- COREUTILS. Команда uniq. Вывод уникального содержимого
- Использование команды uniq в Linux (10 примеров)
- Утилита uniq в Linux
- 1. Удаление повторяющихся строк из вывода
- 2. Вывод информации о количестве дубликатов каждой из строк
- 3. Вывод лишь повторяющихся строк
- 4. Пропуск начальных фрагментов строк
- 5. Вывод всех строк с разделением групп повторяющихся строк
- 6. Вывод лишь не повторяющихся строк
- 7. Пропуск заданного количества символов в начале строк
- 8. Указание количества символов для сравнения
- 9. Сравнение строк без учета регистра
- 10. Использование завершающего нулевого символа вместо символа перехода на новую строку
- Заключение
- Linux количество уникальных строк
- Использование
- Команда uniq без опций
- Параметры uniq
- Опция -c
- Опция -d
- Опция -D (расширение GNU)
- Опция -u
- Опция -f
- Опция -s
- Опция -w
- Команда uniq и символы кириллицы
- Резюме команды uniq
COREUTILS. Команда uniq. Вывод уникального содержимого
Общий синтаксис программы uniq в linux предельно простой:
unic [OPTIONS] [INPUT [OUTPUT]]
Тоесть, чтобы вывести уникальные строки, например в тестовом файле my_text_file, нужно команде uniq передать его имя в качестве аргумента
Нельзя, разумеется, забывать, что вы должны находится именно в той дирректории, где и лежит файл my_text_file. Иначе uniq необходимо передать полный путь до файла в linux:
Неуникальные строки можно посчитать. Для этого передайте quic в качестве опции ключ «-c».
unic -c /home/user/my_text_file
В выводе вы получите таблицу из 2-х колонок, в первой будет указано количество повторяющихся строк, во второй их значение.
В linux uniq также можно попросить печатать только те строки, которые имеют дубликаты, для этого нужно использовать ключ «-d»:
uniq -d /home/user/my_text_file
Опции можно комбинировать, и чтобы посчитать только строки которые имеют дубликаты, следует ввести такую команду:
uniq -d -с /home/user/my_text_file
В противовес ключу «-d» есть ключ «-u», заставляющий uniq выводить только строки, не имеющие дубликата:
uniq -u /home/user/my_text_file
Однако, как мы и освещали в вводой части, uniq работает только последовательно, следовательно строки, содержащиеся в файле, например:
не будут считаться уникальными. Чтобы разрешить эту проблему можно использовать в linux команду uniq совместно с командой sort, перенаправляя вывод одной команды на ввод другой:
sort -n my_text_file | uniq
или же просто использовать sort с ключом «-u»
sort -n -u my_text_file
Возможности и примеры использования утилиты sort мы уже освещали в статье COREUTILS. Команда sort. Сортировка вывода программ
Источник
Использование команды uniq в Linux (10 примеров)
Оригинал: Linux Uniq Command Tutorial for Beginners (10 examples)
Автор: Himanshu Arora
Дата публикации: 23 мая 2017 г.
Перевод: А.Панин
Дата перевода: 24 мая 2017 г.
Если вы являетесь пользователем интерфейса командной строки Linux и ваша работа связана с редактированием текстовых файлов, вы должны знать (если уже не знаете) о существовании огромного количества утилит с интерфейсом командной строки, которые могут помочь вам в различных ситуациях. Например, одной из таких утилит является утилита uniq , выводящая или удаляющая из вывода повторяющиеся строки, находящиеся в текстовом файле.
В данной статье мы будем обсуждать методику использования утилиты uniq на основе простых для понимания примеров. Но перед тем, как приступить к рассмотрению примеров стоит упомянуть о том, что все примеры и инструкции из данной статьи были протестированы в системе Ubuntu 16.04 LTS.
Утилита uniq в Linux
Как уже говорилось ранее, утилита uniq осуществляет вывод или удаление из вывода повторяющихся строк. А это синтаксис соответствующей команды:
А это описание функций утилиты с ее страницы руководства: «Утилита осуществляет фильтрацию идентичных строк из ВХОДНОГО ФАЙЛА (или из стандартного потока ввода) и выводит информацию в ВЫХОДНОЙ ФАЙЛ (или стандартный поток вывода). При вызове без параметров идентичные строки объединяются в рамках первых найденных экземпляров строк.»
Ниже приведен ряд примеров, которые помогут вам лучше понять принцип работы рассматриваемой утилиты.
1. Удаление повторяющихся строк из вывода
Предположим, что в нашем распоряжении имеется файл со следующими строками:
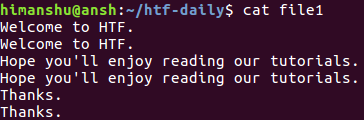
Несложно заметить, что каждая из строк повторяется. Теперь применим утилиту uniq по отношению к этому файлу и посмотрим, к чему это приведет.

Очевидно, что вывод не содержит дубликатов строк. Обратите внимание на то, что содержимое оригинального файла с именем file1 в нашем случае осталось неизменным. Вы можете перенаправить вывод утилиты в другой файл в том случае, если вам нужно сохранить вывод для дальнейшей обработки.
2. Вывод информации о количестве дубликатов каждой из строк
Если вам нужно, вы можете использовать утилиту uniq для вывода информации о количестве повторений каждой из строк файла. Это может быть сделано с помощью параметра командной строки -c . Например, команда
будет генерировать следующий вывод:

Несложно заметить, что перед каждой из строк выводится число, соответствующее количеству ее повторений.
3. Вывод лишь повторяющихся строк
Для того, чтобы утилита uniq выводила лишь повторяющиеся строки, следует использовать параметр -D командной строки. Например, предположим, что файл с именем файл file1 теперь содержит дополнительную строку в конце (обратите внимание на то, что эта строка не повторяется).
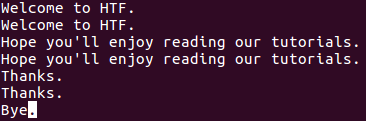
Теперь при исполнении команды
будет генерироваться следующий вывод:
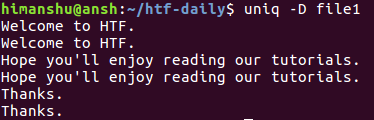
Как вы видите, параметр -D сообщает утилите uniq о необходимости вывода всех повторяющихся строк, включая их повторы. Для лучшей читаемости вы можете активировать режим вывода пустой строки после каждой из групп повторяющихся строк с помощью параметра —all-repeated .
Данный параметр требует от пользователя обязательного указания метода добавления разделителя. Строки могут добавляться к разделителю (то есть, пустой строке) с помощью метода prepend или разделяться с помощью него с помощью метода append . Например, в данном случае используется метод prepend .
![]()
Более того, если вам нужно, чтобы утилита выводила лишь по одному экземпляру каждой из повторяющихся строк, вы можете воспользоваться параметром -d . Это пример его использования:

Очевидно, что в выводе приводится лишь по одному экземпляру строки из каждой группы.
4. Пропуск начальных фрагментов строк
Иногда, в зависимости от ситуации, совпадение двух строк может быть установлено по совпадению определенных частей этих строк. Например, рассмотрим следующий файл:
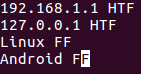
Теперь предположим, что строки должны считаться совпадающими или не совпадающими на основании совпадения или несовпадения их вторых полей (то есть HTF или FF) и вам нужно сделать так, чтобы утилита uniq использовала такой же критерий сравнения, чего несложно добиться с помощью параметра командной строки -f .
Параметр -f требует от вас обязательной передачи числа, которое соответствует количеству полей, которые нужно пропустить. Например, в нашем случае мы передаем в качестве значения параметр -f значение 1, так как мы хотим, чтобы утилита uniq пропустила лишь первое поле:

Из вывода очевидно, что утилита uniq посчитала первую и третью строку повторяющимися исключительно на основе их вторых полей.
5. Вывод всех строк с разделением групп повторяющихся строк
При необходимости вывода всех строк с разделением групп повторяющихся строк с помощью пустой строки вы можете использовать параметр —group . Как и в случае описанного выше параметра —all-repeated , параметр —groups требует от пользователя обязательного указания позиции пустой строки ( prepend , append или both ).
Это пример использования рассматриваемого параметра:
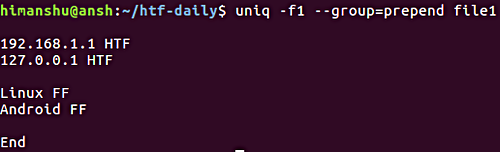
Обратите внимание на параметр -f , который обсуждался в предыдущем разделе.
6. Вывод лишь не повторяющихся строк
Вы уже наверняка поняли, что утилита uniq по умолчанию выводит лишь повторяющиеся строки. Но если вам нужно, вы можете сообщить ей о необходимости вывода лишь не повторяющихся или уникальных строк. Это делается с помощью параметра командной строки -u .
В нашем случае команда будет выглядеть следующим образом:
Это пример ее использования:

Обратите внимание на параметр -f , который обсуждался в разделе 4.
7. Пропуск заданного количества символов в начале строк
В одном из предыдущих разделов мы обсуждали методику пропуска полей строк при использовании утилиты uniq. Однако, при необходимости вы можете сообщить утилите о необходимости пропуска не начальных полей, а начальных символов строк. Для доступа к соответствующей функции может использоваться параметр командной строки -s .
Например, предположим, что наш файл содержит следующие строки:
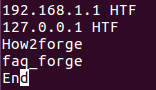
Теперь, если вы захотите, чтобы uniq пропустила первые 4 символа каждой строки перед их сравнением, вы сможете воспользоваться следующей командой:
А это приведенная выше команда в действии:
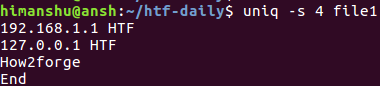
Несложно заметить, что четвертая строка (faq_forge) из оригинального файла была пропущена. Это объясняется тем, что после пропуска первых четырех символов третья и четвертая строки становятся идентичными для утилиты uniq и она выводит лишь первую из них.
8. Указание количества символов для сравнения
По аналогии с пропуском символов, вы можете сообщить утилите uniq о необходимости сравнения лишь заданного количества символов строк. Для этой цели вам придется использовать параметр командной строки -w .
Например, предположим, что файл содержит следующие строки:
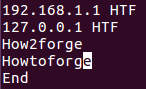
Теперь при необходимости ограничения диапазона символов строк для сравнения тремя первыми символами, может использоваться следующая команда:
Это приведенная выше команда в действии:
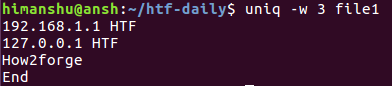
Так как первые три символа третьей и четвертой строк совпадают, эти строки считаются утилитой идентичными. По этой причине в выводе находится лишь третья строка.
9. Сравнение строк без учета регистра
По умолчанию утилита uniq осуществляет сравнение строк с учетом регистра символов. Однако, вы можете активировать режим сравнения строк без учета регистра символов с помощью параметра командной строки -i .
Например, предположим, что мы будем использовать файл с содержимым, аналогичным рассмотренному в предыдущем разделе, но теперь четвертая строка будет начинаться с символов H, O и W в верхнем регистре.
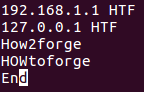
Теперь, если вы попытаетесь выполнить рассмотренную в предыдущем разделе команду, вы получите отличный вывод:
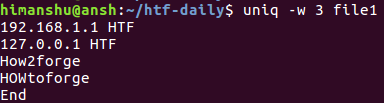
Это объясняется тем, что первые три символа третьей и четвертой строк отличны для утилиты uniq ввиду их регистра. В подобных ситуациях вы можете активировать режим сравнения строк без учета регистра с помощью параметра командной строки -i .
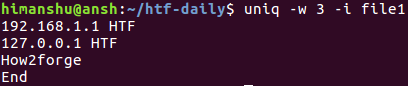
10. Использование завершающего нулевого символа вместо символа перехода на новую строку
По умолчанию утилита uniq генерирует вывод с завершающим символом перехода на новую строку. Однако, при необходимости вы можете активировать режим использования завершающего нулевого символа (полезный при вызове uniq из сценариев). Для этого следует использовать параметр командной строки -z :
Заключение
Мы рассмотрели практически все поддерживаемые утилитой uniq параметры командной строки, поэтому вам остается лишь самостоятельно испытать их в работе для того, чтобы лучше понять их принцип работы и функции. И как обычно, в случае каких-либо сомнений и вопросов следует обращаться к странице руководства утилиты .
Источник
Linux количество уникальных строк
uniq — утилита Unix, с помощью которой можно вывести или отфильтровать повторяющиеся строки в файле. Если входной файл задан как («-») или не задан вовсе, чтение производится из стандартного ввода. Если выходной файл не задан, запись производится в стандартный вывод. Вторая и последующие копии повторяющихся соседних строк не записываются. Повторяющиеся входные строки не распознаются, если они не следуют строго друг за другом, поэтому может потребоваться предварительная сортировка файлов.
Использование
Опции программы имеют следующие значения:
-u Выводить только те строки, которые не повторяются на входе.
-d Выводить только те строки, которые повторяются на входе.
-c Перед каждой строкой выводить число повторений этой строки на входе и один пробел.
-i Сравнивать строки без учёта регистра.
Игнорировать при сравнении первые число_символов символов каждой строки ввода. Если эта опция указана совместно с -f, то будут игнорироваться первые число_полей полей, а затем ещё число_символов символов. Символы также нумеруются начиная с единицы.
Игнорировать при сравнении первые число_полей полей каждой строки ввода. Полем является строка непробельных символов, отделённая от соседних полей пробельными символами. Поля нумеруются начиная с единицы.
Команда uniq без опций
Если в тексте следует подряд несколько одинаковых строк, то команда uniq уменьшит их количество до одной.
Расшифрую этот пример. Команду echo, при помощи опции -e можно заставить печатать не в строчку, как обычно, а в несколько строк. Для этого нужно в конце каждой будущей строки поставить знак новой строки \n, а чтобы «экранировать» обратный слэш (\), который сам по себе тоже является знаком, нужно этот обратный слэш удвоить: \\, и получится \\n. Например, напечатаем в две строки какой-нибудь стишок, например:
(Кто не знает, сообщу по секрету, что великий пролетарский писатель Максим Горький в слове пингвин ставил ударение на первом слоге — пИнгвин). Пробел между знаком новой строки и первым словом следующей строки не ставится, иначе получится «лесенка»:
как в стихах другого великого пролетарского поэта Маяковского:
Но довольно поэзии; вернемся к нашему числовому примеру:
Итак, в первой части этого программного канала команда echo -e, которая выводит на стандартный вывод столбик чисел. Вывод этот канализируется на ввод команды uniq, которая уменьшает количество одинаковых строк (1111) до одной.
Тут нужно уточнить очень интересную вещь: команда uniq сравнивает только рядом расположенные строчки, и если составить столбик цифр в другом порядке, скажем:
то никакого уменьшения числа повторов не произойдет. Становится понятным, что команда uniq любит уже отсортированные тексты, где все одинаковые строчки собраны вместе. Такой сортировкой славится команда sort, вот и добавим ее в наш программный канал:
Команда sort сортирует, команда uniq убирает повторы, кажется все прекрасно, если бы не одно «но» — у программы sort есть опция -u, которая справляется с этой задачей не хуже:
Получается, что команда uniq как бы и не нужна.
Не спешите с выводами, у команды uniq есть еще несколько опций, которых нет у команды sort.
Параметры uniq
Опция -c
Сообщит, сколько было одинаковых строк до их урезания:
Опция -d
Эта опция, наоборот, выведет лишь ту строку, которая повторялась в тексте:
Можно узнать и сколько раз эта строка повторялась:
Опция -D (расширение GNU)
Выведет все повторяющиеся строки, не уменьшая их числа:
На первый взгляд, это не слишком полезно, но в сочетании с некоторыми другими опциями вполне имеет смысл.
Опция -u
Выводит только уникальные строки:
Опция -f
Эта опция пропустит указанное ЧИСЛО «слов», прежде чем начать искать повторы. Тут следует пояснить, что «словом» команда uniq считает любую непрерывную последовательность символов, отделенную от других символов знаками пробела, либо табуляции (таковых знаков может быть один или больше).
В этом примере мы пропустили заведомо одинаковую фамилию, чтобы «отцедить» двойников Иванов. (Правда, безо всяких опций сработало бы не хуже, но в каких-то случаях, скорее всего, эта опция полезна).
Можно скомбинировать эту опцию с другими, слегка изменив синтаксис:
В таком виде она имеет определенный смысл.
Можно было задать эту опцию проще: uniq -1.
Опция -s
Эта опция пропустит необходимое ЧИСЛО символов, прежде начала поиска повторов.
Эту опцию можно комбинировать с другими, если записать без пробела между -s и ЧИСЛОМ:
Можно также ставить просто: uniq +3.
Опция -w
Позволяет сравнивать на уникальность указанное ЧИСЛО символов в каждой строке:
Работает эта опция и в сочетании с опциями пропуска слов или символов:
Опции —help и —version общеизвестны, останавливаться на них мы не будем.
Остается добавить, что команда uniq принимает в качестве аргументов не только файлы, которые проверяются на уникальность, но и файлы, куда результат проверки будет записан:
Команда uniq и символы кириллицы
Новые версии программы с русскими буквами работают адекватно (версия 5.97 с некоторыми опциями неадекватно обращалась с кириллицей; версия 6.4 никаких нареканий не вызывает).
Резюме команды uniq
Сырая и не самая необходимая команда (несмотря на маститых авторов: Richard Stallman и David MacKenzie). Следует обновить до новейшей версии, так как в версии 5.97 замечены ошибки. Для отбраковки одинаковых строк советую, вместо команды uniq, применять команду sort -u.
Источник



