- Как на Linux настроить RAID 10 для достижения высокой производительности и отказоустойчивости дискового ввода / вывода
- Как работает массив RAID 10?
- Настройка массива RAID 10
- Тестируем производительность RAID при помощи DD
- 1. Операция записи
- 2. Операция чтения
- Тестируем производительность RAID при помощи Iozone
- Установка пакета Iozone на CentOS/RHEL 7
- Установка пакета Iozone на Debian 7
- How to create RAID 10 – Striped Mirror Vdev ZPool On Ubuntu Linux
- Before you get started
- Create striped mirrored VDEVs (RAID 10)
- Step – 1: Find device name
- Step -2: Create a 2 x 2 mirrored pool using four raw disks
- Another example: Create a 2 x 2 mirrored pool using four partitions
- How do I delete a zpool and all data stored in the pool called cartwheel?
- Работа с mdadm в Linux для организации RAID
- Установка mdadm
- Сборка RAID
- Подготовка носителей
- Создание рейда
- Создание файла mdadm.conf
- Создание файловой системы и монтирование массива
- Информация о RAID
Как на Linux настроить RAID 10 для достижения высокой производительности и отказоустойчивости дискового ввода / вывода
Массив RAID 10, т. е. RAID 1 + 0 или чередование с зеркалированием, обеспечивает высокую производительность и отказоустойчивость дисковых операций ввода / вывода за счет объединения функций из RAID 0, в котором операции чтения / записи выполняются параллельно на нескольких дисках, и RAID 1, в котором данные записываются идентично на двух или более дисках.
В настоящем руководстве я покажу, как создать программный массив RAID 10, используя для этого пять одинаковых дисков по 8 ГБ. Хотя минимальное количество дисков для создания массива RAID 10 равно четырем (например, комплект с чередованием из двух зеркал), мы добавим дополнительный запасной диск на случай, если один из главных дисков выйдет из строя. Мы также будем пользоваться некоторыми инструментальными средствами, которые в дальнейшем можно будет применить для анализа производительности вашего массива RAID.
Пожалуйста, обратите внимание, что обсуждение вопросов о всех плюсах и минусах RAID 10 и других схем построения массивов дисков (с дисками разных размеров и разными файловыми системами) выходит за рамки этой статьи.
Как работает массив RAID 10?
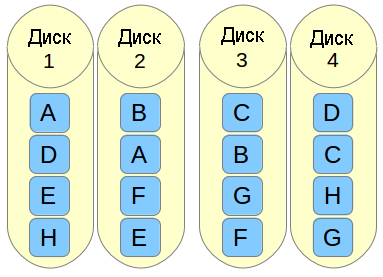
Если вам нужно реализовать решение по хранению данных, в котором поддерживаются интенсивные операции ввода / вывода (например, база данных, электронная почта и веб-серверы), то можно сделать с помощью RAID 10. Позвольте мне рассказать, каким образом это сделать. Обратимся к следующей картинке.
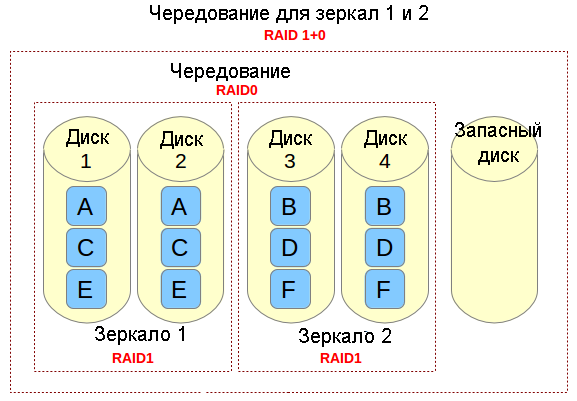
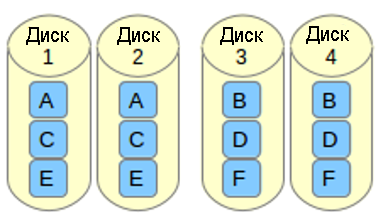
Представьте себе файл, который состоит из блоков данных A, B, C, D, E и F так, как это показано на рисунке выше. Каждый набор зеркал RAID-1 (например, Зеркало 1 или 2) реплицирует блоки на каждом из его двух устройств. Из-за такой конфигурации скорость записи уменьшается, поскольку каждый блок должен быть записан два раза, по одному разу для каждого диска, тогда как производительность по чтению остается неизменной по сравнению с чтением из отдельных дисков. Преимущество состоит в том, что при такой настройке обеспечивается избыточность, так что если произойдет сбой более чем с одним из дисков в каждом зеркале, будет сохранена поддержка выполнения обычных операций дискового ввода / вывода.
Чередование в RAID 0 представляет собой деление данных на блоки и одновременная запись блока A в зеркале 1, блока B в зеркале 2 (и так далее), что улучшает общую производительность чтения и записи. С другой стороны, ни в одном из зеркал не содержится вся информация любой части данных, если рассматривать весь основной набор данных. Это означает, что если сбой произойдет в одном из зеркал, то весь набор RAID 0 (и, следовательно, набор RAID 10) станет неработоспособным с безвозвратной утратой данных.
Настройка массива RAID 10
Есть два возможных способа настройки массива RAID 10: одношаговый (когда массив создается сразу) или последовательный (состоит из создания двух или большего количества массивов RAID 1, а затем использования их в качестве компонентов устройств в RAID 0). В этой статье мы рассмотрим одношаговый вариант создания массива RAID 10, поскольку он позволяет нам создавать массив из четного или нечетного количества дисков, и предоставляет возможность управлять массивом RAID как единым устройством, в отличие от последовательного варианта (в котором допускается только четное число дисков и управление будет осуществляется последовательно, по-отдельности для RAID 1 и RAID 0).
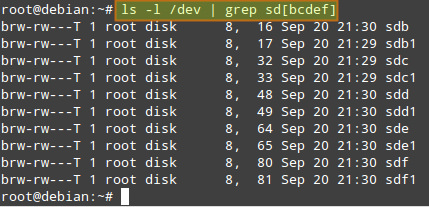
Предполагается, что вы установили пакет mdadm и в вашей системе работает демон. Подробности смотрите в следующем руководстве . Также предполагается, что на каждом диске был создан первичный раздел sd[bcdef]1. Таким образом, команда:
должна выдать следующий результат:
Давайте пойдем дальше и создадим массив RAID 10 с помощью следующей команды:

Когда массив создан (на это должно пойти более нескольких минут), то команда:
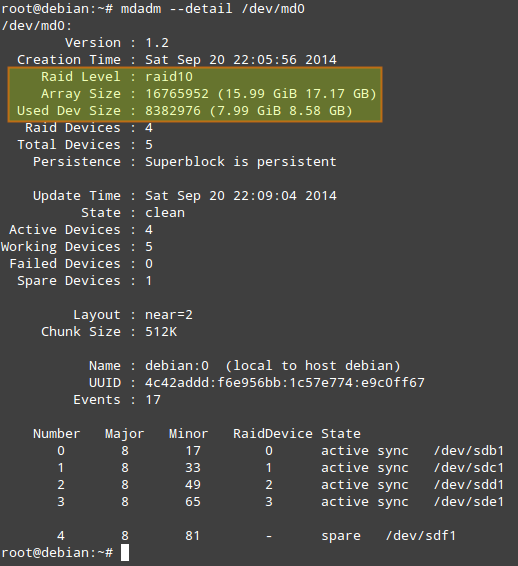
должна выдать следующий результат:
Прежде, чем мы продолжим, необходимо отметить следующее.
- Used Dev Space указывает для каждого устройства емкость, используемую под массив.
- Array Size указывает общий размер массива. Для массива RAID 10, это значение равно (N*C)/M, где N — количество активных устройств, C — емкость активных устройств, M — количество устройств в каждом зеркале. Таким образом, в данном случае (N*C)/M равно (4*8ГБ)/2 = 16ГБ.
- В Layout указываются конкретные особенности размещения данных. Возможные значения здесь следующие.
- n (параметр, используемый по умолчанию): означает near copies (близко расположенные копии). Различные копии одного и того же блока данных имеют в различных устройствах аналогичные смещения. Такая компоновка позволяет получить аналогичные скорости чтения и записи, как и в массиве RAID 0.
o означает offset copies (смещение копий). Вместо того, чтобы дублировать куски данных в отдельной полосе, дублируются целые полосы, но они на каждом устройстве сдвинуты, так что дублируемые блоки находятся на разных устройствах с разными смещениями. Т.е. следующая копия на следующем диске находится на один фрагмент данных дальше. Чтобы использовать эту компоновку в вашем массиве RAID 10, добавьте параметр —layout=o2 в команду, с помощью которой создается массив.
f означает far copies (копии с сильно различающимися смещениями). Такая компоновка обеспечивает более высокую производительность чтения, но худшую производительность записи. Таким образом, это самый лучший вариант для систем, в которых операции чтения должны выполняться гораздо чаще операций записи. Чтобы использовать эту компоновку в вашем массиве RAID 10, добавьте параметр —layout=f2 в команду, с помощью которой создается массив.
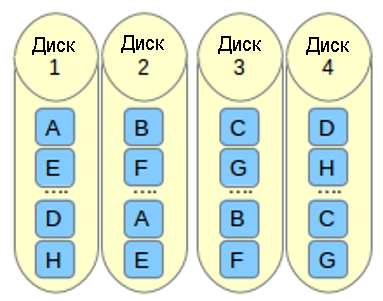
Число, которое расположено за n, f и o в параметре —layout, указывает какое количество копий необходимо для каждого блока данных. Это значение по умолчанию равно 2, но оно может быть в диапазоне от 2 и до числа, равному количеству устройств в массиве. Указывая правильное количество копий, вы можете минимизировать влияние операций ввода/вывода на каждый отдельный диск.
К сожалению, нет формулы расчета размера порции данных, которая бы позволила повысить производительность во всех случаях. Ниже приводится несколько рекомендаций, которые нужно учитывать.
- Файловая система: обычно считают, что лучшей является файловая система XFS, но хорошим выбором будет и EXT4.
- Оптимальная компоновка: когда порции данных расположены далеко друг от друга, то это улучшает производительность при чтении, но ухудшает производительность при записи.
- Количество копий: большее количество копий минимизирует влияние операций ввода / вывода, но увеличивает издержки, поскольку необходимо больше дисков.
- Аппаратура: SSD, скорее всего, будет обеспечивать большую производительность (при одних и тех же условиях), чем традиционные (шпиндельные) диски.
Тестируем производительность RAID при помощи DD
Для проверки производительности нашего массива RAID 10 (/dev/md0) можно использовать следующие тесты.
1. Операция записи
На устройство записывается один файл размером 256 МБ:
1000 раз записываются 512 байта:
Когда установлен флаг dsync, то команда dd не использует кэш файловой системы и выполняет синхронизированную запись в массив RAID. Этот флаг используется для устранения эффекта кэширования во время тестирования производительности RAID.
2. Операция чтения
256KiB*15000 (3.9 GB) копируются из массива в /dev/null:
Тестируем производительность RAID при помощи Iozone
Iozone является инструментальным средством тестирования, с помощью которого можно измерять различные дисковые операции ввода/вывода, в том числе чтение/запись в случайном порядке, последовательное чтение/запись и повторное чтение/повторную запись. Он позволяет экспортировать результаты в файл Microsoft Excel или LibreOffice Calc.
Установка пакета Iozone на CentOS/RHEL 7
Установка пакета Iozone на Debian 7
Команда iozone, указанная ниже, выполнит все тесты с массивом RAID-10:
- -R: генерирует результат в виде отчета в формате, совместимом с Excel.
- -a: запускает команду iozone в полностью автоматическом режиме с выполнением всех тестов и с записью записей/файлов всех необходимых размеров. Размеры записей: 4k-16M; и размеры файлов: 64k-512М.
- -b /tmp/md0.xls: указывает сохранять результаты тестирования в определенном файле.
Надеюсь, что эта статья окажется полезной. Вы можете добавить свои размышления или посоветовать, как улучшить производительность RAID 10.
Источник
How to create RAID 10 – Striped Mirror Vdev ZPool On Ubuntu Linux
Before you get started
First, obviously, you want to make sure zfs is installed, run the following command:
$ sudo apt update
$ sudo apt install zfsutils-linux
Create striped mirrored VDEVs (RAID 10)
The syntax is:
sudo zpool create NAME mirror VDEV1 VDEV2 mirror VDEV3 VDEV4
or:
sudo zpool create NAME mirror VDEV1 VDEV2
sudo zpool add NAME mirror VDEV3 VDEV4
A VDE can be a raw disk, a file/image, or a partition.
Step – 1: Find device name
In this example, I’m going to create a striped mirrored Vdev Zpool using four physical disk. It is recommended that you use /dev/disk/by-id/ disk names, which often use serial numbers of drives. Type the following command to find out find the disks that you have in your system:
$ ls -l /dev/disk/by-id/ | grep sd[a-z]$
Sample outputs:
Fig.01: Linux find disk names by serial number using /dev/disk/by-id/
Step -2: Create a 2 x 2 mirrored pool using four raw disks
You can use wwn-0x50011731002b33ac (sda), wwn-0x50011731002b50d0 (sdb), wwn-0x5001173100406557 (sdc), and wwn-0x50011731004085a7 (sdd) as follows to create a zpool containing a VDEV of 4 drives in a mirror i.e. a 2 x 2 mirrored pool:
$ sudo zpool create tank0 mirror wwn-0x50011731002b33ac wwn-0x50011731002b50d0 mirror wwn-0x5001173100406557 wwn-0x50011731004085a7
OR: use the following syntax, to create a zpool called foo containing a VDEV of 2 drives in a mirror:
$ sudo zpool create foo mirror wwn-0x50011731002b33a wwn-0x50011731002b50d0
Next, add another VDEV of 2 drives in a mirror to the pool:
$ sudo zpool add foo mirror wwn-0x5001173100406557 wwn-0x50011731004085a7 -f
Another example: Create a 2 x 2 mirrored pool using four partitions
Use the following command to list the partitions:
$ ls -l /dev/disk/by-id/ | grep sd[a-z]8$
Use serial number-partition format to create a zpool containing a VDEV of 4 drives in a mirror:
$ sudo zpool create cartwheel mirror wwn-0x5001173100406557-part1 wwn-0x50011731004085a7-part1 -f
$ sudo zpool add cartwheel mirror wwn-0x50011731002b50d0-part1 wwn-0x50011731002b33ac-part8 -f
Finally, execute the following command to make sure it was created on the system:
$ zpool status
$ zpool list
$ df -H
Sample outputs:
Fig.02: See pool’s health status
To destroy both file systems from the pool called cartwheel, run:
$ sudo zfs destroy cartwheel/salesdata
$ sudo zfs destroy cartwheel/lxccontainers
$ sudo zfs list
- No ads and tracking
- In-depth guides for developers and sysadmins at Opensourceflare✨
- Join my Patreon to support independent content creators and start reading latest guides:
- How to set up Redis sentinel cluster on Ubuntu or Debian Linux
- How To Set Up SSH Keys With YubiKey as two-factor authentication (U2F/FIDO2)
- How to set up Mariadb Galera cluster on Ubuntu or Debian Linux
- A podman tutorial for beginners – part I (run Linux containers without Docker and in daemonless mode)
- How to protect Linux against rogue USB devices using USBGuard
Join Patreon ➔
How do I delete a zpool and all data stored in the pool called cartwheel?
$ sudo zpool destroy zpoolNameHere
$ sudo zpool destroy cartwheel
$ zpool status
🐧 Get the latest tutorials on Linux, Open Source & DevOps via
Источник
Работа с mdadm в Linux для организации RAID
mdadm — утилита для работы с программными RAID-массивами различных уровней. В данной инструкции рассмотрим примеры ее использования.
Установка mdadm
Утилита mdadm может быть установлена одной командой.
Если используем CentOS / Red Hat:
yum install mdadm
Если используем Ubuntu / Debian:
apt-get install mdadm
Сборка RAID
Перед сборкой, стоит подготовить наши носители. Затем можно приступать к созданию рейд-массива.
Подготовка носителей
Сначала необходимо занулить суперблоки на дисках, которые мы будем использовать для построения RAID (если диски ранее использовались, их суперблоки могут содержать служебную информацию о других RAID):
mdadm —zero-superblock —force /dev/sd
* в данном примере мы зануляем суперблоки для дисков sdb и sdc.
Если мы получили ответ:
mdadm: Unrecognised md component device — /dev/sdb
mdadm: Unrecognised md component device — /dev/sdc
. то значит, что диски не использовались ранее для RAID. Просто продолжаем настройку.
Далее нужно удалить старые метаданные и подпись на дисках:
wipefs —all —force /dev/sd
Создание рейда
Для сборки избыточного массива применяем следующую команду:
mdadm —create —verbose /dev/md0 -l 1 -n 2 /dev/sd
- /dev/md0 — устройство RAID, которое появится после сборки;
- -l 1 — уровень RAID;
- -n 2 — количество дисков, из которых собирается массив;
- /dev/sd — сборка выполняется из дисков sdb и sdc.
Мы должны увидеть что-то на подобие:
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store ‘/boot’ on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
—metadata=0.90
mdadm: size set to 1046528K
Также система задаст контрольный вопрос, хотим ли мы продолжить и создать RAID — нужно ответить y:
Continue creating array? y
Мы увидим что-то на подобие:
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.
. и находим информацию о том, что у наших дисков sdb и sdc появился раздел md0, например:
.
sdb 8:16 0 2G 0 disk
??md0 9:0 0 2G 0 raid1
sdc 8:32 0 2G 0 disk
??md0 9:0 0 2G 0 raid1
.
* в примере мы видим собранный raid1 из дисков sdb и sdc.
Создание файла mdadm.conf
В файле mdadm.conf находится информация о RAID-массивах и компонентах, которые в них входят. Для его создания выполняем следующие команды:
echo «DEVICE partitions» > /etc/mdadm/mdadm.conf
mdadm —detail —scan —verbose | awk ‘/ARRAY/
DEVICE partitions
ARRAY /dev/md0 level=raid1 num-devices=2 metadata=1.2 name=proxy.dmosk.local:0 UUID=411f9848:0fae25f9:85736344:ff18e41d
* в данном примере хранится информация о массиве /dev/md0 — его уровень 1, он собирается из 2-х дисков.
Создание файловой системы и монтирование массива
Создание файловой системы для массива выполняется также, как для раздела:
* данной командой мы создаем на md0 файловую систему ext4.
Примонтировать раздел можно командой:
mount /dev/md0 /mnt
* в данном случае мы примонтировали наш массив в каталог /mnt.
Чтобы данный раздел также монтировался при загрузке системы, добавляем в fstab следующее:
/dev/md0 /mnt ext4 defaults 1 2
Для проверки правильности fstab, вводим:
Мы должны увидеть примонтированный раздел md, например:
/dev/md0 990M 2,6M 921M 1% /mnt
Информация о RAID
Посмотреть состояние всех RAID можно командой:
В ответ мы получим что-то на подобие:
md0 : active raid1 sdc[1] sdb[0]
1046528 blocks super 1.2 [2/2] [UU]
* где md0 — имя RAID устройства; raid1 sdc[1] sdb[0] — уровень избыточности и из каких дисков собран; 1046528 blocks — размер массива; [2/2] [UU] — количество юнитов, которые на данный момент используются.
** мы можем увидеть строку md0 : active(auto-read-only) — это означает, что после монтирования массива, он не использовался для записи.
Подробную информацию о конкретном массиве можно посмотреть командой:
* где /dev/md0 — имя RAID устройства.
Version : 1.2
Creation Time : Wed Mar 6 09:41:06 2019
Raid Level : raid1
Array Size : 1046528 (1022.00 MiB 1071.64 MB)
Used Dev Size : 1046528 (1022.00 MiB 1071.64 MB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Wed Mar 6 09:41:26 2019
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : proxy.dmosk.local:0 (local to host proxy.dmosk.local)
UUID : 304ad447:a04cda4a:90457d04:d9a4e884
Events : 17
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
- Version — версия метаданных.
- Creation Time — дата в время создания массива.
- Raid Level — уровень RAID.
- Array Size — объем дискового пространства для RAID.
- Used Dev Size — используемый объем для устройств. Для каждого уровня будет индивидуальный расчет: RAID1 — равен половине общего размера дисков, RAID5 — равен размеру, используемому для контроля четности.
- Raid Devices — количество используемых устройств для RAID.
- Total Devices — количество добавленных в RAID устройств.
- Update Time — дата и время последнего изменения массива.
- State — текущее состояние. clean — все в порядке.
- Active Devices — количество работающих в массиве устройств.
- Working Devices — количество добавленных в массив устройств в рабочем состоянии.
- Failed Devices — количество сбойных устройств.
- Spare Devices — количество запасных устройств.
- Consistency Policy — политика согласованности активного массива (при неожиданном сбое). По умолчанию используется resync — полная ресинхронизация после восстановления. Также могут быть bitmap, journal, ppl.
- Name — имя компьютера.
- UUID — идентификатор для массива.
- Events — количество событий обновления.
- Chunk Size (для RAID5) — размер блока в килобайтах, который пишется на разные диски.
Подробнее про каждый параметр можно прочитать в мануале для mdadm:
Также, информацию о разделах и дисковом пространстве массива можно посмотреть командой fdisk:
Источник



