- Глава 28. /dev/zero и /dev/null
- Что означает команда > /dev/null 2>&1
- Перенаправление вывода
- Стандартные ввод, вывод и ошибка
- Что означает «> /dev/null 2>&1»?
- What is /dev/null and How to Use It
- Prerequisites
- Using /dev/null
- Redirecting output to /dev/null
- Redirect all output to /dev/null
- Other examples
- Final thoughts
- About the author
- Sidratul Muntaha
- Linux что такое dev null
Глава 28. /dev/zero и /dev/null
Псевдоустройство /dev/null — это, своего рода, «черная дыра» в системе. Это, пожалуй, самый близкий смысловой эквивалент. Все, что записывается в этот файл, «исчезает» навсегда. Попытки записи или чтения из этого файла не дают, ровным счетом, никакого результата. Тем не менее, псевдоустройство /dev/null вполне может пригодиться.
Подавление вывода на stdout.
Подавление вывода на stderr (from Пример 12-2).
Подавление вывода, как на stdout, так и на stderr.
Удаление содержимого файла, сохраняя, при этом, сам файл, со всеми его правами доступа (очистка файла) (из Пример 2-1 и Пример 2-2):
Автоматическая очистка содержимого системного журнала (logfile) (особенно хороша для борьбы с надоедливыми рекламными идентификационными файлами ( «cookies» )):
Пример 28-1. Удаление cookie-файлов
Подобно псевдоустройству /dev/null, /dev/zero так же является псевдоустройством, с той лишь разницей, что содержит нули. Информация, выводимая в этот файл, так же бесследно исчезает. Чтение нулей из этого файла может вызвать некоторые затруднения, однако это можно сделать, к примеру, с помощью команды od или шестнадцатиричного редактора. В основном, /dev/zero используется для создания заготовки файла с заданой длиной.
Пример 28-2. Создание файла подкачки (swapfile), с помощью /dev/zero
Еще одна область применения /dev/zero — «очистка» специального файла заданного размера, например файлов, монтируемых как loopback-устройства (см. Пример 13-6) или для безопасного удаления файла (см. Пример 12-42).
Пример 28-3. Создание электронного диска
Источник
Что означает команда > /dev/null 2>&1

Сегодня в статье разберемся, что же это за такая команда в Linux системах > /dev/null 2>&1 . Особенно заметно использование таких команд во время работы компилятора.
К примеру, у нас есть такая строчка:
Перенаправление вывода
Оператор > («больше чем»), как в примере выше, переадресовывает вывод программы. В данном случае, что-то отправляется в /dev/null, а что-то переадресовывается в &1.
Стандартные ввод, вывод и ошибка
Существует три стандартных значения ввода и вывода для программ. Ввод получают от клавиатуры (интерактивная, диалоговая программа), или из программы, обрабатывающей вывод другой программы.
Результат программы обычно печатается в стандартной вывод и иногда в файл «STDERR» (ошибка). Все это три дескриптора файла (вы можете представить их как «потоки данных», пришли из языка программирования C), которые часто называют STDIN, STDOUT и STDERR.
Но часто к ним обращаются не по имени, а по номеру:
- 0 — STDIN
- 1 — STDOUT
- 2 — STDERR
По умолчанию, если вы не укажете номер, то будет подразумеваться STDOUT.
В нашем примере видно, что команда направляет свой стандартный вывод в /dev/null (псевдоустройство, которое может принять произвольный объём данных, не сохраняя их совершенно нигде, следовательно, подавив стандартный вывод). Затем все ошибки (то есть STDERR) перенаправить в стандартный вывод. Необходимо поставить амперсанд «&» перед номером назначения.
Смысл вкратце — «весь вывод указанной команды спихнуть в черную дыру!«.
Это один из способов сделать программу по-настоящему безмолвной. Добавлю, что команда в примере аналогична команде
Если есть вопросы, то пишем в комментариях.
Также можете вступить в Телеграм канал, ВК или подписаться на Twitter. Ссылки в шапки страницы.
Заранее всем спасибо.
Источник
Что означает «> /dev/null 2>&1»?
 Долгое время никто не мог объяснить мне, что за амперсанды, знаки и цифры идут после юниксовых команд. При этом все примеры были показаны без объяснения — зачем все это? Гугл также не давал ответа. Особенно заметно использование таких команд во время работы компилятора. В этой статье постараюсь объяснить эти странные команды.
Долгое время никто не мог объяснить мне, что за амперсанды, знаки и цифры идут после юниксовых команд. При этом все примеры были показаны без объяснения — зачем все это? Гугл также не давал ответа. Особенно заметно использование таких команд во время работы компилятора. В этой статье постараюсь объяснить эти странные команды.
К примеру, у нас есть такая строчка:
cron job command > /dev/null 2>&1
Перенаправление вывода
Оператор > («больше чем»), как в примере выше, переадресовывает вывод программы. В данном случае, что-то отправляется в /dev/null, а что-то переадресовывается в &1.
Стандартные ввод, вывод и ошибка
Существует три стандартных значения ввода и вывода для программ. Ввод получают от клавиатуры (интерактивная, диалоговая программа), или из программы, обрабатывающей вывод другой программы.
Результат программы обычно печатается в стандартной вывод и иногда в файл «STDERR» (ошибка). Все это три дескриптора файла (вы можете представить их как «потоки данных», пришли из языка программирования C), которые часто называют STDIN, STDOUT и STDERR.
Но часто к ним обращаются не по имени, а по номеру:
0 — STDIN, 1 — STDOUT и 2 — STDERR
По умолчанию, если вы не укажете номер, то будет подразумеваться STDOUT.
В нашем примере видно, что команда направляет свой стандартный вывод в /dev/null (псевдоустройство, которое может принять произвольный объём данных, не сохраняя их совершенно нигде, следовательно, подавив стандартный вывод). Затем все ошибки (то есть STDERR) перенаправить в стандартный вывод. Необходимо поставить амперсанд «&» перед номером назначения.
Смысл вкратце — «весь вывод указанной команды спихнуть в черную дыру!«.
Это один из способов сделать программу по-настоящему безмолвной. Добавлю, что команда в примере аналогична команде cron job command >/dev/null 2>/dev/null
Официальный FAQ FreeBSD предупреждает: отправка данных в /dev/null/ перегревает ваш процессор 🙂
Источник
What is /dev/null and How to Use It
One such example is /dev/null. It’s a special file that’s present in every single Linux system. However, unlike most other virtual files, instead of reading, it’s used to write. Whatever you write to /dev/null will be discarded, forgotten into the void. It’s known as the null device in a UNIX system.
Why would you want to discard something into the void? Let’s check out what /dev/null is and its usage.
Prerequisites
Before diving deep into the usage of /dev/null, we have to have a clear grasp of the stdout and stderr data stream. Check out this in-depth guide on stdin, stderr, and stdout.
Let’s have a quick refresh. Whenever any command-line utility is run, it generates two outputs. The output goes to stdout and the error (if generated) goes to stderr. By default, both these data streams are associated with the terminal.
For example, the following command will print out the string within the double quotation mark. Here, the output is stored in stdout.

The next command will show us the exit status of the previously-run command.

As the previous command ran successfully, the exit status is 0. Otherwise, the exit status will be different. What happens when you try to run an invalid command?

Now, we need to know about the file descriptor. In the UNIX ecosystem, these are integer values assigned to a file. Both stdout (file descriptor = 1) and stderr (file descriptor = 2) have a specific file descriptor. Using the file descriptor (1 and 2 in this situation), we can redirect the stdout and stderr to other files.
For starter, the following example will redirect the stdout of the echo command to a text file. Here, we didn’t specify the file descriptor. If not specified, bash will use stdout by default.

The following command will redirect the stderr to a text file.

Using /dev/null
Redirecting output to /dev/null
Now, we’re ready to learn how to use /dev/null. First, let’s check out how to filter normal output and error. In the following command, grep will try to search for a string (hello, in this case) in the “/sys” directory.
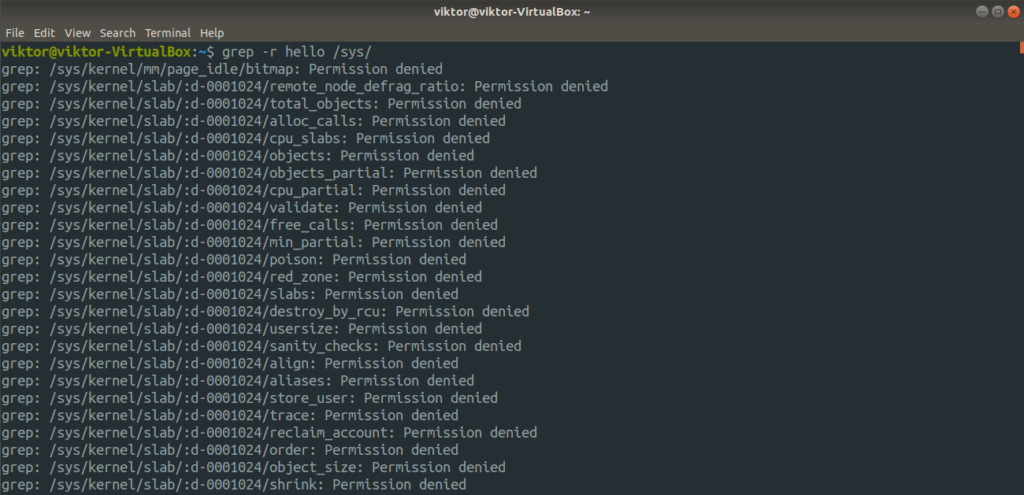
However, it will generate a lot of error as without root privilege, grep can’t access a number of files. In such a case, it’ll result in “Permission denied” errors. Now, using the redirection, we can get a clearer output.

The output looks much better, right? Nothing! In this case, grep doesn’t have access to a lot of files and those that are accessible doesn’t have the string “hello”.
In the following example, we’ll be pinging Google.
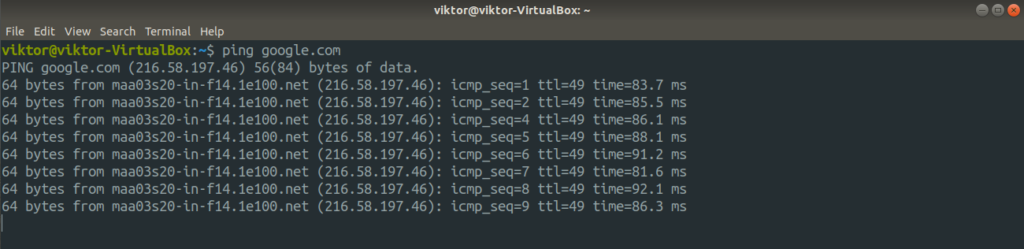
However, we don’t want to see all those successful ping results. Instead, we only want to focus on the errors when ping couldn’t reach Google. How do we do that?

Here, the contents of stdout are dumped to /dev/null, leaving only the errors.
Redirect all output to /dev/null
In certain situations, the output may not be useful at all. Using redirection, we can dump all the output into the void.

Let’s break this command a little bit. First, we’re dumping all the stdout to /dev/null. Then, in the second part, we’re telling bash to send stderr to stdout. In this example, there’s nothing to output. However, if you’re confused, you can always check if the command ran successfully.

The value is 2 because the command generated a lot of errors.
If you tend to forget the file descriptor of stdout and stderr, the following command will do just fine. It’s a more generalized format of the previous command. Both stdout and stderr will be redirected to /dev/null.

Other examples
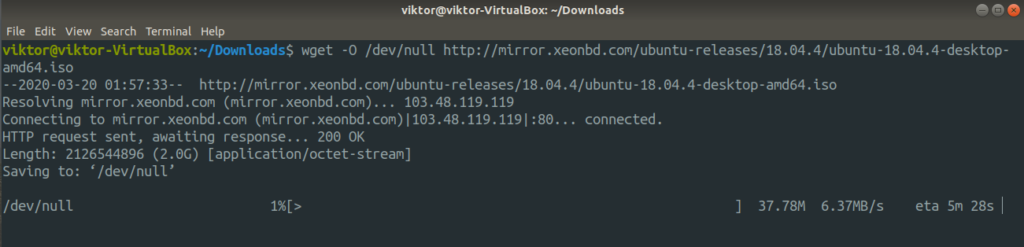
This is an interesting one. Remember the dd tool? It’s a powerful tool for converting and copying files. Learn more about dd. Using dd, we can test the sequential read speed of your disk. Of course, it’s not an accurate measurement. However, for a quick test, it’s pretty useful.

Here, I’ve used the Ubuntu 18.04.4 ISO as the big file.
Similarly, you can also test out the download speed of your internet connection.
Final thoughts
Hopefully, you have a clear understanding of what this /dev/null file is. It’s a special device that, if written to it, discards and if read from, reads null. The true potential of this interesting feature is in interesting bash scripts.
Are you interested in bash scripting? Check out the beginner’s guide to bash scripting.
About the author

Sidratul Muntaha
Student of CSE. I love Linux and playing with tech and gadgets. I use both Ubuntu and Linux Mint.
Источник
Linux что такое dev null
В Linux существуют две директории — /dev и /proc, которые не имеют Windows-аналогов, и их назначение начинающим пользователям обычно непонятно. Но именно они являются мощными инструментами для понимания и более эффективного использования Linux.
Эта статья — обзор файловых систем Device (/dev) и Process (/proc). Здесь обьясняется, что это такое, как они работают, и как они используются на практике.
/dev: Файловая система устройств.
Устройства: В Linux устройство — это любая вещь (или программа, эмулирующая эту вещь), которая предоставляет методы для осуществления ввода/вывода. Например, клавиатура — это устройство ввода. В Linux большинство устройств представлены, как файлы в этой файловой системе (сетевые карты — исключение). Эти специальные файлы хранятся в /dev, и легко доступны для всех процессов, работающих с устройствами.
Обычно устройства разделяются на 2 категории — символьные устройства и блокирующие устройства. Символьные устройства производят операции ввода-вывода на базе символов. Самый очевидный пример — это клавиатура, где каждое нажатие кнопки посылает один символ.
Блокирующие устройства читают данные большими обьемами. Обычно это — устройства хранения данных, такие, как жесткие диски IDE (/dev/hd), SCSI (/dev/sd) и CD-ROMы (/dev/cdrom). В операциях ввода-вывода учавствуют большие массивы данных, что обеспечивает более эффективную работу.
Наименования устройств: Устройства часто называются сокращенными названиями вещей, которые они представляют. Например, /dev/fb представляет Frame Buffer для графики, а /dev/hd — жесткие диски IDE. Иногда более удобны бывают символьные ссылки, например — /dev/mouse может ссылаться на USB, PS2, и т.д.
Иногда может быть несколько одинаковых устройств. Если на компьютере 2 CD-ROMа, то первый будет называться /dev/cdrom0, а второй — /dev/cdrom1.
В случае с жесткими дисками наименование становится сложнее. Имя устройства состоит из типа, позиции и номера раздела. Например, первый жесткий диск может быть назван /dev/hda, где «hd» обозначает «диск IDE», а «a» — что это первый HDD. /dev/hdb будет указыать на второй жесткий диск. Первый раздел на первом диске будет называться /dev/hda1, где число 1 — номер раздела. Заметьте, что у некоторых устройств нумерация может начинаться и с нуля (/dev/cdrom0). Список всех разделов может выглядеть примерно так:
/dev/hda
/dev/hda1
/dev/hda2
/dev/hda3
/dev/hda4
/dev/hdb
/dev/hdb1
/dev/hdb2
/dev/hdb3
Жесткие диски SCSI используют /dev/sd вместо /dev/hd, но их правила наименования ничем не отличаются.
Специальные устройства: Существует несколько специальных устройств, которые иногда могут быть полезны — /dev/null, /dev/zero, / dev/full, and /dev/random.
Устройство /dev/null физически не существует, но данные, помещенные туда, просто исчезают и их уже невозможно вернуть обратно. Во многих случаях программы выводят много лишней информации. В shell-скриптах /dev/null часто используется, чтобы не беспокоить пользователя различными ненужными вещами. В примере, приведенном ниже, в ядро помещается модуль и вывод перенаправляется в /dev/null.
$ modprobe cipher-twofish > /dev/null
/dev/zero выполняет почти те же функции, что и /dev/null. Это устройство так же используется, чтобы убрать ненужные данные, но чтение из /dev/zero постоянно дает символы \0. (Чтение из /dev/null дает символы End of file). Поэтому /dev/zero часто используется для создания пустых файлов:
dd if=/dev/zero of=/my-file bs=1k count=100
Эта команда создает файл размером 100 Kb, состоящий только из нулевых символов.
/dev/full изображает полное устройство. Запись в /dev/full возвращает ошибку. Это устройство полезно при тестировании, как программа поведет себя при доступе к устройству, не имеющему свободного места.
$ cp test-file /dev/full
cp: writing /dev/full»: No space left on device
$ df -k /dev/full
file system 1k-blocks Used Available Use% Mounted on
/dev/full 0 0 0 —
Устройства /dev/random и /dev/urandom генерируют «случайную» информацию. Хотя вывод из обоих этих устройств может показаться совершенно случайным, но /dev/random на самом деле более случайно, чем /dev/urandom. /dev/random генерирует случайные символы на основе «шума окружающей среды», который имеет ограниченное количество, поэтому /dev/random работает медленно, и может иногда останавливаться и ждать поступления новых данных. /dev/urandom использует те же данные, что и /dev/random, но если случайные данные заканчиваются, начинается генерация псевдослучайных чисел. Это делает /dev/urandom более быстрым, но менее безопасным.
Старая файловая система /dev: В прошлом /dev была частью нормальной файловой системы и состояла из специальных файлов, созданных при установке системы и хранящихся на жестком диске.
Обычно /dev занимала очень много места, чтобы поддерживать множество жестких дисков, консолей, и т.д. Например, в старой файловой системе размещались сразу же 11 записей для жестких дисков — с /dev/hdb1 по /dev/hdb11. И чтобы выяснить, какой из этих файлов действительно соответствует устройству, нужна была команда:
$ file -s /dev/hdb?
/dev/hdb1: Linux/i386 ext2 file system
/dev/hdb2: Linux/i386 ext2 file system
/dev/hdb3: Linux/i386 ext2 file system
/dev/hdb4: empty
/dev/hdb5: empty
/dev/hdb6: empty
/dev/hdb7: empty
/dev/hdb8: empty
/dev/hdb9: empty
Если файл для устройства не присутствовал, есго нужно было создавать специальной программой mknod или MAKEDEV. Хотя старая модель работала, но она была сложной и неудобной.
DevFS: В ядрах версии 2.4 появилась альтернатива под названием DevFS. Принцип — файловая система /dev создается ядром при каждой загрузке и хранится в оперативной памяти. Если добавляются новые устройства, ядро просто добавляет запись, соответствующую им, в /dev. Если устройство требует специальной конфигурации для корректной работы с DevFS, то существует конфигурационный файл (обычно /etc/devfsd.conf).
/proc: Файловая система для процессов.
Процессы: В любое время Linux имеет много процессов, запущенных одновременно. Некоторые процессы доступны пользователю, а некоторые находятся на заднем плане и обрабатывают задачи, которые не требуют взаимодействия с пользователем. Запуск «ps -ef» в консоли выведет список всех процессов. Это выглядит примерно так:
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 11:08 ? 00:00:04 init
root 2 1 0 11:08 ? 00:00:00 [keventd]
root 3 0 0 11:08 ? 00:00:00 [ksoftirqd_CPU0]
root 4 0 0 11:08 ? 00:00:00 [kswapd]
root 5 0 0 11:08 ? 00:00:00 [bdflush]
root 6 0 0 11:08 ? 00:00:00 [kupdated]
root 8 1 0 11:08 ? 00:00:00 [kjournald]
root 86 1 0 11:08 ? 00:00:00 /sbin/devfsd /dev
root 165 1 0 11:09 ? 00:00:00 [kjournald]
root 168 1 0 11:09 ? 00:00:00 [khubd]
root 294 1 0 11:09 ? 00:00:00 [kapmd]
root 515 1 0 11:09 ? 00:00:00 metalog [MASTER]
root 521 515 0 11:09 ? 00:00:00 metalog [KERNEL]
root 531 1 0 11:09 ? 00:00:00 /sbin/dhcpcd eth0
/etc/X11/fs/config -droppriv -user xfs
root 572 1 0 11:09 ? 00:00:00 /usr/kde/2/bin/kdm
root 593 572 2 11:09 ? 00:04:27 /usr/X11R6/bin/X -auth /var/lib/kdm/authfiles/A:0-25pIgI
root 644 1 0 11:09 vc/1 00:00:00 /sbin/agetty 38400 tty1 linux
root 1045 572 0 12:16 ? 00:00:00 -:0
mbutcher 1062 1045 0 12:16 ? 00:00:00 /bin/sh /etc/X11/Sessions/kde-2.2.2
mbutcher 1091 1062 0 12:16 ? 00:00:00 /bin/bash —login /usr/kde/2/bin/startkde
mbutcher 1132 1 0 12:16 ? 00:00:00 kdeinit: Running.
mbutcher 1157 1132 0 12:16 ? 00:00:01 kdeinit: kwin
mbutcher 1159 1 0 12:16 ? 00:00:07 kdeinit: kdesktop
mbutcher 1168 1 0 12:16 ? 00:00:00 kdeinit: kwrited
mbutcher 1171 1168 0 12:16 pty/s0 00:00:00 /bin/cat
mbutcher 1173 1 0 12:16 ? 00:00:00 alarmd
mbutcher 1207 1132 0 12:23 ? 00:00:08 kdeinit: konsole -icon konsole -miniicon konsole
mbutcher 1219 1207 0 12:23 pty/s2 00:00:00 /bin/bash
mbutcher 1309 1260 0 13:48 pty/s3 00:00:01 vi dev-and-proc.html
root 1314 1220 0 14:03 pty/s2 00:00:00 ps -ef
Многие из задач в списке, выведенном ps — это процессы, выполняемые на заднем плане. Процессы, заключенные в квадратные скобки — это процессы на уровне ядра. И только несколько задач, таких, как процессы KDE и записи в нижней части списка, взаимодействуют с пользователем.
Чтобы управлять системой, ядро должно следить за каждым запущенным процессом, включая себя. Так же информация о запущенных процессах должна быть доступна и для многих пользовательских приложений, таких, как «ps» и «top». В файловой системе /proc ядро хранит информацию о процессах.
Как DevFS, /proc хранится в памяти, а не на диске. Если посмотреть на файл /proc/mounts (который перечисляет все смонтированные файловые системы), то вы увидите строку:
proc /proc proc rw 0 0
/proc контролируется ядром и не имеет соответствующего устройства.
Информация о запущенных процессах: Чтобы следить за процессами, ядро назначает каждому из них номер PID (Process ID). Запуск команды «ps -ef», как мы уже делали ранее, напечатает список процессов, отсортированный по номеру PID (вторая колонка). В /proc хранится информация о каждом PID.
Многие директории в /proc — это числа, соответствующие номерам PID. Внутри директорий есть файлы, предоставляющие важные детали о процессе. Например, в выводе ps (выше) была строка:
mbutcher 1219 1207 0 12:23 pty/s2 00:00:00 /bin/bash
Этот процесс запускает bash, и имеет PID 1219. Директория /proc/1219 содержит информацию об этом процессе.
$ ls /proc/1219
cmdline cpu cwd environ exe fd maps mem root stat statm status
Файл «cmdline» содержит команду, данную для запуска этого процесса. Файл «environ» содержит переменные для процесса. «status» имеет статусную информацию, включая номер пользователя (UID) и номер группы (GID) пользователя, запустившего процесс, номер родительского процесса PPID (parent process ID), который запустил PID, и текущее состояние процесса, такое, как «Sleeping» или «Running».
$ cat status
Name: bash
State: S (sleeping)
Tgid: 1219
Pid: 1219
PPid: 1207
TracerPid: 0
Uid: 501 501 501 501
Gid: 501 501 501 501
FDSize: 256
Groups: 501 10 18
VmSize: 2400 kB
VmLck: 0 kB
VmRSS: 1272 kB
VmData: 124 kB
VmStk: 20 kB
VmExe: 544 kB
VmLib: 1604 kB
SigPnd: 0000000000000000
SigBlk: 0000000080010000
SigIgn: 8000000000384004
SigCgt: 000000004b813efb
CapInh: 0000000000000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
Каждая директория процесса также содержит несколько символических ссылок. «cwd» — ссылка на текущую рабочую директорию для этого процесса, «exe» — ссылка на саму программу, и «root» ссылается на директорию, которую программа считает корневой (обычно «/»). Директория «fd» содержит список символических ссылок на описания файлов, используемых процессом.
Так же в директории есть и другие файлы, предоставляющие информацию обо всем, начиная от использования процессора и памяти до количества времени, в течении которого этот процесс работал. Они описаны в исходниках ядра под «Documentation/file systems/proc.txt» и в man-странице «man proc».
Информация ядра: Кроме информации о процессах, /proc содержит много информации, генерируемой ядром для описания состояния системы.
Ядро и его модули могут генерировать файлы в /proc для предоставления информации об их состоянии. Например, /proc/fb предоставляет информацию о доступных устройствах frame buffer (чаще всего используются для демонстрации логотипа при загрузке).
$ cat fb
0 VESA VGA
Число 0 — это индекс устройства, соответствующего /dev/fb0. Если бы имелся второй frame buffer, то имелась бы еще одна запись, соответствующая /dev/fb1. Вообще, данные в /proc часто ссылаются на устройства в /dev или дают о них больше информации.
Много информации об устройствах хранится в /proc. Файл /proc/pci содержит информацию о почти каждом PCI-устройстве, обнаруженном в системе. Запуск команды «lspci» выводит похожий список, потому что в качестве источника информации используется именно /proc/pci. /proc/bus содержит директории для различных шинных архитектур (PCI, PCCard, USB), которые в свою очередь содержат информацию об устройствах, подключенных к этим шинам. Сетевая информация и статистика хранится в /proc/net. Информация о жестких дисках хранится в /proc/ide и /proc/scsi, в зависимости от типа жесткого диска. /proc/devices перечисляет все устройства, разделенные на категории «block» и «characters».
$ cat /proc/devices
Character devices:
1 mem
2 pty/m%d
3 pty/s%d
4 tts/%d
5 cua/%d
7 vcs
10 misc
14 sound
29 fb
116 alsa
162 raw
180 usb
226 drm
254 pcmcia
Block devices:
1 ramdisk
2 fd
3 ide0
22 ide1
А вообще — в /proc имеется намного больше файлов, чем описано здесь. Для каждого ядра формат /proc может быть разным, в зависимости от конфигурации и версии ядра, установленных устройств, и состояния компьютера. Формат информации может быть разным, но большинство из этих файлов документированы в Documentation/file systems/proc.txt.
Взаимодействие с процессами через /proc: Некоторые файлы из /proc предназначены не только для чтения. Запись в них может изменять параметры ядра. Чтение файлов из каталога /proc обычно безопасно, но записывать информацию в эти файлы, не зная их формата, опасно. Но все равно, иногда запись в /proc — это единственный способ взаимодействия с ядром.
Например, в последние версии ядра можно встроить высокопроизводительный Web-сервер, работающий на уровне ядра системы (khttp). Запуск Web-сервера по умолчанию может быть небезопасен, и поэтому khttp можно запустить через сообщение, посылаемое в /proc.
echo 1 > /proc/sys/net/khttpd/start
Когда ядро видит изменение содержимого /proc/sys/net/khttpd/start с нуля (значение по умолчанию) на единицу, оно запускает khttpd сервер.Так же в /proc имеется еще несколько десятков конфигурируемых параметров — некоторые для настройки оборудования, другие — для управления ядром. Почти все из них выполняются на низком уровне, и их неправильное использование может быть небезопасно для системы.
Заключение: /proc и /dev предоставляют в виде файлов интерфейсы для взаимодействия с Linux. Они помогают в определении конфигурации и состояния различных устройств и процессов системы. Так же они обеспечивают простое взаимодействие с операционной системой. Понимание и применение этих двух файловых систем — ключ к эффективной работе в Linux.
Источник



