- Linux cmp сравнение файлов
- 7 примеров использования команды cmp в Linux
- Утилита cmp
- 1. Сравнение содержимого двух файлов
- 2. Вывод отличающихся значений байтов
- 3. Пропуск начальных байтов двух файлов
- 4. Вывод информации о позициях (и значениях) всех отличающихся байтов
- 5. Ограничение количества байтов для сравнения
- 6. Вывод индикатора хода процесса сравнения
- 7. Сокрытие вывода
- Заключение
- Команда cmp в Linux с примерами
- LinuxShare
- Навигация
- Вход для пользователей
- Кто на сайте
- Сравнение и объединение файлов diff, diff3, sdiff, cmp, patch : Что значит сравнение?
Linux cmp сравнение файлов
Существует несколько утилит для сравнения содержимого файлов различными способами. Эти инструменты особенно полезны для сравнения текста в файлах.
Используйте cmp, чтобы определить, различаются ли два текстовых файла. В качестве аргумента укажите два имени файла, и, если файлы содержат одинаковые данные, cmp не вернет результата. Если же файлы различаются, cmp выводит позицию и номер строки в файлах, в которых обнаружены различия.
Чтобы определить, в чем различаются файлы `master’ и `backup’, наберите:
$ cmp master backup [Enter]
Чтобы сравнить два файла и получить отчет о различиях в них, используйте утилиту diff. Отчет о различиях форматируется таким образом, чтобы другие утилиты (например, patch) могли использовать его, чтобы сделать сравниваемые файлы идентичными. В качестве аргументов для diff нужно указать имена сравниваемых файлов.
Чтобы сравнить файлы `manuscript.old’ и `manuscript.new’, введите:
$ diff manuscript.old manuscript.new [Enter]
Отчет о различиях выводится в файл стандартного вывода; чтобы сохранить его в файл на диске, перенаправьте вывод в файл:
$ diff manuscript.old manuscript.new > manuscript.diff [Enter]
В этом случае отчет будет сохранен в файле `manuscript.diff’.
Чтобы нагляднее увидеть различия в двух файлах, используйте команду sdiff; вместо генерации отчета о различиях, она выводит файлы в две колонки, разделяемые пробелами. Различающиеся строки разделяются `|’; строки, встречающиеся только в первом файле, заканчиваются ` ‘.
Чтобы сравнить файлы `laurel’ и `hardy’ на экране, введите:
$ sdiff laurel hardy less [Enter]|
Для одновременного сравнения трех файлов используйте diff3.
Чтобы вывести отчет о различиях между файлами `larry’, `curly’, и `moe’ в файл `stooges’, введите:
Источник
7 примеров использования команды cmp в Linux
Оригинал: Linux cmp command tutorial for beginners (7 examples)
Автор: Himanshu Arora
Дата публикации: 19 мая 2017 г.
Перевод: А.Панин
Дата перевода: 23 мая 2017 г.
Вне зависимости от ваших служебных обязанностей, при условии работы с интерфейсом командной строки Linux, вы рано или поздно столкнетесь с необходимостью сравнения содержимого двух файлов с помощью утилиты с интерфейсом командной строки. Для этой цели предназначено сразу несколько утилит, причем одной из них является утилита cmp .
В рамках данной статьи мы будем рассматривать методику использования утилиты cmp на основе простых для понимания примеров. Но перед тем как перейти к рассмотрению этих примеров, следует упомянуть о том, что все они протестированы в системе Ubuntu 16.04 LTS.
Утилита cmp
Утилита cmp позволяет осуществить побайтовое сравнение содержимого двух файлов. Она поддерживает ряд дополнительных функций, доступных посредством соответствующих параметров командной строки. В данной статье мы обсудим некоторые ключевые параметры командной строки, которые позволят вам (то есть, начинающему пользователю) лучше понять принцип работы рассматриваемой утилиты.
1. Сравнение содержимого двух файлов
Простейшая методика использования утилиты cmp заключается в исполнении следующей команды:
Как уже говорилось, утилита осуществляет побайтовое сравнение содержимого двух указанных файлов. При обнаружении отличия она останавливает процесс сравнения и выводит информацию о номере отличающейся строки и номере отличающегося байта.

Из приведенной выше иллюстрации очевидно, что отличие содержимого двух указанных файлов находится в 20 байте в первой строке.
2. Вывод отличающихся значений байтов
Если вам нужно, вы можете сообщить утилите cmp о необходимости вывода отличающихся значений байтов. Для этого может использоваться параметр командной строки -b .

В данном случае из приведенной выше иллюстрации очевидно, что отличается байт номер 17 двух файлов: в файле file1.txt он соответствует символу «I», а в файле file2.txt — символу «i». То есть, байты имеют значения 154 и 151 соответственно.
3. Пропуск начальных байтов двух файлов
При необходимости вы также можете сообщить утилите cmp о необходимости пропуска определенного количества начальных байтов двух файлов с последующим сравнением содержимого этих файлов. Для этого нужно указать количество байтов после аргумента командной строки -i .
Обратите внимание на то, что в аналогичных случаях (при использовании аргумента -i) байт, с которого начинается сравнение, считается нулевым.
Кроме того, утилита также позволяет вам пропускать различное количество байтов в обоих файлах. Это делается следующим образом:

4. Вывод информации о позициях (и значениях) всех отличающихся байтов
Если вам понадобится, вы можете сообщить утилите cmp о необходимости вывода информации о позициях и значениях всех отличающихся байтов. Эта функция доступна посредством параметра командной строки -l :
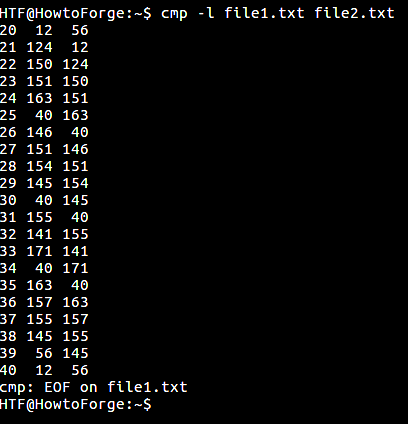
В первом столбце (на иллюстрации выше) выводится позиция (номер) отличающегося байта. Во втором столбце выводится значение байта в этой позиции из первого файла, а в третьем — значение байта в этой позиции из второго файла.
5. Ограничение количества байтов для сравнения
Рассматриваемая утилита также позволяет вам ограничить количество байтов, которые следует сравнивать; к примеру, вам может понадобиться сравнить как минимум 25 или 50 байтов файлов. Для этого предназначен параметр командной строки -n :
6. Вывод индикатора хода процесса сравнения
При сравнении содержимого файлов большого объема (или образов разделов дисковых накопителей) с помощью утилиты cmp вам наверняка захочется отслеживать ход процесса. Для этой цели может использоваться дополнительная утилита pv , вызываемая перед cmp. Это формат команды, которая может использоваться:
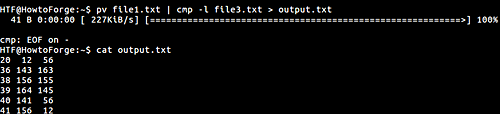
Обратите внимание на то, что файл с именем output.txt будет содержать весь вывод утилиты cmp. Индикатор хода процесса сравнения (приведенный на иллюстрации выше) выводится силами утилиты pv.
Утилита pv не устанавливается по умолчанию в Linux (по крайней мере, в дистрибутиве Ubuntu). При этом вы можете без каких-либо проблем установить ее самостоятельно с помощью следующей команды:
7. Сокрытие вывода
Рассматриваемая утилита позволяет скрыть вывод, который генерируется по умолчанию. Это делается с помощью параметра командной строки -s .
Данный параметр может быть полезен в случае использования утилиты cmp в рамках сценариев. Например, в зависимости от того, идентичны файлы или нет (что можно определить по коду завершения работы утилиты), вы можете выводить специальное сообщение вместо того вывода, который генерируется утилитой по умолчанию.
Заключение
В данной статье мы обсудили большую часть параметров командной строки утилиты cmp, поэтому вам нужно лишь попрактиковаться в их использовании в процессе ежедневной работы. При возникновении любых сомнений или вопросов обращайтесь к странице руководства cmp .
Источник
Команда cmp в Linux с примерами
Команда cmp в Linux / UNIX используется для сравнения двух файлов побайтно и помогает вам определить, идентичны ли эти два файла или нет.
- Когда cmp используется для сравнения между двумя файлами, он сообщает о местоположении первого несоответствия на экране, если обнаружена разница и если различий не найдено, сравниваемые файлы идентичны.
- cmp не выводит сообщения и просто возвращает приглашение, если сравниваемые файлы идентичны.
Синтаксис команды cmp довольно прост для понимания. Если мы сравниваем два файла, то, очевидно, нам понадобятся их имена в качестве аргументов (). В дополнение к этому, необязательные SKIP1 и SKIP2 задают количество пропускаемых байтов в начале каждого файла, которое по умолчанию равно нулю, а OPTION относится к параметрам, совместимым с этой командой, о которых мы поговорим позже.
Пример cmp: Как объяснено, команда cmp сообщает байт и номер строки, если обнаружена разница. Теперь давайте узнаем то же самое с помощью примера. Предположим, есть два файла, которые вы хотите сравнить, один файл file1.txt, а другой файл file2.txt:
- Если файлы не идентичны: вывод вышеуказанной команды будет:
- Если файлы идентичны: вы увидите что-то вроде этого на вашем экране:
Опции для команды cmp
1. -b (print-bytes): если вы хотите, чтобы cmp отображал различные байты в выводе при использовании с опцией -b .
Значения 154 и 151 в вышеприведенных выходных данных являются значениями для этих байтов соответственно.
2. -i [bytes-to-skipped]: теперь эта опция при использовании с командой cmp помогает пропускать определенное количество начальных байтов из обоих файлов, а затем после пропуска сравнивает файлы. Это можно сделать, указав число байтов в качестве аргумента опции командной строки -i.
Обратите внимание, что в подобных случаях (где вы используете -i для пропуска байтов), байт, с которого начинается сравнение, обрабатывается как нулевой байт.
3. -i [байты, которые нужно пропустить из первого файла]: [байты, которые нужно пропустить из второго файла]: эта опция очень похожа на описанную выше опцию -i [байты, которые нужно пропустить], но с той разницей, что теперь она позволяет нам нужно ввести количество байтов, которые мы хотим пропустить из обоих файлов по отдельности.
4. -l опция: эта опция заставляет команду cmp печатать позицию байта и значение байта для всех отличающихся байтов.
Первый столбец в выводе представляет позицию (номер байта) различных байтов. Второй столбец представляет значение байта отличающегося байта в первом файле, в то время как третий столбец представляет значение байта отличающегося байта во втором файле.
5. -s опция: это позволяет вам подавить вывод, обычно производимый командой cmp, он сравнивает два файла без записи каких-либо сообщений. Это дает значение выхода 0, если файлы идентичны, значение 1, если они разные, или значение 2, если появляется сообщение об ошибке.
6. -n [количество байтов для сравнения]: эта опция позволяет вам ограничить количество байтов, которые вы хотите сравнить, например, если нужно сравнивать не более 25 или 50 байтов.
8. — -v опция: это дает информацию о выходе и выходах.
9. — -help option: отображает справочное сообщение и завершает работу.
Источник
LinuxShare
Навигация
Вход для пользователей
Кто на сайте
Сравнение и объединение файлов diff, diff3, sdiff, cmp, patch : Что значит сравнение?
Существует несколько представлений о том, как рассматривать различия между двумя файлами. Одно представление, что различия — серии строк, которые были удалены, вставлены или изменены в одном файле для получения другого. ‘diff’ сравнивает два файла строка за строкой, находя отличающиеся группы строк, и сообщает о каждой такой группе. Он может сообщать об отличающихся строках в нескольких форматах, которые имеют различные назначения.
GNU ‘diff’ может показать, различаются ли файлы, не уточняя различий. Он также обеспечивает возможности не отображать отдельные виды различий, которые не важны для Вас. В большинстве случаев такие различия — это изменения в количестве «пропусков» между словами или строками. ‘diff’ также позволяет не отображать различия прописных букв от строчных или различия в строках, которые соответствуют некоторому заданому регулярному выражению. Эти опции могут сочетаться; например, можно игнорировать изменения и в «пропусках», и в замене регистра букв.
Другой способ представлять различия между двумя файлами, рассматривая последовательность пар символов, в которых символы могут совпадать или различаться. ‘cmp’ сообщает о различиях между двумя файлами символ за символом, а не строка за строкой. Следовательно, он более чем ‘diff’ подходит для сравнения двоичных файлов. Для текстовых файлов, ‘cmp’ применяется, главным образом, когда необходимо выяснить являются ли два файла одинаковыми.
Для иллюстрации преимущества построчного сравнения перед посимвольным сравнением, представьте что случиться, если в начало файла добавить единственный символ новой строки. Если сравнить теперь этот файл с первоначальным, в котором нет этой новой строки в начале, ‘diff’ сообщит, что к файлу добавили пустую строку, в то время как ‘cmp’ сообщит, что почти все символы в файлах различаются.
‘diff3’ обычно сравнивает три входных файла строку за строкой, находя группы различающихся строк и сообщает о каждой такой группе. Его результаты работы оформлены так, чтобы легко было отследить два разных набора изменений для одного и того же файла.
Сравнивая два файла, ‘diff’ находит последовательности строк общих для обоих файлов, разделенных группами разных строк, которые называются ханками. Сравнение двух одинаковых файлов дает одну последовательность общих строк и не дает ханков, так как отличающихся строк нет. Сравнение двух совершенно разных файлов не дает общих строк, а дает один большой ханк, состоящий из всех строк обоих файлов. Вообще говоря, существует много способов искать общие строки для двух данных файлов. ‘diff’ пытается минимизировать общий размер ханка, ища большие последовательности общих строк разделенных маленькими ханками отличающихся строк.
Например, предположим файл ‘F’ состоит из трех строк ‘a’, ‘b’,’ c’, а файл ‘G’ состоит из тех же трех строк в обратном порядке ‘c’, ‘b’, ‘a’. Если ‘diff’ посчитает общей строку ‘c’, команда ‘diff F G’ выдаст следующий результат:
Также возможно считать общей строку ‘a’. ‘diff’ не всегда находит оптимальное соответствие между файлами; это позволяет ему работать быстрее. Но его результаты обычно близки к максимально коротким. Вы можете избежать этой издержки с помощью опции ‘—minimal’
Опции ‘-b’ и ‘-ignore-space-change’ игнорируют «пропуски» на концах строк, и считают все другие последовательности из одного или более «пропусков» одинаковыми. С этими опциями, ‘diff’ считает следующие две строки одинаковыми ($ обозначает конец строки):
Опции ‘-B’ и ‘—ignore-blank-lines’ игнорируют вставки или удаления чистых строк. Эти опции предусмотрены только для обработки строк, которые полностью пусты; они не касаются строк которые выглядят как пустые, но содержат пробел или символы табуляции. С этими опциями, например, файл содержащий:
GNU ‘diff’ может рассматривать прописные буквы как одинаковые с соответствующими им строчными, так, что, например, будет считать `Funky Stuff’, `funky STUFF’, и `fUNKy stuFf’ одинаковыми строками. Чтобы добиться этого, используйте опцию ‘-i’ или ‘—ignore-case’.
Для игнорирования вставок и удалений строк, соответствующих регулярному выражению используется опция ‘-l REGEXP’ или ‘—ignore-matching-lines=REGEXP’. Следует избегать регулярных выражений содержащих метасимволы оболочки, чтобы избежать их неправильного толкования оболочкой. Например
Тем не менее, ‘-I’ игнорирует удаление или вставку строк, которые содержат регулярное выражение, только если каждая изменяемая строка в ханках — каждая вставка и удаление — соответствует регулярному выражению. Другими словами, для каждого неигнорируемого изменения, ‘diff’ печатает полный набор изменений в его окружении, включая игнорируемые.
Можно определить более одного выражения для игнорирования строк, используя более одной опции ‘-I’. ‘diff’ пытается учитывать во всех строках все выражения, начиная с последнего заданного.
Когда необходимо выяснить только отличаются ли файлы, и не важно чем именно, можно использовать обобщенный формат вывода. В этом формате, не показывая различия между файлами, ‘diff’ просто сообщает отличаются ли они. Этот формат задается опциями ‘-q’ и ‘—brief’.
Особенно полезен обобщенный формат для сравнения содержания двух директорий. Он также гораздо быстрее, чем обычное сравнивание строка за строкой, так как ‘diff’ может остановить анализ файлов как только обнаружит, что они отличаются.
Чтобы быстро показать отличаются ли файлы друг от друга, можно также использовать ‘cmp’. Для одинаковых файлов, ‘cmp’ не производит никакого вывода. Для разных файлов ‘cmp’, по умолчанию выводит смещение и номер строки там, где было обнаружено первое различие. Используя опцию ‘-s’, можно игнорировать эту информацию, так что ‘cmp’ не будет создавать выходного файла и сообщит лишь отличаются ли они используя выходной статус (см. «Запуск cmp»).
В отличие от ‘diff’, ‘cmp’ не может сравнивать каталоги; он сравнивает только файлы.
Если ‘diff’ считает, что оба файла, которые он сравнивает двоичные (нетекстовые), он обычно рассматривает эту пару файлов так, как если бы был выбран обобщенный формат вывода, и сообщает только, отличаются ли эти файлы. Так делается потому, что сравнение строка за строкой обычно бессмысленно для двоичных файлов.
‘diff’ определяет является ли файл текстовым или двоичным проверяя в нем первые несколько байтов; точное число проверяемых байтов зависит от системы, но обычно это несколько тысяч. Если каждый символ в этой части файла ненулевой, ‘diff’ считает файл текстовым; иначе файл считается двоичным.
Иногда может быть необходимо заставить ‘diff’ рассматривать файлы как текстовые. Например, сравниваются текстовые файлы, содержащие нулевые символы; ‘diff’ ошибочно решит, что эти файлы нетекстовые. Или сравниваются документы в формате, используемом текстовым редактором, который содержит нулевые символы для описания особого форматирования. Можно заставить ‘diff’ рассматривать все файлы как текстовые, и сравнивать их строка за строкой, с помощью опции ‘-a’ или ‘—text’. Если файлы, сравниваемые при помощи этой опции, на самом деле не содержат текст, они возможно содержат несколько символов новой строки, и результаты работы ‘diff’ будут содержать ханки показывающие различия между длинными строками тех символов, какие бы они ни были, из которых состоят файлы.
Можно также заставить ‘diff’ рассматривать все файлы как двоичные, сообщая только отличаются ли они (но не сообщая чем). Для этого используется опция ‘—brief’.
В операционных системах, различающих текстовые и двоичные файлы, ‘diff’ обычно считывает и записывает все данные как текст. Использование опции ‘—binary’ заставляет ‘diff’ считывать и записывать вместо этого двоичные данные. Эта опция не действует на Posix-совместимых системах таких как GNU или традиционный Unix. Тем не менее, многие операционные системы на персональных компьютерах отображают конец строки возвратом каретки и следующим за ним символом новой строки. На таких системах, ‘diff’ обычно игнорирует эти возвраты каретки при вводе и генерирует их в конце каждой обработанной строки, но с опцией ‘—binary’ ‘diff’ воспринимает возрат каретки просто как еще один обрабатываемый символ, и не генерирует его в конце каждой обработанной строки. Это может быть полезно для работы с нетекстовыми файлами, которые должны быть совместимы с Posix системами.
Если необходимо сравнивать два файла байт за байтом, можно использовать программу ‘cmp’ с опцией ‘-l’, чтобы выяснить значения каждого отличающегося байта в файлах. В GNU ‘cmp’, используя опцию ‘-c’, можно показывать ASCII представление этих байтов. (см. подробнее «Запуск cmp»).
Если ‘diff3’ считает, что все сравниваемые файлы — двоичные (нетекстовые файлы), он обычно сообщает об ошибке, так как такие сравнения обычно бесполезны. ‘diff3’ использует тот же метод, что и ‘diff’ чтобы определить является ли файл двоичным. Как и в ‘diff’, если входные файлы состоят их нескольких нетекстовых символов, но с другой стороны скорее являются текстовыми, можно заставить ‘diff3’ рассматривать все файлы как текстовые и сравнивать их строка за строкой с помощью опции ‘-a’ или ‘—text’.
Источник



