Команда Diff в Linux
diff — это утилита командной строки, которая позволяет сравнивать два файла построчно. Он также может сравнивать содержимое каталогов.
Команда diff обычно используется для создания патча, содержащего различия между одним или несколькими файлами, которые можно применить с помощью команды patch .
Как использовать команду diff
Синтаксис команды diff следующий:
Команда diff может отображать вывод в нескольких форматах, наиболее распространенными из которых являются обычный, контекстный и унифицированный формат. Вывод включает информацию о том, какие строки в файлах необходимо изменить, чтобы они стали идентичными. Если файлы совпадают, вывод не производится.
Чтобы сохранить вывод команды в файл, используйте оператор перенаправления:
В этой статье мы будем использовать следующие два файла, чтобы объяснить, как работает команда diff :
Нормальный формат
В простейшей форме, когда команда diff запускается для двух текстовых файлов без каких-либо параметров, она производит вывод в нормальном формате:
Результат будет выглядеть примерно так:
Обычный выходной формат состоит из одного или нескольких разделов, в которых описываются различия. Каждый раздел выглядит так:
0a1 , 2d2 и 4c4,5 — это команды изменения. Каждая команда изменения содержит следующее слева направо:
- Номер строки или диапазон строк в первом файле.
- Особый символ изменения.
- Номер строки или диапазон строк во втором файле.
Символ изменения может быть одним из следующих:
- a — Добавьте линии.
- c — Измените линии.
- d — Удалить строки.
За командой изменения следуют полные строки, которые удаляются ( ) и добавляются в файл ( > ).
- 0a1 — добавить строку 1 второго файла в начало file1 (после строки 0 ).
- > Kubuntu — Строка из второй строки, которая добавляется в первый файл, как описано выше.
- 2d2 — Удалить строку 2 в первом файле. 2 после символа d означает, что если строку не удалить, она появится на строке 2 второго файла.
- — удаленная строка.
- 4c4,5 — Заменить (изменить) строку 5 в первом файле на строки 4-5 из второго файла.
- — строка в первом заменяемом файле.
- — — Разделитель.
- > Arch Linux и > Centos — Строки из второго файла, заменяющие строку в первом файле.
Формат контекста
Когда используется формат вывода контекста, команда diff отображает несколько строк контекста вокруг строк, которые различаются между файлами.
Параметр -c указывает diff выводить вывод в контекстном формате:
Вывод начинается с имен и меток времени сравниваемых файлов, а также с одного или нескольких разделов, описывающих различия. Каждый раздел выглядит так:
- from-file-line-numbers и to-file-line-numbers — Номера строк или разделенный запятыми диапазон строк в первом и втором файле, соответственно.
- from-file-line и to-file-line — Строки, которые различаются, и строки контекста:
- Строки, начинающиеся с двух пробелов, являются строками контекста, одинаковыми в обоих файлах.
- Строки, начинающиеся со знака минуса ( — ), — это строки, которые ничего не соответствуют во втором файле. Во втором файле отсутствуют строки.
- Строки, начинающиеся с символа плюса ( + ), — это строки, которые ничего не соответствуют в первом файле. В первом файле отсутствуют строки.
- Строки, начинающиеся с восклицательного знака ( ! ), — это строки, которые меняются между двумя файлами. Каждая группа строк, начинающаяся с ! из первого файла имеет соответствующее совпадение во втором файле.
Давайте объясним наиболее важные части вывода:
- В этом примере у нас есть только один раздел, описывающий различия.
- *** 1,6 **** и — 1,7 —- сообщает нам диапазон строк из первого и второго файлов, которые включены в этот раздел.
- Строки Ubuntu , Debian , Fedora и последняя пустая строка в обоих файлах одинаковы. Эти строки начинаются с двойного пробела.
- Строка — Arch Linux из первого файла ничего не соответствует во втором файле. Хотя эта строка также существует во втором файле, позиции другие.
- Строка + Kubuntu из второго файла ничего не соответствует в первом файле.
- Линия ! CentOS из первого файла и строк ! Arch Linux и ! CentOS из второго файла меняются между файлами.
По умолчанию количество контекстных строк по умолчанию равно трем. Чтобы указать другой номер, используйте параметр -C ( —contexts ):
Единый формат
Унифицированный выходной формат — это улучшенная версия контекстного формата, обеспечивающая меньший размер вывода.
Используйте параметр -u чтобы указать diff для печати вывода в едином формате:
Вывод начинается с имен и отметок времени файлов и одного или нескольких разделов, описывающих различия. Каждый раздел имеет следующую форму:
- @@ from-file-line-numbers to-file-line-numbers @@ — Номер строки или диапазон строк из первого и второго файлов, включенных в этот раздел.
- line-from-files — строки, которые отличаются и строки контекста:
- Строки, начинающиеся с двух пробелов, являются строками контекста, одинаковыми в обоих файлах.
- Строки, начинающиеся с символа минуса ( — ), — это строки, которые удаляются из первого файла.
- Строки, начинающиеся с символа плюса ( + ), — это строки, добавленные из первого файла.
Игнорировать регистр
Как вы могли заметить в приведенных выше примерах, команда diff по умолчанию чувствительна к регистру.
Используйте параметр -i чтобы указать diff игнорировать регистр:
Выводы
Сравнение текстовых файлов на предмет различий — одна из самых распространенных задач системных администраторов Linux.
Команда diff сравнивает файлы построчно. Для получения дополнительной информации введите в терминале man diff .
Если у вас есть вопросы, оставьте комментарий ниже.
Источник
Сравнение файлов в консоли Linux
Нужно увидеть различия между двумя ревизиями текстового файла? Тогда diff — это команда, которая вам нужна. Из этого туториала вы узнаете, как легко использовать diff в Linux и macOS.
Погружение в diff
Команда diff сравнивает два файла и выдает список различий между ними. Чтобы быть более точным, он создает список изменений, которые необходимо внести в первый файл, чтобы он соответствовал второму файлу. Если вы будете иметь это в виду, вам будет легче понять вывод diff. Команда diff была разработана для поиска различий между файлами исходного кода и для вывода результатов, которые могут быть прочитаны и обработаны другими программами, такими как команда patch . В этом уроке мы рассмотрим наиболее полезные способы использования diff .
Давайте углубимся и проанализируем два файла. Порядок файлов в командной строке определяет, какой файл diff считает «первым файлом», а какой — «вторым файлом». В приведенном ниже примере alpha1 — это первый файл, а alpha2 — второй файл. Оба файла содержат фонетический алфавит, но второй файл, alpha2, подвергся некоторому дальнейшему редактированию, так что эти два файла не идентичны.
Мы можем сравнить файлы с этой командой. Введите diff, пробел, имя первого файла, пробел, имя второго файла и нажмите клавишу ВВОД.
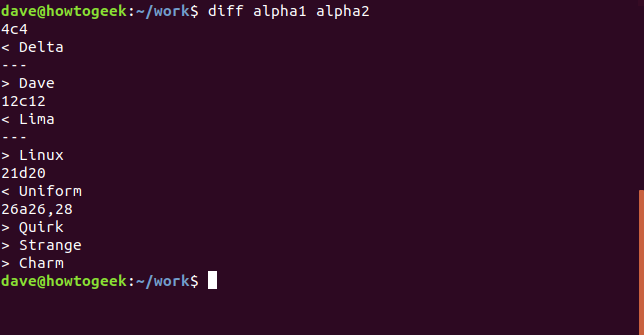
Как мы анализируем этот результат? Если вы знаете, что искать, это не так уж плохо. Каждое различие перечисляется по очереди в одном столбце, и каждое различие помечается. Ярлык содержит цифры по обе стороны от буквы, например 4c4. Первое число — это номер строки в alpha1, а второе — номер строки в alpha2. Буква в середине может быть:
- c: Строка в первом файле должна быть изменена, чтобы соответствовать строке во втором файле.
- d: строка в первом файле должна быть удалена, чтобы соответствовать второму файлу.
- a: Дополнительный контент должен быть добавлен в первый файл, чтобы он соответствовал второму файлу.
4c4 в нашем примере говорит нам, что четвертая строка alpha1 должна быть изменена, чтобы соответствовать четвертой строке alpha2. Это первое различие между двумя найденными файлами.
Строки, начинающиеся с ссылаются на второй файл, alpha2. Строка Dave говорит нам, что слово Dave — это содержимое строки четыре в alpha2. Подводя итог, нам нужно заменить Delta на Dave в четвертой строке в alpha1, чтобы эта строка соответствовала обоим файлам.
Следующее изменение обозначено 12c12 . Применяя ту же логику, это говорит нам о том, что строка 12 в alpha1 содержит слово Lima, а строка 12 в alpha2 содержит слово Linux.
Третье изменение относится к строке, которая была удалена из alpha2. Метка 21d20 расшифровывается как «строка 21 должна быть удалена из первого файла, чтобы синхронизировать оба файла со строки 20 и далее». Строка -s (сообщать об идентичных файлах).

Вы можете использовать опцию -q (краткая), чтобы получить одинаково лаконичное утверждение о двух разных файлах.

Следует обратить внимание на то, что с двумя одинаковыми файлами опция -q (краткая) полностью закрывается и ничего не сообщает.
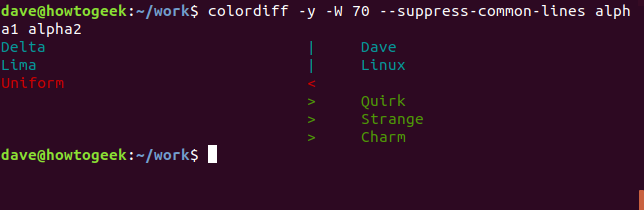
Альтернативный взгляд
Опция -y (рядом) использует другую компоновку для описания различий в файлах. Часто удобно использовать параметр -W (ширина) с видом рядом, чтобы ограничить количество отображаемых столбцов. Это позволяет избежать появления уродливых строк, которые затрудняют чтение. Здесь мы указали diff производить параллельное отображение и ограничивать вывод до 70 столбцов.
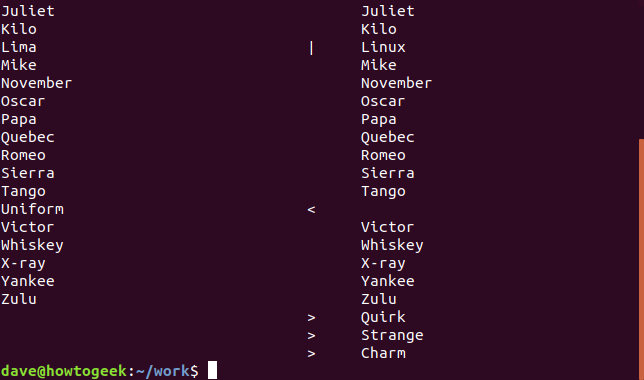
Первый файл в командной строке, alpha1, показан слева, а вторая строка в командной строке, alpha2, показана справа. Строки из каждого файла отображаются рядом. Рядом с этими строками в alpha2 есть символы индикатора, которые были изменены, удалены или добавлены.
- |: Строка, которая была изменена во втором файле.
- : Строка, добавленная ко второму файлу, которого нет в первом файле.
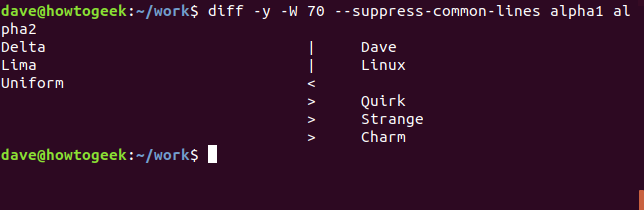
Если вы предпочитаете более компактную сводную информацию о различиях в файлах, используйте параметр —suppress-common-lines . Это заставляет diff перечислять только измененные, добавленные или удаленные строки.
Добавьте цветовую подсветку
Другая утилита под названием colordiff добавляет цветовую подсветку к выводу diff. Это позволяет намного легче увидеть, какие линии имеют различия.
Используйте apt-get для установки этого пакета в вашу систему, если вы используете Ubuntu или другой дистрибутив на основе Debian. В других дистрибутивах Linux используйте инструмент управления пакетами вашего дистрибутива Linux.
Используйте colordiff же, как вы используете diff .
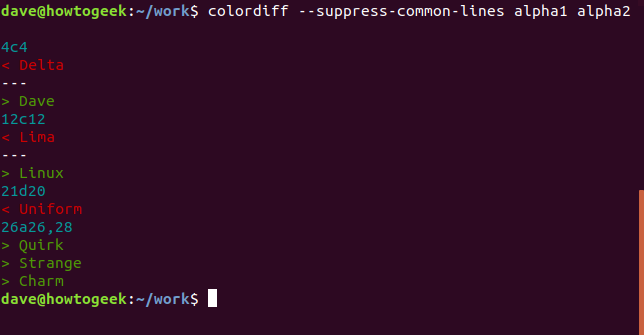
На самом деле, colordiff — это оболочка для diff, и diff делает всю работу за кулисами. Из-за этого все опции diff будут работать с colordiff.
Предоставление определённого контекста
Чтобы найти некоторую золотую середину между наличием всех строк в файлах, отображаемых на экране, и наличием в списке только измененных строк, мы можем попросить diff предоставить некоторый контекст. Есть два способа сделать это. Оба способа достигают одной и той же цели — показывать несколько строк до и после каждой измененной строки. Вы сможете увидеть, что происходит в файле в том месте, где была обнаружена разница.
Первый метод использует опцию -c (скопированный контекст).
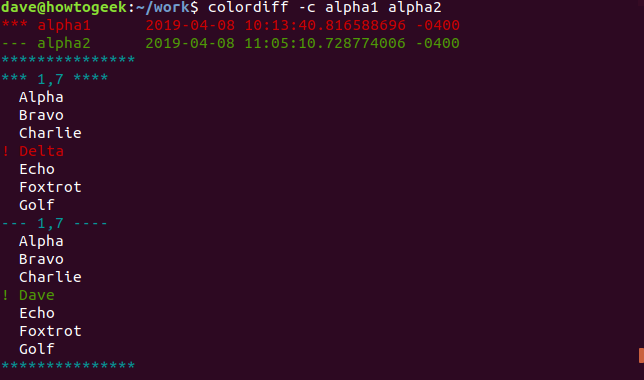
Вывод diff имеет заголовок. В заголовке перечислены два имени файла и время их изменения. Звездочки (*) перед именем первого файла и тире (-) перед именем второго файла. Звездочки и тире будут использоваться, чтобы указать, какому файлу принадлежат строки в выходных данных.
Линия звездочек с 1,7 в середине указывает на то, что мы смотрим на линии от alpha1. Чтобы быть точным, мы смотрим на строки с первой по седьмую. Слово Delta помечается как измененное. Он имеет восклицательный знак (!) Рядом с ним, и он красный. Есть три строки не измененного текста, отображаемые до и после этой строки, поэтому мы можем видеть контекст этой строки в файле.
Линия штрихов с 1,7 в середине говорит о том, что мы сейчас смотрим на линии из alpha2. Опять же, мы смотрим на строки с первой по седьмую, причем слово Dave на четвертой строке помечено как отличающееся.
Три строки контекста выше и ниже каждого изменения — это значение по умолчанию. Вы можете указать, сколько строк контекста вы хотите предоставить diff . Для этого используйте опцию -C (скопированный контекст) с заглавной буквой «C» и укажите количество строк, которое вам нужно:
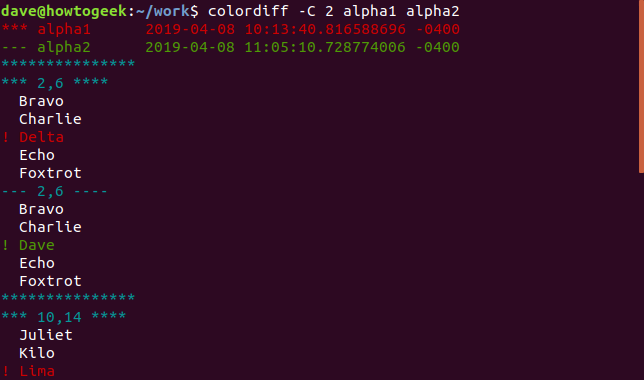
Вторая опция diff которая предлагает контекст, это опция -u (унифицированный контекст).
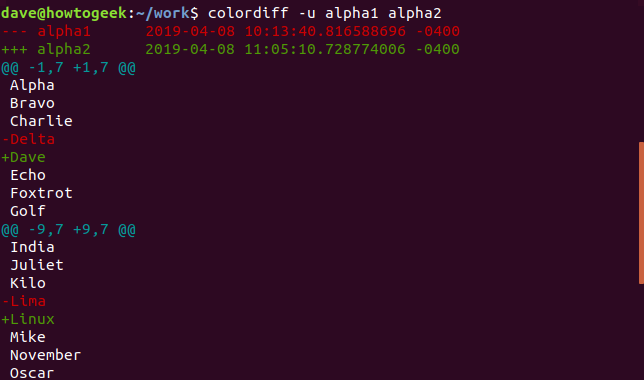
Как и раньше, у нас есть заголовок на выходе. Эти два файла названы, и показано время их изменения. Есть тире (-) перед названием альфа1 и знаки плюс (+) перед названием альфа2. Это говорит нам о том, что тире будут использоваться для обозначения альфа1, а знаки плюс будут использоваться для обозначения альфа2. По всему списку разбросаны строки, начинающиеся со знаков (@). Эти строки отмечают начало каждого различия. Они также говорят нам, какие строки показываются из каждого файла.
Нам показывают три строки до и после строки, помеченной как отличающиеся, чтобы мы могли видеть контекст измененной строки. В едином представлении линии с разницей показаны одна над другой. Перед строкой из alpha1 стоит тире, а перед строкой из alpha2 стоит знак плюс. Это отображение достигает в восьми строках того, что для скопированного контекстного дисплея выше потребовалось пятнадцать.
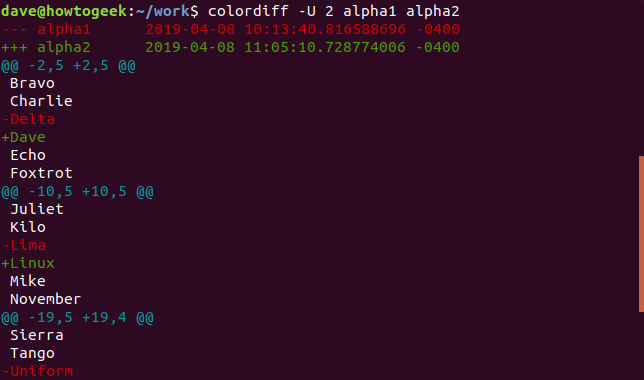
Как и следовало ожидать, мы можем попросить diff точное количество строк унифицированного контекста, которые мы хотели бы видеть. Для этого используйте опцию -U (унифицированный контекст) с заглавной буквой «U» и укажите желаемое количество строк:
Игнорирование пустого пространства
Давайте проанализируем еще два файла, test4 и test5. В них есть имена шести супергероев.
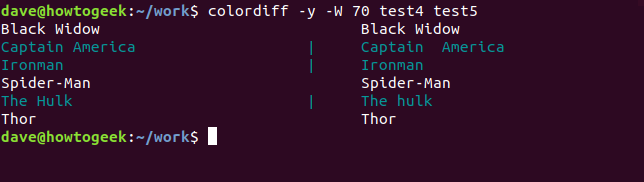
Результаты показывают, что diff находит ничего особенного с линиями Black Widow, Spider-Man и Thor. Он отмечает изменения с линиями Капитан Америка, Железный человек и Халк.
Так что же отличается? Что ж, в тесте 5 Халк пишется строчной буквой «h», а у «Капитана Америка» есть дополнительный пробел между «Капитаном» и «Америкой». Хорошо, это ясно, но что не так с линией Ironman? Там нет видимых различий. Вот хорошее эмпирическое правило. Если вы не видите этого, ответ — пробел. В конце этой строки почти наверняка есть пробел или два, или символ табуляции.
Если они не имеют значения для вас, вы можете diff игнорировать определенные типы различий строк, в том числе:
- -i: игнорировать различия в случае.
- -Z: игнорировать конечные пробелы.
- -b: игнорировать изменения количества пустого пространства.
- -w: игнорировать все изменения пробелов.
Давайте попросим diff снова проверить эти два файла, но на этот раз, чтобы игнорировать любые различия в случае.
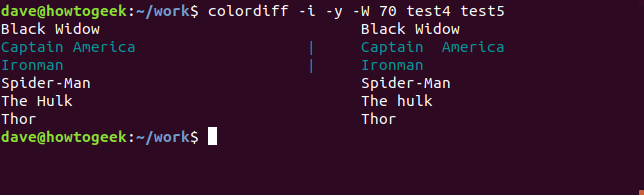
Строки с «The Hulk» и «The Hulk» теперь считаются совпадением, и для строчной буквы «h» не отмечается никакой разницы. Давайте попросим diff также игнорировать конечный пробел.
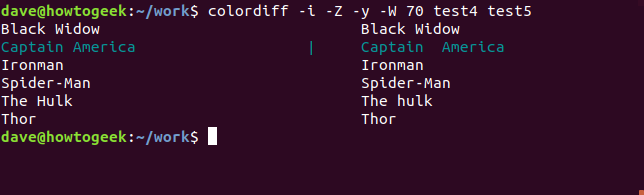
Как и предполагалось, конечный пробел должен был быть различием на линии Ironman, потому что diff больше не помечает разницу для этой линии. Это оставляет Капитана Америку. Давайте попросим diff игнорировать регистр и игнорировать все проблемы с пробелами.
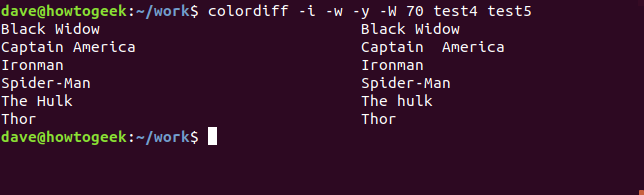
Указав diff игнорировать различия, которые нас не интересуют, diff сообщает нам, что для наших целей файлы совпадают.
Команда diff имеет много других опций, но большинство из них относится к созданию машиночитаемого вывода. Их можно просмотреть на странице руководства Linux. Параметры, которые мы использовали в приведенных выше примерах, позволят вам отследить все различия между версиями ваших текстовых файлов, используя командную строку и человеческие глаза.
Источник



