- Конвертирование файлов в кодировку UTF-8 в Linux
- Конвертирование файлов из UTF-8 в ASCII
- Конвертирование нескольких файлов в кодировку UTF-8
- How to Convert Files to UTF-8 Encoding in Linux
- Convert Files from UTF-8 to ASCII Encoding
- Convert Multiple Files to UTF-8 Encoding
- If You Appreciate What We Do Here On TecMint, You Should Consider:
- Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
- Программы для определения кодировки в Linux
- Команда file -i показывает неверную кодировку
- Программа enca для определения кодировки файла
- Как определить кодировку строки
- Изменение кодировки в Linux
- Использование команды iconv
- Конвертирование файлов из windows-1251 в UTF-8 кодировку
- Изменение кодировки программой enca
- Конвертация строки в правильную кодировку
Конвертирование файлов в кодировку UTF-8 в Linux
Оригинал: How to Convert Files to UTF-8 Encoding in Linux
Автор: Aaron Kili
Дата публикации: 2 ноября 2016 года
Перевод: А. Кривошей
Дата перевода: ноябрь 2017 г.
В этом руководстве мы рассмотрим кодировки символов и разберем несколько примеров преобразования файлов из одной кодировки в другую с помощью утилиты командной строки. Затем мы покажем, как преобразовать файлы в Linux из любой кодировки (charset) в UTF-8.
Как вы, наверное, уже знаете, компьютер не понимает и не хранит информацию в виде букв, цифр или чего-либо еще. Он работает только с битами. Бит имеет только два возможных значения — 0 или 1, true или false, да или нет. Все остальное кодируется последовательностями битов.
Простыми словами, кодировка символов — это способ кодировки различных символов определенными последовательностями нулей и единиц. Когда мы вводим текст и сохраняем его в файл, слова и предложения, которые мы набираем, состоят из разных символов, а символы преобразуются в биты с помощью кодировки.
Существуют различные схемы кодирования, такие как ASCII, ANSI, Unicode и другие. Ниже приведен пример кодировки ASCII.
В Linux для преобразования текста из одной кодировки в другую используется утилита командной строки iconv.
Вы можете проверить кодировку файла с помощью команды file, используя флаг -i или -mime, который печатает строку типа mime, как в приведенных ниже примерах:

Синтаксис команды iconv следующий:
Где -f или —from-code задает входную кодировку, а -t или —to-encoding задает конечную кодировку.
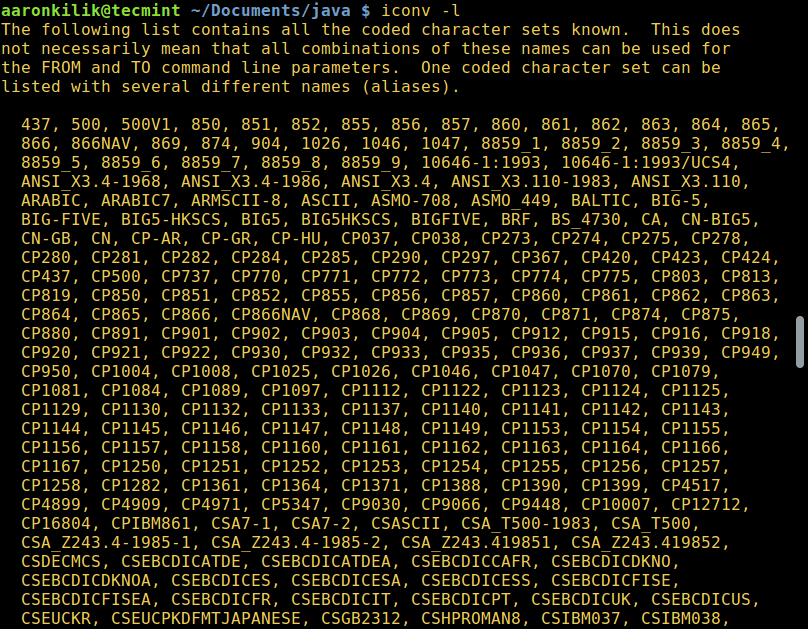
Для того, чтобы вывести список всех доступных опций, введите:
Конвертирование файлов из UTF-8 в ASCII
Далее мы научимся конвертировать текст из одной кодировки в другую. Приведенная ниже команда преобразует текст из ISO-8859-1 в кодировку UTF-8.
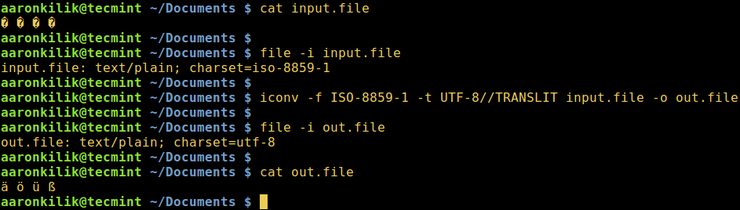
Рассмотрим файл input.file, который содержит следующие символы:
(Прим: вы увидите эти символы на снимке ниже)
Начнем с проверки кодировки файла, затем просмотрим его содержимое. Мы можем преобразовать все символы в кодировку ASCII.
После запуска команды iconv мы затем проверяем содержимое выходного файла и новую кодировку, как показано ниже.
Примечание. Если в команду добавлена строка //IGNORE, то символы, которые не могут быть преобразованы, и ошибка выводятся после преобразования.
Далее, если добавлена строка //TRANSLIT, как в приведенном выше примере (ASCII//TRANSLIT), преобразуемые символы при необходимости и по возможности транслитерируются. Это означает, что если символ не может быть представлен в целевой кодировке, его можно аппроксимировать одним или несколькими похожими символами.
Далее, любой символ, который не может быть транслитерирован и которого нет в целевой кодировке, заменяется в выводе вопросительным знаком (?).
Конвертирование нескольких файлов в кодировку UTF-8
Возвращаясь к основной теме нашей статьи, мы можем написать небольшой скрипт для преобразования нескольких или всех файлов в каталоге в кодировку UTF-8, под названием encoding.sh:
Сохраните этот файл и сделайте скрипт исполняемым. Запускайте его из той директории, где расположены ваши файлы.
Важное замечание. Вы также можете также использовать этот скрипт для преобразования нескольких файлов из одной заданной кодировки в другую (любую), просто меняйте со значения переменных FROM_ENCODING и TO_ENCODING, не забывая об имени выходного файла «$
Для получения дополнительной информации почитайте руководство iconv:
Подводя итог этой статье, необходимо отметить, что понимание способов преобразования текста из одной кодировки в другую — это знания, необходимые каждому пользователю компьютера, а тем более программистам, когда дело касается работы с текстами.
Если вы хотите лучше понять проблему кодировок символов, прочитайте следующие статьи:
Источник
How to Convert Files to UTF-8 Encoding in Linux
In this guide, we will describe what character encoding and cover a few examples of converting files from one character encoding to another using a command line tool. Then finally, we will look at how to convert several files from any character set (charset) to UTF-8 encoding in Linux.
As you may probably have in mind already, a computer does not understand or store letters, numbers or anything else that we as humans can perceive except bits. A bit has only two possible values, that is either a 0 or 1 , true or false , yes or no . Every other thing such as letters, numbers, images must be represented in bits for a computer to process.
In simple terms, character encoding is a way of informing a computer how to interpret raw zeroes and ones into actual characters, where a character is represented by set of numbers. When we type text in a file, the words and sentences we form are cooked-up from different characters, and characters are organized into a charset.
There are various encoding schemes out there such as ASCII, ANSI, Unicode among others. Below is an example of ASCII encoding.
In Linux, the iconv command line tool is used to convert text from one form of encoding to another.
You can check the encoding of a file using the file command, by using the -i or —mime flag which enables printing of mime type string as in the examples below:
![]() Check File Encoding in Linux
Check File Encoding in Linux
The syntax for using iconv is as follows:
Where -f or —from-code means input encoding and -t or —to-encoding specifies output encoding.
To list all known coded character sets, run the command below:
![]() List Coded Charsets in Linux
List Coded Charsets in Linux
Convert Files from UTF-8 to ASCII Encoding
Next, we will learn how to convert from one encoding scheme to another. The command below converts from ISO-8859-1 to UTF-8 encoding.
Consider a file named input.file which contains the characters:
Let us start by checking the encoding of the characters in the file and then view the file contents. Closely, we can convert all the characters to ASCII encoding.
After running the iconv command, we then check the contents of the output file and the new encoding of the characters as below.
![]() Convert UTF-8 to ASCII in Linux
Convert UTF-8 to ASCII in Linux
Note: In case the string //IGNORE is added to to-encoding, characters that can’t be converted and an error is displayed after conversion.
Again, supposing the string //TRANSLIT is added to to-encoding as in the example above (ASCII//TRANSLIT), characters being converted are transliterated as needed and if possible. Which implies in the event that a character can’t be represented in the target character set, it can be approximated through one or more similar looking characters.
Consequently, any character that can’t be transliterated and is not in target character set is replaced with a question mark (?) in the output.
Convert Multiple Files to UTF-8 Encoding
Coming back to our main topic, to convert multiple or all files in a directory to UTF-8 encoding, you can write a small shell script called encoding.sh as follows:
Save the file, then make the script executable. Run it from the directory where your files ( *.txt ) are located.
Important: You can as well use this script for general conversion of multiple files from one given encoding to another, simply play around with the values of the FROM_ENCODING and TO_ENCODING variable, not forgetting the output file name «$
For more information, look through the iconv man page.
To sum up this guide, understanding encoding and how to convert from one character encoding scheme to another is necessary knowledge for every computer user more so for programmers when it comes to dealing with text.
Lastly, you can get in touch with us by using the comment section below for any questions or feedback.
If You Appreciate What We Do Here On TecMint, You Should Consider:
TecMint is the fastest growing and most trusted community site for any kind of Linux Articles, Guides and Books on the web. Millions of people visit TecMint! to search or browse the thousands of published articles available FREELY to all.
If you like what you are reading, please consider buying us a coffee ( or 2 ) as a token of appreciation.

We are thankful for your never ending support.
Источник
Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
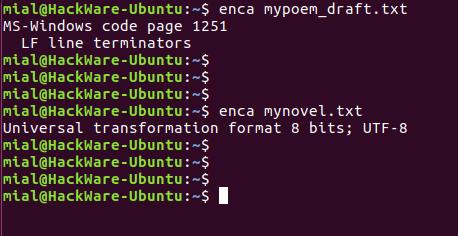
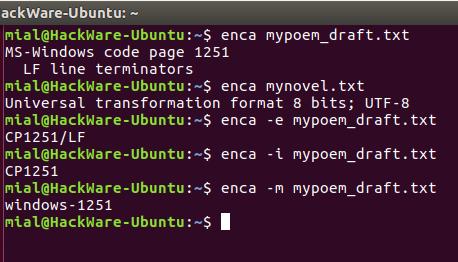
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
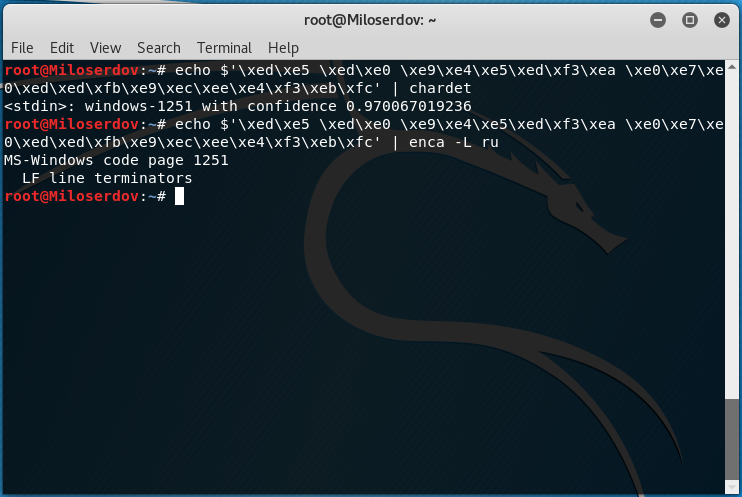
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
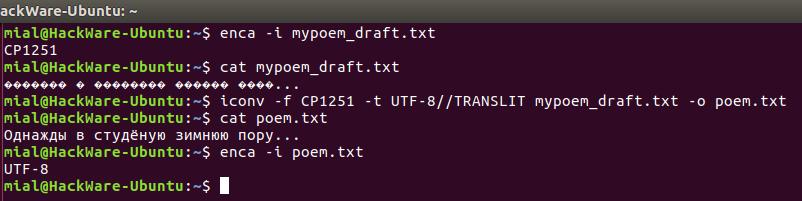
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)
Источник



