- Команда Grep в Linux (поиск текста в файлах)
- Командный синтаксис grep
- Искать строку в файлах
- Инвертировать соответствие (исключить)
- Использование Grep для фильтрации вывода команды
- Рекурсивный поиск
- Показать только имя файла
- Поиск без учета регистра
- Искать полные слова
- Показать номера строк
- Подсчет совпадений
- Бесшумный режим
- Основное регулярное выражение
- Расширенные регулярные выражения
- Поиск нескольких строк (шаблонов)
- Строки печати перед матчем
- Печатать строки после матча
- Выводы
- Как использовать команду grep в Linux
- Как использовать команду grep в Linux
- Вы знали?
- Примеры команды grep в Linux и Unix
- Синтаксис
- Как мне использовать grep для поиска файла в Linux?
- Как использовать grep рекурсивно
- Как использовать grep для поиска только слов
- Как использовать grep для поиска двух разных слов
- Игнорировать регистр
- Как я могу посчитать строку, когда слова совпали
- Вывод
Команда Grep в Linux (поиск текста в файлах)
Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
В этой статье мы покажем вам, как использовать команду grep на практических примерах и подробных объяснениях наиболее распространенных опций GNU grep .
Командный синтаксис grep
Синтаксис команды grep следующий:
Пункты в квадратных скобках необязательны.
- OPTIONS — Ноль или более вариантов. Grep включает ряд опций , управляющих его поведением.
- PATTERN — Шаблон поиска.
- FILE — Ноль или более имен входных файлов.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Например, чтобы отобразить все строки, содержащие строку bash из файла /etc/passwd , вы должны выполнить следующую команду:
Результат должен выглядеть примерно так:
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
Инвертировать соответствие (исключить)
Чтобы отобразить строки, не соответствующие шаблону, используйте параметр -v (или —invert-match ).
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
Вы также можете объединить несколько каналов по команде. Как вы можете видеть в выходных данных выше, также есть строка, содержащая процесс grep . Если вы не хотите, чтобы эта строка отображалась, передайте результат другому экземпляру grep как показано ниже.
Рекурсивный поиск
Для рекурсивного поиска шаблона вызовите grep с параметром -r (или —recursive ). Когда используется этот параметр, grep будет искать все файлы в указанном каталоге, пропуская символические ссылки, которые встречаются рекурсивно.
Чтобы следовать по всем символическим ссылкам , вместо -r используйте параметр -R (или —dereference-recursive ).
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Если вы используете опцию -R , grep будет следовать по всем символическим ссылкам:
Обратите внимание на последнюю строку вывода ниже. Эта строка не печатается, когда grep вызывается с -r потому что файлы внутри каталога с sites-enabled Nginx являются символическими ссылками на файлы конфигурации внутри каталога с sites-available .
Показать только имя файла
Чтобы подавить вывод grep по умолчанию и вывести только имена файлов, содержащих совпадающий шаблон, используйте параметр -l (или —files-with-matches ).
Приведенная ниже команда выполняет поиск по всем файлам, заканчивающимся на .conf в текущем рабочем каталоге и выводит только имена файлов, содержащих строку linuxize.com :
Результат будет выглядеть примерно так:
Параметр -l обычно используется в сочетании с рекурсивным параметром -R :
Поиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Чтобы игнорировать регистр при поиске, вызовите grep с параметром -i (или —ignore-case ).
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
Но если вы выполните поиск без учета регистра с использованием параметра -i , он будет соответствовать как заглавным, так и строчным буквам:
Указание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
Чтобы вернуть только те строки, в которых указанная строка представляет собой целое слово (заключенное в символы, отличные от слов), используйте параметр -w (или —word-regexp ).
Если вы запустите ту же команду, что и выше, включая параметр -w , команда grep вернет только те строки, где gnu включен как отдельное слово.
Показать номера строк
Параметр -n (или —line-number ) указывает grep показывать номер строки, содержащей строку, соответствующую шаблону. Когда используется эта опция, grep выводит совпадения на стандартный вывод с префиксом номера строки.
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
Результат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Подсчет совпадений
Чтобы вывести количество совпадающих строк в стандартный вывод, используйте параметр -c (или —count ).
В приведенном ниже примере мы подсчитываем количество учетных записей, в которых в качестве оболочки используется /usr/bin/zsh .
Бесшумный режим
-q (или —quiet ) указывает grep работать в тихом режиме, чтобы ничего не отображать на стандартном выводе. Если совпадение найдено, команда завершает работу со статусом 0 . Это полезно при использовании grep в сценариях оболочки, где вы хотите проверить, содержит ли файл строку, и выполнить определенное действие в зависимости от результата.
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте символ ^ (каретка) для сопоставления выражения в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Используйте символ $ (доллар), чтобы найти выражение в конце строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом конце строки.
Используйте расширение . (точка) символ, соответствующий любому одиночному символу. Например, чтобы сопоставить все, что начинается с kan затем имеет два символа и заканчивается строкой roo , вы можете использовать следующий шаблон:
Используйте [ ] (скобки) для соответствия любому одиночному символу, заключенному в квадратные скобки. Например, найдите строки, содержащие accept или « accent , вы можете использовать следующий шаблон:
Используйте [^ ] для соответствия любому одиночному символу, не заключенному в квадратные скобки. Следующий шаблон будет соответствовать любой комбинации строк, содержащих co(any_letter_except_l)a , например coca , cobalt и т. Д., Но не будет соответствовать строкам, содержащим cola ,
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Чтобы интерпретировать шаблон как расширенное регулярное выражение, используйте параметр -E (или —extended-regexp ). Расширенные регулярные выражения включают в себя все основные метасимволы, а также дополнительные метасимволы для создания более сложных и мощных шаблонов поиска. Вот несколько примеров:
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
Параметр -o используется для печати только соответствующей строки.
Поиск нескольких строк (шаблонов)
Два или более шаблонов поиска можно объединить с помощью оператора ИЛИ | .
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
В приведенном ниже примере мы ищем все вхождения слов fatal , error и critical в файле ошибок журнала Nginx :
Если вы используете опцию расширенного регулярного выражения -E , то оператор | не следует экранировать, как показано ниже:
Строки печати перед матчем
Чтобы напечатать определенное количество строк перед совпадающими строками, используйте параметр -B (или —before-context ).
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
Печатать строки после матча
Чтобы напечатать определенное количество строк после совпадающих строк, используйте параметр -A (или —after-context ).
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
Выводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Подробнее о Grep можно узнать на странице руководства пользователя Grep .
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Источник
Как использовать команду grep в Linux
Как использовать команду grep в Linux
Команда grep используется для поиска текста. Он ищет в данном файле строки, содержащие совпадения с заданными строками или словами. Это одна из самых полезных команд в Linux и Unix-подобных системах. Давайте посмотрим, как использовать grep в Linux или Unix-подобных системах
Вы знали?
Название «grep» происходит от команды, используемой для выполнения аналогичной операции с использованием текстового редактора Unix / Linux. Ed: Утилиты grep — это семейство, которое включает в себя grep, egrep и fgrep для поиска. В большинстве случаев вам нужно использовать fgrep, поскольку он самый быстрый и просматривает только строки и слова. Однако набрать grep легко. Следовательно, это личный выбор.
g/re/p
Примеры команды grep в Linux и Unix
Ниже приведены некоторые стандартные команды grep, объясненные с примерами, которые помогут вам начать работу с grep в Linux, macOS и Unix:
- Найдите любую строку, которая содержит слово в имени файла в Linux: grep ‘word’ filename
- Выполните поиск слова ‘bar’ без учета регистра в Linux и Unix: grep -i ‘bar’ file1
- Найдите все файлы в текущем каталоге и во всех его подкаталогах в Linux по слову httpd: grep -R ‘httpd’ .
- Найдите и отобразите общее количество раз, когда строка ‘nixcraft’ появляется в файле с именем frontpage.md:: grep -c ‘nixcraft’ frontpage.md
Давайте подробно рассмотрим все команды и параметры.
Синтаксис
Синтаксис grep следующий:
grep ‘word’ filename
fgrep ‘word-to-search’ file.txt
grep ‘word’ file1 file2 file3
grep ‘string1 string2’ filename
cat otherfile | grep ‘something’
command | grep ‘something’
command option1 | grep ‘data’
grep —color ‘data’ fileName
grep [-options] pattern filename
fgrep [-options] words file
Как мне использовать grep для поиска файла в Linux?
Найдите /etc/passwd для пользователя boo, введите:
grep boo /etc/passwd
Примеры выходных данных::
Мы можем использовать fgrep/grep тобы найти все строки файла, содержащие определенное слово. Например, чтобы перечислить все строки файла с именем address.txt в текущем каталоге, которые содержат слово “California” выполните:
fgrep California address.txt
Обратите внимание, что приведенная выше команда также возвращает строки, в которых “California” является частью других слов, например “Californication” или “Californian”. Следовательно, передайте -w параметр с помощью команды grep/fgrep чтобы получить только строки, в которых “California” включено как целое слово:
fgrep -w California address.txt
Вы можете заставить grep игнорировать регистр слов, то есть сопоставить boo, Boo, BOO и все другие комбинации с -i параметром. Например, введите следующую команду:
grep -i «boo» /etc/passwd 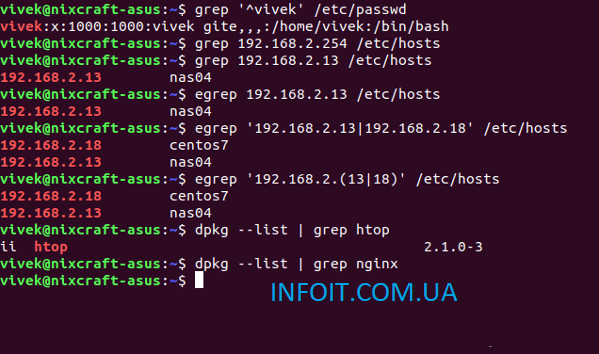
Последнийgrep -i «boo» /etc/passwd может работать следующим образом с помощью:
cat /etc/passwd | grep -i «boo»
Как использовать grep рекурсивно
Вы можете выполнять поиск рекурсивно, т.е. читать все файлы в каждом каталоге по строке “192.168.1.5”
$ grep -r «192.168.1.5» /etc/
ИЛИ
$ grep -R «192.168.1.5» /etc/
Примеры выходных данных:
Вы увидите результат для 192.168.1.5 в отдельной строке, перед которой будет указано имя файла (например /etc/ppp/options) в котором он был найден. Включение имен файлов в выходные данные можно подавить, используя -h следующее:
$ grep -h -R «192.168.1.5» /etc/
ИЛИ
$ grep -hR «192.168.1.5» /etc/
Примеры выходных данных:
Как использовать grep для поиска только слов
Когда вы ищете boo, grep будет соответствовать fooboo, boo123, barfoo35 и другим. Вы можете заставить команду grep выбирать только те строки, содержащие совпадения, которые образуют целые слова, т.е. соответствуют только boo word:
$ grep -w «boo» file
Как использовать grep для поиска двух разных слов
Используйте команду egrep следующим образом:
$ egrep -w ‘word1|word2’ /path/to/file
Игнорировать регистр
Мы можем заставить grep игнорировать различия в регистрах в шаблонах и данных. Например, когда я ищу «bar», соответствую «BAR», «Bar», «BaR»
$ grep -i ‘bar’ /path/to/file
В этом примере я собираюсь включить все подкаталоги в поиск:
$ grep -r -i ‘main’
Как я могу посчитать строку, когда слова совпали
Команда grep может сообщить, сколько раз шаблон был сопоставлен для каждого файла, используя -c (count) опцию:
$ grep -c ‘word’ /path/to/file
Передайте -n опцию, которая должна предшествовать каждой строке вывода с номером строки в текстовом файле, из которого он был получен:
$ grep -n ‘root’ /etc/passwd
Вывод
Команда grep очень универсальна, и многие новые пользователи Linux или Unix считают ее сложной. Поэтому я предлагаю вам также прочитать справочную страницу grep . Подведем итог большинству вариантов импорта:
Источник



