- Linux кодировка windows 1251
- [РЕШЕНО] Кодировка win1251
- Можно ли в Линуксе установить кодировку win1251
- Re: Можно ли в Линуксе установить кодировку win1251
- Re: Можно ли в Линуксе установить кодировку win1251
- Re: Можно ли в Линуксе установить кодировку win1251
- Re: Можно ли в Линуксе установить кодировку win1251
- Re: Можно ли в Линуксе установить кодировку win1251
- Кодировка в Gedit
- Содержание
- Описание проблемы
- Настройка Gedit на автоопределение кодировки
- Смена кодировки открытого файла
- Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
- Программы для определения кодировки в Linux
- Команда file -i показывает неверную кодировку
- Программа enca для определения кодировки файла
- Как определить кодировку строки
- Изменение кодировки в Linux
- Использование команды iconv
- Конвертирование файлов из windows-1251 в UTF-8 кодировку
- Изменение кодировки программой enca
- Конвертация строки в правильную кодировку
Linux кодировка windows 1251
Все что нужно сделать — это скачать найденую в сети CP1251-locale для FreeBSD и установить в систему:
Примечание: Забудьте про указанную выше локаль CP1251 и берите родную от FreeBSD, появилась RELENG_4 и в Current, ну или готовую из RELENG_4. Замечание: Верхние строчки не актуальны с появлением CP1251 во FreeBSD:
Использование locale CP1251 на консоли и виртуальных терминалах, вместо KOI8-R
Для проверки локализации в html/php, смотри пункт Проверка локализации
Установка CP1251 locale в Linux:
Чтобы понять что, как и где создает утилита localedef, обязательно прочитайте man localedef, потому что в разных linux’ах locale распологается либо в /usr/share/locale/, либо /usr/lib/locale/. Вся локаль, включая 1251 уже содержится в i18n, необходимо лишь сгенерить из нее LC которая ляжет в /usr/share/locale/ru_RU.CP1251 или в /usr/lib/locale/ru_RU.CP1251 (зависит от типа Linux), достаточно выполнить команду:
Для проверки локализации в html/php, смотри пункт Проверка локализации
Можете воспользоваться моими заготовками для проверки html и php:
- .htacces                     Скачать wget’ом, затем cp htaccess .htaccess
- winlavr.php3                   Скачать wget’ом, затем cp winlavr.cp1251 winlavr.php3
- текст в cp1251 для winlavr.php3 Скачать wget’ом.
- winlavr.php3 — проверка преобразования/Windows-1251 кодировки — верхний/нижний регистр и стремные буквы
необходимо скачать указанные выше файлы .htaccess и winlavr.php3, разместить на WWW или в домашней странице и посмотреть результат.
Есть много разных CP1251 фонтов для X11, я таскаю за собой следующие:
Разворачиваете нужные или подходящие вам в /usr/X11R6/lib/X11/fonts, добавляете их в XF86Config, например: Рестартуете X11 или прямо в сеансе добавляете их в FontPath: теперь смело можно смотреть файлы в Windows-CP1251 кодировке, запуская, например xterm с понравившимся фонтом: где win9x15 есть alias фонта: -micex-fixed-medium-r-normal—15-140-75-75-c-90-windows-1251
для переключения раскладок в X11 можно воспользоваться портами FreeBSD:
Примечание: необходимо помнить что некоторые коды ascii из CP1251 являются управляющими.
[РЕШЕНО] Кодировка win1251

| #1 — 2 июля 2016 в 17:34 |
Здравствуйте! В линукс минт 17 я решал проблему с кодировкой win1251 одним из двух способов, а именно: 1) sudo apt-get install gconf-editor
Выполните в терминале команду:
1) команда в терминале gconf-editor
2) проходим в /apps/gedit-2/preferences/encodings/
3) в ключ auto_detected добавляем WINDOWS-1251,
если её нет, то вписываем и двигаем CURRENT вверх.
2) gsettings set org.gnome.gedit.preferences.encodings auto-detected «[‘UTF-8’, ‘WINDOWS-1251’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]»
После того как установил Минт 18 Х64, не нахожу в папку encodings, ее просто нет и второй способ тоже не работает. Нашел временное решение — установил программу mouspad, которая при запуске текст.файла определяет, что кодировка не верна и предлагает выбрать ее самому из списка доступных. А как можно сделать так, что бы добавить кодировку WINDOWS-1251 как это получалось у меня в минт 17?
| #2 — 2 июля 2016 в 18:29 |
| sulako: |
| Кодировка WINDOWS-1251, UTF-8, ISO-8859-15, UTF-16 |
Leafpad



Открывает автоматом файл.txt c кодировкой WINDOWS-1251 без предложения выбора, в какой кодировке открыть как Mousepad.
Можно ли в Линуксе установить кодировку win1251
При написании сайта возникают проблемы с кодировками между виндовыми и линуксовыми машинами (один разработчик пишет на win1251, а другой — на KOI-8). Можно ли каким-либо образом установить в линуксе Win1251? Ведь в винде можно из многих прог просмотреть KOI-8 без перекодировки, есть какая-нибудь такая может прога под линух?
Re: Можно ли в Линуксе установить кодировку win1251
Да, можно — программа easy cirillic\\ делаешь ec koi8 — и ты в кои-8\\ ec cp1251, ec cp866 — виндовые кодировки взять можно на линуксовых сайтах\\(opennet.ru, etc)

Re: Можно ли в Линуксе установить кодировку win1251
Вот поставил себе Mandrake 8.0 — она при установке позволяет задать, какая кодировка будет для русского языка. Поставил Koi8-r — половина окошек, менюшек и прочего — русскими, половина — кракозябрами (причём не умляутами, а именно БНОПНЯ всякая и РЕЯР с ФЕУФ-ом). Переставил, указал Windows-1251 — половина кракозябрами, половина — русскими. Самое смешное, что часть надписей и в том, и в другом случае кракозябрами. Ситуация очень похожая и в KDE, и в Gnome. Игра с панелькой управления «KDE / Look-n-feel / Fonts» пока ни к чему умному не привела.
Однако, может, кто-нибудь мудрый и великодушный подскажет, в чём грабли?
Re: Можно ли в Линуксе установить кодировку win1251
Ага, вот почитал форум — нашёл тему «Консоль в Мандрайк 8.0»
Re: Консоль в Мандрайк 8.0 В КДЕ все решается еще проще : заходишь в редактор меню — там все в ажуре и никаких каракулей! Ничего не делая, жмеш иконку «сохранить», ждешь несколько секунд, выходишь — везде русские буквы !
Попробую так, что ли.
Re: Можно ли в Линуксе установить кодировку win1251
. И всё-таки, а при каком раскладе будет меньше геморроя — при Win1251 или при koi8-r?
Re: Можно ли в Линуксе установить кодировку win1251
ага, вообще в новостях всё написано про 8-ку:
Кодировка в Gedit
Содержание
Описание проблемы
Ubuntu по умолчанию использует кодировку текстовых файлов UTF-8, однако некоторые операционные системы используют другие кодировки (например, русская версия Microsoft Windows использует CP-1251). Из-за разницы в кодировках могут возникнуть проблемы при открытии текстовых файлов в редакторе Gedit — они будут нечитаемыми. Данная статья предлагает несколько простых способов решения этой проблемы.
Настройка Gedit на автоопределение кодировки
Gedit может автоматически определить нужную кодировку. Для этого его нужно немного настроить.
Есть 3 варианта:
Вариант 1.
Запускаем dconf-editor и переходим в
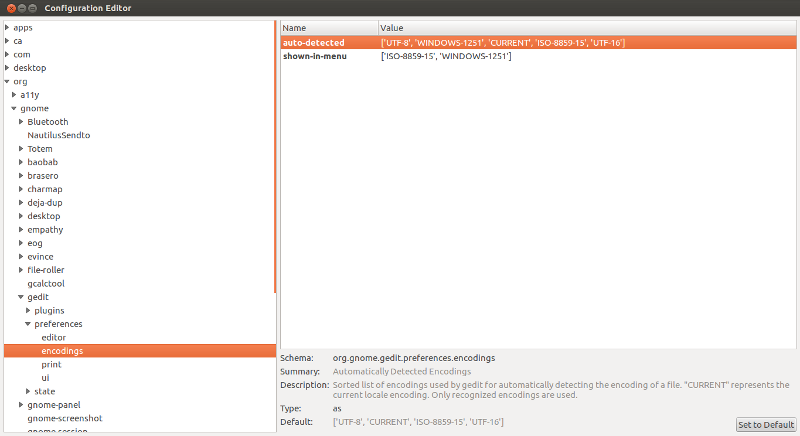
Редактируем ключ auto_detected 3) , вписывая нужную нам кодировку
Вариант 2.
Выполните в терминале команду:
Откроется Редактор Конфигурации GNOME. В нем откройте для редактирования ключ auto_detected 4) . 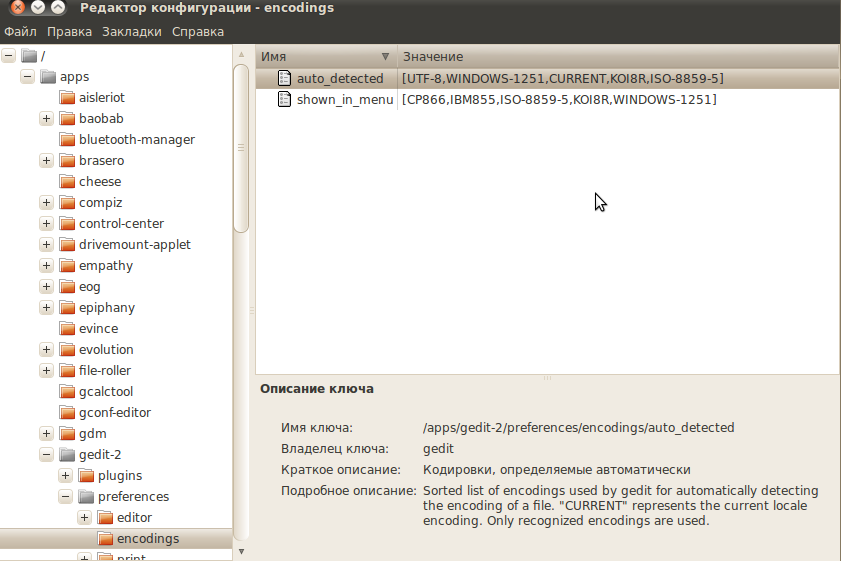 В появившемся окне редактирования переместите нужную вам кодировку вверх, так, чтобы она находилась сразу после UTF-8. Нажмите OK и закройте редактор.
В появившемся окне редактирования переместите нужную вам кодировку вверх, так, чтобы она находилась сразу после UTF-8. Нажмите OK и закройте редактор. 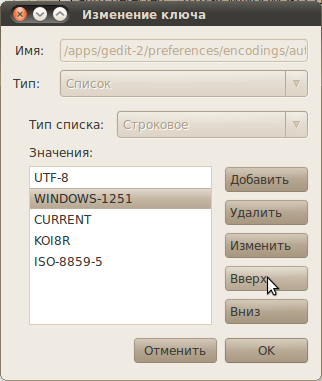
Вариант 3. Выполните в терминале команду:
Для Ubuntu 16.04:
Для Ubuntu Mate 16.04:
Данный способ является самым быстрым.
Теперь, если вы откроете файл с кодировкой WINDOWS-1251 — он будет правильно отображаться в Gedit.
Смена кодировки открытого файла
С помощью системы плагинов можно добавить возможность выбора кодировки уже открытого файла.
/.local/share/gedit/plugins (если такой папки нет, то её нужно создать)
После этого в главном меню Файл появляется пункт «Encoding», который позволяет менять кодировку в уже открытом документе.
Как определить кодировку файла или строки. Как конвертировать файлы в кодировку UTF-8 в Linux
В этой инструкции мы опишем что такое кодировка символов и рассмотрим несколько примеров конвертации файлов из одной кодировки в другую с использованием инструмента командной строки. Наконец, мы узнаем, как на Linux конвертировать несколько файлов из одного набора символов (charset) в UTF-8 кодировку.
Возможно, вы уже в курсе, что компьютер не понимает и не сохраняет буквы, числа или что-то ещё чем обычно оперируют люди. Компьютер работает с битами. Бит имеет только два возможных значения: 0 или 1, «истина» или «ложь», «да» или «нет». Все другие вещи, вроде букв, цифр, изображений должны быть представлены в битах, чтобы компьютер мог их обрабатывать.
Говоря простыми словами, кодировка символов – это способ информирования компьютера о том, как интерпретировать исходные нули и единицы в реальные символы, где символ представлен набором чисел. Когда мы печатаем текст в файле, слова и предложения, которые мы формируем, готовятся из разных символов, а символы упорядочиваются в кодировку.
Имеются различные схемы кодирования, среди них такие как ASCII, ANSI, Unicode. Ниже пример ASCII кодировки.
Программы для определения кодировки в Linux
Команда file -i показывает неверную кодировку
Чтобы узнать кодировку файла используется команда file с флагами -i или —mime, которые включают вывод строки с типом MIME. Пример:

Команда file показывает кодировки, но для одного из моих файлов она неверна. Рассмотрим ещё одну альтернативу.
Программа enca для определения кодировки файла
Утилита enca определяет кодировку текстовых файлов и, если нужно, конвертирует их.
Установим программу enca:
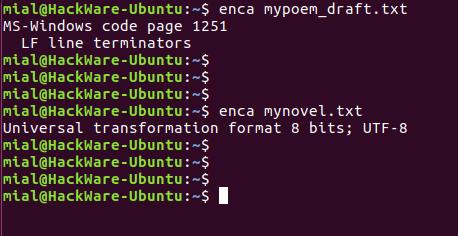
В этот раз для обоих файлов кодировка определена верно.
Запуск команды без опции выводит что-то вроде:
Это удобно для чтения людьми. Для использования вывода программы в скриптах есть опция -e, она выводит только универсальное имя, используемое в enca:
Если вам нужно имя, которое используется для названия кодировок в iconv, то для этого воспользуйтесь опцией -i:
Для вывода предпочитаемого MIME имени кодировки используется опция -m:
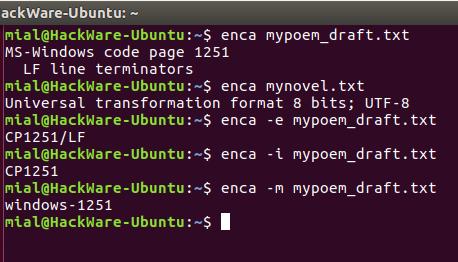
Для правильного определения кодировки программе enca нужно знать язык файла. Она получает эти данные от локали. Получается, если локаль вашей системы отличается от языка документа, то программа не сможет определить кодировку.
Язык документа можно явно указать опцией -L:
Чтобы узнать список доступных языков наберите:
Как определить кодировку строки
Для определения, в какой кодировке строка, используйте одну из следующих конструкций:
Вместо СТРОКА_ДЛЯ_ПРОВЕРКИ впишите строку, для которой нужно узнать кодировку. Если у вас строка не на русском языке, то откорректируйте значение опции -L.
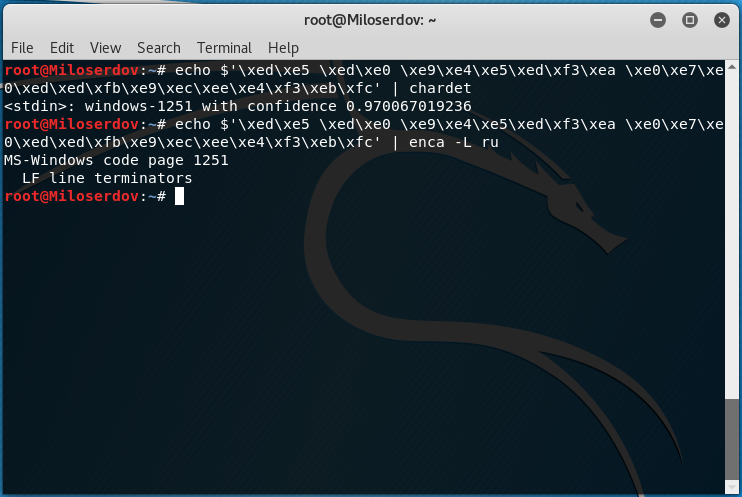
Если возникло сообщение об ошибке:
то попробуйте установить chardet из стандартных репозиториев.
Если chardet не найдена в репозиториях, то поищите программу uchardet, затем установите и используйте её.
Изменение кодировки в Linux
Использование команды iconv
В Linux для конвертации текста из одной кодировки в другую используется команда iconv.
Синтаксис использования iconv имеет следующий вид:
Где -f или —from-code означает кодировку исходного файла -t или —to-encoding указывают кодировку нового файла. Флаг -o является необязательным, если его нет, то содержимое документа в новой кодировке будет показано в стандартном выводе.
Чтобы вывести список всех кодировок, запустите команду:

Конвертирование файлов из windows-1251 в UTF-8 кодировку
Далее мы научимся, как конвертировать файлы из одной схемы кодирования (кодировки) в другую. В качестве примера наша команда будет конвертировать из windows-1251 (которая также называется CP1251) в UTF-8 кодировку.
Допустим, у нас есть файл mypoem_draft.txt его содержимое выводится как
Мы начнём с проверки кодировки символов в файле, просмотрим содержимое файла, выполним конвертирование и просмотрим содержимое файла ещё раз.
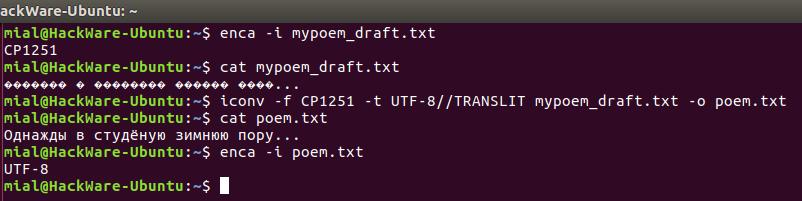
Примечание: если к кодировке, в который мы конвертируем файл добавить строку //IGNORE, то символы, которые невозможно конвертировать, будут отбрасываться и после конвертации показана ошибка.
Если к конечной кодировке добавляется строка //TRANSLIT, конвертируемые символы при необходимости и возможности будут транслитерированы. Это означает, когда символ не может быть представлен в целевом наборе символов, он может быть заменён одним или несколькими выглядящими похоже символами. Символы, которые вне целевого набора символов и не могут быть транслитерированы, в выводе заменяются знаком вопроса (?).
Изменение кодировки программой enca
Программа enca не только умеет определять кодировку, но и может конвертировать текстовые файлы в другую кодировку. Особенностью программы является то, что она не создаёт новый файл, а изменяет кодировку в исходном. Желаемую кодировку нужно указать после ключа -x:
Конвертация строки в правильную кодировку
Команда iconv может конвертировать строки в нужную кодировку. Для этого строка передаётся по стандартному вводу. Достаточно использовать только опцию -f для указания кодировки, в которую должна быть преобразована строка. Т.е. используется команда следующего вида:

Также для изменения кодировки применяются программы:
- piconv
- recode
- enconv (другое название enca)



