- Конвертирование файлов в кодировку UTF-8 в Linux
- Конвертирование файлов из UTF-8 в ASCII
- Конвертирование нескольких файлов в кодировку UTF-8
- How to Convert Files to UTF-8 Encoding in Linux
- Convert Files from UTF-8 to ASCII Encoding
- Convert Multiple Files to UTF-8 Encoding
- If You Appreciate What We Do Here On TecMint, You Should Consider:
- How to convert ISO8859-15 to UTF8?
- 8 Answers 8
- Not the answer you’re looking for? Browse other questions tagged linux bash text or ask your own question.
- Linked
- Subscribe to RSS
- How to convert a file from ASCII to UTF-8?
- 1 Answer 1
- Formatting from ISO-8859-1 to Windows-1251
- 1 Answer 1
Конвертирование файлов в кодировку UTF-8 в Linux
Оригинал: How to Convert Files to UTF-8 Encoding in Linux
Автор: Aaron Kili
Дата публикации: 2 ноября 2016 года
Перевод: А. Кривошей
Дата перевода: ноябрь 2017 г.
В этом руководстве мы рассмотрим кодировки символов и разберем несколько примеров преобразования файлов из одной кодировки в другую с помощью утилиты командной строки. Затем мы покажем, как преобразовать файлы в Linux из любой кодировки (charset) в UTF-8.
Как вы, наверное, уже знаете, компьютер не понимает и не хранит информацию в виде букв, цифр или чего-либо еще. Он работает только с битами. Бит имеет только два возможных значения — 0 или 1, true или false, да или нет. Все остальное кодируется последовательностями битов.
Простыми словами, кодировка символов — это способ кодировки различных символов определенными последовательностями нулей и единиц. Когда мы вводим текст и сохраняем его в файл, слова и предложения, которые мы набираем, состоят из разных символов, а символы преобразуются в биты с помощью кодировки.
Существуют различные схемы кодирования, такие как ASCII, ANSI, Unicode и другие. Ниже приведен пример кодировки ASCII.
В Linux для преобразования текста из одной кодировки в другую используется утилита командной строки iconv.
Вы можете проверить кодировку файла с помощью команды file, используя флаг -i или -mime, который печатает строку типа mime, как в приведенных ниже примерах:

Синтаксис команды iconv следующий:
Где -f или —from-code задает входную кодировку, а -t или —to-encoding задает конечную кодировку.
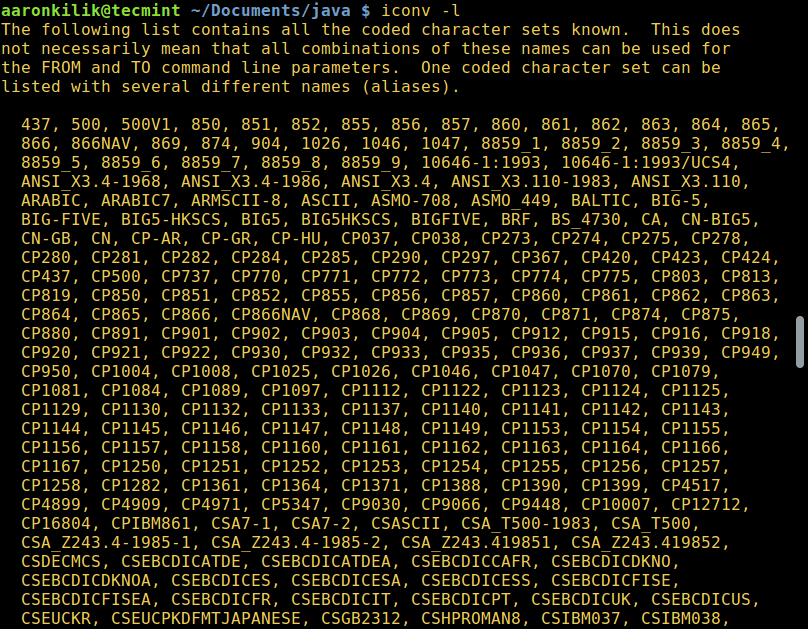
Для того, чтобы вывести список всех доступных опций, введите:
Конвертирование файлов из UTF-8 в ASCII
Далее мы научимся конвертировать текст из одной кодировки в другую. Приведенная ниже команда преобразует текст из ISO-8859-1 в кодировку UTF-8.
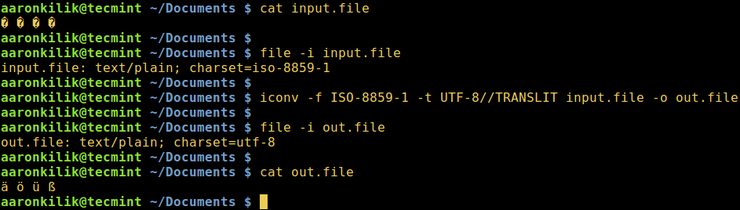
Рассмотрим файл input.file, который содержит следующие символы:
(Прим: вы увидите эти символы на снимке ниже)
Начнем с проверки кодировки файла, затем просмотрим его содержимое. Мы можем преобразовать все символы в кодировку ASCII.
После запуска команды iconv мы затем проверяем содержимое выходного файла и новую кодировку, как показано ниже.
Примечание. Если в команду добавлена строка //IGNORE, то символы, которые не могут быть преобразованы, и ошибка выводятся после преобразования.
Далее, если добавлена строка //TRANSLIT, как в приведенном выше примере (ASCII//TRANSLIT), преобразуемые символы при необходимости и по возможности транслитерируются. Это означает, что если символ не может быть представлен в целевой кодировке, его можно аппроксимировать одним или несколькими похожими символами.
Далее, любой символ, который не может быть транслитерирован и которого нет в целевой кодировке, заменяется в выводе вопросительным знаком (?).
Конвертирование нескольких файлов в кодировку UTF-8
Возвращаясь к основной теме нашей статьи, мы можем написать небольшой скрипт для преобразования нескольких или всех файлов в каталоге в кодировку UTF-8, под названием encoding.sh:
Сохраните этот файл и сделайте скрипт исполняемым. Запускайте его из той директории, где расположены ваши файлы.
Важное замечание. Вы также можете также использовать этот скрипт для преобразования нескольких файлов из одной заданной кодировки в другую (любую), просто меняйте со значения переменных FROM_ENCODING и TO_ENCODING, не забывая об имени выходного файла «$
Для получения дополнительной информации почитайте руководство iconv:
Подводя итог этой статье, необходимо отметить, что понимание способов преобразования текста из одной кодировки в другую — это знания, необходимые каждому пользователю компьютера, а тем более программистам, когда дело касается работы с текстами.
Если вы хотите лучше понять проблему кодировок символов, прочитайте следующие статьи:
Источник
How to Convert Files to UTF-8 Encoding in Linux
In this guide, we will describe what character encoding and cover a few examples of converting files from one character encoding to another using a command line tool. Then finally, we will look at how to convert several files from any character set (charset) to UTF-8 encoding in Linux.
As you may probably have in mind already, a computer does not understand or store letters, numbers or anything else that we as humans can perceive except bits. A bit has only two possible values, that is either a 0 or 1 , true or false , yes or no . Every other thing such as letters, numbers, images must be represented in bits for a computer to process.
In simple terms, character encoding is a way of informing a computer how to interpret raw zeroes and ones into actual characters, where a character is represented by set of numbers. When we type text in a file, the words and sentences we form are cooked-up from different characters, and characters are organized into a charset.
There are various encoding schemes out there such as ASCII, ANSI, Unicode among others. Below is an example of ASCII encoding.
In Linux, the iconv command line tool is used to convert text from one form of encoding to another.
You can check the encoding of a file using the file command, by using the -i or —mime flag which enables printing of mime type string as in the examples below:
![]() Check File Encoding in Linux
Check File Encoding in Linux
The syntax for using iconv is as follows:
Where -f or —from-code means input encoding and -t or —to-encoding specifies output encoding.
To list all known coded character sets, run the command below:
![]() List Coded Charsets in Linux
List Coded Charsets in Linux
Convert Files from UTF-8 to ASCII Encoding
Next, we will learn how to convert from one encoding scheme to another. The command below converts from ISO-8859-1 to UTF-8 encoding.
Consider a file named input.file which contains the characters:
Let us start by checking the encoding of the characters in the file and then view the file contents. Closely, we can convert all the characters to ASCII encoding.
After running the iconv command, we then check the contents of the output file and the new encoding of the characters as below.
![]() Convert UTF-8 to ASCII in Linux
Convert UTF-8 to ASCII in Linux
Note: In case the string //IGNORE is added to to-encoding, characters that can’t be converted and an error is displayed after conversion.
Again, supposing the string //TRANSLIT is added to to-encoding as in the example above (ASCII//TRANSLIT), characters being converted are transliterated as needed and if possible. Which implies in the event that a character can’t be represented in the target character set, it can be approximated through one or more similar looking characters.
Consequently, any character that can’t be transliterated and is not in target character set is replaced with a question mark (?) in the output.
Convert Multiple Files to UTF-8 Encoding
Coming back to our main topic, to convert multiple or all files in a directory to UTF-8 encoding, you can write a small shell script called encoding.sh as follows:
Save the file, then make the script executable. Run it from the directory where your files ( *.txt ) are located.
Important: You can as well use this script for general conversion of multiple files from one given encoding to another, simply play around with the values of the FROM_ENCODING and TO_ENCODING variable, not forgetting the output file name «$
For more information, look through the iconv man page.
To sum up this guide, understanding encoding and how to convert from one character encoding scheme to another is necessary knowledge for every computer user more so for programmers when it comes to dealing with text.
Lastly, you can get in touch with us by using the comment section below for any questions or feedback.
If You Appreciate What We Do Here On TecMint, You Should Consider:
TecMint is the fastest growing and most trusted community site for any kind of Linux Articles, Guides and Books on the web. Millions of people visit TecMint! to search or browse the thousands of published articles available FREELY to all.
If you like what you are reading, please consider buying us a coffee ( or 2 ) as a token of appreciation.

We are thankful for your never ending support.
Источник
How to convert ISO8859-15 to UTF8?
I have an Arabic file encoded in ISO8859-15. How can I convert it into UTF8?
I used iconv but it doesn’t work for me.
I wanted to attach the file, but I don’t know how.
8 Answers 8
Could it be that your file is not ISO-8859-15 encoded? You should be able to check with the file command:
Also, you can use iconv without providing the encoding of the original file:
I found this to work for me:
I have ubuntu 14 and the other answers where no working for me
I found this command here
We have this problem and to solve
Create a script file called to-utf8.sh
Set the executable bit
Do a conversion
If you want to convert all files under a folder, do

in my case, the file command tells a wrong encoding, so i tried converting with all the possible encodings, and found out the right one.
execute this script and check the result file.

You can use ISO-8859-9 encoding:
I got the same problem, but i find the answer in this page! it works for me, you can try it.
Iconv just writes the converted text to stdout. You have to use -o OUTPUTFILE.txt as an parameter or write stdout to a file. ( iconv -f x -t z filename.txt > OUTPUTFILE.txt or iconv -f x -t z OUTPUTFILE.txt in some iconv versions)

Not the answer you’re looking for? Browse other questions tagged linux bash text or ask your own question.
Linked
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
site design / logo © 2021 Stack Exchange Inc; user contributions licensed under cc by-sa. rev 2021.10.8.40416
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Источник
How to convert a file from ASCII to UTF-8?
I’m trying to transcode a bunch a files from ASCII to UTF-8.
For that, I tried using iconv :
-f ENCODING the encoding of the input
-t ENCODING the encoding of the output
Still that file didn’t convert to UTF-8. It is a .dat file.
Before posting this, I searched Google and found information like:
ASCII is a subset of UTF-8, so all ASCII files are already UTF-8 encoded. The bytes in the ASCII file and the bytes that would result from «encoding it to UTF-8» would be exactly the same bytes. There’s no difference between them.
Still the above links didn’t help.
Even though it is in ASCII it will support UTF-8 as UTF-8 is a super set, the other party who is going to receive the files from me need file encoding as UTF-8. He just need file format as UTF-8.
Any suggestions please.

1 Answer 1
I’m a little confused by the question, because, as you indicated, ASCII is a subset of UTF-8, so all ASCII files are already UTF-8 encoded.
If you’re sending files containing only ASCII characters to the other party, but the other party is complaining that they’re not ‘UTF-8 Encoded’, then I would guess that they’re referring to the fact that the ASCII file has no byte order mark explicitly indicating the contents are UTF-8.
If that is indeed the case, then you can add a byte order mark using the answer here:
If the other party indicates that he does not need the ‘BOM’ (Byte Order Mark), but is still complaining that the files are not UTF-8, then another possibility is that your initial file is not actually ASCII, but rather contains characters that are encoded using ANSI or ISO-8859-1.
Edited to add the following experiment, after comment from Ram regarding the other party looking for the type using the ‘file’ command
Источник
Formatting from ISO-8859-1 to Windows-1251
I want to fix the encoding in a string «Ïåðåïðîøèòü Ñûðîåæêèíà» and get the correct UTF-8 string «Перепрошить Сыроежкина». This website told me that I need to convert from ISO-8859-1 to Windows-1251 to get the correct result, however when I try to use iconv for this I get this error:
What I also do not understand is why I need to convert the string to Windows-1251 when I want to get the result in UTF-8 .
Edit: I also tried to use enconv , however the result was unsatisfactory as well.
1 Answer 1
The string seems to be double-encoded: first the original Windows-1251 has been mis-interpreted as ISO-8859-1, then those mis-interpreted characters are themselves turned into their UTF-8 equivalents.
The fact that you can have the «wrong» text as visible characters along with the «correct» text indicates your system works in UTF-8 or some other Unicode character set, and that the string has been converted to Unicode in its mis-interpreted form.
Try decoding it this way:
If those characters were actually in their native 8-bit encoding, the string would be displayed something like this on an UTF-8 system: «����������� ����������». Any ISO-8859-1 (or any 8-bit character set) characters with the high bit set are likely to produce an «invalid encoding» result when interpreted as UTF-8. Unicode has a special display symbol, «�», for «this character has been encoded in a broken way».
If your system was actually using ISO-8859-1, you would see the string as ‘Ïåðåïðîøèòü Ñûðîåæêèíà’ — but then it would be impossible to display «Перепрошить Сыроежкина» in the same terminal window, because ISO-8859-1 does not include Cyrillics at all.
The website you linked probably sees the incoming string as UTF-8, and assumes that this conversion was just a part of the communication between the browser and the web server, and just identifies the other misinterpretation.
Источник



