- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Руководство по команде grep в Linux
- Про Linux за 5 минут | Что это или как финский студент перевернул мир?
- Для чего мы пользуемся grep-ом?
- Поиск строк
- Поиск по нескольким параметрам
- Разница между grep, egrep fgrep, pgrep, zgrep
- Разница между find и grep
- Рекурсивный поиск
- Найти пробелы и табуляцию
- Использование регулярных выражений
- Исключение терминов в Grep
- Предпосылка
- Пример 1
- Пример 2
- Исключить термин из нескольких слов
- Исключить файл
- Исключить каталог с Word
- Исключить слово с помощью каталога
- Заключение
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Руководство по команде grep в Linux
Читать между строк
10 минут чтения
То, что система Linux предоставляет пользователю большое многообразие разного функционала уже не секрет. На одном из прошлых материалов мы рассмотрели, как и где можно использовать команду find. В этой же статье мы на примерах разберём команду grep, мощный инструмент системных администраторов.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Про Linux за 5 минут | Что это или как финский студент перевернул мир?

Для чего мы пользуемся grep-ом?
Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле. Также можно передать вывод любой команды в grep, что сильно упрощает работу во время поиска и траблшутинга.
Возьмём команду ls. Сама по себе она выводит список всех файлов и папок.
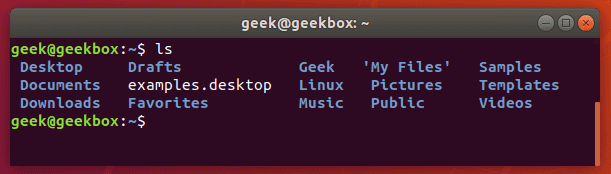
Но если нужно найти конкретную папку или один файл среди сотни других, то мы можем передать вывод команды ls в grep через вертикальную черту (|), а уже grep-у параметром передать нужное слово.
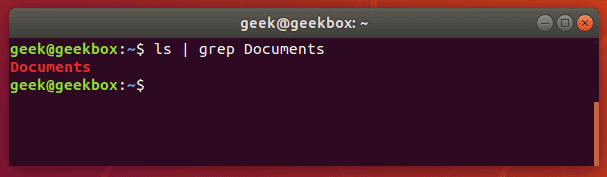
Если команда grep ничего не вернула, значит искомого файла/папки не существует в данной директории.
Поиск строк
Если же нужно найти не одно слово, а словосочетание или целое предложение, то параметр команды grep должно быть выделено кавычками. Grep поддерживает как одинарные, так и двойные кавычки.
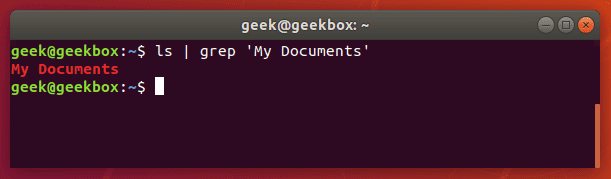
Несмотря на то, что команда grep чаще используется как своего рода фильтр для других команд, но её также можно использовать отдельно как на примере ниже.
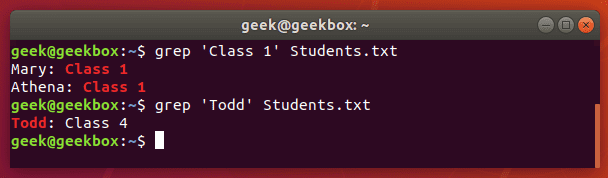
В этом примере мы вели поиск указанных в кавычках слов в файле Students.txt и команда grep успешно справилась со своей задачей.
Поиск по нескольким параметрам
Команде grep можно передавать не один параметр, а несколько. Для этого перед каждым аргументом пишется ключ e. Эту команду система понимает, как «или-или» и выводит все вхождения указанных слов. Заметьте, что кавычками выделена только строка, которая содержит пробел.

Разница между grep, egrep fgrep, pgrep, zgrep
Исторически разные версии Linux-а включали разновидности команды grep. Хотя в современных версия систем базовая команда grep поддерживает все возможности, которыми обладают egrep fgrep, pgrep, zgrep, но все же их тоже стоит рассмотреть.
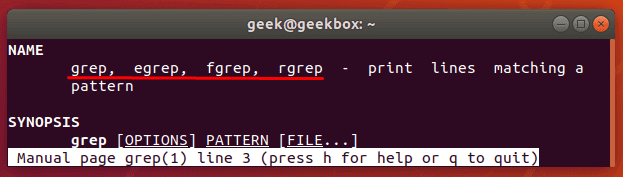
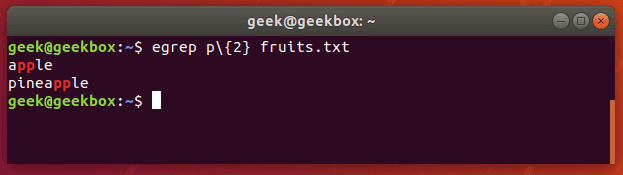
Как видно из вывода man grep (мануал по команде grep), все эти версии всего лишь разные названия основной команды. Например, egrep это тоже самое, что и grep E (помните, командная строка Linux регистрозависимая и команды grep e и grep E интерпретируются по разному). Этой команде в качестве шаблона передается расширенное регулярное выражение. Существует очень много разных ситуаций, где можно воспользоваться этой командой. Например, две команды ниже эквивалентны и выводят все строки, в которых есть две подряд идущих буквы «p».
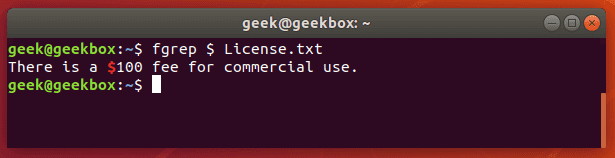
Fgrep это команда grep F, которая обрабатывает переданный шаблон как список фиксированных данных строкового типа. Эта команда полезна, когда в шаблоне используются зарезервированные для регулярных выражений символы, которые при обычно grep пришлось бы экранировать.
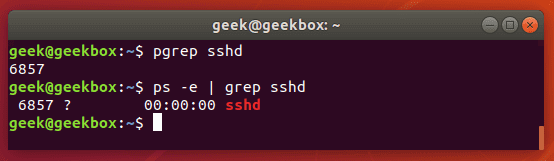
Команда pgrep используется для поиска конкретного процесса, запущенного в системе и возвращает идентификатор указанного процесса (PID). Команда ниже выводит PID процесса sshd. Почти такого же результата можно достичь если запустить команду ps e | grep sshd.
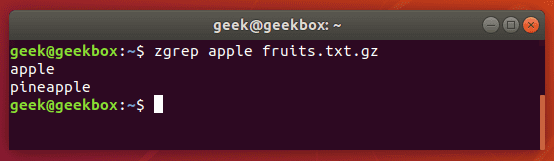
Команда zgrep используется для поиска указанного шаблона в заархивированных файлах, что очень удобно так как не приходится сначала разархивировать файл, а потом уже вести поиск.
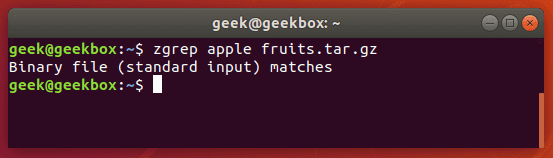
Zgrep также работает с tar архивами, но ограничивается лишь выводом информации о том, нашла ли она соответствие или нет. Это замечание мы сделали потому, что чаще всего gzip-ом архивируются tar файлы.
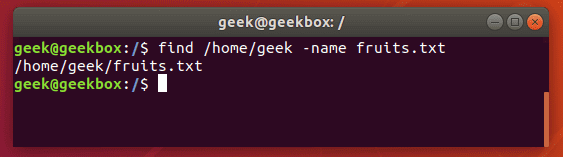
Разница между find и grep
Те, кто только начинает пользоваться командной строкой Linux должны понимать, что find и grep это две разные команды, которые имеют совсем разные функции, даже если оба используются для «поиска» чего-либо.
При поиске файлов grep-ом удобно пользоваться для фильтрации вывода команды find, как и было показано в начале материала. Но если нужно найти какой-то файл в системе по его названию или части названия (при этом используется маска *), то лучше всего обратиться к find. Она выведёт точно расположение искомого файла.
Рекурсивный поиск
Чтобы вести поиск по указанному шаблону среди всех файлов во всех папках и подпапках, команду grep нужно запустить с ключом r. Команда выведет все файлы, где найдено совпадение с указанным шаблоном, а также путь к ним. По умолчанию поиск ведется по текущей директории и поддиректориях.

Найти пробелы и табуляцию
Как и было отмечено ранее, если в шаблоне поиска содержится пробел, то мы должны выделять строку кавычками. Это мы можем использовать для поиска пробелов и знаков табуляции в файле. О том как вставить табуляцию чуть позже.

Есть несколько путей вставки табуляции, но некоторые дистрибутивы могут не поддерживать их. Как известно, в командной строке Linux клавиша TAB сама по себе дополняет введённую команду. Но если комбинировать клавиши ctrl+v, а затем нажать TAB, то система воспримет это как знак табуляции. $ grep » » sample.txt
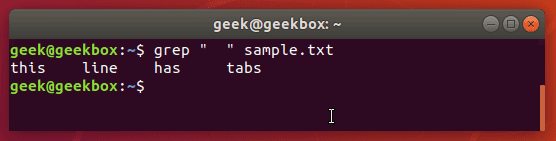
Эта фишка очень помогает при поиске среди конфигурационных файлов системы, так как значения от параметров отделяются табуляцией.
Использование регулярных выражений
Регулярные выражения сильно расширяют возможности команды grep, что позволяет нам вести более гибкий поиск. Далее мы рассмотрим несколько вариантов использования регулярных выражений.
[квадратные скобки] они используются чтобы проверить на соответствие одному из указанных символов.
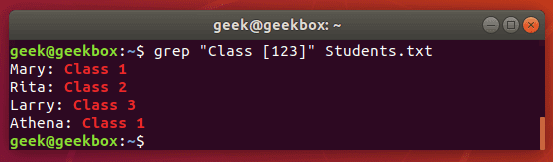
[-] знак дефиса означает диапазон значений. Это могут быть как буквы, так и цифры.
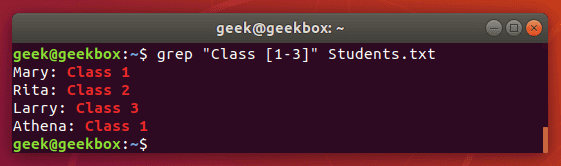
Вторая команда вывела то же, что и первая, но здесь мы обошлись знаком диапазона.
^ каретка используется для поиска строк, которые начинаются с указанного шаблона. Команда ниже выведет все строки, которые начинаются с буквы «А».
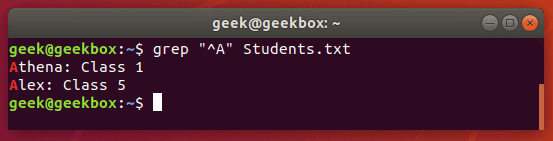
[^] но между квадратными скобками смысл каретки меняется. Здесь он исключает из поиска следующие за ней символы или диапазон символов.
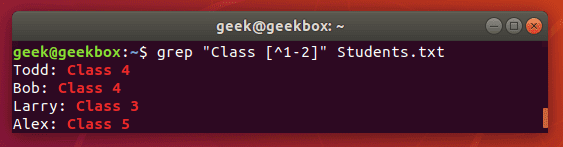
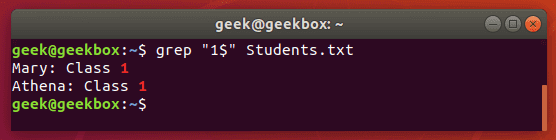
$ знак доллара означает конец строки. Команда выведет только те строки, в конце которых встречает указанный шаблон.
.точка обозначает один любой символ. Чтобы указать несколько любых символов, можно написать символ точку нужное количество раз.
Источник
Исключение терминов в Grep
Главное меню » Linux » Исключение терминов в Grep

Мы обнаружили два важных ключевых слова, используемых для исключения терминов из любого файла. –V используется для инвертирования совпадения; затем он выводит несовпадающие строки в тексте.
Предпосылка
Для выполнения этой функции нам необходимо, чтобы в нашей системе был установлен Linux, настроенный на виртуальной машине. Добавив имя пользователя и пароль, вы получите доступ к приложениям в операционной системе. Вам нужен терминал, чтобы открывать и запускать на нем команды.
Пример 1
Чтобы применить эту функцию к слову, нам нужен файл, существующий в нашей системе. Если у вас нет файлов, сначала создайте их. У нас есть файл с именем fileb.txt. Мы будем использовать команду cat для отображения текста.
Это изображение показывает вывод файла.
Если мы хотим исключить некоторые слова из текста, мы воспользуемся следующей командой, чтобы исключить слова из файла b.txt
В приведенной выше команде мы использовали –v, который инвертирует текст в запросе. Ubuntu – это слово, которое мы хотим исключить из данного текста. –I используется для чувствительности к регистру и является необязательной, если желаемый результат должен быть получен без использования –i. «|» используется для исключения или сопоставления точных слов. Вывод этой команды должен быть добавлен ниже.
В этом выводе вы увидели, что «ubuntu» удалена из файла. Чтобы извлечь из файла другое слово, например Linux, мы можем изменить данную команду.
Таким образом, одновременно будет исключено более одного слова.
Пример 2
В этом примере из файла удаляется вся строка. Целевое слово упоминается в команде, и команда работает таким образом, что слово сопоставляется с текстом в строке, и таким образом вся строка удаляется из файла. Синтаксис команды такой же, как описано выше в этом руководстве. Пусть у нас есть файл с именем file22.txt. Во-первых, мы отобразим все содержимое, чтобы соответствующий результат показал разницу.
Теперь применим команду, чтобы исключить всю строку из файла.
Команда будет применена таким образом, чтобы соответствовать целевому слову и отображать все строки, кроме той, которая содержит совпадение. Теперь вы можете видеть, что первой строки нет в текстовом файле.
Исключить термин из нескольких слов
В отличие от приведенных выше примеров, здесь мы упомянем несколько команд, чтобы исключить их из текстового файла. Cat и Grep действуют одинаково. Теперь с помощью данной команды мы разберемся с этой концепцией.
В этой команде –e используется более чем для одного термина в качестве входных данных в команде. Это удалит оба слова из текста. Первая команда подразумевает, что файл должен быть отображен, а затем удаляются слова, которые мы хотим исключить. Одновременно вторая команда будет использовать первым –v для удаления слов, написанных далее в команде.
Вот еще один способ исключения. Во-первых, мы исключаем одно слово, указав адрес файла, а после «|» введем второе слово.
Исключить файл
Подобно словам, мы также можем исключить файл из системы. Мы будем использовать следующую команду.
Эта команда удалит файл. Эта команда будет использовать ключевое слово «-exclude» для удаления файла. «* .Txt» означает, что файл имеет расширение «txt». Команда будет работать со всеми текстовыми файлами для поиска соответствующего файла, который присутствует в системе.
Исключить каталог с Word
Каталог также можно исключить, указав слово. Эта команда поможет сопоставить слово, присутствующее в любом текстовом файле каталога, а затем удалить соответствующий каталог или каталоги, содержащие это слово. Здесь мы не упоминаем имя файла в команде.
«Dir» представляет каталог в системе. –R показывает рекурсивную функцию. Чтобы внести какие-либо изменения в каталоги, мы всегда используем –R.
Мы процитируем другой пример, который показывает, что каталоги, содержащие слово «Auro», удаляются из системы.
Он покажет все каталоги, включая слово Auro.
Исключить слово с помощью каталога
Поскольку мы исключили каталог с помощью слова, мы также можем исключить слово с помощью каталога или указать полный путь к файлу.
В этой команде мы хотим исключить слово год. Чтобы представить каталог, мы напишем –R. Рассмотрим файл 20.txt, как показано ниже.
Теперь примените следующую команду, используя каталог в качестве входных данных.
Результат, полученный от этой команды, исключает слово год из вывода.
Переходим к другому примеру. Здесь мы исключим слово «grep» из каталога, используя следующую добавленную команду.
Заключение
Исключение термина – это альтернатива процессу сопоставления Grep. Это помогает удалить ненужные слова или строки из файлов, имеющихся в системе. Эта статья поможет вам избавиться от нежелательных слов.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Источник



