- Подсчитать общее количество вхождений с помощью grep
- Подсчет количества вхождений слова в текстовом файле
- Используем grep | wc
- Используем tr | grep
- Еще один пример
- Заключение
- 🐧 16 опций grep, которые помогут вам в реальном мире
- Синтаксис команды
- 1. Поиск в нескольких файлах
- 2. Поиск без учета регистра
- 3. Поиск всего слова
- 4. Проверка количества совпадений
- 5. Поиск в подкаталогах
- 6. Инверсивный поиск
- 7. Печать номеров строк
- 8. Ограниченный вывод
- 9. Отображение дополнительных строк
- 10. Список имен файлов
- 11. Точный вывод строк
- 12. Совпадение по началу строки
- 13. Совпадение по концу строки
- 14. Файл шаблонов
- 15. Указание нескольких шаблонов
- 16. Расширенные выражения
- Заключение
- Команда Grep в Linux (Поиск текста в файлах)
- Grep Command in Linux (Find Text in Files)
- В этой статье мы покажем вам, как использовать grep команду, на практических примерах и подробных объяснениях наиболее распространенных grep опций GNU .
- grep Синтаксис команды
- Поиск строки в файлах
- Инвертировать (исключить) совпадение
- Использование Grep для фильтрации выходных данных команды
- Рекурсивный поиск
- Показывать только имя файла
- Поиск без учета регистра
- Поиск полных слов
- Показать номера строк
- Количество совпадений
- Скрытый режим
- Основное регулярное выражение
- Расширенные регулярные выражения
- Поиск по шаблону нескольких строк
- Печать строк перед сопоставлением
- Печать строк после сопоставления
- Вывод
Подсчитать общее количество вхождений с помощью grep
grep -c полезен для определения количества встреч строк в файле, но он учитывает каждый случай только один раз в строке. Как посчитать несколько вхождений на строку?
Я ищу что-то более элегантное, чем:
grep’s -o будет выводить только совпадения, игнорируя строки; wc можно их посчитать
Это также будет соответствовать «иглам» или «многоигольным иглам».
Только отдельные слова:
Если у вас есть GNU Grep (всегда на Linux и Cygwin, иногда в других местах), вы можете рассчитывать выходные строки из grep -o : grep -o needle | wc -l .
С Perl, вот несколько способов, которые я нахожу более элегантными, чем ваш (даже после исправления ).
При использовании только инструментов POSIX одним из подходов, если это возможно, является разбиение ввода на строки с одним соответствием перед передачей его в grep. Например, если вы ищете целые слова, то сначала превратите каждый несловарный символ в новую строку.
В противном случае, нет стандартной команды для выполнения этой конкретной части обработки текста, поэтому вам нужно переключиться на sed (если вы мазохист) или awk.
Вот более простое решение, использующее sed и grep , которое работает со строками или даже регулярными выражениями, но не работает в нескольких угловых случаях с закрепленными шаблонами (например, оно находит два вхождения ^needle или \bneedle в needleneedle ).
Обратите внимание, что в приведенных выше заменах sed я имел \n в виду перевод строки. Это стандартно в части шаблона, но в тексте замены, для переносимости, используется замена на обратную косую черту для новой строки \n .
Источник
Подсчет количества вхождений слова в текстовом файле

Когда вы работаете с текстовым файлом в графическом редакторе, то можно увидеть количество вхождений слова, используя статистику, если она предоставляется редактором или, например, нажать Ctrl+F и увидеть количество найденных вхождений.
Иногда нужно выполнить подсчет вхождений слова или символов в файле, используя командую строку. Рассмотрим, как это можно сделать.
Используем grep | wc
Предположим, что у нас есть файл myfile.txt со следующим содержимым:
Воспользуемся командой grep и найдем вхождение слова « текст » в файле myfile.txt :
В результате будет выведено:
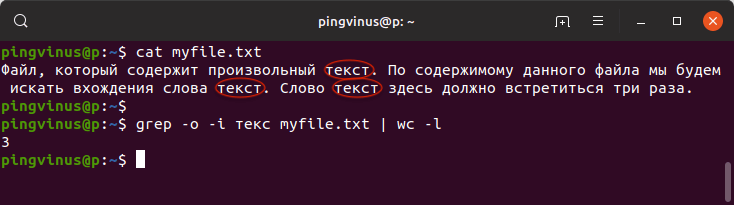
Описание команды:
Команда grep выполняет поиск слова « текст » в файле myfile.txt .
Опция -i — игнорировать регистр символов.
Опция -o — используется, чтобы возвращалось само найденное слово. Каждое найденное слово выводится на отдельной строке (в нашем случае каждое слово передается команде wc ).
Далее вывод команды grep направляется команде wc , так как используется оператор вертикальной черты | (конвейер).
Команда wc (от «word count») с опцией -l выполняет подсчет количества строк. То есть в нашем случае количество, найденных командной grep , слов.
Используем tr | grep
Для разнообразия воспользуемся еще одной командой, которая также выполняет подсчет количества вхождений строки в текстовом файле:
В результате будет выведено:
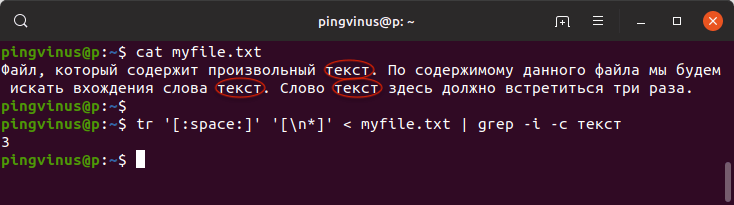
Описание команды:
Мы воспользовались командой tr (от «translate» или «transliterate»), которая используется для преобразования одних символов в другие. В нашем случае мы командной tr разбиваем файл на строки: все пробельные символы ( [:space:] ) заменяются на символ новой строки ( [\n*] ) .
Затем вывод команды tr направляется команде grep , так как используется конвейер |
Опция -c команды grep считает количество строк.
Еще один пример
Обращаю внимание на то, что описанные выше команды, ищут не отдельное слово, а именно вхождение слова (вхождение символов) в тексте. То есть, если в тексте встречается строка вида « Это хорошие помидоры », и мы ищем вхождение слова « помидор », то получим в результате одно вхождение, так как в нашем тексте есть эти символы.
Приведем пример. Выполним поиск в следующем файле:
В результате будет выведено:
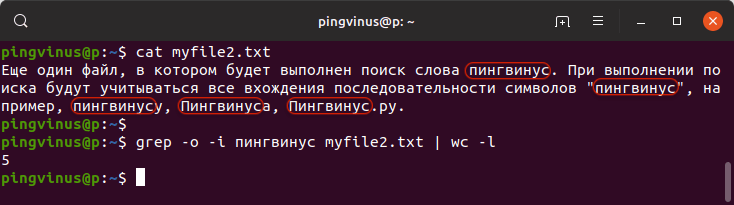
Аналогично командой tr
В результате будет выведено:
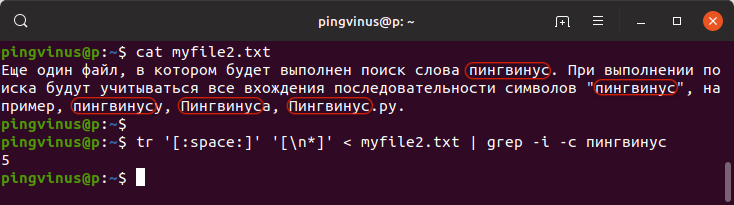
Заключение
Мы рассмотрели, как можно посчитать количество вхождений определенных символов в текстовом файле, используя командую строку. Вы также познакомились с некоторыми возможностями команд grep , wc и tr , и перенаправлением результата одной команды на вход другой — конвейером |
Источник
🐧 16 опций grep, которые помогут вам в реальном мире

Перевод публикуется с сокращениями, автор оригинальной статьи Abhishek Nair .
Мощь регулярных выражений в сочетании с поддерживаемыми опциями в grep делает это возможным.
Синтаксис команды
Grep ожидает шаблон и необязательные аргументы вместе со списком файлов, если они используются без конвейера.
1. Поиск в нескольких файлах
Grep позволяет искать заданный шаблон не только в одном, но и в нескольких файлах с помощью масок (например, знака «*»):
Из приведенного вывода можно заметить, что grep печатает имя файла перед соответствующей строкой, чтобы указать местонахождение шаблона.
2. Поиск без учета регистра
G rep предлагает искать паттерн, не глядя на его регистр. Используйте флаг -i, чтобы утилита игнорировала регистр:
3. Поиск всего слова
Зачастую вместо частичного совпадения необходимо полное соответствие поисковому слову. Это можно сделать, используя флаг -w:
4. Проверка количества совпадений
Иногда вместо фактического совпадения со строкой нам необходимо количество успешных совпадений, найденных grep. Этот результат можно получить, используя опцию -c:
5. Поиск в подкаталогах
Часто требуется выполнить поиск файлов не только в текущем рабочем каталоге, но и в подкаталогах. G rep позволяет это сделать с помощью флага -r:
Как можно заметить, grep проходит через каждый подкаталог внутри текущего каталога и перечисляет файлы и строки, в которых найдено совпадение.
6. Инверсивный поиск
Если вы хотите найти что-то несоответствующее заданному шаблону, grep и это умеет при помощи флага -v:
Можно сравнить вывод команды grep по одному и тому же шаблону и файлу с флагом -v или без него. С флагом печатается каждая строка, которая не соответствует шаблону.
7. Печать номеров строк
Если хотите напечатать номера найденных строк, чтобы узнать их позицию в файле, используйте опцию -n:
8. Ограниченный вывод
Для больших файлов вывод может быть огромным и тогда вам понадобится фиксированное количество строк вместо всей простыни. Можно использовать —m[num]:
Обратите внимание, как использование флага влияет на вывод для того же набора условий:
9. Отображение дополнительных строк
Иногда необходимо вывести не только строки по некоторому шаблону, но и дополнительные строки выше или ниже найденных для понимания контекста. Можно напечатать строку выше, ниже или оба варианта, используя флаги -A, -B или -C со значением num (количество дополнительных строк, которые будут напечатаны). Это применимо ко всем совпадениям, которые grep находит в указанном файле или в списке файлов.
Ниже показан обычный вывод grep , а также вывод с флагами. Обратите внимание, как grep интерпретирует флаги и их значения, а также изменения в соответствующих выходных данных:
- с флагом —A1 выведется 1 строка, следующая за основной;
- —B1 напечатает 1 строку перед основной;
- —C1 выведет по одной строке снизу и сверху.
10. Список имен файлов
Чтобы напечатать только имя файлов, в которых найден шаблон, используйте флаг -l:
11. Точный вывод строк
Если необходимо напечатать строки, которые точно соответствуют заданному шаблону, а не какой-то его части, применяйте в команде ключ -x:
В приведенном ниже примере file.txt содержится слово «support», а строки без точного совпадения игнорируются.
12. Совпадение по началу строки
Используя регулярные выражения, можно найти начало строки:
Обратите внимание, как использование символа «^» изменяет выходные данные. Знак «^» указывает начало строки, т.е. ^It соответствует любой строке, начинающейся со слова It. Заключение в кавычки может помочь, когда шаблон содержит пробелы и т. д.
13. Совпадение по концу строки
Эта полезная регулярка способна помочь найти по шаблону конец строки:
Обратите внимание, как меняется вывод, когда мы сопоставляем символ «.» и когда используем «$», чтобы сообщить утилите о строках, заканчивающихся на «.» (без тех, которые могут содержать символ посередине).
14. Файл шаблонов
Если у вас есть некий список часто используемых шаблонов, укажите его в файле и используйте флаг -f. Файл должен содержать по одному шаблону на строку.
В примере мы создали файл шаблонов pattern.txt с таким содержанием:
Чтобы это использовать, применяйте ключ -f:
15. Указание нескольких шаблонов
G rep позволяет указать несколько шаблонов с помощью -e:
16. Расширенные выражения
G rep поддерживает расширенные регулярные выражения или ERE (похожие на egrep) с использованием флага -E.
Использование ERE имеет преимущество, когда вы хотите рассматривать мета-символы как есть и не хотите заменять их строками. Использование -E с grep эквивалентно команде egrep.
Вот одно из применений ERE, когда необходимо вывести строки, например, из больших конфигурационных файлов. Здесь использовался флаг -v, чтобы не печатать строки, соответствующие шаблону ^(#|$).
Заключение
Приведенные выше примеры – лишь верхушка айсберга. G rep поддерживает целый ряд опций и может оказаться полезным инструментом в руках специалиста, который способен эффективно его использовать. Мы можем не только взять на вооружение приведенные выше примеры, но и комбинировать их, чтобы получить требуемый результат в различных условиях.
Для дальнейшего изучения утилиты и расширения кругозора стоит почитать мануал, выполнив в терминале команду man grep, или посетить страницу с официальной документацией .
Источник
Команда Grep в Linux (Поиск текста в файлах)
Grep Command in Linux (Find Text in Files)
В этой статье мы покажем вам, как использовать grep команду, на практических примерах и подробных объяснениях наиболее распространенных grep опций GNU .

Команда grep означает «глобальная печать регулярных выражений», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep считывает из стандартного ввода, которое обычно является выводом другой команды.
grep Синтаксис команды
Синтаксис grep команды следующий:
- OPTIONS — Ноль или более вариантов. Grep включает в себя ряд параметров, которые контролируют его поведение.
- PATTERN — Шаблон поиска.
- FILE — Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ на чтение к файлу.
Поиск строки в файлах
Основное использование grep команды — поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из /etc/passwd файла, вы должны выполнить следующую команду:
Вывод должен выглядеть примерно так:
Если строка содержит пробелы, вам необходимо заключить ее в одинарные или двойные кавычки:
Инвертировать (исключить) совпадение
Чтобы отобразить линии, которые не соответствуют шаблону, используйте параметр -v (или —invert-match ).
Например, чтобы напечатать строки, которые не содержат строку, которую nologin вы используете:
Использование Grep для фильтрации выходных данных команды
Выходные данные команды могут быть отфильтрованы с grep помощью сквозного трубопровода, и только те строки, которые соответствуют заданному шаблону, будут напечатаны на терминале.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользователь, www-data вы можете использовать следующую ps команду:
Вы также можете объединить несколько каналов в команду. Как вы можете видеть в выводе выше, есть также строка, содержащая grep процесс. Если вы не хотите, чтобы эта строка отображалась, передайте вывод другому grep экземпляру, как показано ниже.
Рекурсивный поиск
Для рекурсивного поиска шаблона, grep используйте -r опцию (или —recursive ). Когда эта опция используется, grep будет выполняться поиск по всем файлам в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы перейти по всем символическим ссылкам , вместо этого -r используйте -R опцию (или —dereference-recursive ).
Вот пример, показывающий, как искать строку baks.dev во всех файлах в /etc каталоге:
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете -R опцию, grep перейдите по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается -r из-за того, что файлы в sites-enabled каталоге Nginx являются символическими ссылками на файлы конфигурации внутри sites-available каталога.
Показывать только имя файла
Чтобы подавить grep вывод по умолчанию и печатать только имена файлов, содержащих сопоставленный шаблон, используйте параметр -l (или —files-with-matches ).
Команда ниже просматривает все файлы, заканчивающиеся .conf в текущем рабочем каталоге, и печатает только имена файлов, содержащих строку baks.dev :
Вывод будет выглядеть примерно так:
-l Вариант обычно используется в сочетании с рекурсивной опции -R :
Поиск без учета регистра
По умолчанию учитывается grep регистр. Это означает, что прописные и строчные символы рассматриваются как разные.
Чтобы игнорировать регистр при поиске, grep используйте -i опцию (или —ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не будет отображать никаких выходных данных, т.е. есть совпадающие строки:
Но если вы выполните поиск без учета регистра, используя -i опцию, он будет соответствовать как заглавным, так и строчным буквам:
Указание «Зебра» будет соответствовать «Зебра», «ZEbrA» или любой другой комбинации прописных и строчных букв для этой строки.
Поиск полных слов
При поиске строки grep будут отображаться все строки, в которых строка встроена в более крупные строки.
Например, если вы ищете «gnu», все строки, где «gnu» встроен в более крупные слова, такие как «cygnus» или «magnum», будут совпадать:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное не в словах), используйте параметр -w (или —word-regexp ).
Если вы выполните ту же команду, что и выше, включая -w опцию, grep команда вернет только те строки, которые gnu включены в качестве отдельного слова.
Показать номера строк
Опция -n (или —line-number ) указывает grep показывать номер строки, содержащей строку, которая соответствует шаблону. Когда эта опция используется, grep печатает совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из /etc/services файла, содержащего строку с bash префиксом с соответствующим номером строки, вы можете использовать следующую команду:
Вывод ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Количество совпадений
Чтобы напечатать количество совпадающих строк в стандартный вывод, используйте параметр -c (или —count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, которые имеют /usr/bin/zsh оболочку.
Скрытый режим
-q (Или —quiet ) говорит , grep чтобы работать в скрытом режиме , чтобы не показывать ничего на стандартный вывод. Если совпадение найдено, команда завершается со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве команды тестирования в if инструкции :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте ^ символ (каретка), чтобы соответствовать выражению в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Используйте $ символ (доллар), чтобы соответствовать выражению в конце строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом конце строки.
Используйте . символ (точка), чтобы соответствовать любому отдельному символу. Например, для сопоставления всего, что начинается с kan двух символов и заканчивается строкой roo , вы можете использовать следующий шаблон:
Используйте [ ] (скобки) для соответствия любому отдельному символу, заключенному в скобки. Например, найдите строки, содержащие accept или « accent , вы можете использовать следующий шаблон:
Используется [^ ] для соответствия любому отдельному символу, не заключенному в скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих co(any_letter_except_l)a , например coca , cobalt и так далее, но не будет совпадать со строками, содержащими cola ,
Чтобы избежать специального значения следующего символа, используйте \ символ (обратный слеш).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или —extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Ниже приведены некоторые примеры:
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
-o Опция используется для печати только строку соответствия.
Поиск по шаблону нескольких строк
Два или более шаблонов поиска могут быть объединены с помощью оператора ИЛИ | .
По умолчанию grep шаблон интерпретируется как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и их версии с обратной косой чертой должны использоваться.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в журнале Nginx файл ошибки:
Если вы используете опцию расширенного регулярного выражения -E , оператор | не должен быть экранирован, как показано ниже:
Печать строк перед сопоставлением
Чтобы напечатать определенное количество строк перед сопоставлением строк, используйте параметр -B (или —before-context ).
Например, чтобы отобразить пять строк начального контекста перед сопоставлением строк, вы должны использовать следующую команду:
Печать строк после сопоставления
Чтобы напечатать определенное количество строк после сопоставления строк, используйте параметр -A (или —after-context ).
Например, чтобы отобразить пять строк конечного контекста после сопоставления строк, вы должны использовать следующую команду:
Вывод
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
На странице руководства пользователя Grep можно узнать больше о Grep .
Источник



