эта утилита для вас. ss собирает и выводит информации о всех TCP и UDP портах, открытых ssh / ftp / http / https соединениях и т.д.
nmap — утилита позволяет сканировать сервер, определяет какая ОС установлена, можно узнать, защищен ли компьютер какими-либо пакетными фильтрами или фаерволом и многие другие возможности (утилита с открытым исходным кодом для исследования сети и проверки безопасности).
MTR — утилита для диагностики сети, комбинирует в себе возможности программ traceroue и ping, производит исследование соединений между узлом, на котором она запущена и целевым узлом, программа позволяет определить узел, на котором происходят потери пакетов.
Tcpdump — выводит заголовки пакетов проходящих через сетевой интерфейс, которые совпадают с булевым выражением, входит в большинство дистрибутивов Unix и позволяет перехватывать и отображать/сохранять в файл сетевой трафик. С помощью tcpdump можно анализировать трафик на сетевом уровне (ARP, ICMP), на транспортном уровне (TCP, UDP).
Justniffer — консольная утилита для анализа трафика, сниффер протокола HTTP, основанный на pcap и заточенный под TCP.
System related monitoring
nmon — утилита системного мониторинга, выводит информацию о ЦП, оперативной памяти, сети, дисках, как в виде графиков, так и в числовых данных, файловых системах, NFS, самых нагружающих процессах, ресурсах.
conky — многофункциональный полностью настраиваемый системный монитор для Linux и BSD систем, отслеживает многие показатели системы, такие как CPU, память, swap, размеры дисков, температуру, скорость закачки и загрузки, системные сообщения и многое другое.
Glances — утилита для мониторинга системных ресурсов в режиме реального времени, выполняет мониторинг в одном окне, выводит информацию о использование CPU, Load Average, использование RAM и Swap, битрейт интерфейсов, данные сенсоров (только в Linux), битрейт ввода/вывода, использование ФС, информацию о процессах.
saidar — маленький инструмент, который выводит основную информацию о системных ресурсах (показывает загрузку процессора, памяти, процессов и сетевых интерфейсов).
RRDtool — утилита для мониторинга сети и аппаратных ресурсов, набор утилит RRDtool предназначен для хранения, обработки и отображения любых данных, изменяющихся во времени, сюда относятся: сетевой трафик, пропускная способность сети, загрузка процессора и ОЗУ, температура.
RRDTool собирает информацию и создает графики, информация хранится в кольцевой БД. Размер БД остается постоянным, потому что ячейки задействованы циклически.
monit — утилита выполняет те же функции что и monitord, мониторит состояние сервисов, отправляет уведомления о различных событиях по email, совершает действия по перезапуску служб в зависимости от условий. Есть возможность следить за состоянием системы как из командной строки, так и через собственный веб-сервер monit.
Linux process explorer — компактное, но мощное C++ / QT графическое приложение для просмотра активных процессов (диспетчер задач) и мониторинга состояния системы (системный монитор) подробно
df — утилита, выводит данные о размере свободного дискового пространства указанной файловой системы или файловой системы, к которой относится указанный файл, сообщает его размер, точки монтирования. Если не заданы ни файл, ни файловая система, утилита выводит статистику по всем cмонтированным файловым системам. Выводимые значения соответствуют количеству 512-байтных блоков.
discus — аналогичен df, отличие графически вывод выглядит приятнее)
xosview — является классическим инструментом для мониторинга системы, он прост, отображает текущее состояние системы в виде набора графических полос, длинна и ширина которых зависит от размера окна.
Dstat — хорошая утилита, чтобы мониторить состояния системы, анализировать производительно и диагностировать сбои в интерактивном режиме. Можно подключать разнообразные модули для мониторинга различных служб (mysql, nfs, postfix). Универсальная замена для Vmstat, IOSTAT, NetStat и ifstat.
SNMP — протокол модели OSI, был разработан с целью проверки функционирования сетевых маршрутизаторов и мостов, потом сфера действия протокола охватила и другие сетевые устройства, такие как хабы, шлюзы, терминальные сервера, LAN Manager сервера, машины под управлением Windows NT.
Утилиты пакета Net-SNMP — для отслеживания параметров маршрутизатора.
incron (INotify CRON) — пакет утилит, можно запускать скрипты по событиям на файловой системе, используя систему уведомлений ядра Linux inotify. Утилита типа как cron, но в качестве рычага для выполнения команды не время, а совпадение заданного события файловой системы применительно к указанному файлу.
monitorix — простой инструмент для мониторинга системы, можно контролировать загрузку и температуру процессора, оперативной памяти, жестких дисков и прочего оборудования. Изначально был создан для использования в производственных серверов Linux / UNIX, но может быть использован на встроенных устройствах.
vmstat — статистика виртуальной памяти, небольшой встроенный инструмент, который отслеживает и отображает краткую информацию о состоянии памяти в компьютере.
uptime — утилита, показывает текущее время, время работы после загрузки, количество текущих пользователей в компьютерной системе и нагрузку за последние 1, 5 и 15 минут.
46. mpstat — встроенный инструмент, который отслеживает использование процессоров в системе. Наиболее часто используемая команда mpstat -P ALL — показывает развернутую статистику всех процессов системы.
pmap — выводит данные о распределении памяти между процессами, позволяет найти причину узких мест, связанных с использованием памяти.
ps — утилита для мониторинга процессов в режиме реального времени, показывает список всех процессов, которые выполнялись на момент запуска этой программы, работает быстрее чем top, ориентирована на просмотр PID спецефического процесса и всей командной строки каждого процесса.
sar — утилита, часть Systat пакета, используется для мониторинга различных подсистем Linux (процессор, память, ввод/вывод) в реальном времени. Мощная утилита, она удобна, когда нужно собрать информацию об активностях за некоторый период для дальнейшего использования.
collectl — утилита для мониторинга загрузки процессора, сети, мониторит производительность и собирает статистику с различного оборудования, различных служб таких как bind, apache, openvpn, mysql и других.
iostat — утилита для выявление узких мест, связанных с диском, выдает информацию о дисковом вводе/выводе и об использовании процессора.
free — утилита выводит информацию о полном обьеме памяти, свободной и занятой части памяти, включая swap-разделы.
/Proc file system — файловая система дает возможность изучить ядро Linux изнутри). Из этих статистических данных вы можете получить подробную информацию о различных аппаратных устройств на вашем компьютере.
GKrellM — настраиваемый виджет с различными темами, который отображает на рабочем столе данные об устройстве системы: CPU, температуру, память, сеть и так далее.
Gnome system monitor — мониторит работу системы, утилита выводит в виде графиков информацию в реальном времени о ресурсах — использование процессора (CPU), использование оперативной памяти (RAM) и файла подкачки (SWAP), а также использование сети.
Log monitoring tools
GoAccess — утилита, с помощью которой можно анализировать логи веб серверов и строить отчеты (анализ логов доступа к вашим сайтам) в режиме реального времени. Кроме того, данные можно выводить в HTML, JSON или CSV. Выводит общую статистику, топ посетителей, 404, геолокации и многое другое.
Logwatch — анализирует логи системы по различным критериям с возможность составления отчета и отправки его по почте, построена на модульном принципе, вы можете создать собственные критерии для анализа.
Swatch — утилита для активного мониторинга журналов регистрации, контролирует практически любые типы лог файлов.
MultiTail — консольный инструмент, можно наблюдать за log файлами, а также за выводом других команд (таких как rsstail, wtmptail, negtail), может разбивать терминал на много маленьких окон.
System tools
acct or psacct — утилиты для мониторинга пользователей и приложений, которые работают или работали в системе, работает в режиме background и собирает в логи данные, можно отслеживать количество ресурсов потребляемых тем или иным приложением.
whowatch — утилита, отслеживает пользователей в вашей системе и позволяет видеть в реальном времени, какие команды и процессы они используют.
strace — утилита, которая отслеживает системные вызовы, которые делает указанный процесс, а также какие сигналы он получает.
DTrace — большой брат strace, утилита для отладки iOS-приложений, она нужна при отладке сложных случаев, когда вам нужно задать правила для фильтрации вызываемых функций, утилита не для слабонервных, нужно изучить «1000 и 1 „книгу для работы с ней.
webmin — веб-инструмент для системного администрирования, избавляет от необходимости вручную редактировать файлы конфигурации Unix, позволяет удаленно управлять системой в случае необходимости, вы можете настраивать аккаунты юзеров, сервер Apache, DNS, файловый сервер и другое.
stat — встроенный инструмент, отображает информацию о состоянии файлов и файловых систем, выводит данные о том как, когда файл был изменен, или о его правке.
ifconfig — команда позволяет конфигурировать сетевые интерфейсы.
ulimit — утилита, с ее помощью можно установить ограничения на общесистемные ресурсы, обеспечивает контроль над ресурсами для оболочки и процессов, запущенных под ее управлением, встроена в интерпретатор bash. Значения limit, как правило указывается в 1024-байтных блоках.
cpulimit — небольшая утилита, которая поможет ограничить использование процессом CPU.
lshw — небольшая утилита предоставляет детальную информацию о конфигурации оборудования компьютера, выводит данные о памяти, версии микропрограммы, устройстве материнской платы, типе и скорости работы процессора, конфигурации кэша, частотах шин.
w — встроенная команда, которая отображает информацию о пользователях, которые в настоящее время используют машину, краткий учет о текущей активности в системе.
lsof (List Of Opened Files) — утилита для вывода информации о том, какие файлы используются теми или иными процессами.
Infrastructure monitoring tools
Server Density — инструмент мониторинга Linux, позволяет настраивать оповещения и просматривать графики для системной и сетевой метрики.
OpenNMS — мониторит различные сервисы и внутренние системы сетевого и серверного оборудования.
SysUsage — утилита, работает на всех unix-платформах и отображает подробную информацию о процессорах, памяти, устройствах ввода/вывода, сетевых устройствах, файлах, процессах и датчиках температуры. Диаграммы создаются при помощи rrdtool.
brainypdm — веб-инструмент управления данными и мониторингом, который собирает данные о производительности с помощью nagios.
PCP — дает возможность собирать метрики с нескольких хостов, можете получить доступ к данным графика через веб-интерфейс или GUI. Хорошо подходит для мониторинга больших систем.
KDE system guard — менеджер задач, графический монитор, выдающий сведения о системе в режиме реального времени, приложение для KDE, позволяет осуществлять мониторинг локальных и удаленных хостов.
Munin — OpenSource проект, который написан на Perl и использующем RRDtool, инструмент мониторинга ресурсов, собирает данные с нескольких серверов одновременно и выводит все в графиках (все прошедшие события сервера, нагрузку).
Nagios — приложения для полного мониторинга системы и сетей.
Zenoss — системы мониторинга, которая наблюдает за состоянием устройств в сети, что может помочь предупредить проблемы еще до их появления, функция автообнаружения позволяет быстро собрать информацию обо все активных системах в сети, ядро Zenoss анализирует среду, что дает возможность быстро разобраться с большим количеством специфических устройств.
Cacti — с помощью протокола SNMP снимает статистику с устройств, через RRD-tool делает наглядные графики, будь то использование дискового пространства на файл-сервере, или загрузка интерфейсов комутатора.
Zabbix — система мониторинга, которая состоит из нескольких подсистем, причем все они могут размещаться на разных машинах, используется для мониторинга серверов (в основном).
Бонус
collectd — собирает статистку об использовании ресурсов, легконастраиваемый инструмент.
Observium — система мониторинга и наблюдения за сетевыми устройствами и серверами.
Nload — инструмент командной строки, контролирует пропускную способность сети, если возникает потребность получить визуальное представление о загруженности сетевых интерфейсов системы, увидеть общую статистику по сетевому трафику.
Вы можете установить его с помощью:
SmokePing — утилита для накопления информации о задержках в передаче и потере пакетов, отображает все состояния в виде графиков, можно контролировать скорость реакции сервисов на запросы.
MobaXterm приходит на помощь и позволяет использовать многие из терминальных команд, которые обычно встречаются в Linux, если вы работаете в среде Windows.
Shinken monitoring — система мониторинга, гибкая в настройке, много совместимого софта, с собственным WebUI, с широким спектром поддерживаемого сетевого и серверного оборудования.
Источник



