- grep — поиск в Linux, примеры
- 1. Немного про grep
- 2. Базовый синтаксис команды grep
- 3. Как использовать grep для поиска в файлах
- 4. Рекурсивное использование grep
- 5. Использование grep для поиска только целых слов
- 6. Как искать несколько различных слов
- 7. Подсчет количества строк, содержащих вхождение
- 8. Инвертный поиск
- 9. Как выводить только имена файлов в которых есть включение слова
- 10. Поиск всех файлов содержащих слово во всех файлах и поддиректориях
- 11. Вывод строк перед и после найденного вхождения
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Руководство по команде grep в Linux
- Про Linux за 5 минут | Что это или как финский студент перевернул мир?
- Для чего мы пользуемся grep-ом?
- Поиск строк
- Поиск по нескольким параметрам
- Разница между grep, egrep fgrep, pgrep, zgrep
- Разница между find и grep
- Рекурсивный поиск
- Найти пробелы и табуляцию
- Использование регулярных выражений
- Команда uniq Linux
- Синтаксис uniq
- Опции uniq
- Примеры использования uniq
- Выводы
grep — поиск в Linux, примеры
1. Немного про grep
Команда grep (global regular expression print) остается одной из наиболее универсальных команд в окружении командной строки Linux. Это происходит потому что grep является чрезвычайно мощной утилитой которая дает пользователям возможность сортировать ввод на основе сложных правил, тем самым делая ее популярным связующим звеном в конвейере команд. Grep в основном используется для поиска текста как в данных поступающих на стандартный вход, так и в указанных файлах на предмет строк содержащих указанные слова или подстроки.
2. Базовый синтаксис команды grep
Ниже представлены примеры использования grep с базовым синтаксисом:
3. Как использовать grep для поиска в файлах
Попробуем найти пользователя «vasya» в файле passwd. Для поиска в файле /etc/passwd информации о пользователе «vasya» необходимо использовать следующую команду:
Также мы можем попросить grep осуществлять поиск игнорируя регистр букв, то есть не делая различия между большими и маленькими буквами. Для этого используется параметр -i, как показано ниже:
4. Рекурсивное использование grep
Если у вас есть большое количество текстовых файлов в ряде директорий и поддиректорий, к примеру, конфигурационных файлов apache в /etc/apache2 и требуется найти файл где содержится определенный текст, то стоит использовать параметр -r чтобы осуществить рекурсивный поиск. То есть поиску будет осуществлен по всем файлам в иерархии директорий:
Также можно использовать этот параметр в верхнем регистре. То есть можно писать -R. Разница в том что при использовании -r не происходит обработка символических ссылок, а при использовании -R — происходит. Пример использования:
/etc/apache2/sites-available/debian-help.ru: ServerName debian-help.ru /etc/apache2/sites-available/debian-help.ru: ServerAlias www.debian-help.ru
Как можно видеть результат состоит из имени файла, где была найдена строка и самой строки. Включение в вывод имен файлов можно с легкостью подавить с помощью параметра -h, как показано ниже:
ServerName debian-help.ru ServerAlias www.debian-help.ru
5. Использование grep для поиска только целых слов
Когда вы ищите qwe, grep выберет все вхождения данного сочетания, к примеру, qwerty, qwe123, 345qwerty и множество других комбинаций. Вы можете указать, чтобы grep выбирал только те строки, которые содержат точное включение в виде целого слова. Для этого используйте параметр -w:
6. Как искать несколько различных слов
Для поиска двух или более различных слов вы можете использовать команду egrep следующим образом:
Либо вариант с просто grep:
7. Подсчет количества строк, содержащих вхождение
grep может сообщать сколько строк содержат указанное сочетание. Для этого воспользуйтесь параметром -c (count):
В дополнение, можно использовать параметр -n чтобы заставить grep выводить номера строк в файле, в которых было найдено включение:
8. Инвертный поиск
grep позволяет осуществлять поиск наоборот, то есть будут выведены все строки, кроме имеющих вхождение указанного слова и для этого используется параметр -v:
Можно исключить что-либо из вывода поиска применив конвейер:
9. Как выводить только имена файлов в которых есть включение слова
Для вывода только имен файлов нужно использовать параметр -l, к примеру, так:
10. Поиск всех файлов содержащих слово во всех файлах и поддиректориях
Если вам нужно осуществить поиск слова в любых формах во всех файлах в этой директории и всех содержащихся в ней тоже, то используйте сочетание описанных выше параметров:
11. Вывод строк перед и после найденного вхождения
Для вывода нескольких строк перед вхождением используется параметры -A, а после вождения -B.
К примеру, чтобы вывести 5 строк перед и 10 после найденного вхождения используйте команду:
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Руководство по команде grep в Linux
Читать между строк
10 минут чтения
То, что система Linux предоставляет пользователю большое многообразие разного функционала уже не секрет. На одном из прошлых материалов мы рассмотрели, как и где можно использовать команду find. В этой же статье мы на примерах разберём команду grep, мощный инструмент системных администраторов.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена

Про Linux за 5 минут | Что это или как финский студент перевернул мир?

Для чего мы пользуемся grep-ом?
Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле. Также можно передать вывод любой команды в grep, что сильно упрощает работу во время поиска и траблшутинга.
Возьмём команду ls. Сама по себе она выводит список всех файлов и папок.
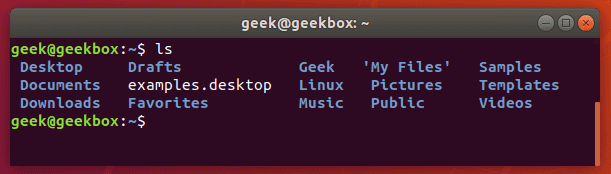
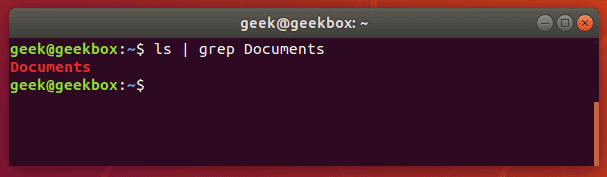
Но если нужно найти конкретную папку или один файл среди сотни других, то мы можем передать вывод команды ls в grep через вертикальную черту (|), а уже grep-у параметром передать нужное слово.
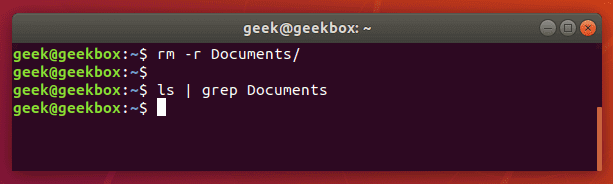
Если команда grep ничего не вернула, значит искомого файла/папки не существует в данной директории.
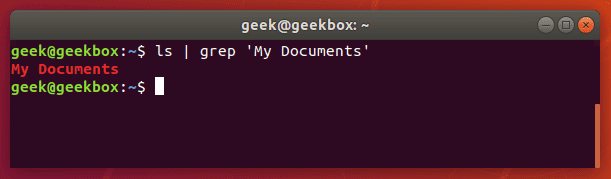
Поиск строк
Если же нужно найти не одно слово, а словосочетание или целое предложение, то параметр команды grep должно быть выделено кавычками. Grep поддерживает как одинарные, так и двойные кавычки.
Несмотря на то, что команда grep чаще используется как своего рода фильтр для других команд, но её также можно использовать отдельно как на примере ниже.
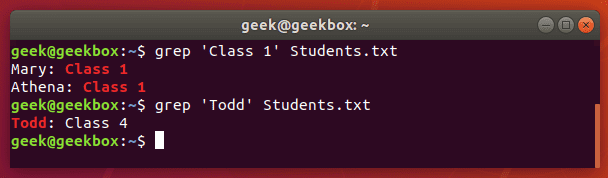
В этом примере мы вели поиск указанных в кавычках слов в файле Students.txt и команда grep успешно справилась со своей задачей.
Поиск по нескольким параметрам
Команде grep можно передавать не один параметр, а несколько. Для этого перед каждым аргументом пишется ключ e. Эту команду система понимает, как «или-или» и выводит все вхождения указанных слов. Заметьте, что кавычками выделена только строка, которая содержит пробел.

Разница между grep, egrep fgrep, pgrep, zgrep
Исторически разные версии Linux-а включали разновидности команды grep. Хотя в современных версия систем базовая команда grep поддерживает все возможности, которыми обладают egrep fgrep, pgrep, zgrep, но все же их тоже стоит рассмотреть.
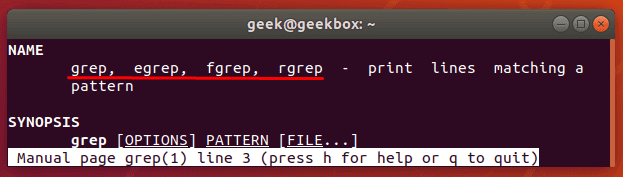
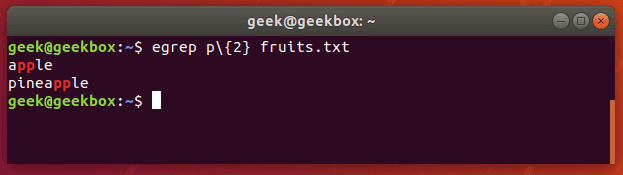
Как видно из вывода man grep (мануал по команде grep), все эти версии всего лишь разные названия основной команды. Например, egrep это тоже самое, что и grep E (помните, командная строка Linux регистрозависимая и команды grep e и grep E интерпретируются по разному). Этой команде в качестве шаблона передается расширенное регулярное выражение. Существует очень много разных ситуаций, где можно воспользоваться этой командой. Например, две команды ниже эквивалентны и выводят все строки, в которых есть две подряд идущих буквы «p».
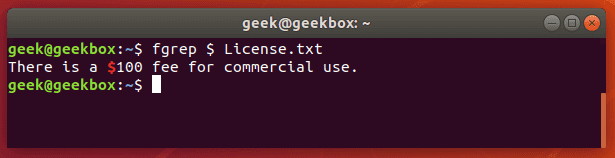
Fgrep это команда grep F, которая обрабатывает переданный шаблон как список фиксированных данных строкового типа. Эта команда полезна, когда в шаблоне используются зарезервированные для регулярных выражений символы, которые при обычно grep пришлось бы экранировать.
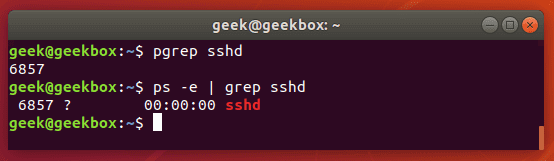
Команда pgrep используется для поиска конкретного процесса, запущенного в системе и возвращает идентификатор указанного процесса (PID). Команда ниже выводит PID процесса sshd. Почти такого же результата можно достичь если запустить команду ps e | grep sshd.
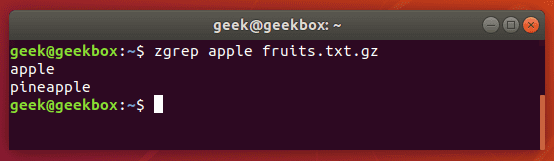
Команда zgrep используется для поиска указанного шаблона в заархивированных файлах, что очень удобно так как не приходится сначала разархивировать файл, а потом уже вести поиск.
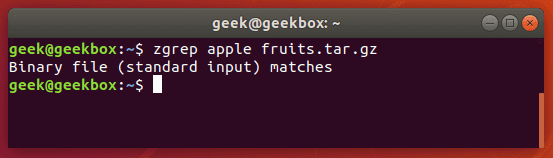
Zgrep также работает с tar архивами, но ограничивается лишь выводом информации о том, нашла ли она соответствие или нет. Это замечание мы сделали потому, что чаще всего gzip-ом архивируются tar файлы.
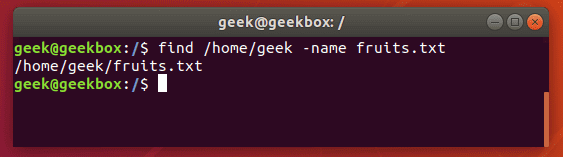
Разница между find и grep
Те, кто только начинает пользоваться командной строкой Linux должны понимать, что find и grep это две разные команды, которые имеют совсем разные функции, даже если оба используются для «поиска» чего-либо.
При поиске файлов grep-ом удобно пользоваться для фильтрации вывода команды find, как и было показано в начале материала. Но если нужно найти какой-то файл в системе по его названию или части названия (при этом используется маска *), то лучше всего обратиться к find. Она выведёт точно расположение искомого файла.
Рекурсивный поиск
Чтобы вести поиск по указанному шаблону среди всех файлов во всех папках и подпапках, команду grep нужно запустить с ключом r. Команда выведет все файлы, где найдено совпадение с указанным шаблоном, а также путь к ним. По умолчанию поиск ведется по текущей директории и поддиректориях.

Найти пробелы и табуляцию
Как и было отмечено ранее, если в шаблоне поиска содержится пробел, то мы должны выделять строку кавычками. Это мы можем использовать для поиска пробелов и знаков табуляции в файле. О том как вставить табуляцию чуть позже.

Есть несколько путей вставки табуляции, но некоторые дистрибутивы могут не поддерживать их. Как известно, в командной строке Linux клавиша TAB сама по себе дополняет введённую команду. Но если комбинировать клавиши ctrl+v, а затем нажать TAB, то система воспримет это как знак табуляции. $ grep » » sample.txt
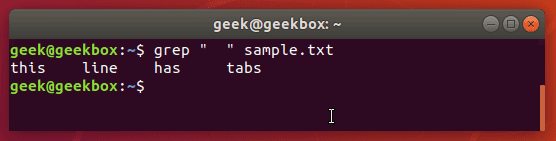
Эта фишка очень помогает при поиске среди конфигурационных файлов системы, так как значения от параметров отделяются табуляцией.
Использование регулярных выражений
Регулярные выражения сильно расширяют возможности команды grep, что позволяет нам вести более гибкий поиск. Далее мы рассмотрим несколько вариантов использования регулярных выражений.
[квадратные скобки] они используются чтобы проверить на соответствие одному из указанных символов.
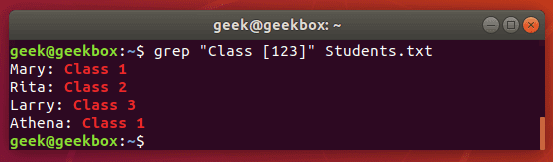
[-] знак дефиса означает диапазон значений. Это могут быть как буквы, так и цифры.
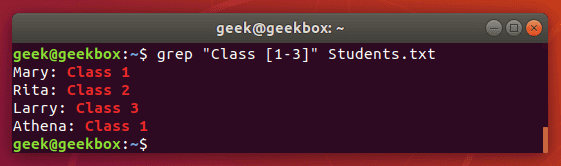
Вторая команда вывела то же, что и первая, но здесь мы обошлись знаком диапазона.
^ каретка используется для поиска строк, которые начинаются с указанного шаблона. Команда ниже выведет все строки, которые начинаются с буквы «А».
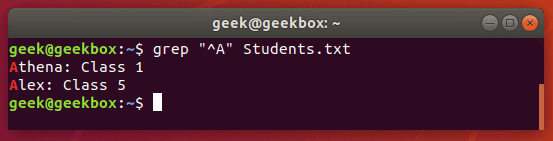
[^] но между квадратными скобками смысл каретки меняется. Здесь он исключает из поиска следующие за ней символы или диапазон символов.
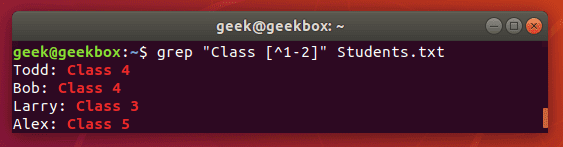
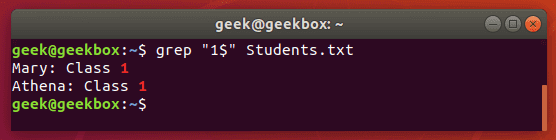
$ знак доллара означает конец строки. Команда выведет только те строки, в конце которых встречает указанный шаблон.
.точка обозначает один любой символ. Чтобы указать несколько любых символов, можно написать символ точку нужное количество раз.
Источник
Команда uniq Linux
Команда uniq предназначена для поиска одинаковых строк в массивах текста. При этом с найденными совпадениями пользователь может совершать множество действий — например, удалять их из вывода либо наоборот, выводить только их.
Работа команды осуществляется как с текстовыми файлами (в том числе, записями скриптов), так и с текстом, напечатанным в командной строке терминала.
Синтаксис uniq
Запись команды осуществляется следующим образом:
$ uniq опции файл_источник файл_для_записи
Файл источник указывает откуда надо читать данные, а файл для записи — куда писать результат. Но их указывать не обязательно. В примерах мы будем набирать текст, который нуждается в редактировании, прямо в командную строку терминала, воспользовавшись ещё одной командой — echo, и применив к ней опцию -e. Это будет выглядеть так:
echo -e [текст, слова в котором разделены управляющей последовательностью\\n] | uniq
Эта управляющая последовательность нужна, чтобы указать утилите, что каждое слово выводится в новой строке. Если указано только название файла источника, результат выполнения команды появится прямо в окне терминала. А при наличии выходного файла текст будет напечатан в теле документа.
Опции uniq
У команды uniq есть такие основные опции:
- -u (—unique) — выводит исключительно те строки, у которых нет повторов.
- -d (—repeated) — если какая-либо строка повторяется несколько раз, она будет выведена лишь единожды.
- -D — выводит только повторяющиеся строки.
- —all-repeated[=МЕТОД] — то же самое, что и -D, но при использовании этой опции между группами из одинаковых строк при выводе будет отображаться пустая строка. [=МЕТОД] может иметь одно из трех значений — none (применяется по умолчанию), separate или prepend.
- —group[=МЕТОД] — выводит весь текст, при этом разделяя группы строк пустой строкой. [=МЕТОД] имеет значения separate (по умолчанию), prepend, append и both, среди которых нужно выбрать одно.
Вместе с основными опциями могут применяться дополнительные. Они нужны для более тонких настроек работы команды:
- -f (—skip-fields=N) — будет проведено сравнение полей, начиная с номера, который следует после указанного вместо буквы N. Поля — это слова, хотя, называть их словами в прямом смысле слова нельзя, ведь словом команда считает любую последовательность символов, отделенную от других последовательностей пробелом либо табуляцией.
- -i (—ignore-case) — при сравнении не будет иметь значение регистр, в котором напечатаны символы (строчные и заглавные буквы).
- -s (—skip-chars=N) — работает по аналогии с -f, однако, игнорирует определенное количество символов, а не строк.
- -c (—count) — в начале каждой строки выводит число, которое обозначает количество повторов.
- -z (—zero-terminated) — вместо символа новой строки при выводе будет использован разделитель строк NULL.
- -w (—check-chars=N) — указание на то, что нужно сравнивать только первые N символов в строках.
Примеры использования uniq
Прежде всего следует отметить главную особенность команды uniq — она сравнивает только строки, которые находятся рядом. То есть, если две строки, состоящие из одинакового набора символов, идут подряд, то они будут обнаружены, а если между ними расположена строка с отличающимся набором символов — то не будут поэтому перед сравнением желательно отсортировать строки с помощью sort. Без задействования файлов uniq работает так:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq

После команды uniq можно использовать её опции. Вот пример вывода, где не просто удалены повторы, но и указано количество одинаковых строк:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq -c

Теперь применим команду к тексту, который находится в файле.
uniq —all-repeated=prepend text-example.txt

Как можно заметить, глядя на снимок экрана, команда вывела в качестве повторяющихся только вторую и третью группу строк.

Причина этого — незаметный глазу символ пробела, который стоит в конце одной из строк первой группы. Нужно быть предельно внимательным при использовании uniq, чтобы получить качественный результат.
Используемая опция —all-repeated=prepend выполнила свою работу — добавила пустые строки в начало, в конец и между группами строк. Теперь попробуем сравнить только первые 5 символов в каждой строке.
echo -e небо исполосовано молниями\\nоблака на небе\\nоблака разогнал ветер\\nоблака закрыли солнце\\nсолнце светит ярко\\nзвезды кажутся огромными | uniq -w5

Как видно на скриншоте, повторяющиеся строки, которые начинались словом «облака», были удалены. Осталась только первая из них. Вывод только уникальных строк с использованием опции -u выглядит так:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq -u

Чтобы проигнорировать определенное количество символов в начале одинаковых строк, воспользуемся опцией —skip-chars. В данном случае команда пропустит слово «облака», сравнив слова «перистые» и «белые».
echo -e небо\\nоблака перистые\\nоблака перистые\\nоблака белые\\nсолнце\\nзвезды | uniq —skip-chars=6

А вот наглядная демонстрация отличий при использовании опции —group с разными значениями. both добавило пустые строки как перед текстом, так и после него, а также между группами строк.
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq —group=both

Тогда как append не добавило пустую строку перед текстом:
echo -e небо\\nоблака\\nоблака\\nоблака\\nсолнце\\nзвезды | uniq —group=append

Выводы
Команда uniq linux пригодится тем, кто часто и много работает с массивами текста, не имея возможности вычитывать их самостоятельно. Следует заметить, что не все версии uniq работают исправно, поэтому иногда результат выдачи может отличаться от ожидаемого.
Свои вопросы относительно использования команды, а также замечания и пожелания оставляйте в комментариях.
Источник



