- Linux для человеков!
- Обзоры
- Фотогалереи
- Помощь при использовании сайта
- Новое из блога
- Перекодировка текстовых файлов из cp1251 в UTF-8 с помощью iconv
- Конвертирование файлов в кодировку UTF-8 в Linux
- Конвертирование файлов из UTF-8 в ASCII
- Конвертирование нескольких файлов в кодировку UTF-8
- Одминский блог
- Смена кодировки сайта из CP1251 на UTF-8
- Смена кодировки файлов в Ubuntu, а так же iconv и большие файлы
- iconv и большие файлы
- akost / convert.sh
- This comment has been minimized.
- Batname commented Apr 15, 2014
- This comment has been minimized.
- FernandoBasso commented May 7, 2015
- This comment has been minimized.
- vkdimitrov commented Aug 4, 2015
- This comment has been minimized.
- ranold commented Apr 7, 2016
- This comment has been minimized.
- nymo commented Jan 20, 2017
- This comment has been minimized.
- obojdi commented Feb 17, 2017
- This comment has been minimized.
- anonymous2ch commented Feb 27, 2017
Linux для человеков!
Обзоры
Фотогалереи
Помощь при использовании сайта
Новое из блога
Перекодировка текстовых файлов из cp1251 в UTF-8 с помощью iconv
В Windows по умочанию используется кодировка символов CP1251, чем иногда доставляет проблем пользователям других, нормальных ОС, которые давно перешли на юникод и забыли о проблемах с кодировками как страшный сон. Но пользователи Windows как американцы, не знают, что существуют другие страны ОС и сохраняют субтитры в CP1251 что делает их нечитабельными для других.
Для решения этой проблемы есть iconv который как раз и служит для перекодировки текстовых файлов из одной кодировки в другую. Во всех почти дистрибутивах данный пакет устанавливается по умолчанию, но если его вдруг не оказалось — установите его с помощью вашего пакетного менеджера.
Для перекодировки достаточно ввести всего одну команду в терминале, а именно:
Поясню: ключ «f» задает исходную кодировку в которой файл находится сейчас, ключ «t» указывает целевую кодировку, ключ «o» задает путь для сохранения перекодированного файла.
Вот, все очень просто. Так же вы можете таким образом кодировать любые текстовые файлы. Часто и тексты песен попадаются с такой неприятной особенностью.
Недавно узнал более простой и понятный способ перекодировки текстовых файлов — с помощью enconv.
Не буду приводить полного синтаксиса и описания всех ключей. Для перекодировки достаточно одного, например:
С помощью данной команды мы перегнали текст в UTF-8. Да, именно, просто перегнали без необходимости указания исходной кодировки. Все просто, указываем лишь ту которую хотим получить. Желательно сделать резервную копию файла, так как насколько я понял enconv’у нельзя задать выходной файл и изменяться кодировка будет прямо в исходном файле.
Если у кого то есть еще какие то методы перекодировки текстовых файлов — прошу в каменты.
Источник
Конвертирование файлов в кодировку UTF-8 в Linux
Оригинал: How to Convert Files to UTF-8 Encoding in Linux
Автор: Aaron Kili
Дата публикации: 2 ноября 2016 года
Перевод: А. Кривошей
Дата перевода: ноябрь 2017 г.
В этом руководстве мы рассмотрим кодировки символов и разберем несколько примеров преобразования файлов из одной кодировки в другую с помощью утилиты командной строки. Затем мы покажем, как преобразовать файлы в Linux из любой кодировки (charset) в UTF-8.
Как вы, наверное, уже знаете, компьютер не понимает и не хранит информацию в виде букв, цифр или чего-либо еще. Он работает только с битами. Бит имеет только два возможных значения — 0 или 1, true или false, да или нет. Все остальное кодируется последовательностями битов.
Простыми словами, кодировка символов — это способ кодировки различных символов определенными последовательностями нулей и единиц. Когда мы вводим текст и сохраняем его в файл, слова и предложения, которые мы набираем, состоят из разных символов, а символы преобразуются в биты с помощью кодировки.
Существуют различные схемы кодирования, такие как ASCII, ANSI, Unicode и другие. Ниже приведен пример кодировки ASCII.
В Linux для преобразования текста из одной кодировки в другую используется утилита командной строки iconv.
Вы можете проверить кодировку файла с помощью команды file, используя флаг -i или -mime, который печатает строку типа mime, как в приведенных ниже примерах:

Синтаксис команды iconv следующий:
Где -f или —from-code задает входную кодировку, а -t или —to-encoding задает конечную кодировку.
Для того, чтобы вывести список всех доступных опций, введите:
Конвертирование файлов из UTF-8 в ASCII
Далее мы научимся конвертировать текст из одной кодировки в другую. Приведенная ниже команда преобразует текст из ISO-8859-1 в кодировку UTF-8.
Рассмотрим файл input.file, который содержит следующие символы:
(Прим: вы увидите эти символы на снимке ниже)
Начнем с проверки кодировки файла, затем просмотрим его содержимое. Мы можем преобразовать все символы в кодировку ASCII.
После запуска команды iconv мы затем проверяем содержимое выходного файла и новую кодировку, как показано ниже.
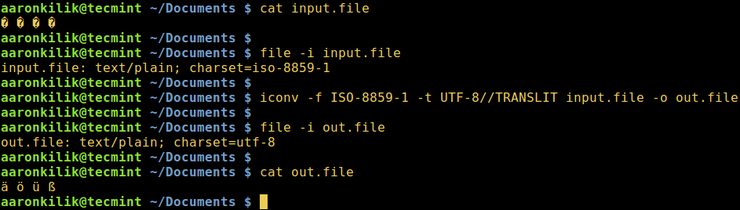
Примечание. Если в команду добавлена строка //IGNORE, то символы, которые не могут быть преобразованы, и ошибка выводятся после преобразования.
Далее, если добавлена строка //TRANSLIT, как в приведенном выше примере (ASCII//TRANSLIT), преобразуемые символы при необходимости и по возможности транслитерируются. Это означает, что если символ не может быть представлен в целевой кодировке, его можно аппроксимировать одним или несколькими похожими символами.
Далее, любой символ, который не может быть транслитерирован и которого нет в целевой кодировке, заменяется в выводе вопросительным знаком (?).
Конвертирование нескольких файлов в кодировку UTF-8
Возвращаясь к основной теме нашей статьи, мы можем написать небольшой скрипт для преобразования нескольких или всех файлов в каталоге в кодировку UTF-8, под названием encoding.sh:
Сохраните этот файл и сделайте скрипт исполняемым. Запускайте его из той директории, где расположены ваши файлы.
Важное замечание. Вы также можете также использовать этот скрипт для преобразования нескольких файлов из одной заданной кодировки в другую (любую), просто меняйте со значения переменных FROM_ENCODING и TO_ENCODING, не забывая об имени выходного файла «$
Для получения дополнительной информации почитайте руководство iconv:
Подводя итог этой статье, необходимо отметить, что понимание способов преобразования текста из одной кодировки в другую — это знания, необходимые каждому пользователю компьютера, а тем более программистам, когда дело касается работы с текстами.
Если вы хотите лучше понять проблему кодировок символов, прочитайте следующие статьи:
Источник
Одминский блог
Блог о технологиях, технократии и методиках борьбы с граблями
Смена кодировки сайта из CP1251 на UTF-8
Перевозил тут пачку сайтов с LAMP на LNAMP, где фронтэндом выступает NGINX. И все бы ничего, если бы не пачка статических сателлитов в кодировке Windows-1251 (cp1251).
Как тут прикололся девака – при анализе сайта, надо сначала чекать кодировку и в случае обнаружения кодировки сайта cp1251 – проверку возраста можно не осуществлять. Но, тем не менее, в инетах до сих пор встречаются такие мастадонты, которые клепают сайты в кодировке CP1251.
Под апачем, при добавлении сайта в ISP Panel это даже не заметишь, а вот при попытке добавить этот же сайт в Vesta CP, получаешь гемор на задницу с крикозябрами. Поэтому надо редактировать конфиг Nginx, предварительно прикрутив туда виндовую кодировку. Но, насколько я помню, у меня этот танец с бубнами не задался и в тот раз, я просто повесил саты на LAMP.
Так что оставалось либо плясать с бубнами вокруг прикручивания виндовой кодировки к NGINX, либо перекодивать файлы в родную для нжинкса UTF-8. Сделать это можно средствами текстового редактора Notepad++ путем перевода кодировки документа и последующего сохранения; либо же в самом линухе. Как я выше заметил, саты статические, то есть на файлах, без использования базы данных. Поэтому перекодировать надо было именно файлы. С базой данных все происходило бы несколько иначе.
Перекодировка файла из CP1251 в UTF-8 производится в консоли через команду iconv
# iconv -f cp1251 -t utf8 FILE-CP1251 -o FILE-UTF8
либо же можно переписать файл в самого себя
# iconv -f cp1251 -t utf8 file.txt -o file.txt
Но поскольку мне надо было перекодировать большое число файлов php, содержащихся в разных папках, то мне пришлось составить небольшое предложение:
# find /path-to-files/ -type f -name \*php -exec iconv -f cp1251 -t utf-8 ‘<>‘ -o ‘<>‘ \;
Конвертит все в лет.
Для конвертации кодировок есть еще утилита enconv, входящая в состав пакета enca – вот он как раз конвертит сам в себя по умолчанию, перезаписывая файл выходной кодировкой:
# enconv -c file.txt
но, к сожалению, я его не смог подружить с русским языком, т.к даже при указании языка через ключик -L russian скрипт матерился на ошибки. Но с другой стороны, все нормально решилось и через iconv
Источник
Смена кодировки файлов в Ubuntu, а так же iconv и большие файлы
Давно в категории «Ubuntu» у меня не было материалов. Сегодня я исправлюсь и выпущу сразу две статьи. Итак, начнём. вам приходилось менять кодировку текстовых файлов в linux’e? А что если объем такого файла больше 10 Gb?!
Что бы изменить кодировку файла нужно использовать замечательную утилиту iconv. В параметрах необходимо указывать исходную кодировку, а в этом нам поможет команда:
Ну а далее вот такие действия:
iconv -f WINDOWS-1251 -t UTF-8 -o output_file.txt original_file.txt
- -f WINDOWS-1251 — исходная кодировка,
- -t UTF-8 — конечная
- -o output_file.txt — куда выводить результат
- original_file.txt — исходный файл
Остальные ключики как обычно в man iconv.
iconv и большие файлы
Для быстрого выполнения процесса кодировки, iconv загружает файл в оперативную память и в swap. Но это работает только для небольших файлов. Если файл уж совсем большой, а ОЗУ не особо, то вы прост получите ошибку, мол «слишком большой файл», звиняйте хлопцы. Где взять такой файл? К примеру это может быть выборка из БД ( игры для ipad, PC, PSP или другие данные)
Вот здесь предлагают различные решения данного вопроса: и скриптами, и разбивка на части, вывод в потоки, а потом обратно сборка в файл. Лично мне понравилось весьма простое решение: команда split — она позволяет разбить текстовый файл на более мелкие, а дальше с ними работать как угодно можно.
В простом варианте чтобы разбить файл на куски объёмом по 1Gb выполнить:
Это самые просты решения, эти команды можно использовать в различных скриптах и получить от этого много кайфов. Надеюсь эта заметка вам чем-то помогла.
Источник
akost / convert.sh
| #! /bin/bash |
| # Recursive file convertion windows-1251 —> utf-8 |
| # Place this file in the root of your site, add execute permission and run |
| # Converts *.php, *.html, *.css, *.js files. |
| # To add file type by extension, e.g. *.cgi, add ‘-o -name «*.cgi»‘ to the find command |
| find ./ -name » *.php » -o -name » *.html » -o -name » *.css » -o -name » *.js » -type f | |
| while read file |
| do |
| echo » $file « |
| mv $file $file .icv |
| iconv -f WINDOWS-1251 -t UTF-8 $file .icv > $file |
| rm -f $file .icv |
| done |
This comment has been minimized.
Copy link Quote reply
Batname commented Apr 15, 2014
This comment has been minimized.
Copy link Quote reply
FernandoBasso commented May 7, 2015
Great script. Works perfectly, even on cygwin (which I have to use at work). Thanks a lot.
This comment has been minimized.
Copy link Quote reply
vkdimitrov commented Aug 4, 2015
This comment has been minimized.
Copy link Quote reply
ranold commented Apr 7, 2016
This comment has been minimized.
Copy link Quote reply
nymo commented Jan 20, 2017
Thanks! Really good script.
This comment has been minimized.
Copy link Quote reply
obojdi commented Feb 17, 2017
Confirmed working on cygwin, many thanks @akost!
This comment has been minimized.
Copy link Quote reply
anonymous2ch commented Feb 27, 2017
That script is bad. since iconv doesn’t detect if file is already UTF-8. So it will ruin your files if run on directory with files in mixed encodings. Running iconv more than once is guaranteed to screw your files too.
What you actually should use for this operation is enca, since it will correctly detect input encoding and act accordingly.
Источник



