- Как удалить большое количество файлов в Linux
- Как быстро удалить Очень Много файлов?
- Re: Как быстро удалить Очень Много файлов?
- Каждую неделю вопрос на ЛОРе.
- Use ionice, Luke!
- Re: Как быстро удалить Очень Много файлов?
- Удалить миллионы файлов в linux
- Так как же удалить миллионы файлов из одной папки?
- Подготовка
- Тесты
- Удаление через rm -r
- Удаление через rm ./*
- Удаление через find -exec
- Удаление через find -delete
- Удаление через ls -f и xargs
- Удаление через perl readdir
- Удаление через программу на C readdir + unlink
- Как удалить сразу несколько файлов в Bash на Linux?
- 7 ответов
Как удалить большое количество файлов в Linux
Удалять файлы можно используя утилиту find, в отличие от ls или rm с указанием маски она не формирует изначально список содержимого каталога, а перебирает файлы по одному.
Посчитать количество файлов можно так
find /home/web/example.com/www/opt/cache/ -type f ¦ wc -l
С -exec rm -f можно запустить процесс удаления файлов (он может занять длительное время)
find /home/web/example.com/www/opt/cache/ -type f -exec rm -f <> \;
Можно попробовать find с опцией delete
find /home/web/example.com/www/opt/cache/ -type f -delete
Скорее всего не даст никакого результата rm с указанием файлов по маске — система при этом до того как начать удаление попытается сформировать полный список файлов, что сделать не получится
Также существует вариант с ls -f, вывод которого перенаправляется в xargs по 100 файлов, затем удаляемых при помощи rm. Может успешно отрабатывать, однако если файлов слишком много вывести список не получится и с ls -f
cd /home/web/example.com/www/opt/cache/ ; ls -f . | xargs -n 100 rm
Самой эффективной командой обычно оказывается find с -exec rm -f, однако все зависит от количества файлов и использовать стоит все представленные варианты (приоритет процессов при удалении имеет смысл максимально понижать используя nice и ionice — алиасы для find или других команд можно добавить в .bashrc пользователя, от имени которого производится удаление).
Источник
Как быстро удалить Очень Много файлов?
Есть раздел под XFS. В нём директория. Выглядит так:
# ls -ldh .
drwxrwxrwx 2 user user 330M Aug 4 01:04
Т.е. только мета-инфа весит 330 Мб (верхняя планка, значит, 1,3-1,4 млн. файлов). Списка имён файлов нет.
Вопрос: как их быстро удалить, с минимальной утилизацией винтов (продакшн-сервер) и без потери остальных данных на этом разделе?

Re: Как быстро удалить Очень Много файлов?
rm -dfr /var/www или че там у тебя
Каждую неделю вопрос на ЛОРе.
Этого вопроса ещё нет в FAQ? (Мне лень смотреть)
find . -maxdepth 1 -type f | xargs -0 ls

Use ionice, Luke!
> Т.е. только мета-инфа весит 330 Мб
Неверно, но к делу отношения не имеет.
> Вопрос: как их быстро удалить,
rm -rf /path/to/dir
> с минимальной утилизацией винтов (продакшн-сервер)
echo cfq > /sys/block/[диск, где находится ФС]/queue/scheduler
ionice -c3 rm -rf /path/to/dir
P.S. Непонятно, чем они так помешали, что понадобилось их так срочно удалять.
Re: Как быстро удалить Очень Много файлов?
Спасибо. С -d всё хорошо.
До этого пробовал:
#find ./ -maxdepth 1 -type f -mtime +7 -exec rm -f <> \;
(не хотелось удалять всё), выглядело так:
——————
#strace -s 360 -p 25670
Process 25670 attached — interrupt to quit
getdents64(4, /* 73 entries */, 4096) = 4088
getdents64(4, /* 73 entries */, 4096) = 4088
getdents64(4, /* 73 entries */, 4096) = 4088
getdents64(4, /* 73 entries */, 4096) = 4088
getdents64(4, /* 73 entries */, 4096) = 4088
etdents64(4,
Process 25670 detached
——————
, т.е. видимо строило файл-лист и делало это больше недели, с обычным rm было так же (надо было кстати использование памяти замерить).
А с ionice -c3 rm -dfr dir так:
# strace -s 360 -p 933
——————
Process 933 attached — interrupt to quit
unlink(«4e2a0e62921574187660e5ea2155af7e») = 0
unlink(«6094ad144713c973537c162b9e52b5d5») = 0
unlink(«86287687383af5b9c880cd6d4dbaca1c») = 0
unlink(«a8c6a06559e542e396c01a28d6110bbc») = 0
unlink(«ce40f028183e656e1fb5039b8a06dc92») = 0
unlink(«6c66c8ac651afbcd9c3b6dd45a79d506») = 0
unlink(«0753b1f1fcadc9262f0705c897350846») = 0
unlink(«a76ec71296a85087c5e76c413c92e23b») = 0
unlink(«66d65eba60a15d3e44b4058c763dbe74») = 0
— SIGINT (Interrupt) @ 0 (0) —
Process 933 detached
——————
Источник
Удалить миллионы файлов в linux
Как удалить миллионы файлов в linux? Проблемам достаточно известная и, самое главное, не так проста как кажется. Симптомы:
- Невозможно сделать ls в папке, зависает терминал
- Невозможно удалить так же в MC по той же причине невозможно зайти в папку.
- Консольные утилиты отказываются удалять файлы поскольку Argument list too long
- find ls так же выдают Как удалить миллионы файлов в linux Argument list too long
При наличии в одном каталоге нужных нам файлов и ненужных, мы вынуждены удалять файлы по маске, и тут кроется основная проблема большинство консольных утилит не в состояние выдать вам столь весомый список, а следствие этого и работать с ним. Первым отваливается rm который вам заявляет что слишком большой массив данных.
При определенном условие все еще отрабатывает такой хитрый вариант как
Оптимизировав его мы можем добавить еще пару сотен тысяч файлов и опять же у нас появится та же проблема, слишком большой массив данных.
Основная проблема в том, что мне нужно удалить именно данный файл, а не всю папку или все файлы находящиеся в ней. В результате для удаления 14 000 000 файлов мне потребовалось сделать ход конем в первую очередь отказаться от регулярок, поскольку они требуют построения всего дерева. И отказаться от любых утилит, составляющих весь список в пользу построчного построения. Используем тот же find
Далее, после получения файла, в моем случае он было около 200 мегабайт, подставляем ко всем
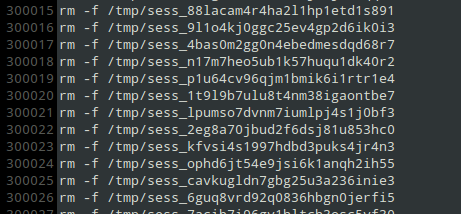
Естественно, вариант смотрится достаточно страшно, и не оптимально. Но он помог мне решить задачу которая не поддалась никаким другим вариантам.
Самое главное в find не должно быть никаких регулярок! В противном случае он так же откажется работать, все что нам потребуется отсортируем уже в файле. Ну и напоследок не доводите до такого, в моем случае не удалялись сессии. Естественно, после формирования файла с командами нам потребуется их исполнить
Источник
Так как же удалить миллионы файлов из одной папки?

Феерическая расстановка точек над i в вопросе удаления файлов из переполненной директории.
Прочитал статью Необычное переполнение жесткого диска или как удалить миллионы файлов из одной папки и очень удивился. Неужели в стандартном инструментарии Linux нет простых средств для работы с переполненными директориями и необходимо прибегать к столь низкоуровневым способам, как вызов getdents() напрямую.
Для тех, кто не в курсе проблемы, краткое описание: если вы случайно создали в одной директории огромное количество файлов без иерархии — т.е. от 5 млн файлов, лежащих в одной единственной плоской директории, то быстро удалить их не получится. Кроме того, не все утилиты в linux могут это сделать в принципе — либо будут сильно нагружать процессор/HDD, либо займут очень много памяти.
Так что я выделил время, организовал тестовый полигон и попробовал различные средства, как предложенные в комментариях, так и найденные в различных статьях и свои собственные.
Подготовка
Так как создавать переполненную директорию на своём HDD рабочего компьютера, потом мучиться с её удалением ну никак не хочется, создадим виртуальную ФС в отдельном файле и примонтируем её через loop-устройство. К счастью, в Linux с этим всё просто.
Создаём пустой файл размером 200Гб
Многие советуют использовать для этого утилиту dd, например dd if=/dev/zero of=disk-image bs=1M count=1M , но это работает несравнимо медленнее, а результат, как я понимаю, одинаковый.
Форматируем файл в ext4 и монтируем его как файловую систему
К сожалению, я узнал об опции -N команды mkfs.ext4 уже после экспериментов. Она позволяет увеличить лимит на количество inode на FS, не увеличивая размер файла образа. Но, с другой стороны, стандартные настройки — ближе к реальным условиям.
Создаем множество пустых файлов (будет работать несколько часов)
Кстати, если в начале файлы создавались достаточно быстро, то последующие добавлялись всё медленнее и медленнее, появлялись рандомные паузы, росло использование памяти ядром. Так что хранение большого числа файлов в плоской директории само по себе плохая идея.
Проверяем, что все айноды на ФС исчерпаны.
Размер файла директории
Теперь попробуем удалить эту директорию со всем её содержимым различными способами.
Тесты
После каждого теста сбрасываем кеш файловой системы
sudo sh -c ‘sync && echo 1 > /proc/sys/vm/drop_caches’
для того чтобы не занять быстро всю память и сравнивать скорость удаления в одинаковых условиях.
Удаление через rm -r
$ rm -r /mnt/test_dir/
Под strace несколько раз подряд (. ) вызывает getdents() , затем очень много вызывает unlinkat() и так в цикле. Занял 30Мб RAM, не растет.
Удаляет содержимое успешно.
Т.е. удалять переполненные директории с помощью rm -r /путь/до/директории вполне нормально.
Удаление через rm ./*
$ rm /mnt/test_dir/*
Запускает дочерний процесс шелла, который дорос до 600Мб, прибил по ^C . Ничего не удалил.
Очевидно, что glob по звёздочке обрабатывается самим шеллом, накапливается в памяти и передается команде rm после того как считается директория целиком.
Удаление через find -exec
$ find /mnt/test_dir/ -type f -exec rm -v <> \;
Под strace вызывает только getdents() . процесс find вырос до 600Мб, прибил по ^C . Ничего не удалил.
find действует так же, как и * в шелле — сперва строит полный список в памяти.
Удаление через find -delete
$ find /mnt/test_dir/ -type f -delete
Вырос до 600Мб, прибил по ^C . Ничего не удалил.
Аналогично предыдущей команде. И это крайне удивительно! На эту команду я возлагал надежду изначально.
Удаление через ls -f и xargs
$ cd /mnt/test_dir/ ; ls -f . | xargs -n 100 rm
параметр -f говорит, что не нужно сортировать список файлов.
Создает такую иерархию процессов:
ls -f в данной ситуации ведет себя адекватнее, чем find и не накапливает список файлов в памяти без необходимости. ls без параметров (как и find ) — считывает список файлов в память целиком. Очевидно, для сортировки. Но этот способ плох тем, что постоянно вызывает rm , чем создается дополнительный оверхед.
Из этого вытекает ещё один способ — можно вывод ls -f перенаправить в файл и затем удалить содержимое директории по этому списку.
Удаление через perl readdir
$ perl -e ‘chdir «/mnt/test_dir/» or die; opendir D, «.»; while ($n = readdir D) < unlink $n >‘ (взял здесь)
Под strace один раз вызывает getdents() , потом много раз unlink() и так в цикле. Занял 380Кб памяти, не растет.
Удаляет успешно.
Получается, что использование readdir вполне возможно?
Удаление через программу на C readdir + unlink
$ gcc -o cleandir cleandir.c
$ ./cleandir
Под strace один раз вызывает getdents() , потом много раз unlink() и так в цикле. Занял 128Кб памяти, не растет.
Удаляет успешно.
Опять — же, убеждаемся, что использовать readdir — вполне нормально, если не накапливать результаты в памяти, а удалять файлы сразу.
Источник
Как удалить сразу несколько файлов в Bash на Linux?
у меня есть этот список файлов внутри Linux server:
Я удаляю выбранные файлы журнала один за другим, используя команду rm -rf см. ниже:
есть ли другой способ, чтобы я мог удалить выбранные файлы сразу??
7 ответов
Bash поддерживает все виды подстановочных знаков и расширений.
ваше точное дело будет обрабатываться фигурные скобки, например:
больше расширить до одна команда со всеми тремя аргументами и эквивалентна набору:
важно отметить, что это расширение выполняется оболочкой, прежде чем rm еще загружен.
использовать подстановочный знак ( * ) для выбора нескольких файлов.
например, следующая команда удаляет все файлы с именами, начинающимися с abc.log.2012-03- .
Я бы рекомендовал под управлением ls abc.log.2012-03-* чтобы перечислить файлы, чтобы вы могли видеть, что вы собираетесь удалить перед запуском .
для получения более подробной информации см. страницу bash man на расширение имени файла.
если вы хотите удалить все файлы, имена которых соответствуют определенной форме, по шаблону (шаблон Глоб) является наиболее простым решением. Некоторые примеры:
регулярные выражения более мощные, чем подстановочные знаки; вы можете кормить вывод grep to rm -f . Например, если некоторые имена файлов начинаются с «abc.log» и с «ABC.log» , grep можно сделать без учета регистра:
когда я это делаю, я запускаю сначала проверьте, что он выдает результат, который я хочу — особенно если я использую rm -f :
здесь !! расширяется до предыдущей команды. Или я могу ввести стрелку вверх или Ctrl-P и отредактировать предыдущую строку, чтобы добавить .
это предполагает, что вы используете оболочку Bash. Некоторые другие оболочки, особенно csh и tcsh и некоторые более старые оболочки SH, могут не поддерживать $(. ) синтаксис. Вы можете использовать эквивалентный backtick синтаксис:
на $(. ) синтаксис легче читать, и если вы действительно амбициозны, он может быть вложен.
наконец, если подмножество файлов, которые вы хотите удалить, не может быть легко выражено регулярным выражением, трюк, который я часто использую, — это список файлов во временный текстовый файл, а затем отредактируйте его:
затем я могу отредактировать list файл вручную, оставляя только файлы, которые я хочу удалить, и затем:
(предполагается, что ни одно из имен файлов не содержит забавных символов, особенно пробелов.)
или, при редактировании list файл, я могу добавить rm -f в начале каждой строки, а затем:
дикая карта будет хорошо работать для этого, хотя для безопасности было бы лучше использовать дикую карту как можно меньше, поэтому что-то вроде этого:
хотя, судя по всему, это только отдельные файлы? Рекурсивный параметр не должен быть необходим, если ни один из этих элементов не является каталогами, поэтому лучше не использовать его, просто для безопасности.
просто используйте многострочный выбор в sublime, чтобы объединить все файлы в одну строку и добавить пробел между каждым именем файла, а затем добавить rm в начале списка. Это в основном полезно, когда в именах файлов, которые вы хотите удалить, нет шаблона.
Я не гуру linux, но я считаю, что вы хотите передать свой список выходных файлов в xargs rm -rf . Я использовал нечто подобное в прошлом с хорошими результатами. Сначала проверьте пример каталога!
EDIT — возможно, я неправильно понял, основываясь на других ответах, которые появляются. Если вы можете использовать подстановочные знаки, отлично. Я предположил, что ваш исходный список, который вы отобразили, был сгенерирован программой, чтобы дать вам ваш «выбор», поэтому я подумал, что xargs был бы путь к идти.
Если вы хотите удалить все файлы, которые относятся к каталог сразу. Например; имя каталога yor — «log», а каталог» log » включает abc.бревно.2012-03-14, abc.бревно.2012-03-15. файлы ect. Вы должны быть над каталогом журнала и
Источник



