- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Регулярные выражения в Linux
- Первая команда — grep
- egrep (Extended grep)
- Про fgrep
- Рекурсивный rgrep
- Команда sed
- Понимание -regex с GNU find
- Задний план
- Поиск файлов с ls
- Поиск файлов с помощью find
- Вопросов
- Как использовать regex с командой find?
- 7 ответов
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Регулярные выражения в Linux
На регулярной основе
Интересным вопросом в Linux системах, является управление регулярными выражениями. Это полезный и необходимый навык не только профессионалам своего дела, системным администраторам, но, а также и обычным пользователям линуксоподобных операционных систем. В данной статье я постараюсь раскрыть, как создавать регулярные выражения и как их применять на практике в каких-либо целях. Основной областью применение регулярных выражений является поиск информации и файлов в линуксоподобных операционных системах.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Для работы в основном используются следующие символы:
- «\text» — слова начинающиеся с text
- «text/» — слова, заканчивающиеся на text
- «^» — начало строки
- «$» — конец строки
- «a-z» — диапазон от a до z
- «[^t]» — не буква t
- «\[« — воспринять символ [ буквально
- «.» — любой символ
- «a|z» — а или z
Регулярные выражения в основном используются со следующими командами:
grep — утилита поиска по выражению
- egrep — расширенный grep
- fgrep — быстрый grep
- rgrep — рекурсивный grep
- sed — потоковый текстовый редактор.
А особенно с утилитой grep. Данная утилита используется для сортировки результатов чего либо, передавая ей результаты по конвейеру. Эта утилита осуществляет поиск и передачу на стандартный вывод результат его. ЕЕ можно запускать с различными ключами, но можно использовать ее другие варианты, которые представлены выше.
И есть еще потоковый текстовый редактор. Это не полноценный текстовый редактор, он просто получает информацию построчно и обрабатывает. После чего выводит на стандартный вывод. Он не изменяет текстовый вывод или текстовый поток, он просто редактирует перед тем как вывести его для нас на экран.
Начнем со следующего. Создадим один пустой файл file1.txt, через команду touch. Создадим в текстовом редакторе в той же директории файл file.txt.
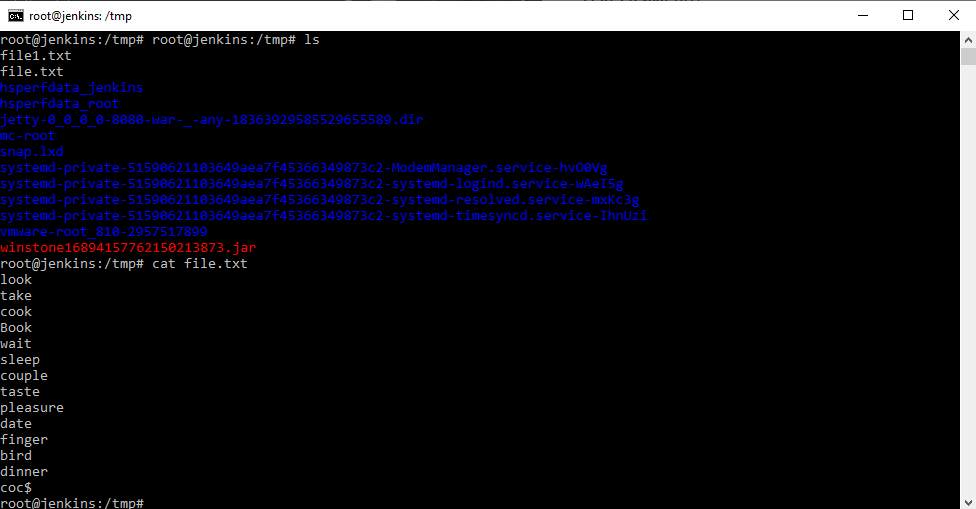
Как мы видим в файле file.txt просто набор слов. Далее мы с помощью данных слов посмотрим, как работают команды.
Первая команда — grep
Получаем справку по данной команде. Как можно понять из справки команда grep и ее производные — это печать линий совпадающих шаблонов. Проще говоря, команда grep помогает сортировать те данные, что мы даем команде, через знак конвейера на ввод. Причем в мануале мы можем видеть egrep, fgrep и т.д. данные команды мы можем не использовать. Использовать можно только grep с ключами различными, т.е. ключи просто заменяют эти команды. Можно на примере посмотреть, как работает данная команда. Например, grep oo file.txt
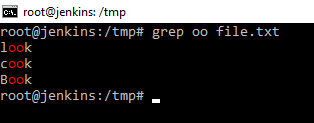
На картинке видно, что команда из указанного файла выбрала по определенному шаблону «oo». Причем даже делает красным цветом подсветку. Можно добавить еще ключик -n, тогда данная команда еще и выведет номер строки в которой находится то, что ищется по шаблону. Это полезно, когда работаем с каким-нибудь кодом или сценарием. Когда необходимо, что-то найти. Сразу видим, где находится объект поиска или что-то ищем по логам.
При использовании шаблона очень важно понимать, что команда grep, чувствительна к регистрам в шаблонах. Это означает, что Boo и boo это разные шаблоны. В одном случае команда найдет слово, а в другом нет. Можно команде сказать, чтобы она не учитывала регистр. Это делается с помощью ключа -i.
Посмотрим содержимое нашего каталога командой ls, а затем отфильтруем только то, что заканчивается на «ile«.

Получается следующее, когда мы даем на ввод команде grep шаблон и где искать, он работает с файлом, а когда мы даем команду ls она выводи содержимое каталога и мы это содержимое передаем по конвейеру на команду grep с заданным шаблоном. Соответственно grep фильтрует переданное содержимое согласно шаблона и выводит на экран. Получается, что команде grep дали, то команда и обработала.
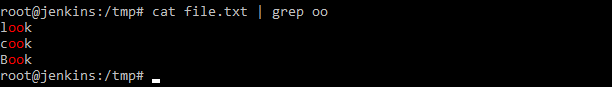
Наглядно можно посмотреть на рисунке выше. Мы просматриваем командой cat содержимое файла и подаем на ввод команде grep с фильтрацией по шаблону.
Давайте найдем файлы в которых содержится сочетание «ple«. grep ple file.txt в данном случае команда нашла оба слова содержащие шаблон. Давайте найдем слово, которое будет начинаться с «ple«. Команда будет выглядеть следующим образом: grep ^ple file.txt . Значок «^» указывает на начало строки. Противоположная задача найти слова, заканчивающиеся на «ple«. Команда будет выглядеть следующим образом grep ple$ file.txt . Т.е. применять к концу строки, говорит значок «$» в шаблоне.

Можно дать команду grep .o file.txt. В данном выражении знак «.» , заменяет любую букву.

Как вы видите вывод шаблона «.ple» вывел только одно слово т.к только слово couple удовлетворяло шаблону , т.к перед «ple» должен был содержаться еще один символ любой.
Попробуем рассмотреть другую команду egrep.
egrep (Extended grep)
man egrep — отошлет к справке по grep.
Данная команда позволяет использовать более расширенный набор шаблонов. Рассмотрим следующий пример команды:
Шаблон заключается в одинарные кавычки, для того чтобы экранировать символы, и команда egrep поняла, что это относится к ней и воспринимала выражение как шаблон. Сам же шаблон означает, что поиск будет искать слова, в начале строки (знак ^) содержащие букву b или d.
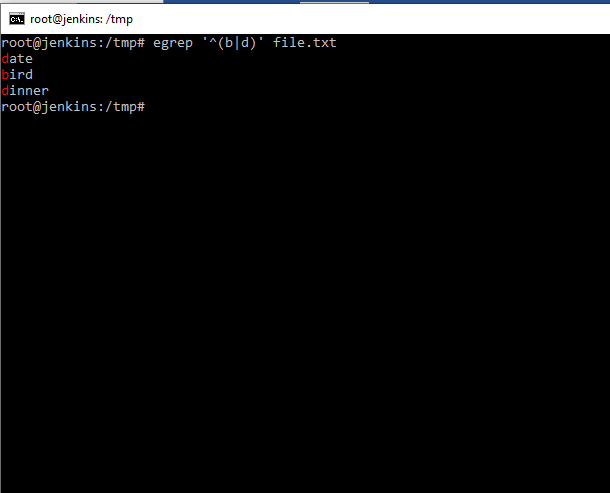
Мы видим, что команда вернула слова, начинающиеся с буквы b или d. Рассмотрим другой вариант использования команды egrep. Например:
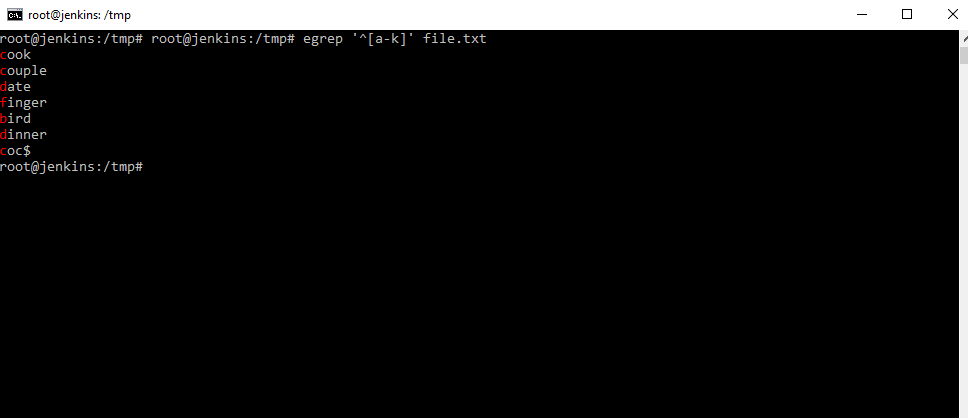
Получим все слова, начинающиеся с «a» по «к». Знак «[]» — диапазона. Как мы видим слова, начинающиеся с большой буквы, не попали. Все эти регулярные выражения очень пригодятся, когда мы что-то ищем в файлах логах.
Усложним еще шаблон. Возьмем следующий:
Усложняя выражение, мы добавили диапазон заглавных букв сказав команде grep искать диапазон маленьких или диапазон больших букв с начала строки.

Вот теперь все хорошо. Слова с Заглавными буквами тоже отобразились.
Как вариант egrep можно запускать просто grep с ключиком -e.
Про fgrep
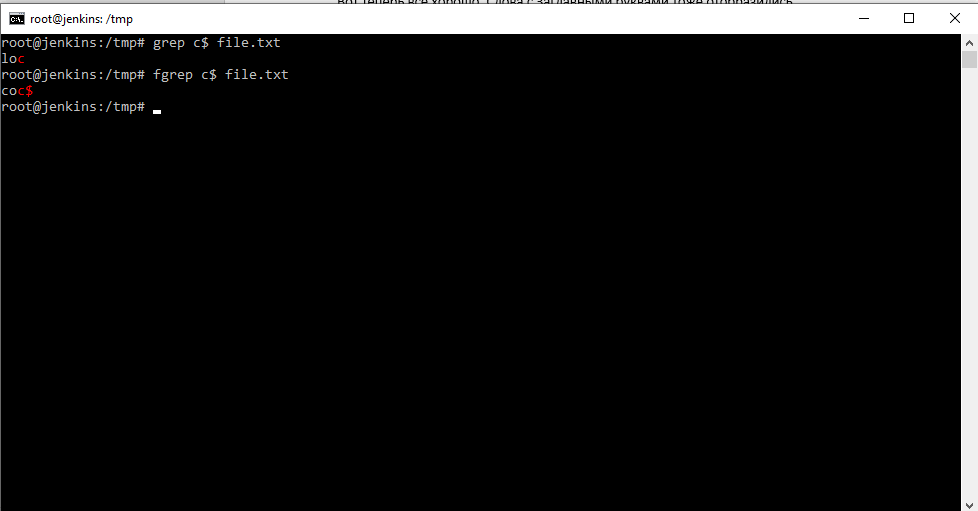
man fgrep — отошлет к справке по grep. Команда fgrep не понимает регулярных выражений вообще.
Получается следующим образом если мы вводим: egrep c$ file.txt . То команда согласно шаблону, ищет в файле букву «c» в конце слова. В случае же с командой fgrep c$ file.txt , команда будет искать именно сочетание «с$». Т.е. команда fgrep воспринимает символы регулярных выражений, как обычные символы, которые ей нужно найти, как аргументы.
Рекурсивный rgrep
Создадим каталог mkdir folder . Создадим файл great.txt в созданной директории folder со словом Hello при помощью команды echo «Hello» folder/great.txt
И если мы скажем grep Hello * , поищи слово Hello в текущей директории. Получится следующая картина.
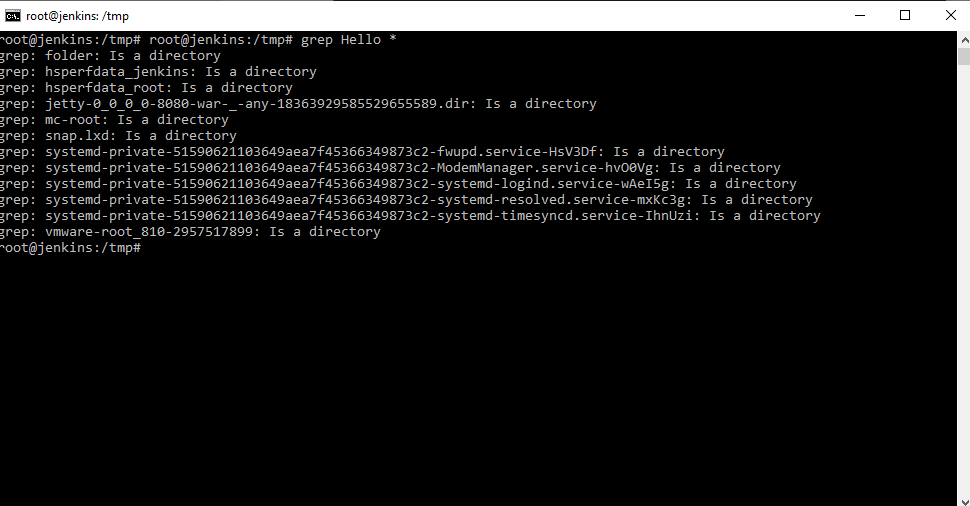
Как мы видим grep не может искать в папках. Для таких случаев и используется утилита rgrep.
Дает следующую картину.
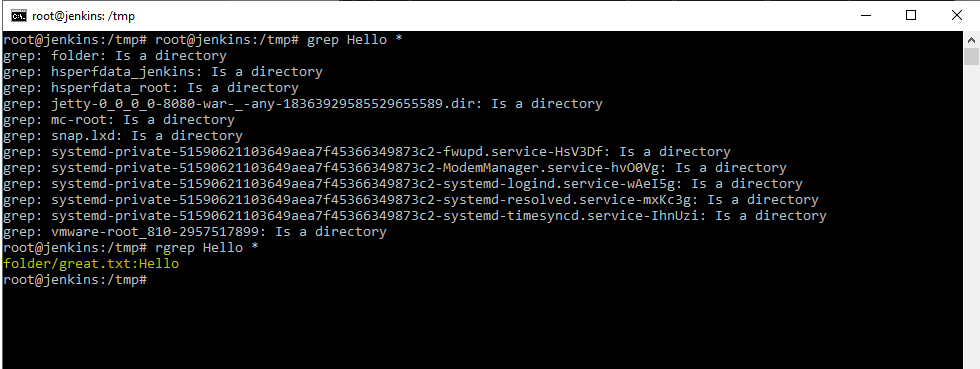
Совершенно спокойно в папке найдено было, то что подходило под шаблон.
Данная утилита пробежалась по всем папкам и файлам в них и нашла подходящее под шаблон слово. Т.е. если нам необходимо провести поиск по всем файлам и папкам, то необходимо использовать утилиту rgrep .
Команда sed
man sed — стрим редактор. Т.е потоковый редактор для фильтрации и редактирования потока данных.
Например, sed -e ‘s/oo/aa’ file.txt — открыть редактор sed и заменить вывод всех oo на aa в файле file.txt. Нужно понимать, что в результате данной команды изменения в файле не произойдут. Просто данные из файла будут взяты и с изменениями выведены на стандартный вывод, т.е. экран. Для сохранения результатов мы можем сказать, чтобы вывел в новый файл указав направление вывода.
В данном редакторе мы можем ему сказать использовать регулярные выражения, для этого необходимо добавить ключ -r. У данного редактора очень большой функционал.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник
Понимание -regex с GNU find
Задний план
У меня есть то, что, по моему мнению, должно быть простым. Я хочу найти все файлы с «cisco» в имени и сделать что-то с этими файлами (через xargs ).
Поиск файлов с ls
Прежде чем использовать xargs , первым шагом будет перечисление всех соответствующих файлов. Список файлов легко с ls | grep cisco ls | grep cisco …
Поиск файлов с помощью find
Хотя это, вероятно, не требуется в этом конкретном случае, найти, как правило, считается безопасным при прокладке трубопроводов в xargs . Однако вся логика, кажется, выходит из окна, когда я использую find -regex .
Однако я знаю, что могу найти эти файлы …
Вопросов
Я понимаю, что find -regex должен соответствовать возврату полного пути, но почему не find -regextype grep -regex «.*/cisco*» -print работает выше? Не следует .*/cisco* соответствует пути?
Я знаю, что я мог бы просто использовать find -path «*cisco*» для решения проблемы, но дело в том, чтобы понять, почему использование my -regex неверно.
Поиск с помощью ls : сначала сначала, ls | grep cisco ls | grep cisco немного многословный, поскольку cisco не является регулярным выражением. Пытаться:
Используя find : по тем же линиям, -regex переполняется простым статическим шаблоном. Как насчет:
Кавычки требуются, поэтому glob интерпретируется find , а не оболочкой. Кроме того, -print требуется для многих версий find , но является необязательным (и предикатом по умолчанию) для других (например, GNU find ). Не стесняйтесь добавлять его, если вам это нужно.
Если вам нужно найти «cisco» в полном пути, вы можете попробовать следующее:
что эквивалентно find | fgrep cisco find | fgrep cisco .
Использование find с регулярными выражениями : давайте сделаем это в любом случае, так как это то, что вы хотите. Бесстыдное копирование с GNU find manpage:
Это означает, что ваше регулярное выражение завернуто в невидимый ^. $ , поэтому он должен соответствовать каждому символу в полном пути файла. Итак, как сказал nwildner и otokan в комментариях, вы должны использовать что-то вроде:
И вам даже не нужен -regextype для чего-то такого простого.
Причина, по которой find -regex «.*/cisco*» не будет соответствовать никаким путям, например ./cisco-eem-tcl.rst или ./cisco_autonomous_to_lwap.rst выглядит следующим образом:
- .* соответствует чему угодно – любому персонажу, ноль или более раз
- / соответствует одной косой чертой – пока что так хорошо
- cisco* соответствует cisc , за которым следует любое количество o .
Помните, что оператор asterix * сдерживает повторение предыдущего элемента, который в этом случае равен o . Это означает, что мы не имеем ничего общего с этим последним компонентом шаблона, потому что это будет нечто вроде cisc , cisco , ciscoo , ciscooo … ad infinitum.
Если вам нужно выразить, что все может следовать за словом cisco , тогда используйте .* После этого:
Возможно, вам хотелось бы немного ограничивать результаты поиска, сопоставляя только rst файлы:
Тем не менее, выполнение простого совпадения в компоненте имени файла пути, таком как это, не требует выразительной мощности регулярных выражений, поэтому вы можете просто отлично использовать только -name с помощью glob для получения того же соответствия:
и для обработки этих совпадений с помощью xargs вы сделали бы что-то вроде этого:
Вы всегда должны помнить, что регулярные выражения и глобусы – это разные вещи синтаксически и семантически. Посмотрите, как man find и читают о параметрах -name и -regex , чтобы узнать больше.
Источник
Как использовать regex с командой find?
У меня есть некоторые изображения с именем сгенерированной строки uuid1. Например 81397018-b84a-11e0-9d2a-001b77dc0bed.формат jpg. Я хочу узнать все эти изображения, используя команду «найти»:
но это не работает. Что-то не так с регулярным выражением? Кто-нибудь может мне помочь?
7 ответов
обратите внимание, что нужно указать .*/ в начале find соответствует всему пути.
моя версия find:
на -regex найти выражение соответствует все имя, включая относительный путь от текущего каталога. Для find . этого всегда начинается с ./ , то любые каталоги.
и emacs регулярные выражения, которые имеют другие правила экранирования, чем обычные регулярные выражения egrep.
если все они находятся непосредственно в текущем каталоге, то
должны работать. (Я не совсем уверен, — я не могу получить подсчитано повторение, чтобы работать здесь.) Можно выбрать для egrep выражения -regextype posix-egrep :
(обратите внимание, что все сказанное здесь для GNU find, я ничего не знаю о BSD, который также является значением по умолчанию для Mac.)
судя по другим ответам, кажется, это может быть ошибка find.
однако вы можете сделать это таким образом:
find . * | grep -P «[a-f0-9\-]<36>\.jpg»
возможно, вам придется немного настроить grep и использовать разные параметры в зависимости от того, что вы хотите, но это работает.
попробуйте использовать одинарные кавычки ( ‘ ), чтобы избежать экранирования оболочки вашей строки. Помните, что выражение должно соответствовать всему пути, т. е. должно выглядеть так:
кроме того, кажется, что моя находка (GNU 4.4.2) знает только основные регулярные выражения, особенно синтаксис <36>. Думаю, тебе придется обойтись без этого.
вы должны использовать абсолютный путь к каталогу при применении инструкции с регулярным выражением. В вашем примере
следует изменить на
в большинстве систем Linux некоторые дисциплины в регулярном выражении не могут быть распознаны этой системой, поэтому вы должны явно указать-regexty как
простой способ — вы можете указать .* в начале, потому что найти весь путь.
на Mac (BSD найти): то же, что и принятый ответ, .*/ префикс необходим для соответствия полному пути:
man find говорит -E использует расширенную поддержку регулярных выражений
Источник



