- How to read first and last line from cat output?
- 7 Answers 7
- Display the last lines of a file in Unix
- How do you get to the Last Line in Nano?
- Method # 1: Using the “Alt+ /” Shortcut Combination:
- Method # 2: Using the “Ctrl+ W” and “Ctrl+ V” Shortcut Combinations:
- About the author
- Karim Buzdar
- How to display certain lines from a text file in Linux?
- 11 Answers 11
- How do you keep only the last n lines of a log file?
- 8 Answers 8
- Install
- Documentation
How to read first and last line from cat output?
I have text file. Task — get first and last line from file after
Need this without cat output (only 1 and 5).
Maybe awk and more shorter solution exist.


7 Answers 7
sed Solution:
When reading from stdin if would look like this (for example ps -ef ):
head & tail Solution:
When data is coming from a command ( ps -ef ):
awk Solution:
And also the piped example with ps -ef :

sed -n ‘1p;$p’ file.txt will print 1st and last line of file.txt .

A funny pure Bash≥4 way:
After this, you’ll have an array ary with first field (i.e., with index 0 ) being the first line of file , and its last field being the last line of file . The callback cb (optional if you want to slurp all lines in the array) unsets all the intermediate lines so as to not clutter memory. As a free by-product, you’ll also have the number of lines in the file (as the last index of the array+1).
With sed you could d elete lines if NOT the 1 st one AND NOT the la $ t one.
Use ! to NOT (negate) a condition and the X
or you could use a range — from 2 nd to la $ t — and delete all lines in that range except the la $ t line:

The above prints the first item in the output of seq 10 via the if 1..1 , while the or eof will also print the last item.
Источник
Display the last lines of a file in Unix
Use the Unix command tail to read from standard input or a file and send the result to standard output (that is, your terminal screen). The format for using the tail command is:
Everything in brackets is an optional argument. If you don’t specify a filename, tail uses standard input.
Tail begins at distance +number from the beginning or -number from the end of the input. The number is counted in units of lines, blocks, or characters, according to the appended options -l , -b , or -c . When you don’t specify a unit, tail operates based on lines.
Specifying -r causes tail to print lines from the end of the file in reverse order. The default for -r is to print the entire file this way. Specifying -f causes tail not to quit at the end of the file, but rather to reread the file repeatedly (useful for watching a «growing» file such as a log file).
For example, given a file containing the English alphabet with each letter on a separate line, the command:
You can use tail with pipes. For example, to see the sizes of the last few files in the current directory, you could enter at the Unix prompt:
To save this information in a file in the current directory named mylist , at the Unix prompt, enter:
For more detailed information on tail , consult the Unix manual page by entering at the prompt:
At Indiana University, for personal or departmental Linux or Unix systems support, see Get help for Linux or Unix at IU.
Источник
How do you get to the Last Line in Nano?
Method # 1: Using the “Alt+ /” Shortcut Combination:
The first thing that you need to do is to launch a file with the nano editor using the terminal command shown below:
You can provide any file name instead of Testing.txt according to the file that you want to open.

Once your file will open with the nano editor, the cursor will be pointing at the beginning of the file. Just press “Alt+ /” (Alt+ Forward Slash) and you will notice that your cursor has shifted to the end of the last line of your file as shown in the following image:

Method # 2: Using the “Ctrl+ W” and “Ctrl+ V” Shortcut Combinations:
Open any desired file with nano editor through the command stated above. Once your file is opened in the nano editor, press “Ctrl+ W”. Doing this will make a Search prompt to appear at the end of your file as shown in the image below:
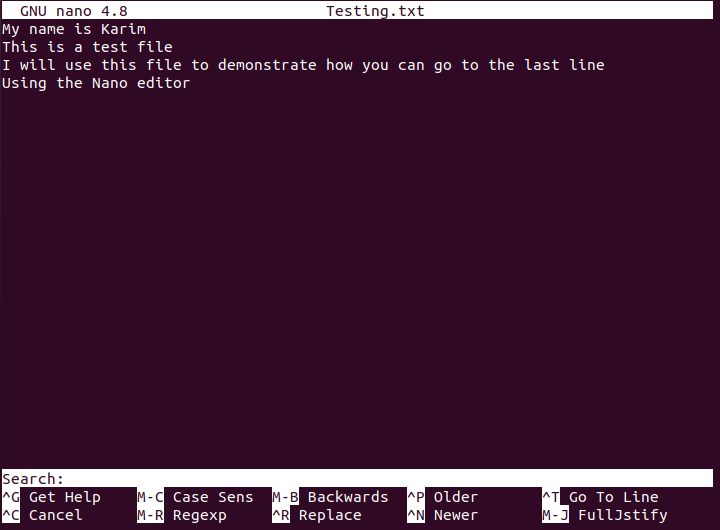
Now press “Ctrl+ V” after that Search prompt appears and you will notice that your cursor is now pointing to the end of the last line of your file as shown in the following image:

These methods prove to be helpful when you are working with large files and you quickly want to navigate to the end of the file or the last line of the file. These files can either be text files or any other type of file. The methods of navigating to the last line of any file in the nano editor will remain the same.
About the author

Karim Buzdar
Karim Buzdar holds a degree in telecommunication engineering and holds several sysadmin certifications. As an IT engineer and technical author, he writes for various web sites. He blogs at LinuxWays.
Источник
How to display certain lines from a text file in Linux?
I guess everyone knows the useful Linux cmd line utilities head and tail . head allows you to print the first X lines of a file, tail does the same but prints the end of the file. What is a good command to print the middle of a file? something like middle —start 10000000 —count 20 (print the 10’000’000th till th 10’000’010th lines).
I’m looking for something that will deal with large files efficiently. I tried tail -n 10000000 | head 10 and it’s horrifically slow.
11 Answers 11
You might be able to speed that up a little like this:
In those commands, the option -n causes sed to «suppress automatic printing of pattern space». The p command «print[s] the current pattern space» and the q command «Immediately quit[s] the sed script without processing any more input. » The quotes are from the sed man page.
By the way, your command
starts at the ten millionth line from the end of the file, while your «middle» command would seem to start at the ten millionth from the beginning which would be equivalent to:
The problem is that for unsorted files with variable length lines any process is going to have to go through the file counting newlines. There’s no way to shortcut that.
If, however, the file is sorted (a log file with timestamps, for example) or has fixed length lines, then you can seek into the file based on a byte position. In the log file example, you could do a binary search for a range of times as my Python script here* does. In the case of the fixed record length file, it’s really easy. You just seek linelength * linecount characters into the file.
* I keep meaning to post yet another update to that script. Maybe I’ll get around to it one of these days.
Источник
How do you keep only the last n lines of a log file?
A script I wrote does something and, at the end, appends some lines to its own logfile. I’d like to keep only the last n lines (say, 1000 lines) of the logfile. This can be done at the end of the script in this way:
but is there a more clean and elegant solution? Perhaps accomplished via a single command?

8 Answers 8
It is possible like this, but as others have said, the safest option is the generation of a new file and then a move of that file to overwrite the original.
The below method loads the lines into BASH, so depending on the number of lines from tail , that’s going to affect the memory usage of the local shell to store the content of the log lines.
The below also removes empty lines should they exist at the end of the log file (due to the behaviour of BASH evaluating «$(tail -1000 test.log)» ) so does not give a truly 100% accurate truncation in all scenarios, but depending on your situation, may be sufficient.
The utility sponge is designed just for this case. If you have it installed, then your two lines can be written:
Normally, reading from a file at the same time that you are writing to it is unreliable. sponge solves this by not writing to myscript.log until after tail has finished reading it and terminated the pipe.
Install
To install sponge on a Debian-like system:
To install sponge on a RHEL/CentOS system, add the EPEL repo and then do:
Documentation
From man sponge :
sponge reads standard input and writes it out to the specified file. Unlike a shell redirect, sponge soaks up all its input before writing the output file. This allows constructing pipelines that read from and write to the same file.

definitely «tail + mv» is much better! But for gnu sed we can try
For the record, with ed you could do something like
This opens infile and r eads in the output of tail -n 1000 infile (i.e. it inserts that output before the 1st line) and then delete from what was initially the 1st line to the end of file. Replace ,p with w to edit the file in-place.
Keep in mind though that ed solutions aren’t suitable for large files.
What you can do in your script is implement the logic of log rotation. Do all the logging through a function:
This function, firstly, does something like:
then, it checks the size of the file or somehow decides that the file requires rotation. At that point, the file logfile.1 , if it exists, is removed, the file logfile.0 , if it exists, is renamed to logfile.1 and logfile is renamed to logfile.0 .
Deciding whether to rotate could be based on a counter maintained in the script itself. When it hits 1000, it is reset to zero.
If always strictly trimming to 1000 lines is a requirement, the script could count the number of lines in the log file when it starts, and initialize the counter accordingly (or if the count already meets or exceeds 1000, do the rotation immediately).
Or you could obtain the size, such as with wc -c logfile and do the rotation based on exceeding a certain size. This way the file never has to be scanned to determine the condition.
I did use, instead of mv , the cp command to achieve it that you are able to have some logfiles right in place where a Software is running. Maybe in the different User home dir or in the app dir and do have all logs in one place as hardlinks. If you use the mv command you lose the hard link. If you use the cp command instead you will keep this hard link.
my code is something like:
So if the files are on the same Filesystem you may give as well some different rights to the users and in the $
If it is the mv command you lose the hardlink between the files and so your second file is not more connected to the first one — maybe placed some where else.
If on the other place you don’t allow someone to erase the file your logs stay together and be nice controlled via your own script.
logrotate maybe nicer. But I am happy with this solution.
Don’t be disturbed by the «» but in my case there are some files with spaces and other special letters in and If I don’t do the «» around or the <> the whole lot doesn’t work nice.
Источник



