- How to Count lines in a file in UNIX/Linux
- Using “wc -l”
- Using awk
- Using sed
- Using grep
- Some more commands
- How to Count the Lines of a File in Linux
- The Linux Command to Count Lines
- Counting the Occurrences of a Pattern in a File
- Counting the Number of Files with a Specific Extension
- Output of the wc Command Without Flags
- Count the Lines in a Zipped File in Linux
- Count Empty Lines in a File
- Conclusion
- Calculating the number of lines in a file?
- 4 Answers 4
- Not the answer you’re looking for? Browse other questions tagged command-line bash or ask your own question.
- Linked
- Related
- Hot Network Questions
- Subscribe to RSS
- Count lines in large files
- 14 Answers 14
- How to count lines in a document?
- 27 Answers 27
- wc -l does not count lines.
- POSIX-compliant solution
How to Count lines in a file in UNIX/Linux
Question: I have a file on my Linux system having a lot of lines. How do I count the total number of lines in the file?
Using “wc -l”
There are several ways to count lines in a file. But one of the easiest and widely used way is to use “wc -l”. The wc utility displays the number of lines, words, and bytes contained in each input file, or standard input (if no file is specified) to the standard output.
So consider the file shown below:
1. The “wc -l” command when run on this file, outputs the line count along with the filename.
2. To omit the filename from the result, use:
3. You can always provide the command output to the wc command using pipe. For example:
You can have any command here instead of cat. Output from any command can be piped to wc command to count the lines in the output.
Using awk
If you must want to use awk to find the line count, use the below awk command:
Using sed
Use the below sed command syntax to find line count using GNU sed:
Using grep
Our good old friend «grep» can also be used to count the number of lines in a file. These examples are just to let you know that there are multiple ways to count the lines without using «wc -l». But if asked I will always use «wc -l» instead of these options as it is way too easy to remember.
With GNU grep, you can use the below grep syntax:
Here is another version of grep command to find line count.
Some more commands
Along with the above commands, its good to know some rarely used commands to find the line count in a file.
1. Use the nl command (line numbering filter) to get each line numbered. The syntax for the command is:
Not so direct way to get line count. But you can use awk or sed to get the count from last line. For example:
2. You can also use vi and vim with the command «:set number» to set the number on each line as shown below. If the file is very big, you can use «Shift+G» to go to the last line and get the line count.
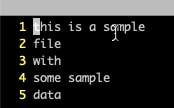
3. Use the cat command with -n switch to get each line numbered. Again, here you can get the line count from the last line.
4. You can also use perl one lines to find line count:
Источник
How to Count the Lines of a File in Linux
Knowing how to count the lines of a file or from the output of a command is a must in Linux.
How to count the lines in a file with Linux?
Linux provides the wc command that allows to count lines, words and bytes in a file or from the standard input. It can be very useful in many circumstances, some examples are: getting the number of errors in a log file or analysing the output coming from other Linux commands.
How many errors can you see in the logs of your application? How many unique users have used your application today?
These are just two examples of scenarios in which you need to be able to count the lines of a file.
So, how can you count the lines of a file using Linux?
Let’s find out how!
The Linux Command to Count Lines
The most used command to do that is the wc (word count) command.
Let’s say we want to count the lines in the /var/log/messages file.
This file contains global system messages and it’s very useful to troubleshoot issues with your Linux system.
To count the number of lines we will use the following syntax:
The -l flag is used to get the number of lines, the reason for this flag is that the wc command allows to do a lot more than just counting lines…
As you can see in this case the number of lines in the file is 2094.
Counting the Occurrences of a Pattern in a File
Now, let’s say we want to count the number of errors in the same file.
We can use the grep command followed by the wc command using the pipe.
The pipe is used to send the standard output of the command before the pipe to the standard input of the command after the pipe.
Here the output of the grep command becomes the input of the wc command.
The output of the grep command without pipe would be:
So we have two lines that contain the string ERROR.
If we use the pipe followed by the wc command we won’t see anymore the lines but just the number of lines:
I want to know how many times the Apache web server on my Linux machine has been restarted.
First we look for all the lines in /var/log/messages containing the word ‘Apache’:
We use the -i flag in the grep command to ignore the case when looking for a match, so our grep would match lines containing the text ‘apache’ or ‘Apache’.
We can see that Apache logs the following message when it starts successfully:
So our grep command becomes:
Two grep commands?
Yes, you can use the pipe to concatenate multiple commands, even if they are the same command, like in this case.
And finally we can add wc to get the total count:
So, our Apache has been restarted successfully 13 times.
You can also get the same result of the command above using the -c flag for the grep command.
The command above becomes:
The wc command can be also used to count the number of lines in multiple files:
Counting the Number of Files with a Specific Extension
If we want to count the number of files with extension .log inside the /var/log/ directory, we can use:
The wildcard *.log is used to match all the files with extension .log.
What do we do if we want to get the actual number of files?
We use once again the pipe and the wc command:
The power of wc together with other Linux commands is endless!
Output of the wc Command Without Flags
Let’s execute the previous command:
But this time without passing any flags to the wc command.
We see three numbers in the output…what do they represent?
They are the total numbers of lines, words and bytes.
From the previous example we can already see that 5 is the number of lines. Let’s confirm that 45 and 321 are the number of words and bytes.
The -m flag for the wc command allows to get just the number of words:
And the -c flag to get the number of bytes:
Count the Lines in a Zipped File in Linux
So far we have seen how to count the lines of files in Linux.
What if I want to count the number of lines in a zipped file?
First of all we can use the zcat command to print the content of a zipped file.
Let’s say we have a zipped file called app_logs.gz, I can use the following command to see its content:
To see the number of lines in this file I can simply use the pipe followed by the wc command in the same way we have seen in the previous sections:
So, no need to use the gunzip command to decompress the file before counting its lines!
This article gives more details about compressing files in Linux.
Count Empty Lines in a File
I have showed you few things you can do with grep, wc and other commands.
And I want to show you something else that can be useful.
Let’s say I want to count the number of empty lines in a file.
The syntax is similar to other commands we have seen so far with a difference in the pattern matched via the grep command to identify empty lines.
The pattern to identify an empty line with grep is:
This represents an empty line because ^ is the beginning of the line, $ is the end of the line and there’s nothing between them.
So taking as an example a file called app_error.log, the full command to identify the number of empty lines in this file is:
That as we have seen before can also be written using the -c flag for grep:
If I want to print the number of lines that are not empty I can simply add the -v flag for the grep command that inverts the sense of the matching.
It basically selects the lines that don’t match the pattern specified:
Conclusion
There are many ways you can use the wc command on your Linux system.
You have learned how you can use it to count lines in a file…
How to mix it with the grep command using the pipe, to count the occurrences of a specific pattern in a normal file and in a zipped one…
And how to get the number of files in a directory with a specific extension.
And there are so many other ways in which you can use it.
Источник
Calculating the number of lines in a file?
How would I calculate and display the number of lines and words that are contained in a .sh file?

4 Answers 4
Use the tool wc .
To count the number of lines: -l
To count the number of words: -w
See man wc for more options.

As mentioned by souravc, you can use wc for this:
To only display the count itself, you can pipe that output to awk , like this:
. or as kos mentioned below:

You can use grep command with blank matching string
You can also output the entire file with line numbers in front of every line using the command below:
Not the answer you’re looking for? Browse other questions tagged command-line bash or ask your own question.
Linked
Related
Hot Network Questions
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
site design / logo © 2021 Stack Exchange Inc; user contributions licensed under cc by-sa. rev 2021.10.8.40416
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Источник
Count lines in large files
I commonly work with text files of
20 Gb size and I find myself counting the number of lines in a given file very often.
The way I do it now it’s just cat fname | wc -l , and it takes very long. Is there any solution that’d be much faster?
I work in a high performance cluster with Hadoop installed. I was wondering if a map reduce approach could help.
I’d like the solution to be as simple as one line run, like the wc -l solution, but not sure how feasible it is.

14 Answers 14
Try: sed -n ‘$=’ filename
Also cat is unnecessary: wc -l filename is enough in your present way.
Your limiting speed factor is the I/O speed of your storage device, so changing between simple newlines/pattern counting programs won’t help, because the execution speed difference between those programs are likely to be suppressed by the way slower disk/storage/whatever you have.
But if you have the same file copied across disks/devices, or the file is distributed among those disks, you can certainly perform the operation in parallel. I don’t know specifically about this Hadoop, but assuming you can read a 10gb the file from 4 different locations, you can run 4 different line counting processes, each one in one part of the file, and sum their results up:
Notice the & at each command line, so all will run in parallel; dd works like cat here, but allow us to specify how many bytes to read ( count * bs bytes) and how many to skip at the beginning of the input ( skip * bs bytes). It works in blocks, hence, the need to specify bs as the block size. In this example, I’ve partitioned the 10Gb file in 4 equal chunks of 4Kb * 655360 = 2684354560 bytes = 2.5GB, one given to each job, you may want to setup a script to do it for you based on the size of the file and the number of parallel jobs you will run. You need also to sum the result of the executions, what I haven’t done for my lack of shell script ability.
If your filesystem is smart enough to split big file among many devices, like a RAID or a distributed filesystem or something, and automatically parallelize I/O requests that can be paralellized, you can do such a split, running many parallel jobs, but using the same file path, and you still may have some speed gain.
EDIT: Another idea that occurred to me is, if the lines inside the file have the same size, you can get the exact number of lines by dividing the size of the file by the size of the line, both in bytes. You can do it almost instantaneously in a single job. If you have the mean size and don’t care exactly for the the line count, but want an estimation, you can do this same operation and get a satisfactory result much faster than the exact operation.
Источник
How to count lines in a document?
I have lines like these, and I want to know how many lines I actually have.
Is there a way to count them all using linux commands?

27 Answers 27
This will output the number of lines in :
Or, to omit the from the result use wc -l :
You can also pipe data to wc as well:
To count all lines use:
To filter and count only lines with pattern use:
Or use -v to invert match:
See the grep man page to take a look at the -e,-i and -x args.

there are many ways. using wc is one.
sed -n ‘$=’ file (GNU sed)
The tool wc is the «word counter» in UNIX and UNIX-like operating systems, but you can also use it to count lines in a file by adding the -l option.
wc -l foo will count the number of lines in foo . You can also pipe output from a program like this: ls -l | wc -l , which will tell you how many files are in the current directory (plus one).
If you want to check the total line of all the files in a directory ,you can use find and wc:


wc -l does not count lines.
Yes, this answer may be a bit late to the party, but I haven’t found anyone document a more robust solution in the answers yet.
Contrary to popular belief, POSIX does not require files to end with a newline character at all. Yes, the definition of a POSIX 3.206 Line is as follows:
A sequence of zero or more non- characters plus a terminating character.
However, what many people are not aware of is that POSIX also defines POSIX 3.195 Incomplete Line as:
A sequence of one or more non- characters at the end of the file.
Hence, files without a trailing LF are perfectly POSIX-compliant.
If you choose not to support both EOF types, your program is not POSIX-compliant.
As an example, let’s have look at the following file.
No matter the EOF, I’m sure you would agree that there are two lines. You figured that out by looking at how many lines have been started, not by looking at how many lines have been terminated. In other words, as per POSIX, these two files both have the same amount of lines:
The man page is relatively clear about wc counting newlines, with a newline just being a 0x0a character:
Hence, wc doesn’t even attempt to count what you might call a «line». Using wc to count lines can very well lead to miscounts, depending on the EOF of your input file.
POSIX-compliant solution
You can use grep to count lines just as in the example above. This solution is both more robust and precise, and it supports all the different flavors of what a line in your file could be:
Источник



