- Как сравнить двоичные файлы в Linux?
- 14 ответов
- Как сравнить двоичные файлы в Linux?
- 14 ответов 14
- Как сравнить двоичные файлы в Linux?
- diff + xxd
- colordiff + xxd
- vimdiff + xxd
- Сравнение файлов в Linux
- Сравнение файлов diff
- Сравнение файлов Linux с помощью GUI
- 1. Kompare
- 2. Meld
- 3. Diffuse
- 4. KDiff3
- 5. TkDiff
- Выводы
- Diff of two similar big raw binary files
- 5 Answers 5
Как сравнить двоичные файлы в Linux?
мне нужно сравнить два двоичных файла и получить вывод в виде
для каждого байта. Так если file1.bin is
в двоичной форме и file2.bin is
Я хочу получить что-то вроде
каков самый простой способ достижения цели? Стандартный инструмент? Какой-то сторонний инструмент?
(Примечание: cmp -l должны быть убиты огонь, он использует десятичную систему для смещений и восьмеричную для байтов.)
14 ответов
это выведет смещение и байты в hex:
или -1 , чтобы первое печатное смещение начиналось с 0.
к сожалению, strtonum() специфичен для GAWK, поэтому для других версий awk-например, mawk-вам нужно будет использовать функцию преобразования восьмеричного в десятичное число. Например,
сломанный вне для считываемости:
попробовать diff в следующей комбинации замещения процесса zsh/bash и colordiff в CLI:
- -y показывает вам различия бок о бок (необязательно)
- xxd является инструментом CLI для создания вывода шестнадцатеричного двоичного файла
- colordiff будет раскрасить diff вывод (установка через: sudo apt-get install colordiff )
- добавить -W200 to diff шире вывод
- если файлы большие, добавьте ограничение (например, -l1000 ) для каждого xxd
есть инструмент DHEX, которые могут сделать работу, и есть еще один инструмент под названием VBinDiff.
для строго командной строки, попробуйте JDIFF.
метод, который работает для добавления / удаления байтов
создать тестовый случай с одним удалением байта 64:
если вы также хотите увидеть ASCII версию символа:
протестировано на Ubuntu 16.04.
предпочитаю od over xxd потому что:
- it is POSIX, xxd нет (поставляется с Vim)
- имеет -An удалить столбец адреса без awk .
Источник
Как сравнить двоичные файлы в Linux?
Мне нужно сравнить два двоичных файла и получить вывод в виде:
за каждый другой байт. Так что если file1.bin
в двоичном виде и file2.bin
Я хочу получить что-то вроде
Есть ли способ сделать это в Linux? Я знаю о cmp -l но он использует десятичную систему для смещений и восьмеричную для байтов, которых я хотел бы избежать.
14 ответов 14
Это напечатает смещение и байты в шестнадцатеричном виде:
Или введите $1-1 чтобы первое напечатанное смещение начиналось с 0.
К сожалению, strtonum() специфичен для GAWK, поэтому для других версий awk — например, mawk — вам потребуется использовать функцию преобразования восьмеричного числа в десятичное. Например,
Вычеркнуто для удобства чтения:
Как сказал Кряк :
Попробуйте использовать diff в следующей комбинации замены процесса zsh/bash и colordiff в CLI:
- -y показывает различия между собой (необязательно)
- xxd — это инструмент CLI для создания шестнадцатеричного вывода двоичного файла
- colordiff раскрасит вывод diff (установите с помощью: sudo apt-get install colordiff )
- добавить -W200 к diff для более широкого вывода (по 200 символов в строке)
- если файлы слишком большие, добавьте ограничение (например, -l1000 ) для каждого xxd
Есть инструмент под названием DHEX, который может сделать эту работу, и есть другой инструмент, который называется VBinDiff.
Для строго командной строки попробуйте JDIFF.
Метод, который работает для добавления / удаления байтов
Сгенерируйте тестовый пример с единственным удалением байта 64:
Если вы также хотите увидеть ASCII-версию персонажа:
Проверено на Ubuntu 16.04.
Я предпочитаю od xxd потому что:
- это POSIX, а xxd нет (поставляется с Vim)
- имеет -An для удаления столбца адреса без awk .
Источник
Как сравнить двоичные файлы в Linux?
Мне нужно сравнить два двоичных файла и получить вывод в виде:
за каждый другой байт. Так что, если file1.bin есть
в двоичном виде и file2.bin является
Я хочу получить что-то вроде
Есть ли способ сделать это в Linux? Я знаю, cmp -l но он использует десятичную систему для смещений и восьмеричную для байтов, которых я хотел бы избежать.
Это выведет смещение и байты в шестнадцатеричном виде:
Или сделать так, $1-1 чтобы первое напечатанное смещение начиналось с 0.
К сожалению, strtonum() это специфично для GAWK, поэтому для других версий awk — например, mawk — вам нужно будет использовать функцию преобразования восьмеричного числа в десятичное. Например,
Вычеркнуто для удобства чтения:
Как сказал Кряк :
diff + xxd
Попробуйте diff использовать следующую комбинацию подстановки zsh / bash:
- -y показывает различия между собой (необязательно).
- xxd инструмент CLI для создания шестнадцатеричного вывода двоичного файла
- Добавить -W200 к diff для более широкого выхода (из 200 символов в строке).
- Для цветов используйте colordiff как показано ниже.
colordiff + xxd
Если у вас есть colordiff , он может раскрасить diff вывод, например:
В противном случае установить через: sudo apt-get install colordiff .
vimdiff + xxd
Вы также можете использовать vimdiff , например,
- если файлы слишком большие, добавьте ограничение (например -l1000 ) для каждого xxd
Есть инструмент под названием DHEX, который может сделать эту работу, и есть другой инструмент, который называется VBinDiff .
Для строго командной строки, попробуйте jojodiff .
Метод, который работает для добавления / удаления байтов
Создайте тестовый пример с единственным удалением байта 64:
Если вы также хотите увидеть ASCII-версию персонажа:
Проверено на Ubuntu 16.04.
Я предпочитаю od более , xxd потому что:
- это POSIX , xxd нет (поставляется с Vim)
- имеет, -An чтобы удалить столбец адреса без awk .
Источник
Сравнение файлов в Linux
Иногда возникает необходимость сравнить несколько файлов между собой. Это может понадобиться при анализе разницы между несколькими версиями конфигурационного файла или просто для сравнения различных файлов. В Linux для этого есть несколько утилит, как для работы через терминал, так и в графическом интерфейсе.
В этой статье мы рассмотрим как выполняется сравнение файлов Linux. Разберем самые полезные способы, как для терминала, так и в графическом режиме. Сначала рассмотрим как выполнять сравнение файла linux с помощью утилиты diff.
Сравнение файлов diff
Утилита diff linux — это программа, которая работает в консольном режиме. Ее синтаксис очень прост. Вызовите утилиту, передайте нужные файлы, а также задайте опции, если это необходимо:
$ diff опции файл1 файл2
Можно передать больше двух файлов, если это нужно. Перед тем как перейти к примерам, давайте рассмотрим опции утилиты:
- -q — выводить только отличия файлов;
- -s — выводить только совпадающие части;
- -с — выводить нужное количество строк после совпадений;
- -u — выводить только нужное количество строк после отличий;
- -y — выводить в две колонки;
- -e — вывод в формате ed скрипта;
- -n — вывод в формате RCS;
- -a — сравнивать файлы как текстовые, даже если они не текстовые;
- -t — заменить табуляции на пробелы в выводе;
- -l — разделить на страницы и добавить поддержку листания;
- -r — рекурсивное сравнение папок;
- -i — игнорировать регистр;
- -E — игнорировать изменения в табуляциях;
- -Z — не учитывать пробелы в конце строки;
- -b — не учитывать пробелы;
- -B — не учитывать пустые строки.
Это были основные опции утилиты, теперь давайте рассмотрим как сравнить файлы Linux. В выводе утилиты кроме, непосредственно, отображения изменений, выводит строку в которой указывается в какой строчке и что было сделано. Для этого используются такие символы:
- a — добавлена;
- d — удалена;
- c — изменена.
К тому же, линии, которые отличаются, будут обозначаться символом .
Вот содержимое наших тестовых файлов:

Теперь давайте выполним сравнение файлов diff:
diff file1 file2

В результате мы получим строчку: 2,3c2,4. Она означает, что строки 2 и 3 были изменены. Вы можете использовать опции для игнорирования регистра:
diff -i file1 file2
Можно сделать вывод в две колонки:
diff -y file1 file2

А с помощью опции -u вы можете создать патч, который потом может быть наложен на такой же файл другим пользователем:
diff -u file1 file2

Чтобы обработать несколько файлов в папке удобно использовать опцию -r:

Для удобства, вы можете перенаправить вывод утилиты сразу в файл:
diff -u file1 file2 > file.patch

Как видите, все очень просто. Но не очень удобно. Более приятно использовать графические инструменты.
Сравнение файлов Linux с помощью GUI
Существует несколько отличных инструментов для сравнения файлов в linux в графическом интерфейсе. Вы без труда разберетесь как их использовать. Давайте рассмотрим несколько из них:
1. Kompare
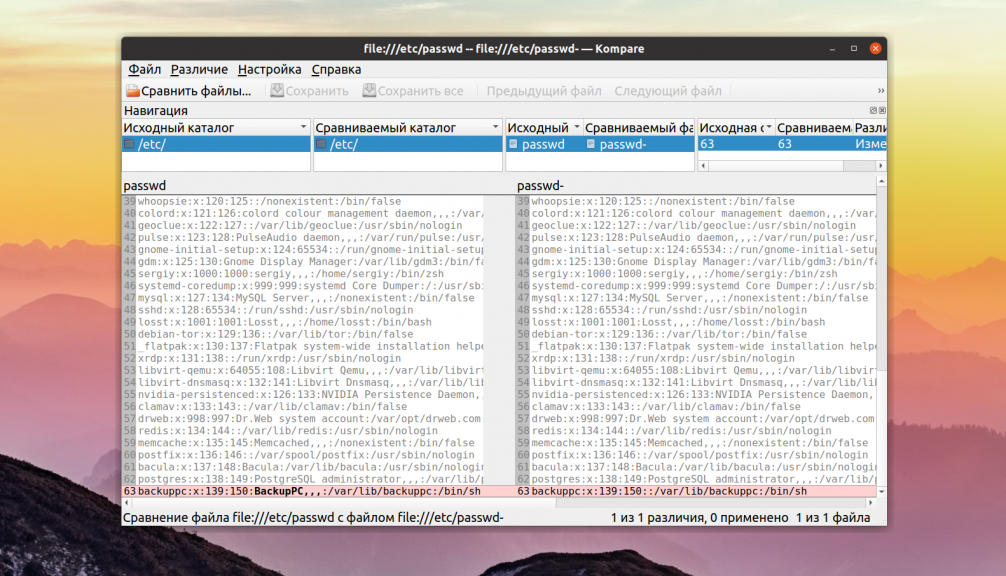
Kompare — это графическая утилита для работы с diff, которая позволяет находить отличия в файлах, а также объединять их. Написана на Qt и рассчитана в первую очередь на KDE. Кроме сравнения файлов утилита поддерживает сравнение каталогов и позволяет создавать и применять патчи к файлам.
2. Meld
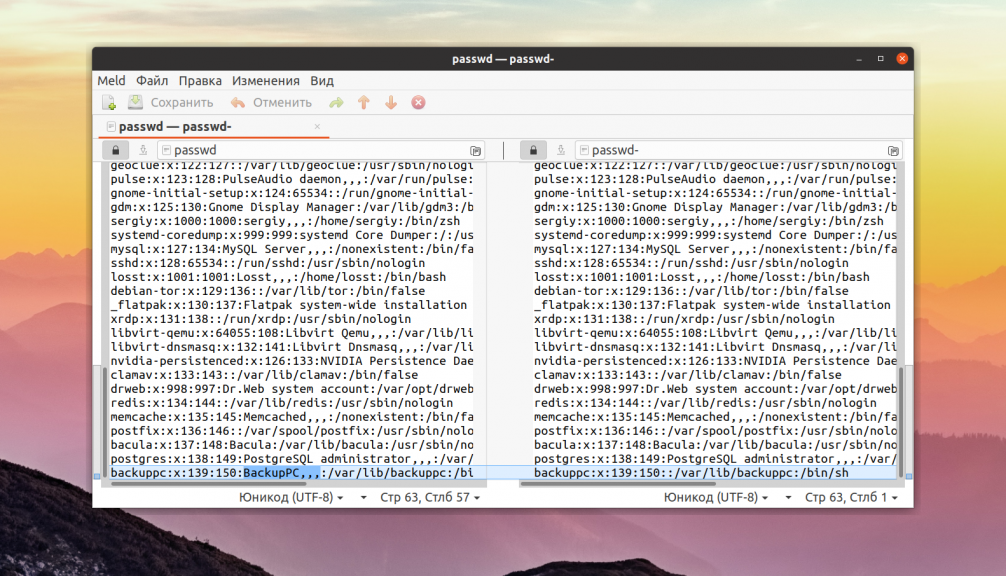
Это легкий инструмент для сравнения и объединения файлов. Он позволяет сравнивать файлы, каталоги, а также выполнять функции системы контроля версий. Программа создана для разработчиков и позволяет сравнивать до трёх файлов. Можно сравнивать каталоги и автоматически объединять сравниваемые файлы. Кроме того поддерживаются такие системы контроля версий, как Git.
3. Diffuse
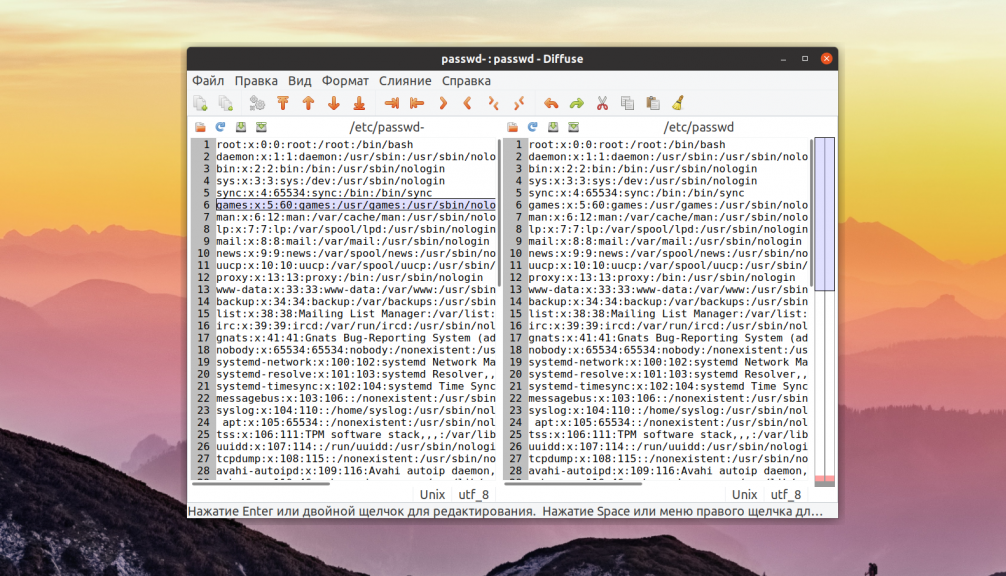
Diffuse — еще один популярный и достаточно простой инструмент для сравнения и слияния файлов. Он написан на Python 2. Поэтому в современных версиях Ubuntu программу будет сложно установить. Поддерживается две основные возможности — сравнение файлов и управление версиями. Вы можете редактировать файлы прямо во время просмотра.
4. KDiff3
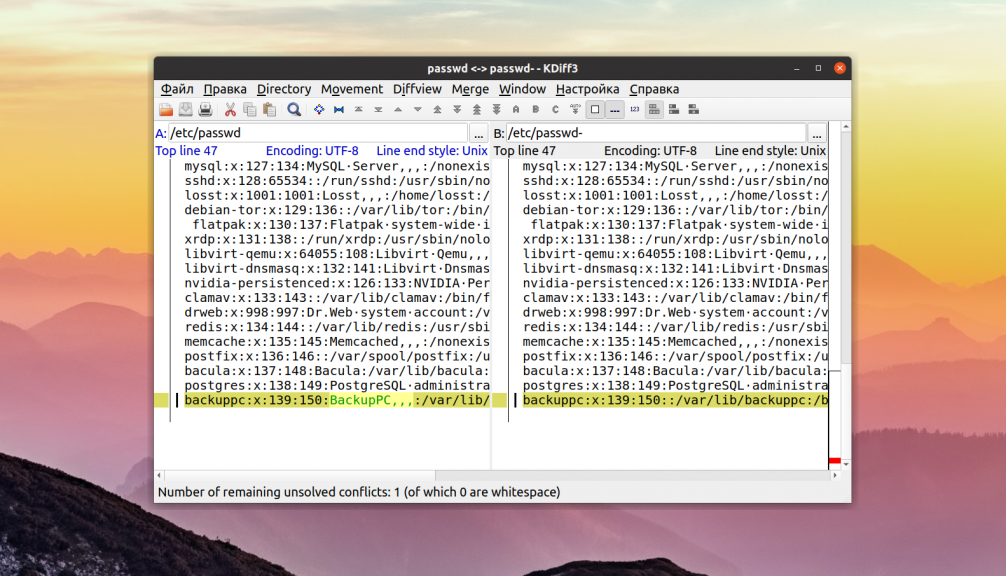
KDiff3 — еще один отличный, свободный инструмент для сравнения файлов в окружении рабочего стола KDE. Он входит в набор программ KDevelop и работает на всех платформах, включая Windows и MacOS. Можно выполнить сравнение до трех файлов Linux или даже сравнить каталоги. Кроме того, есть поддержка слияния и ручного выравнивания.
5. TkDiff
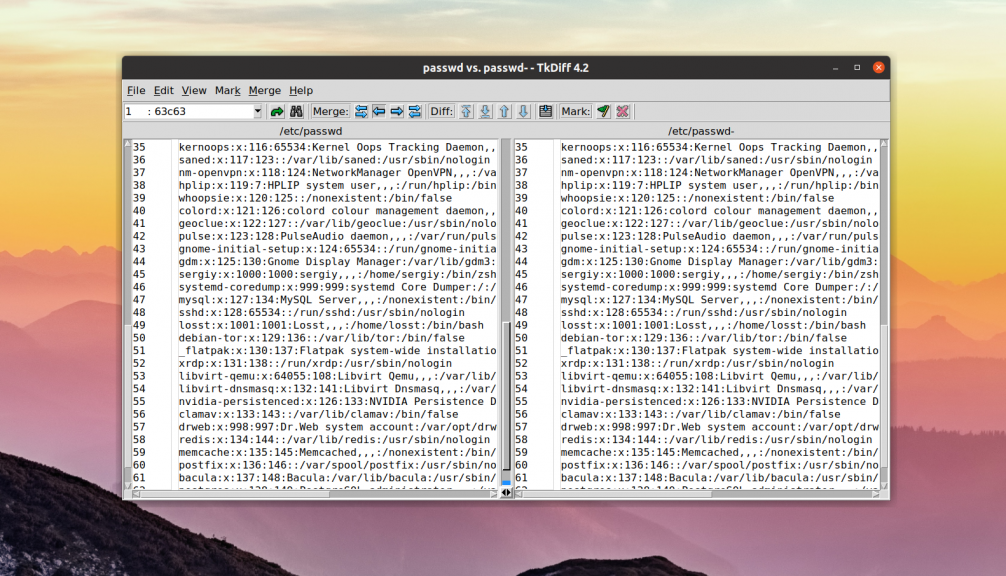
Это очень простая утилита для сравнения файлов написанная на основе библиотеки tk. Она позволяет сравнивать только два файла, поддерживает поиск и редактирование сравниваемых файлов.
Выводы
В этой статье мы рассмотрели как выполняется сравнение файлов linux с помощью терминала, как создавать патчи, а также сделали небольшой обзор лучших графических утилит для сравнения файлов. А какие инструменты для сравнения используете вы? Напишите в комментариях!
Источник
Diff of two similar big raw binary files
Let’s say I have a 4 GB file abc on my local computer. I have uploaded it to a distant server via SFTP, it took a few hours.
Now I have slightly modified the file (probably 50 MB maximum, but not consecutive bytes in this file) locally, and saved it into abc2 . I also kept the original file abc on my local computer.
How to compute a binary diff of abc and abc2 ?
I could only send a patch file (probably max 100MB) to the distant server, instead of reuploading the whole abc2 file (it would take a few hours again!), and recreate abc2 on the distant server from abc and patch only.
Locally, instead of wasting 8 GB to backup both abc and abc2 , I could save only abc + patch , so it would take diff , but here I’m looking for something that could work for any raw binary format, it could be zip files or executables or even other types of file.
PS2: If possible, I don’t want to use rsync ; I know it can replicate changes between 2 computers in an efficient way (not resending data that has not changed), but here I really want to have a patch file, that is reproducible later if I have both abc and patch .
5 Answers 5
For the second application/issue, I would use a deduplicating backup program like restic or borgbackup , rather than trying to manually keep track of «patches» or diffs. The restic backup program allows you to back up directories from multiple machines to the same backup repository, deduplicating the backup data both amongst fragments of files from an individual machine as well as between machine. (I have no user experience with borgbackup , so I can’t say anything about that program.)
Calculating and storing a diff of the abc and abc2 files can be done with rsync .
This is an example with abc and abc2 being 153 MB. The file abc2 has been modified by overwriting the first 2.3 MB of the file with some other data:
We create out patch for transforming abc into abc2 and call it abc-diff :
The generated file abc-diff is the actual diff (your «patch file»), while abc-diff.sh is a short shell script that rsync creates for you:
This script modifies abc so that it becomes identical to abc2 , given the file abc-diff :
The file abc-diff could now be transferred to wherever else you have abc . With the command rsync —read-batch=abc-diff abc , you would apply the patch to the file abc , transforming its contents to be the same as the abc2 file on the system where you created the diff.
Re-applying the patch a second time seems safe. There is no error messages nor does the file’s contents change (the MD5 checksum does not change).
Note that unless you create an explicit «reverse patch», there is no way to easily undo the application of the patch.
I also tested writing the 2.3 MB modification to some other place in the abc2 data, a bit further in (at about 50 MB), as well as at the start. The generated «patch» was 4.6 MB large, suggesting that only the modified bits were stored in the patch.
Источник



