- Count Number of Files in a Directory in Linux
- Count number of files in directory in Linux
- Count number of files and directories (without hidden files)
- Count number of files and directories including hidden files
- Count number of files and directories including the subdirectories
- Count only the files, not directories
- Count only the files, not directories and only in current directory, not subdirectories
- How to Count Number of Files in a Directory in Linux
- Method 1: Use ls and wc command for counting number of lines in directory
- Method 2: Use tree command for counting number of files in directory
- Method 3: Use find command to count number of files in a directory
- Find number of files in folder and sub folders?
- 9 Answers 9
- How to count number of files in each directory?
- 18 Answers 18
- Is there a bash command which counts files?
- 16 Answers 16
Count Number of Files in a Directory in Linux
I presume you are aware of the wc command for counting number of lines. We can use the same wc command with ls command to count the number of files in a directory.
This task seems simple but could soon turn slightly complex based on your need and definition of counting files. Before I confuse you further, let’s see about various use cases of counting the number of files in Linux.
Count number of files in directory in Linux
Let me first show you the content of the test directory I am going to use in this tutorial:
You can see that it has 9 files (including one hidden file) and 2 sub-directories in that directory. But you don’t have to do it manually. Let’s count the number of files using Linux commands.
Count number of files and directories (without hidden files)
You can simply run the combination of the ls and wc command and it will display the number of files:
This is the output:
There is a problem with this command. It counts all the files and directories in the current directories. But it doesn’t see the hidden files (the files that have name starting with a dot).
This is the reason why the above command showed me a count of 10 files instead of 11 (9 files and 2 directories).
Count number of files and directories including hidden files
You probably already know that -a option of ls command shows the hidden files. But if you use the ls -a command, it also displays the . (present directory) and .. (parent directory). This is why you need to use -A option that displays the hidden files excluding . and .. directories.
This will give you the correct count of files and directories in the current directory. Have a look at the output that shows a count of 11 (9 files and 2 directories):
You can also use this command to achieve the same result:
Note that it the option used is 1 (one) not l (L). Using the l (L) option displays an additional line at the beginning of the output (see ‘total 64’ in the directory output at the beginning of the article). Using 1 (one) lists one content per line excluding the additional line. This gives a more accurate result.
Count number of files and directories including the subdirectories
What you have see so far is the count of files and directories in the current directory only. It doesn’t take into account the files in the subdirectories.
If you want to count the number of files and directories in all the subdirectories, you can use the tree command.
This command shows the directory structure and then displays the summary at the bottom of the output.
As you can see in the output, it shows that there are 7 directories and 20 files in total. The good thing about this result is that it doesn’t count directories in the count of files.
Count only the files, not directories
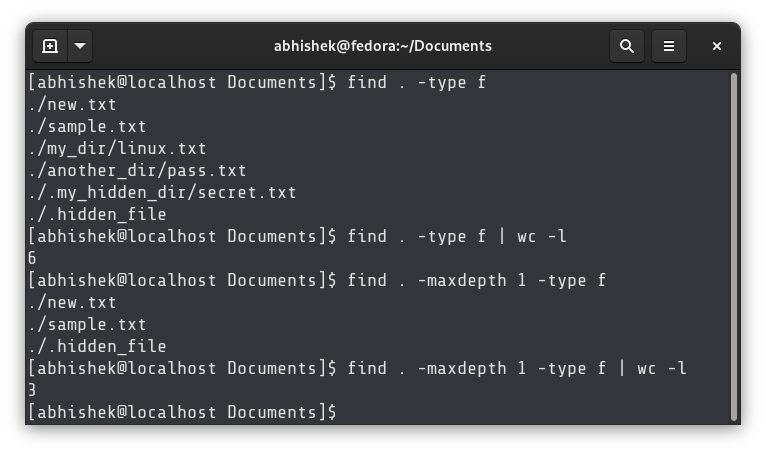
So far, all the solutions we have seen for counting the number of files, also take directories into account. Directories are essentially files but what if you want to count only the number of files, not directories? You can use the wonderful find command.
You can run this command:
The above command searched for all the files (type f) in current directory and its subdirectories.
Count only the files, not directories and only in current directory, not subdirectories
That’s cool! But what if you want to count the number of files in the current directory only excluding the files in the subdirectories? You can use the same command as above but with a slight difference.
All you have to do is to add the ‘depth’ of your find. If you set it at 1, it won’t enter the subdirectories.
Here’s the output now:
In the end…
In Linux, you can have multiple ways to achieve the same goal. I am pretty sure there can be several other methods to count the number of files in Linux. If you use some other command, why not share it with us?
I hope this Linux tutorial helped you learn a few things. Stay in touch for more Linux tips.
Источник
How to Count Number of Files in a Directory in Linux
How do you know how many files are there is a directory?
In this quick tutorial, you’ll learn various ways to count the number of files in a directory in Linux.
Method 1: Use ls and wc command for counting number of lines in directory
The simplest and the most obvious option is to use the wc command for counting number of files.
The above command will count all the files and directories but not the hidden ones. You can use -A option with the ls command to list hidden files but leaving out . and .. directories:
If you only want to count number of files, including hidden files, in the current directory, you can combine a few commands like this:
Let me explain what it does:
- -p with ls adds / at the end of the directory names.
- -A with ls lists all the files and directories, including hidden files but excluding . and .. directories.
- grep -v /$ only shows the lines that do NOT match ( -v option) lines that end with / .
- wc -l counts the number of lines.
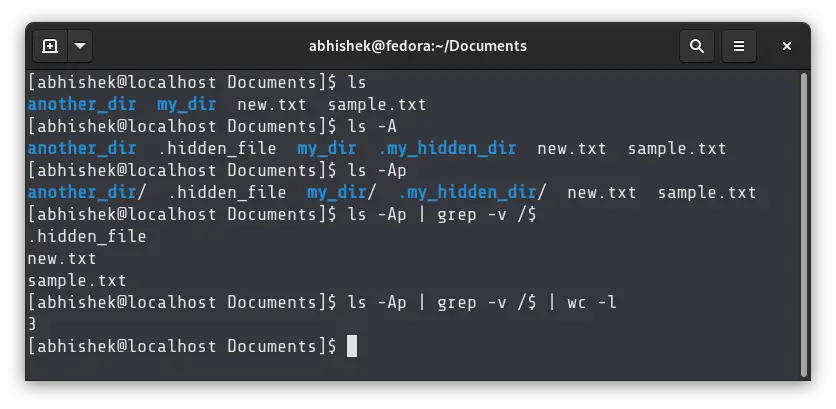
Basically, you use ls to list display all the files and directories (with / added to directory names). You then use pipe redirection to parse this output to the grep command. The grep command only displays the lines that do not have / at the end. The wc command then counts all such lines.
Method 2: Use tree command for counting number of files in directory
You can use the tree command for displaying the number of files in the present directory and all of its subdirectories.
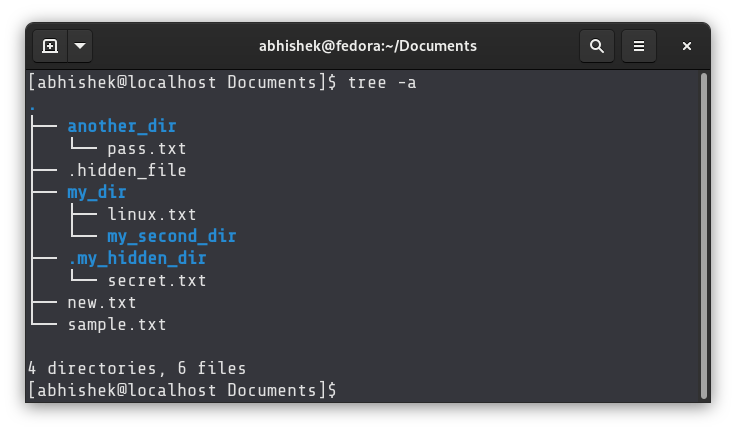
As you can see, the last line of the output shows the number of directories and files, including the hidden ones thanks to option -a .
If you want to get the number of files in current directory only, exclude the subdirectories, you can set the level to 1 like this:
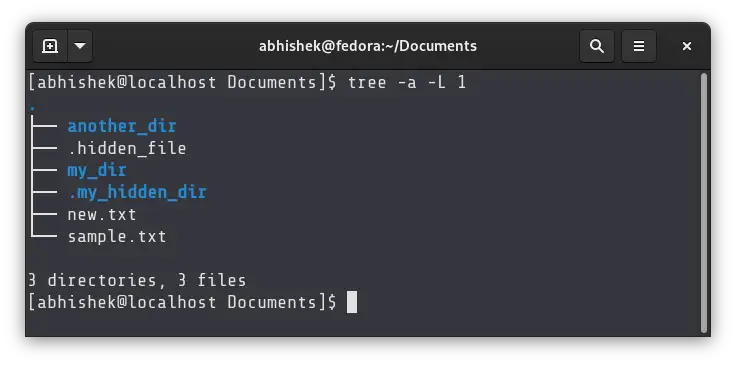
Method 3: Use find command to count number of files in a directory
The evergreen find command is quite useful when it comes with dealing with files.
If you want to count the number of files in a directory, use the find command to get all the files first and then count it using the wc command.
With -type f you tell the find command to only look for files.
If you don’t want the files from the subdirectories, limit the scope of find command at level 1, i.e. current directory.
There could be some other ways to count the number of lines in a directory in Linux. It’s up to you how you want to go about.
I hope you find this helpful. Feel free to leave a question or suggestion in the comment section.
Источник
Find number of files in folder and sub folders?
I want to find the total count of the number of files under a folder and all its sub folders.
9 Answers 9
May be something like
find . -type f | wc -l
would do the trick. Try the command from the parent folder.
-type f finds all files in . and subfolders. The result (a list of files found) is passed ( | ) to wc -l which counts the number of lines. -name
only looks for certain files.

Use the tree command. You might need to install the tree package.
It will list all the files and folders under the given folder and list a summary at the end.

To count files (even files without an extension) at the root of the current directory, use:
To count files (even files without an extension) recursively from the root of the current directory, use:

The fastest and easiest way, is to use tree . Its speed is limited by your output terminal, so if you pipe the result to tail -1 , you’ll get immediate result. You can also control to what directory level you like the results, using the -L option. For colorized output, use -C . For example:
If it’s not already there, you can get it here.

Don’t count the output lines of find, because filenames, containing 99 newlines, will count as 100 files.
Use this command for each folder in the path
You can use find . | wc -l
find . will list all files and folders and theire contents starting in your current folder.
wc -l counts the results of find
Источник
How to count number of files in each directory?
I am able to list all the directories by
I attempted to list the contents of each directory and count the number of files in each directory by using the following command
But this summed the total number of lines returned by
Is there a way I can count the number of files in each directory?
18 Answers 18
This prints the file count per directory for the current directory level:

Assuming you have GNU find, let it find the directories and let bash do the rest:
- find . -type f to find all items of the type file , in current folder and subfolders
- cut -d/ -f2 to cut out their specific folder
- sort to sort the list of foldernames
- uniq -c to return the number of times each foldername has been counted

You could arrange to find all the files, remove the file names, leaving you a line containing just the directory name for each file, and then count the number of times each directory appears:
The only gotcha in this is if you have any file names or directory names containing a newline character, which is fairly unlikely. If you really have to worry about newlines in file names or directory names, I suggest you find them, and fix them so they don’t contain newlines (and quietly persuade the guilty party of the error of their ways).
If you’re interested in the count of the files in each sub-directory of the current directory, counting any files in any sub-directories along with the files in the immediate sub-directory, then I’d adapt the sed command to print only the top-level directory:
The first pattern captures the start of the name, the dot, the slash, the name up to the next slash and the slash, and replaces the line with just the first part, so:
The second replace captures the files directly in the current directory; they don’t have a slash at the end, and those are replace by ./ . The sort and count then works on just the number of names.
Источник
Is there a bash command which counts files?
Is there a bash command which counts the number of files that match a pattern?
For example, I want to get the count of all files in a directory which match this pattern: log*


16 Answers 16
This simple one-liner should work in any shell, not just bash:
ls -1q will give you one line per file, even if they contain whitespace or special characters such as newlines.
The output is piped to wc -l, which counts the number of lines.
You can do this safely (i.e. won’t be bugged by files with spaces or \n in their name) with bash:
You need to enable nullglob so that you don’t get the literal *.log in the $logfiles array if no files match. (See How to «undo» a ‘set -x’? for examples of how to safely reset it.)

Lots of answers here, but some don’t take into account
- file names with spaces, newlines, or control characters in them
- file names that start with hyphens (imagine a file called -l )
- hidden files, that start with a dot (if the glob was *.log instead of log*
- directories that match the glob (e.g. a directory called logs that matches log* )
- empty directories (i.e. the result is 0)
- extremely large directories (listing them all could exhaust memory)
Here’s a solution that handles all of them:
- -U causes ls to not sort the entries, meaning it doesn’t need to load the entire directory listing in memory
- -b prints C-style escapes for nongraphic characters, crucially causing newlines to be printed as \n .
- -a prints out all files, even hidden files (not strictly needed when the glob log* implies no hidden files)
- -d prints out directories without attempting to list the contents of the directory, which is what ls normally would do
- -1 makes sure that it’s on one column (ls does this automatically when writing to a pipe, so it’s not strictly necessary)
- 2>/dev/null redirects stderr so that if there are 0 log files, ignore the error message. (Note that shopt -s nullglob would cause ls to list the entire working directory instead.)
- wc -l consumes the directory listing as it’s being generated, so the output of ls is never in memory at any point in time.
- — File names are separated from the command using — so as not to be understood as arguments to ls (in case log* is removed)
The shell will expand log* to the full list of files, which may exhaust memory if it’s a lot of files, so then running it through grep is be better:
This last one handles extremely large directories of files without using a lot of memory (albeit it does use a subshell). The -d is no longer necessary, because it’s only listing the contents of the current directory.
Источник



