- Как скачать файл в Linux через терминал
- Команда wget
- Команда curl
- How to Download Files from the Linux Command Line
- How to Download a File on Ubuntu Linux using the Command Line
- Download files using Curl
- Install curl
- Download and save the file using the source file name
- Download and save the file with a different name
- Download multiple files
- Download files from an FTP Server
- Pause and resume download
- Download files using Wget
- Install wget
- Download file or webpage using wget
- Download files with a different name
- Download files through FTP
- Recursively download files
- Download multiple files
- Pause and Resume download
- Karim Buzdar
Как скачать файл в Linux через терминал
Не редко при настройке сервера на Linux возникает необходимость в скачивании файлов. Например, это могут быть какие-то архивы или скрипты. Для решения такой задачи необходимо уметь скачивать файлы прямо через терминал Linux. В этой инструкции мы рассмотрим две команды, которые чаще всего используются для скачивания файлов через терминал Linux.
Команда wget
Wget – это мощная утилита для скачивания файлов, с ее помощью можно загружать файлы по протоколам HTTP, HTTPS и FTP. При этом поддерживается скачивание с использованием прокси, а также работа в фоновом режиме.
Кроме этого, с помощью wget можно скачивать веб страницы или даже целые веб-сайты. Для этого используется рекурсивный обход всех найденных на странице ссылок и создание локальной копии сайта с воссозданием его структуры.
Wget хорошо работает с медленным или нестабильным подключением к интернету. В случае разрыва соединения wget будет повторять попытки скачивания до тех пор, пока весь файл не будет загружен. При этом продолжение загрузки будет начинаться с того места, где она остановилась.
Синтаксис команды wget выглядит следующим образом:
Утилита wget доступна на большинстве дистрибутивов Linux. Но, если в вашей системе ее нет, то вы можете установить ее самостоятельно. В Ubuntu для этого нужно выполнить команду:
В общем случае для скачивания файла через терминал Linux достаточно ввести команду « wget » и через пробел указать URL адрес, после чего начнется загрузка указанного документа. Например, команда на скачивание файла может выглядеть вот так:
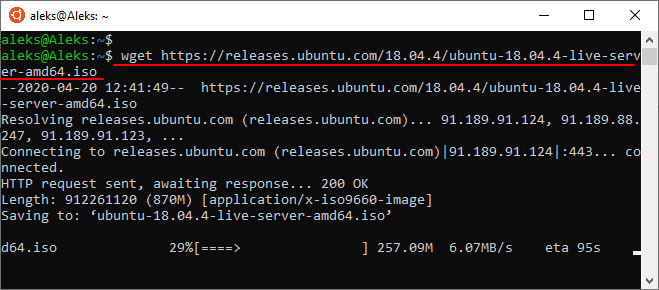
Если нужно скачать несколько файлов подряд, то их адреса можно передать утилите wget за один раз. Для этого просто указываем их через пробел. Например:
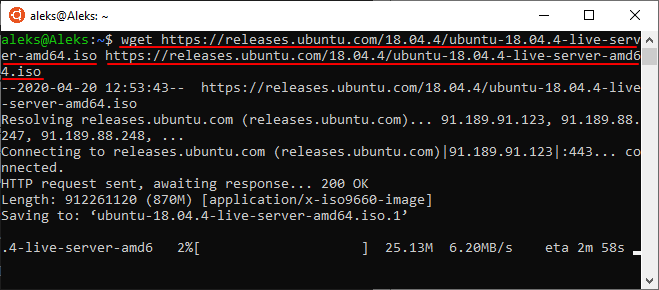
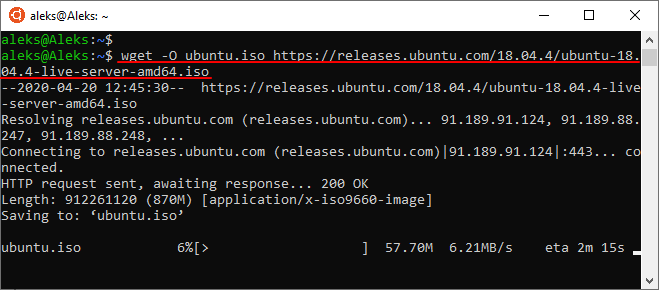
При необходимости, для скачиваемого файла можно указать новое название. Для этого нужно использовать опцию « -O ». В этом случае команда для скачивания файла будет выглядеть так:
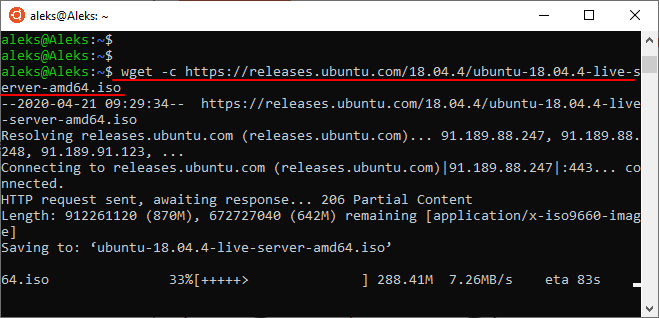
В случае прерывания загрузки ее можно продолжить. Для этого нужно запустить команду wget еще раз, но в этот раз с добавлением опции « -c ». Команда перезапуска загрузки выглядит примерно так:
Если во время скачивания файла вы хотите продолжить работу с терминалом Linux, то загрузку можно выполнить в фоновом режиме. Для этого нужно использовать опцию « -b ». Команда для скачивания файла в фоновом режиме выглядит примерно так:

Это основные опции команды « wget », которые используются чаще всего. Для того чтобы ознакомиться со всеми доступными опциями введите команду « man wget ».
Команда curl
Curl – еще одна мощная утилита для скачивания файлов, которая доступна из терминала Linux. С ее помощью можно скачивать файлы по протоколам HTTP, HTTPS, FTP, FTPS, TFTP, Telnet, SCP, SFTP, DICT, LDAP, а также POP3, IMAP и SMTP. Также curl поддерживает работу через прокси, веб-аутентификацию, отправку данных через http, работу с cookie-файлами и многое другое.
Синтаксис команды curl выглядит следующим образом:
Команда curl может отсутствовать в вашем дистрибутиве Linux. Но, вы можете установить ее самостоятельно. В Ubuntu для этого нужно выполнить следующую команду:
По умолчанию, команда curl выводит скачанное прямо в терминал. Это может быть полезно в некоторых случаях, но чаще всего требуется сохранение скачанного в виде файла. Для этого следует использовать опцию « -O ». Например, команда на скачивание файла с помощью curl может выглядеть примерно так:
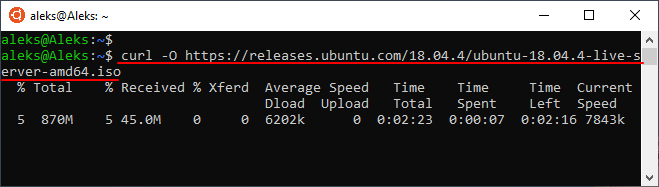
Если нужно скачать сразу несколько файлов, то их можно указать через пробел один за другим. При этом для каждого из файлов нужно указать опцию « -O ». Выглядит это примерно так:
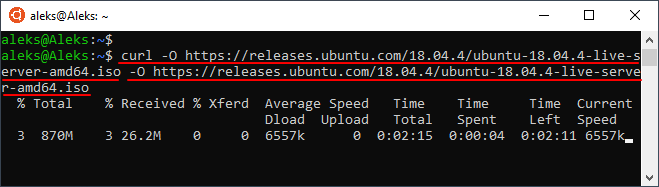
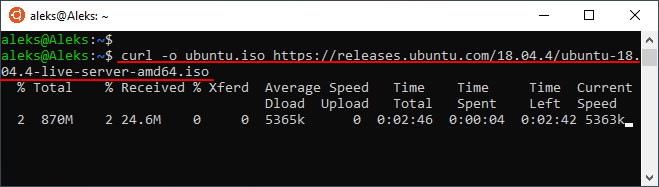
При желании можно изменить имя для скачиваемого файла. Для этого нужно использовать опцию « -o » и после нее указать новое имя для файла. Например:
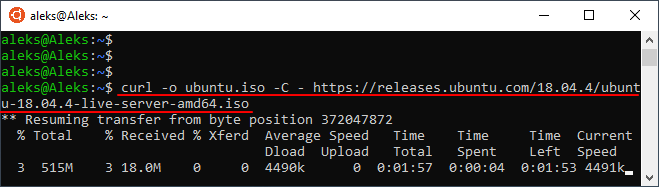
Если загрузка была прервана, то ее можно продолжить с того места, где она остановилась. Для этого нужно еще раз выполнить команду « curl », но с добавлением опции « -C — ». Например:
Это основные опции команды « curl », которые применяются чаще всего. Для того чтобы посмотреть все доступные опции выполните команду « man curl ».
Источник
How to Download Files from the Linux Command Line
This guide will teach you step by step how to download files from the command line in Linux, Windows or macOS using open source (free) software – wget. Wget is a very cool command-line downloader for Linux and UNIX environments that has also been ported to Windows and macOS. Don’t be fooled by the fact that it is a command line tool. It is very powerful and versatile and can match some of the best graphical downloaders around today. It has features such as resuming of downloads, bandwidth control, it can handle authentication, and much more. I’ll get you started with the basics of using wget and then I’ll show you how you can automate a complete backup of your website using wget and cron.
Let’s get started by installing wget. Most Linux distributions come with wget pre-installed. If you manage to land yourself a Linux machine without a copy of wget try the following. On a Red Hat Linux based system such a Fedora you can use:
# yum install wget
or if you use a Debian based system like Ubuntu:
# sudo apt-get install wget
One of the above should do the trick for you. Otherwise, check with your Linux distribution’s manual to see how to get and install packages. Users on Windows can access wget via this website, and for Mac users we have a full guide on how to install wget in macOS.
The most basic operation a download manager needs to perform is to download a file from a URL. Here’s how you would use wget to download a file:
# wget https://www.simplehelp.net/images/file.zip
Yes, it’s that simple. Now let’s do something more fun. Let’s download an entire website. Here’s a taste of the power of wget. If you want to download a website you can specify the depth that wget must fetch files from. Say you want to download the first level links of Yahoo!’s home page. Here’s how would do that:
# wget -r -l 1 https://www.yahoo.com/
Here’s what each options does. The -r activates the recursive retrieval of files. The -l stands for level, and the number 1 next to it tells wget how many levels deep to go while fetching the files. Try increasing the number of levels to two and see how much longer wget takes.
Now if you want to download all the “jpeg” images from a website, a user familiar with the Linux command line might guess that a command like “wget http://www.sevenacross.com*.jpeg” would work. Well, unfortunately, it won’t. What you need to do is something like this:
# wget -r -l1 –no-parent -A.jpeg https://www.yahoo.com
Another very useful option in wget is the resumption of a download. Say you started downloading a large file and you lost your Internet connection before the download could complete. You can use the -c option to continue your download from where you left it.
# wget -c http://www.example_url.com/ubuntu-live.iso
Now let’s move on to setting up a daily backup of a website. The following command will create a mirror of a site in your local disk. For this purpose wget has a specific option, –mirror. Try the following command, replacing sevenacross.com with your website’s address.
# wget –mirror http://www.sevenacross.com/
When the command is done running you should have a local mirror of your website. This make for a pretty handy tool for backups. Let’s turn this command into a cool shell script and schedule it to run at midnight every night. Open your favorite text editor and type the following. Remember to adapt the path of the backup and the website URL to your requirements.
BACKUP_PATH=`/home/backup/` # replace path with your backup directory
WEBSITE_URL=`http://www.sevenacross.net` # replace url with the address of the website you want to backup
# Create and move to backup directory
cd $BACKUP_PARENT_DIR/$YEAR/$MONTH
mkdir $DAY
cd $DAY
Now save this file as something like website_backup.sh and grant it executable permissions:
# chmod +x website_backup.sh
Open your cron configuration with the crontab command and add the following line at the end:
0 0 * * * /path/to/website_backup.sh
You should have a copy of your website in /home/backup/YEAR/MONTH/DAY every day. For more help using cron and crontab, see this tutorial.
Now that you get the basics of downloading files from the command line you can get into the advanced stuff by reading up wget’s man page – just type man wget from the command line.
If this article helped you, I’d be grateful if you could share it on your preferred social network — it helps me a lot. If you’re feeling particularly generous, you could buy me a coffee and I’d be super grateful 🙂
Источник
How to Download a File on Ubuntu Linux using the Command Line
Linux Command line offers more flexibility and control than GUI. A number of people prefer to use the command line than GUI because it is easier and quicker to use than GUI. Using the command line, it is easier to automate the tasks using one line. In addition, it utilizes fewer resources than GUI.
Downloading files is a routine task that is normally performed every day that can include file types like ZIP, TAR, ISO, PNG, etc. you can simply and quickly perform this task using the command line terminal. It requires only using your keyboard. So today, I will show you how you can download a file using the command line in Linux. There are normally two known ways to do this, that is using wget and curl utility. For this article, I am using Ubuntu 20.04 LTS for describing the procedure. But the same commands will work on other Linux distributions like Debian, Gentoo, and CentOS too.
Download files using Curl
Curl can be used to transfer data over a number of protocols. It supports many protocols including HTTP, HTTPS, FTP, TFTP, TELNET, SCP, etc. using Curl, you can download any remote files. It supports pause and resumes functions as well.
To get started with, first, you need to install the curl.
Install curl
Launch command line application in Ubuntu that is Terminal by pressing the Ctrl+Alt+T key combinations. Then enter the below command to install curl with sudo.
When prompted for a password, enter sudo password.

Once the installation is complete, enter the below command to download a file.
Download and save the file using the source file name
To save the file with the same name as the original source file on the remote server, use –O (uppercase O) followed by curl as below:

Instead of -O, you can also specify, “–remote-name” as shown below. Both work the same.

Download and save the file with a different name
If you want to download the file and save it in a different name than the name of the file in the remote server, use -o (lower-case o) as shown below. This is helpful when the remote URL doesn’t contain the file name in the URL as shown in the example below. Advertisement
[filename] is the new name of the output file.

Download multiple files
To download multiple files, enter the command in the following syntax:

Download files from an FTP Server
To download a file from FTP server, enter the command in following syntax:

To download files from user authenticated FTP servers, use the following syntax:
Pause and resume download
While downloading a file, you can manually pause it using Ctrl+C or sometimes it automatically gets interrupted and stopped due to any reason, you can resume it. Navigate to the same directory where you have previously downloaded the file then enter the command in the following syntax:

Download files using Wget
Using wget, you can download files and contents from Web and FTP servers. Wget is a combination of www and the get. It supports protocols like FTP, SFTP, HTTP, and HTTPS. Also it supports recursive download feature. This feature is very useful if you want to download an entire website for offline viewing or for generating a backup of a static website. In addition, you can use it to retrieve content and files from various web servers.
Install wget
Launch command line application in Ubuntu that is terminal by pressing the Ctrl+Alt+T key combinations. Then enter the below command to install wget with sudo.
When prompted for a password, enter the sudo password.

Download file or webpage using wget
To download a file or a webpage, open the Terminal and enter the command in the following syntax:

To save a single webpage, enter the command in the following syntax:

Download files with a different name
If you want to download and save the file with a different name than the name of the original remote file, use -O (upper-case O) as shown below. This is helpful especially when you are downloading a webpage that automatically get saved with the name “index.html”.
To download a file with a different name, enter the command in the following syntax:

Download files through FTP
To download a file from an FTP server, type the command in the following syntax:

To download files from user authenticated FTP servers, use the below syntax:
Recursively download files
You can use the recursive download feature to download everything under the specified directory whether a website or an FTP site. To use the recursive download feature, enter the command in the below syntax:

Download multiple files
You can use wget to download multiple files. Make a text file with a list of file URLs, then use the wget command in the following syntax to download that list.
For instance, I have the text file named “downloads.txt” in which there is a list of two URLs that I want to download using wget. You can see my text file content in the below image:

I will use the below command to download the file links contained in the text file:

You can see that it is downloading both links one by one.
Pause and Resume download
You can Press Ctrl + C to pause a download. To resume a paused download, go to the same directory where you were downloading the file previously and use –c option after wget as in the below syntax:

Using the above command, you will notice that your download has resumed from where it was paused.
So in this article, we have discussed the basic usage of two command-line methods using which you can download a file. One thing to Note that if you do not specify a directory while downloading a file, the files will be downloaded in the current directory in which you are working.
Karim Buzdar
About the Author: Karim Buzdar holds a degree in telecommunication engineering and holds several sysadmin certifications. As an IT engineer and technical author, he writes for various web sites. You can reach Karim on LinkedIn
Источник



