- Working with pipes on the Linux command line
- Checking on NICs
- Examining permissions
- Counting files
- Identifying processes
- Sorting results
- Wrapping up
- Linux pipe Command
- Pipe command
- Basic usage
- Multiple piping
- Manipulating list of files and directories
- Sorting output
- Printing matches of a particular pattern
- Print file content of a particular range
- Unique values
- Error pipes
- About the author
- Sidratul Muntaha
- Что такое каналы (pipe) в Linux? Как работает перенаправление каналов?
- Каналы в Linux: общая идея
- Имейте в виду: Pipe перенаправляет стандартный вывод на стандартный ввод, но не как аргумент команды
- Типы каналов в Linux
- Каналы без названия
- Именованные каналы
- Именованные каналы не занимают память на диске
- Сниженный ввод-вывод
- Связь между двумя очень разными процессами
- Понимание каналов более низкого уровня [для опытных пользователей и разработчиков]
Working with pipes on the Linux command line

I’m sorry to inform you, but the command line didn’t die off with the dinosaurs, nor did it disappear with the dodo or the carrier pigeon. The Linux command line is alive and well, and still going strong. It is an efficient way of quickly gathering and processing information, creating new scripts, and configuring systems.
One of the most powerful shell operators is the pipe ( | ). The pipe takes output from one command and uses it as input for another. And, you’re not limited to a single piped command—you can stack them as many times as you like, or until you run out of output or file descriptors.
One of the main purposes of piping is filtering. You use piping to filter the contents of a large file—to find a particular string or word, for example. This purpose is why the most popular use for pipes involves the commands grep and sort . But, you’re not limited to those cases. You can pipe the output to any command that accepts stream input. Let’s look at a theoretical example as an illustration of how this process works:
Both cmd1 and cmd2 are command line utilities that output their results to the screen ( stdout ). When you pipe one command’s output to another, however, the information from cmd1 doesn’t produce output to the screen. The pipe redirects that output as input to cmd2 .
Note: Don’t confuse pipe ( | ) redirection with file redirection ( > ) and ( ). (An example of file redirection: cmd1 > file or cmd1 .) File redirection either sends output to a file instead of the screen, or pulls input from a file.
Let’s look at some real-world examples of how piping works.
Checking on NICs
Let’s say that you need to know if one of your network interface cards (NICs) has an IP address beginning with 192:
$ ifconfig | grep 192
inet 192.168.1.96 netmask 255.255.255.0 broadcast 192.168.1.255
You can also find out which live NICs you have on a system with a simple pipe to grep :
$ ifconfig | grep UP
enp0s3: flags=4163 mtu 1500
lo: flags=73 mtu 65536
You could also grep for «RUNNING» or «RUN» to display the same information.
Examining permissions
Maybe you want to find out how many directories under /etc are writeable by root:
$ sudo ls -lR | grep drwx
The results are too long to list here, but as you can see from your displayed list, there are a lot of them. You still need to find out how many there are, and a visual count would take a long time. An easy option is to pipe the results of your ls command to the wc (word count) command:
$ sudo ls -lR | grep drwx | wc -l
The -l switch displays the number of lines. Your count might be different. This listing is from a fresh «RHEL 8 server no GUI» install.
[Want to try out Red Hat Enterprise Linux? Download it now for free.]
Counting files
You don’t have to use grep all the time. For example, you can list the number of files in the /etc directory with this:
Again, your results might look different, but you know something is wrong if the command returns a small number of files.
Identifying processes
You can also perform complex tasks using pipes. To list the process IDs (PIDs) for all systemd -related processes:
$ ps -ef | grep systemd | awk ‘< print $2 >‘
The awk command’s $2 output isolates the second (PID) column from the ps command. Note that the last entry, PID 17242 , is actually the PID for the grep command displaying this information, as you can see from the full listing results here:
khess 17242 7505 0 09:40 pts/0 00:00:00 grep —color=auto systemd
To remove this entry from your results, use the pipe operator again:
$ ps -ef | grep systemd | awk ‘< print $2 >‘ | grep -v grep
The -v switch tells the grep command to invert or ignore lines that contain the string that follows—in this case any line containing the word «grep.»
Sorting results
Another popular use of the pipe operator is to sort your results by piping to the sort command. Say that you want to sort the list of names in contacts.txt . First, let’s look at the contents as they are in the file before sorting:
Bob Jones
Leslie Smith
Dana David
Susan Gee
Leonard Schmidt
Linda Gray
Terry Jones
Colin Doe
Jenny Case
Now, sort the list:
$ cat contacts.txt | sort
Bob Jones
Colin Doe
Dana David
Jenny Case
Leonard Schmidt
Leslie Smith
Linda Gray
Susan Gee
Terry Jones
You can reverse the sort order with the -r switch:
$ cat contacts.txt | sort -r
Terry Jones
Susan Gee
Linda Gray
Leslie Smith
Leonard Schmidt
Jenny Case
Dana David
Colin Doe
Bob Jones
Was the output for either of these what you expected? By default, the sort command performs a dictionary sort on the first word or column, which is why Bob Jones and Terry Jones are not listed one after the other.
You can sort by the second column with the -k switch, specifying the column you want to sort on, which in our list is column two:
$ cat contacts.txt | sort -k2
Jenny Case
Dana David
Colin Doe
Susan Gee
Linda Gray
Bob Jones
Terry Jones
Leonard Schmidt
Leslie Smith
If you have a long contact list and you think that this list contains duplicate entries, you can pipe your list to sort and then uniq to remove those duplicates:
$ cat contacts.txt | sort | uniq
This command only displays unique entries, but it doesn’t save the results. To sort the file, filter unique entries, and then save the new file, use this:
$ cat contacts.txt | sort -k2 | uniq > contact_list.txt
Remember that the pipe operator and the file redirect operators do different things.
Wrapping up
Now that you’ve had a taste of the command line’s power, do you think you can handle the responsibility? Command line utilities have more flexibility than their graphical counterparts do. And for some tasks, there are no graphical equivalents.
The best way to learn command line behavior is to experiment. For example, the sort command didn’t do what you thought it should until you explored further. Don’t forget to use the power of your manual ( man ) pages to find those «hidden» secret switches and options that turn command line frustration into command line success.
Источник
Linux pipe Command
- STDIN (0) – Standard input
- STDOUT (1) – Standard output
- STDERR (2) – Standard error
When we’re going to work with “pipe” tricks, “pipe” will take the STDOUT of a command and pass it to the STDIN of the next command.
Let’s check out some of the most common ways you can incorporate the “pipe” command into your daily usage.
Pipe command
Basic usage
It’s better to elaborate on the working method of “pipe” with a live example, right? Let’s get started. The following command will tell “pacman”, the default package manager for Arch and all the Arch-based distros, to print out all the installed packages on the system.
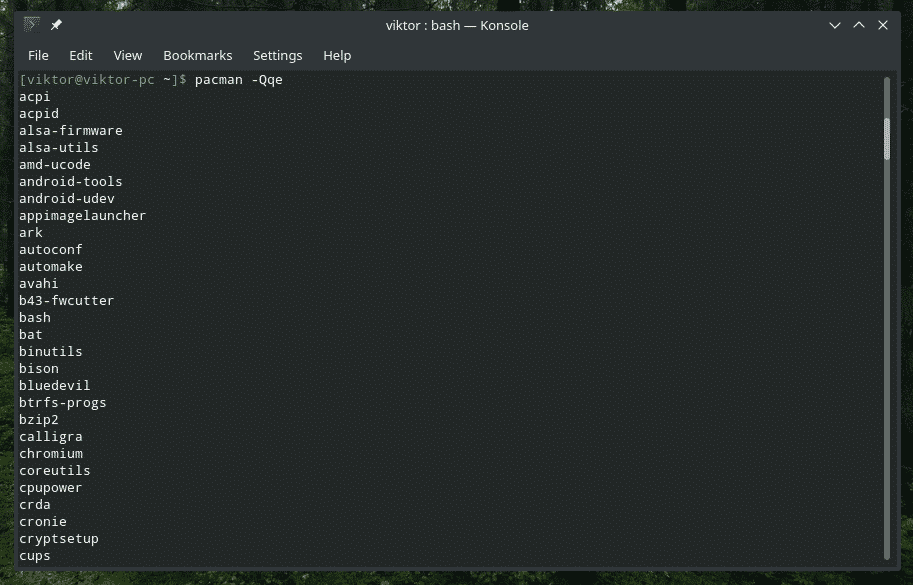
It’s a really LONG list of packages. How, about picking up only a few components? We could use “grep”. But how? One way would be dumping the output to a temporary file, “grep” the desired output and delete the file. This series of tasks, by itself, can be turned into a script. But we only script for very large things. For this task, let’s call upon the power of “pipe”!
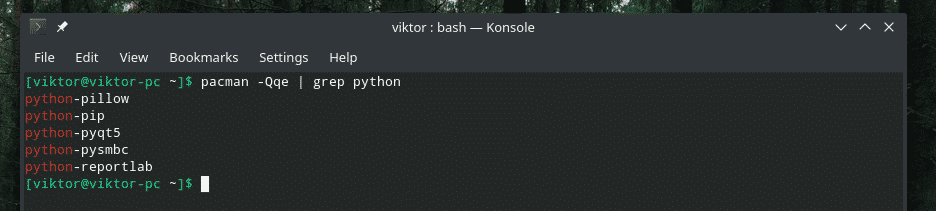
Awesome, isn’t it? The “|” sign is the call to the “pipe” command. It grabs the STDOUT from the left section and feeds it into the STDIN of the right section.
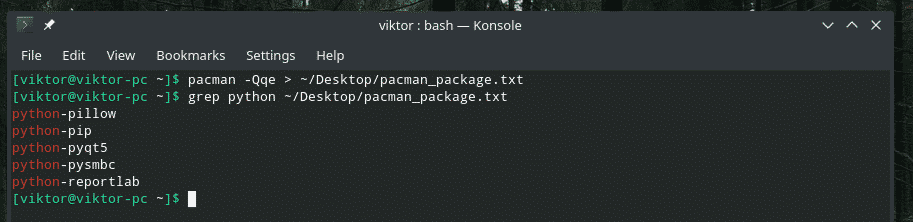
In the aforementioned example, the “pipe” command actually passed the output at the end of the “grep” part. Here’s how it plays out.
/ Desktop / pacman_package.txt
grep python
Multiple piping
Basically, there’s nothing special with the advanced usage of the “pipe” command. It’s completely up to you on how to use it.
For example, let’s start by stacking multiple piping.
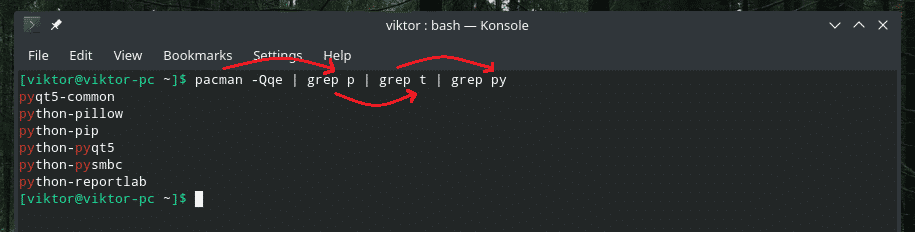
The pacman command output is filtered further and further by “grep” through a series of piping.
Sometimes, when we’re working with the content of a file, it can be really, really large. Finding out the right place of our desired entry can be difficult. Let’s search for all the entries that include digits 1 and 2.
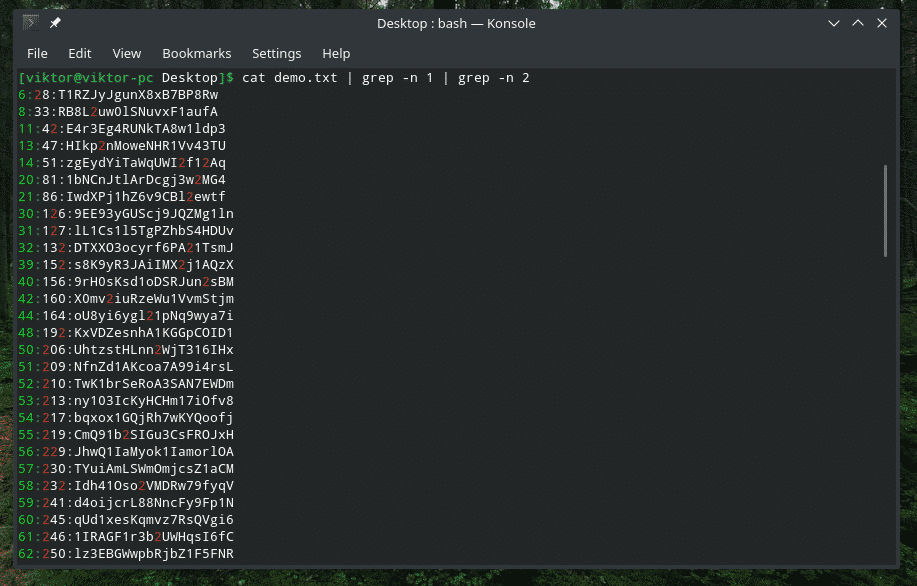
Manipulating list of files and directories
What to do when you’re dealing with a directory with TONS of files in it? It’s pretty annoying to scroll through the entire list. Sure, why not make it more bearable with pipe? In this example, let’s check out the list of all the files in the “/usr/bin” folder.
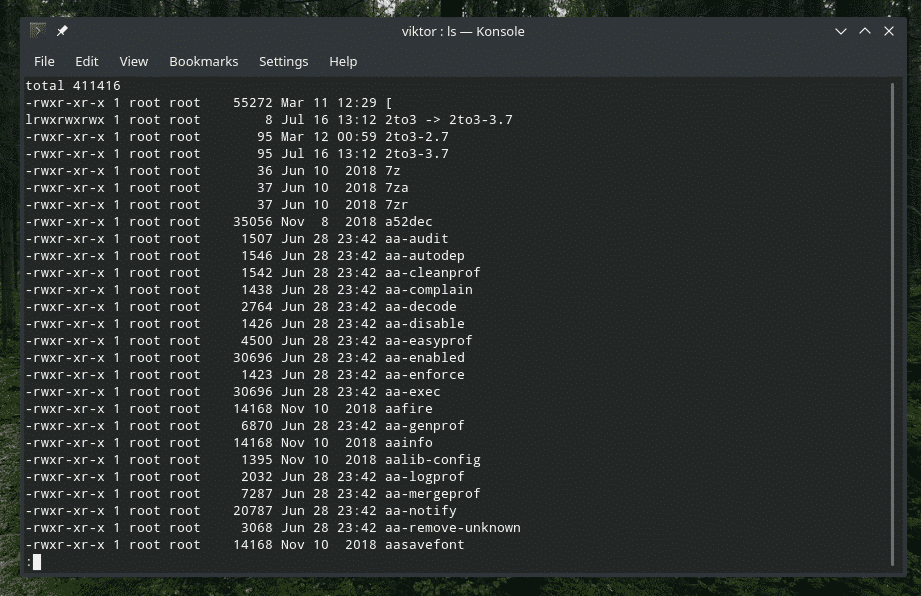
Here, “ls” prints all the files and their info. Then, “pipe” passes it to “more” to work with that. If you didn’t know, “more” is a tool that turns texts into one screenful view at a time. However, it’s an old tool and according to the official documentation, “less” is more recommended.
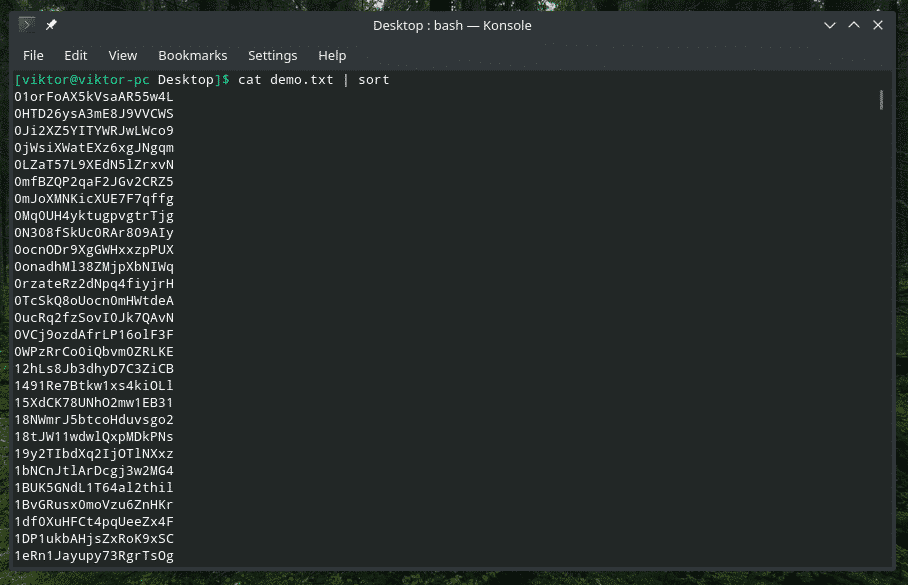
Sorting output
There’s a built-in tool “sort” that will take text input and sort them out. This tool is a real gem if you’re working with something really messy. For example, I got this file full of random strings.

Just pipe it to “sort”.
Printing matches of a particular pattern

This is a pretty twisted command, right? At first, “ls” outputs the list of all files in the directory. The “find” tool takes the output, searches for “.txt” files and summons “grep” to search for “00110011”. This command will check every single text file in the directory with the TXT extension and look for the matches.
Print file content of a particular range
When you’re working with a big file, it’s common to have the need of checking the content of a certain range. We can do just that with a clever combo of “cat”, “head”, “tail” and of course, “pipe”. The “head” tool outputs the first part of a content and “tail” outputs the last part.
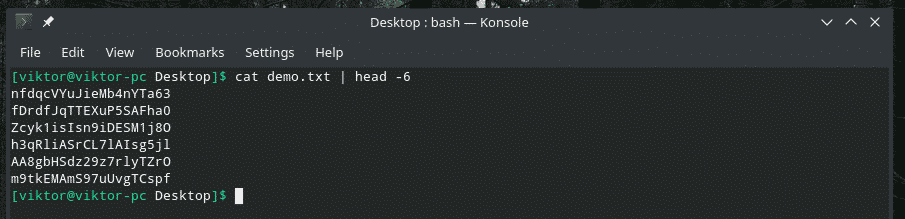
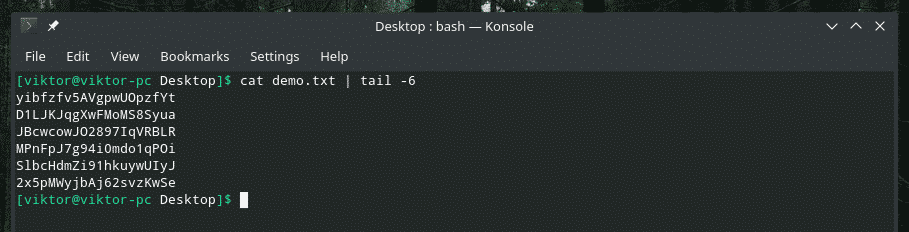
Unique values
When working with duplicate outputs, it can be pretty annoying. Sometimes, duplicate input can cause serious issues. In this example, let’s cast “uniq” on a stream of text and save it into a separate file.
For example, here’s a text file containing a big list of numbers that are 2 digits long. There are definitely duplicate contents here, right?
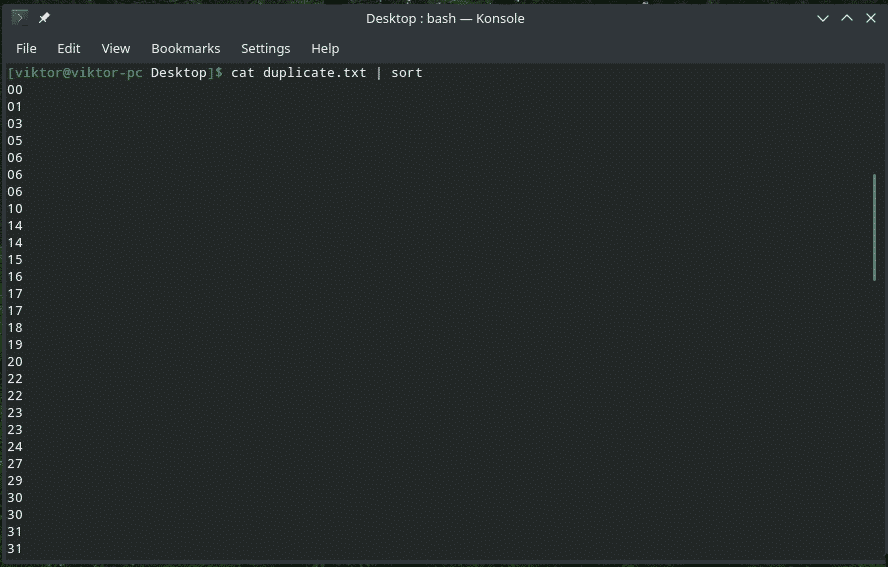
Now, let’s perform the filtering process.

Check out the output.

Error pipes
This is an interesting piping method. This method is used to redirect the STDERR to STDOUT and proceed with the piping. This is denoted by “|&” symbol (without the quotes). For example, let’s create an error and send the output to some other tool. In this example, I just typed some random command and passed the error to “grep”.

Final thoughts
While “pipe” itself is pretty simplistic in nature, the way it works offers very versatile way of utilizing the method in infinite ways. If you’re into Bash scripting, then it’s way more useful. Sometimes, you can just do crazy things outright! Learn more about Bash scripting.
About the author

Sidratul Muntaha
Student of CSE. I love Linux and playing with tech and gadgets. I use both Ubuntu and Linux Mint.
Источник
Что такое каналы (pipe) в Linux? Как работает перенаправление каналов?
Главное меню » Linux » Что такое каналы (pipe) в Linux? Как работает перенаправление каналов?

Вы, вероятно, также знаете, что такое перенаправление канала, которое используется для перенаправления вывода одной команды в качестве ввода для следующей команды.
Но знаете ли вы, что под ним? Как на самом деле работает перенаправление каналов?
Не беспокойтесь, потому что сегодня мы демистифицируем каналы Unix, чтобы в следующий раз, когда вы пойдете на свидание с этими причудливыми вертикальными полосами, вы точно знали, что происходит.
Примечание. Мы использовали термин Unix в некоторых местах, потому что концепция каналов (как и многие другие вещи в Linux) происходит от Unix.
Каналы в Linux: общая идея
Вот что вы повсюду увидите относительно «что такое каналы в Unix?»:
- Каналы Unix – это механизм IPC (межпроцессное взаимодействие), который перенаправляет вывод одной программы на вход другой программы.
Это общее объяснение, которое дают все. Мы хотим проникнуть глубже. Давайте перефразируем предыдущую строку более техническим языком, убрав абстракции:
- Каналы Unix – это механизм IPC (межпроцессного взаимодействия), который принимает программу stdout и пересылает ее другой программе stdin через буфер.
Намного лучше. Удаление абстракции сделало его намного чище и точнее. Вы можете посмотреть на следующую схему, чтобы понять, как работает pipe.
Один из простейших примеров команды pipe – передать некоторый вывод команды команде grep для поиска определенной строки.
Имейте в виду: Pipe перенаправляет стандартный вывод на стандартный ввод, но не как аргумент команды
Очень важно понять, что конвейер передает команду stdout другой команде stdin, но не как аргумент команды. Мы объясним это на примере.
Если вы используете команду cat без аргументов, по умолчанию будет выполняться чтение из stdin. Вот пример:
Здесь мы использовали cat без передачи файлов, поэтому по умолчанию stdin. Затем мы написали строку, а затем использовал Ctrl + d, чтобы сообщить, что закончили писать (Ctrl + d подразумевает EOF или конец файла). Как только мы закончили писать, cat прочитал stdin и написал эту строку в stdout.
Теперь рассмотрим следующую команду:
Вторая команда НЕ эквивалентна cat hey. Здесь stdout”hey” переносится в буфер и передает stdin в cat. Поскольку аргументов командной строки не было, cat по умолчанию выбрал stdin для чтения, а что-то уже было в stdin, поэтому команда cat приняла это и напечатала stdout.
Фактически, мы создали файл с именем hey и поместили в него некоторый контент.
Типы каналов в Linux
В Linux есть два типа каналов:
- Безымянный канал, также называемый анонимным.
- Именованные каналы
Каналы без названия
Без названия каналы, как следует из названия, не имеют имени. Они создаются на лету вашей оболочкой Unix всякий раз, когда вы используете символ |.
Когда люди говорят о каналах в Linux, они обычно говорят об этом. Они полезны, потому что вам, как конечному пользователю, не нужно ничего отслеживать. Ваша оболочка справится со всем этим.
Именованные каналы
Этот немного отличается. Именованные каналы действительно присутствуют в файловой системе. Они существуют как обычный файл. Вы можете создать именованный файл, используя следующую команду:
Это создаст файл с именем «pipe». Выполните следующую команду:
Обратите внимание на «p» в начале, это означает, что файл является каналом. Теперь воспользуемся этим каналом.
Как мы говорили ранее, конвейер пересылает вывод одной команды на вход другой. Это как курьерская служба, вы даете посылку доставить с одного адреса, а они доставляют по другому. Итак, первый шаг – предоставить пакет, то есть предоставить каналу что-то.
Вы заметите, что echo еще не вернули нам терминал. Откройте новый терминал и попробуйте прочитать из этого файла.
Обе эти команды завершили свое выполнение одновременно.
Это одно из фундаментальных различий между обычным файлом и именованным каналом. В канал ничего не записывается, пока какой-либо другой процесс не прочитает его.
Зачем использовать именованные каналы? Вот список того, почему вы хотите использовать именованные каналы
Именованные каналы не занимают память на диске
Если вы выполните a du -s pipe, вы увидите, что он не занимает места. Это потому, что именованные каналы похожи на конечные точки для чтения и записи из буфера памяти и в него. Все, что записывается в именованный канал, фактически сохраняется во временном буфере памяти, который сбрасывается, когда операция чтения выполняется из другого процесса.
Сниженный ввод-вывод
Поскольку запись в именованный канал означает сохранение данных в буфере памяти, операции с большими файлами значительно сокращают дисковый ввод-вывод.
Связь между двумя очень разными процессами
Выходные данные события можно мгновенно и очень эффективно получить из другого процесса с помощью именованных каналов. Поскольку чтение и запись происходят одновременно, время ожидания практически равно нулю.
Понимание каналов более низкого уровня [для опытных пользователей и разработчиков]
В следующем разделе речь идет о каналах на более глубоком уровне с фактическими реализациями. Этот раздел требует от вас базового понимания:
- Как работает программа на C
- Что такое системные вызовы
- Что такое процессы
- Что такое файловые дескрипторы
Мы не будем вдаваться в подробности примеров. Речь идет только о «каналах». Для большинства пользователей Linux этот раздел не нужен.
В конце мы предоставили для компиляции образец файла – Makefile. Имейте в виду, что эти программы предназначены только для иллюстративных целей, поэтому, если вы видите, что ошибки обрабатываются некорректно.
Рассмотрим следующий пример программы:
В строке 16 мы создали безымянный канал, используя функцию pipe(). Первое, что следует заметить, это то, что мы передали массив целых чисел со знаком длиной 2.
Это потому, что канал – это не что иное, как массив из двух целых чисел без знака, представляющих два файловых дескриптора. Один для письма, один для чтения. И оба они указывают на расположение буфера в памяти, которое обычно составляет 1 МБ.
Здесь мы назвали переменную fd. fd [0] – дескриптор входного файла, fd [1] – дескриптор выходного файла. В этой программе один процесс записывает строку в файловый дескриптор fd [1], а другой процесс читает из файлового дескриптора fd [0].
Именованный канал ничем не отличается. С именованным каналом вместо двух файловых дескрипторов вы получаете имя файла, которое можно открыть из любого процесса и работать с ним, как с любым другим файлом, учитывая при этом характеристики канала.
Вот пример программы, которая делает то же самое, что и предыдущая программа, но вместо анонимного канала создает именованный канал.
Здесь мы использовали системный вызов mknod для создания именованного канала. Как вы можете видеть, хотя мы удалили канал по завершении, вы вполне можете оставить его и легко использовать для связи между различными программами, просто открыв и записав в файл с именем «npipe» в моем случае.
Вам также не придется создавать два разных канала для двусторонней связи, как в случае с анонимными каналами.
Вот образец Makefile, как и было обещано. Поместите его в тот же каталог, что и предыдущие программы, с именами «pipe.c» и «fifo.c» соответственно.
Вот так. Это действительно все, что есть в каналах Unix.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник



