- 16 команд мониторинга Linux-сервера, которые вам действительно нужно знать
- iostat
- meminfo и free
- mpstat
- netstat
- ps и pstree
- strace
- tcpdump
- uptime
- vmstat
- Wireshark
- 20 средств мониторинга системы Linux, о которых должен знать каждый системный администратор
- № 1: top – команда выдачи данных об активности процессов
- Наиболее часто используемые горячие клавиши
- № 2: vmstat – активность системы, информация о системе и аппаратных ресурсах
- № 3: w – определяем, кто зарегистрирован и что они делают
- № 4: uptime – сообщает, как долго работает система
- № 5: ps – список процессов
- Показать больше данных
- Показать потоки (LWP и NLWP)
- Показать потоки после процессов
- Выдать список всех процессов на сервере
- Выдать дерево процессов
- Выдать информацию о параметрах безопасности
- Показать каждый процесс для пользователя Vivek
- Настроить выдачу данных в формате, определенном пользователем
- Показывать ID процессов, запущенных под Lighttpd
- Показать имя для PID 55977
- Выдать 10 процессов, потребляющих наибольшее количество памяти
- Выдать 10 процессов, потребляющих наибольший ресурс процессора
- № 6: free – использование памяти
- № 7: : iostat – средняя загрузка процессора, активность дисков
- № 8: sar – сбор и выдача данных о системной активности
- № 9: mpstat – использование мультипроцессора
- № 10: pmap – использование процессами оперативной памяти
- № 11 и № 12: netstat и ss – сетевая статистика
- №13: iptraf – сетевая статистика в режиме реального времени
- №14: tcpdump – детальный анализ сетевого трафика
- № 15: strace – системные вызовы
- № 16: Директорий /Proc – различная статистика ядра
- № 17: Nagios – мониторинг сервера и сети
- № 18: Cacti – инструментальное веб приложение, используемое для мониторинга
- № 19: KDE System Guard – графический монитор, выдающий сведения о системе в режиме реального времени
- № 20: Gnome System Monitor – графическое средство выдачи информации о системе в режиме реального времени
- Бонус: Дополнительные инструментальные средства
- Комментарии
16 команд мониторинга Linux-сервера, которые вам действительно нужно знать
Хотите знать, что самом деле происходит на с вашим сервером? Тогда вы должны знать эти основные команды. Как только вы их освоите, вы станете администратором-экспертом в системах Linux.
В зависимости от дистрибутива Linux, вы можете с помощью программы с графическим интерфейсом получить больше информации, чем могут дать эти команды, запускаемые из командной оболочки. В SUSE Linux, например, есть отличное графическое инструментальное средство YaST , предназначенное для конфигурирования и управления системой; также в KDE есть отличное инструментальное средство KDE System Guard .
Однако, основное правило администратора Linux состоит в том, что вы должны работать с графическим интерфейсом на сервере только в случае, когда это вам абсолютно необходимо. Это обусловлено тем, что графические программы на Linux занимают системные ресурсы, которые было бы лучше использовать в другом месте. Поэтому хотя программа с графическим интерфейсом и может отлично подходить для базовой проверки состояния сервера, если вы хотите знать, что происходит на самом деле, отключите графический интерфейс и воспользуйтесь инструментальными средствами, работающими из командной строки Linux.
Это также означает, что вы должны запускать графический интерфейс на сервере только тогда, когда это действительно необходимо; не оставляйте его работать. Чтобы достичь оптимальной производительности, сервер Linux должен работать на уровне runlevel 3 , на котором, когда компьютер загружается, полностью поддерживается работа в сети и многопользовательский режим, но графический интерфейс не запускается. Если вам действительно нужно графический рабочий стол, вы всегда можете его открыть с помощью команды startx , выполненной из командной строки.
Если ваш сервер при загрузке запускается в графическом режиме, то вам это нужно изменить. Для этого откройте терминальное окно, с помощью команды su перейдите в режим пользователя root и с помощью вашего любимого текстового редактора откройте файл /etc/inittab .
Как только вы это сделаете, найдите строку initdefault и измените ее с id:5:initdefault: на id:3:initdefault:
Если файла inittab нет, то создайте его и добавьте строку id:3 . Сохраните файл и выйдите из редактора. В следующий раз при загрузке ваш сервер будет загружаться на уровне запуска 3. Если вы после этого изменения не захотите перезагружать сервер, вы также можете с помощью команды init 3 непосредственно задать уровень запуска вашего сервера.
Как только ваш сервер станет работать на уровне запуска init 3, вы для того, чтобы увидеть, что происходит внутри вашего сервера, можете начать пользоваться следующими программами командной оболочки.
iostat
Команда iostat подробно показывает, что к чему в вашей подсистеме хранения данных. Как правило, вы должны использовать команду iostat для того, чтобы следить, что ваша подсистема хранения работают в целом хорошо и прежде, чем ваши клиенты заметят, что сервер работает медленно, выявлять те места, из-за медленного ввода/вывода которых возникают проблемы. Поверьте мне, вам следует обнаруживать эти проблемы раньше, чем это сделают ваши пользователи!
meminfo и free
Команда meminfo предоставит вам подробный список того, что происходит в памяти. Как правило, доступ к данным meminfo можно получить с помощью другой программы, например, cat или grep . Так, например, с помощью команды
вы в любой момент будете знать все, что происходит в памяти вашего сервера.
Вы можете воспользоваться командой free для быстрого «фактографического» взгляда на память. Если кратко, то с помощью команды free вы получите обзор состояния памяти, а с помощью команды meminfo вы узнаете все подробности.
mpstat
Команда mpstat сообщает о действиях каждого из доступных процессоров в многопроцессорных серверах. В настоящее время почти во всех серверах используются многоядерные процессоры. Команда mpstat также сообщает об усредненной загрузке всех процессоров сервера. Это позволяет отображать общую статистику по процессорам во всей системе или для каждого процессора отдельно. Эти значения могут предупредить вас о возможных проблемах с приложением прежде, чем они станут раздражать пользователей.
netstat
Команда netstat , точно также, как и ps , является инструментальным средством Linux, которым администраторы пользуются каждый день. Она отображает большое количество информации о состоянии сети, например, об использовании сокетов, маршрутизации, интерфейсах, протоколах, показывает сетевую статистику и многое другое. Некоторые из наиболее часто используемых параметров:
-a — Показывает информацию о всех сокетах
-r — Показывает информацию, касающуюся маршрутизации
-i — Показывает статистику, касающуюся сетевых интерфейсов
-s — Показывает статистику, касающуюся сетевых протоколов
Команда nmon , сокращение от Nigel’s Monitor, является популярным инструментальным средством с открытым исходным кодом, которое предназначено для мониторинга производительности систем Linux. Команда nmon следит за информацией о производительности нескольких подсистем, таких как использование процессоров, использование памяти, выдает информацию о работе очередей, статистику дисковых операций ввода/вывода, статистику сетевых операций, активности системы подкачки и метрические характеристики процессов. Затем вы через «графический» интерфейс команды curses можете в режиме реального времени просматривать информацию, собираемую командой nmon.
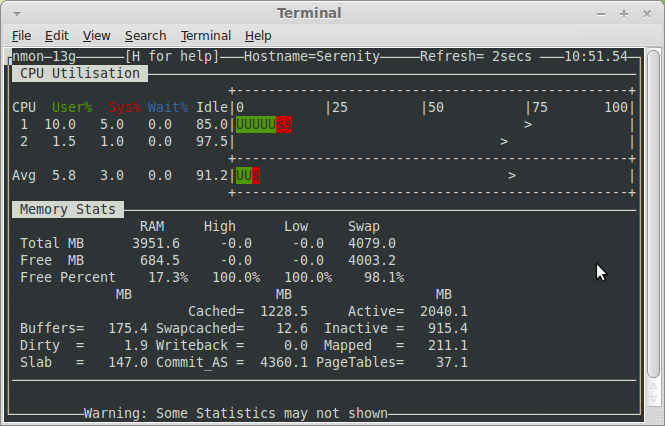
Чтобы команда nmon работала, вы должны ее запустить из командной строки. После этого вы можете с помощью нажатий на отдельные клавиши выбирать подсистемы, за работой которых вы хотите проследить. Например, чтобы получить статистику по процессору, памяти и дискам, наберите c , m и d . Вы также можете использовать команду nmon с флагом -f для того, чтобы сохранить статистику в файле CSV для последующего анализа.
Я считаю, что для повседневного мониторинга серверов команда nmon является одной из самых полезных программ в моем инструментальном наборе, предназначенном для систем Linux.
Команда pmap сообщает об объеме памяти, которые используются процессами на вашем сервере. Вы можете использовать этот инструмент для того, чтобы определить, для каких процессов на сервере выделяется память и как эти процессы ее используют.
ps и pstree
Команды ps и pstree являются двумя самыми лучшими командами администратора Linux. Они обе выдают список всех запущенных процессов. Команда ps показывает, сколько памяти и процессорного времени используют программы, работающие на сервере. Команда pstree выдает меньше информации, но указывает, какие процессы являются потомками других процессов. Имея эту информацию, вы можете обнаружить неуправляемые процессы и уничтожить их с помощью команды kill , предназначенной для «безусловного уничтожения» процессов в Linux.
Программа sar является инструментальным средством мониторинга, столь же универсальным как швейцарский армейский нож. Команда sar , на самом деле, состоит из трех программ: sar , которая отображает данные, и sa1 и sa2 , которые собирают и запоминают данные. После того, как программа sar установлена, она создает подробный отчет об использовании процессора, памяти подкачки, о статистике сетевого ввода/вывода и пересылке данных, создании процессов и работе устройств хранения данных. Основное отличие между sar и nmon в том, что первая команда лучше при долгосрочном мониторинге системы, в то время, как я считаю, nmon лучше для того, чтобы мгновенно получить информацию о состоянии моего сервера.
strace
Команду strace часто рассматривают, как отладочное средство программиста, но, на самом деле, ее можно использовать не только для отладки. Команда перехватывает и записывает системные вызовы, которые происходят в процессе. Т.е. она полезна в диагностических, учебных и отладочных целях. Например, вы можете использовать команду strace для того, чтобы выяснить, какой на самом деле при запуске программы используется конфигурационный файл.
tcpdump
Tcpdump является простой и надежной утилитой мониторинга сети. Ее базовые возможности анализа протокола позволяют получить общее представление о том, что происходит в вашей сети. Однако, чтобы по-настоящему разобраться в том, что происходит в вашей сети, вам следует воспользоваться программой Wireshark (см. ниже).
Команда top показывает, что происходит с вашими активными процессами. По умолчанию она отображает самые ресурсоемкие задачи, запущенные на сервере, и обновляет список каждые пять секунд. Вы можете отсортировать процессы по PID (идентификатор процесса), времени работы, можете сначала указывать новые процессы, затраты по времени, по суммарному затраченному времени, а также по используемой памяти и по общему времени использования процессора с момента запуска процесса. Я считаю, что это быстрый и простой способ увидеть, что некоторый процесс начинает выходить из-под контроля и из-за этого все движется к проблеме.
uptime
Используйте команду uptime для того, чтобы узнать, как долго работает сервер и сколько пользователей было зарегистрировано в системе. Эта команда также покажет вам среднюю загрузку сервера. Оптимальное значение равно 1 или меньше, что означает, что каждый процесс немедленно получает доступ к процессору и потери циклов процессора отсутствуют.
vmstat
Вы можете использовать команду vmstat , в основном, для контроля того, что происходит с виртуальной памятью. Для того, чтобы получить наилучшую производительность системы хранения данных, Linux постоянно обращается к виртуальной памяти.
Если ваши приложения занимают слишком много памяти, вы получите чрезмерное значение затрат страниц памяти (page-outs) — программы перемещаются из оперативной памяти в пространство подкачки вашей системы, которое находится на жестком диске. Ваш сервер может оказаться в таком состоянии, когда он тратит больше времени на управление памятью подкачки, а не на работу ваших приложений; это состояние называемое пробуксовкой (thrashing). Когда компьютер находится в состоянии пробуксовки, его производительность падает очень сильно. Команда vmstat , которая может отображать либо усредненные данные, либо фактические значения, может помочь вам определить программы, которые занимают много памяти, прежде, чем из-за них ваш процессор перестанет шевелиться.
Wireshark
Программа wireshark , ранее известная как ethereal (и до сих пор часто называют именно так), является «старшим братом» команды tcpdump , хотя она более сложная и с более расширенными возможностями анализа и отчетности по используемым протоколам. У wireshark есть как графический интерфейс, так и интерфейс командной оболочки. Если вам требуется серьезное администрирование сетей, вам следует использовать программу ethereal. И, если вы используете wireshark/ethereal, я настоятельно рекомендую воспользоваться книгой Practical Packet Analysis Криса Сандера (Chris Sander), рассказывающей о том, как с помощью практического анализа пакетов можно получить максимальную отдачу от этой полезной программы.
Это обзор всего лишь нескольких наиболее значимых систем мониторинга из многих, имеющихся для Linux. Тем не менее, если вы сможете освоить эти программы, они помогут вам на пути к вершинам системного администрирования Linux.
Источник
20 средств мониторинга системы Linux, о которых должен знать каждый системный администратор
Вам нужно контролировать функциональные характеристики Linux-сервера? Попробуйте для этого описанные ниже встроенные команды и несколько дополнительных инструментальных средств. В большинстве дистрибутивов Linux есть масса средств мониторинга. Эти средства измеряют характеристики, которые можно использовать для получения информации об активности системы. Вы можете воспользоваться этим инструментарием для поиска причин возникновения проблемы с производительностью. Ниже перечислены лишь некоторые команды из большого числа тех, которые нужны при анализе системы и отладке сервера для поиска следующих проблем:
- Узкие места общего характера
- Узкие места, связанные с диском (дисковой памятью)
- Узкие места, связанные с процессором и оперативной памятью
- Узкие места, связанные с сетью
№ 1: top – команда выдачи данных об активности процессов
Программа top динамически выдает в режиме реального времени информации о работающей системе, т.е. о фактической активности процессов. По умолчанию она выдает задачи, наиболее загружающие процессор сервера, и обновляет список каждые пять секунд.
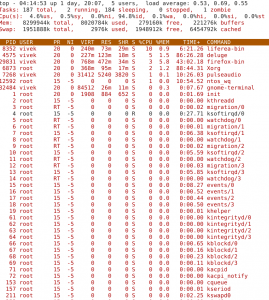
Рис.1: Linux команда — top
Наиболее часто используемые горячие клавиши
При работе команды top можно воспользоваться следующими полезными горячими клавишами:
| Горячая клавиша | Использование |
|---|---|
| t | Включение и выключение выдачи на экран суммарных данных. |
| m | Включение и выключение выдачи на экран информации об использовании памяти. |
| A | Сортировка строк по максимальному потреблению различных системных ресурсов. Полезна для быстрой идентификации задач, для которых в системе не хватает ресурсов. |
| f | Вход в меню интерактивного конфигурирования данных, выдаваемых на экран командой top. Полезна для настройки команды top для выполнения специфической задачи. |
| o | Позволяет вам интерактивно задавать порядок строк, выдаваемой командой top. |
| r | Изменение приоритета процессов с помощью команды renice. |
| k | Удаление процесса с помощью команды kill. |
| z | Переключение между цветным / монохромным вариантом выдачи изображения. |
№ 2: vmstat – активность системы, информация о системе и аппаратных ресурсах
Команда vmstat выдает информационный отчет о активности процессов, памяти, свопинга, поблочного ввода/вывода, прерываний и процессора.
Пример вывода данных:
Выдача статистики использования памяти
Получение данных об активности / неактивности страниц памяти
№ 3: w – определяем, кто зарегистрирован и что они делают
Команда w выдает информацию о том, какие пользователи сейчас находятся в системе и какие процессы запущены от их имени.
Пример вывода данных:
№ 4: uptime – сообщает, как долго работает система
Команду uptime можно использовать с тем, чтобы определить, как долго работает сервер. Выдаются: текущее время, сколько времени работает система, сколько в текущий момент зарегистрировано пользователей и какова средняя нагрузка на систему в последние 1, 5 и 15 минут.
1 можно рассматриваться как оптимальное значение нагрузки. Нагрузка может меняться от системы к системе. Для системы с одним процессором приемлемым может считаться значение от 1 до 3, для мультипроцессорных систем – от 6 до 10.
№ 5: ps – список процессов
Команда ps выдаст краткий список текущих процессов. Для того, чтобы выбрать все процессы, используете параметр -A или –e:
Пример вывода данных:
Команда ps подобна команде top, но выдает больше информации.
Показать больше данных
Для того, чтобы включить режим максимальной выдачи данных (будут показаны аргументы командной строки, переданные в процесс):
Показать потоки (LWP и NLWP)
Показать потоки после процессов
Выдать список всех процессов на сервере
Выдать дерево процессов
Выдать информацию о параметрах безопасности
Показать каждый процесс для пользователя Vivek
Настроить выдачу данных в формате, определенном пользователем
Показывать ID процессов, запущенных под Lighttpd
Показать имя для PID 55977
Выдать 10 процессов, потребляющих наибольшее количество памяти
Выдать 10 процессов, потребляющих наибольший ресурс процессора
№ 6: free – использование памяти
Команда free показывает общее количество свободной и используемой системой физической памяти и памяти свопинга, а также размеры буферов, используемые ядром.
Пример вывода данных:
№ 7: : iostat – средняя загрузка процессора, активность дисков
Команда iostat выдает статистику использования процессора, а также статистику ввода/вывода для устройств, разделов и сетевых файловых систем (NFS).
Пример вывода данных:
№ 8: sar – сбор и выдача данных о системной активности
Команда sar используется для сбора информации о системной активности и выдачи ее в виде отчета или ее сохранения. Чтобы увидеть значение считчика сетевой активности, введите:
Для того, чтобы увидеть значения счетчиков сетевой активности, начиная с 24-го:
С помощью команды sar Вы можете также выдавать данные в режиме реального времени:
Пример вывода данных:
№ 9: mpstat – использование мультипроцессора
Команда mpstat выводит данные об активности каждого имеющегося в наличие процессора, процессор 0 будет первым. Команда mpstat -P ALL выводит данные о среднем использовании ресурсов для каждого из процессоров:
Пример вывода данных:
№ 10: pmap – использование процессами оперативной памяти
Команда pmap выдает данные о распределении памяти между процессами. Использование этой команды позволит найти причину узких мест, связанных с использованием памяти.
Для того, чтобы получить информацию об использовании памяти процессом с pid # 47394, введите:
Пример вывода данных:
Последняя строка очень важна:
- mapped: 933712K общее количество памяти, отведенного под файлы
- writeable/private: 4304K общее количество приватного адресного пространства
- shared: 768000K общее количество адресного пространства, которое данный процесс использует совместно другими процессами.
№ 11 и № 12: netstat и ss – сетевая статистика
Команда netstat выдает информацию о сетевых соединениях, таблицах маршрутизации, статистике по интерфейсам, маскарадинге соединений и многоадресных рассылках. Команда ss используется для выдачи в дамп статистики о сокетах. Она позволяет выдавать информацию, аналогичную выдаваемой командой netstat. Подробное описание команд ss и netstat смотрите по следующим ссылкам:
№13: iptraf – сетевая статистика в режиме реального времени
Команда iptraf запускает цветной интерактивный монитор, следящий за сетевыми IP. Этот монитор сетевых IP базируется на команде ncurses, которая выдает различную сетевую статистику, в том числе информацию о TCP, ведет подсчет UDP, выдает сведения о ICMP и OSPF, информацию о нагрузке на Ethernet, статистику по узлам сети, данные об ошибках контрольных сумм пакетов IP и многое другое. Монитор предоставляет в удобном для чтения виде следующие данные:
- Статистику сетевого трафика по TCP подключениям
- Статистику IP трафика по сетевым интерфейсам
- Статистику сетевого трафика по протоколам
- Статистику сетевого трафика по портам TCP/UDP и по размерам пакетов
- Статистику сетевого трафика по адресам протоколов второго уровня
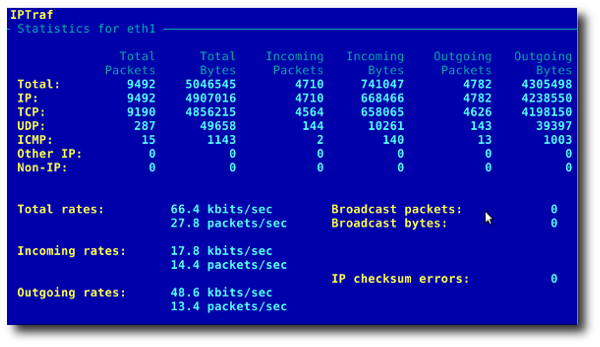
Рис.02; Общая статистика по интерфейсам: статистика трафика IP по сетевым интерфейсам
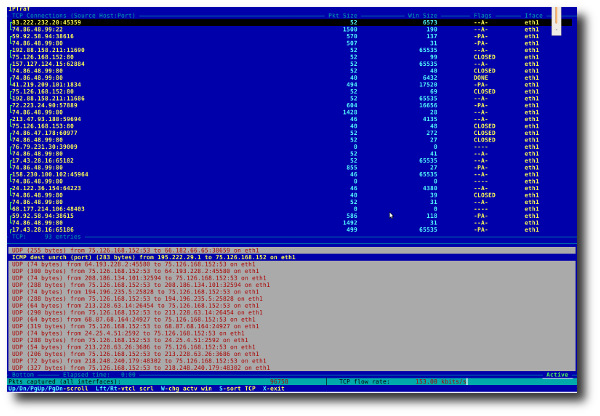
Рис.03: Статистика сетевого трафика по TCP подключениям
№14: tcpdump – детальный анализ сетевого трафика
Команда tcpdump – простая команда, выдающая дамп сетевого трафика. Однако, вам нужно хорошо понимать протоколы TCP/IP для того, чтобы использовать это средство. Например, для того, чтобы показать информацию о трафике DNS, введите следующее:
Для того, чтобы показать все IPv4 HTTP пакеты, идущие на порт и с порта 80, т.е. выдать только те пакеты, которые содержат данные, и, например, не учитывать пакеты SYN и FIN и пакеты ACK-only, введите следующее:
Для того, чтобы показать все сессии FTP для адреса 202.54.1.5, введите следующее:
Для того, чтобы показать все сессии HTTP для адреса 192.168.1.5, введите следующее:
Введите следующую команду и используйте для просмотра подробностей программу анализа wireshark :
№ 15: strace – системные вызовы
Трассировка системных вызовов и сигналов. Это средство полезно для отладки веб сервера и решения других серверных проблем. О том, как использовать это средство и для чего нужна трассировка процессов, смотрите по ссылке strace .
№ 16: Директорий /Proc – различная статистика ядра
В директории /proc имеется подробная информация о различных устройствах и ядре Linux. Подробности смотрите в документации Linux kernel /proc . Самые общие примеры:
№ 17: Nagios – мониторинг сервера и сети
Nagios – популярное open source приложение, предназначенное для мониторинга компьютерных систем и сетей. Вы можете легко следить за всеми своими хостами, сетевым оборудованием и сервисами. Приложение может посылать предупреждающее сообщение, когда что-то идет не так, как надо, а затем – еще одно, когда ситуация исправляется. Имеется приложение FAN — «Fully Automated Nagios» («Полностью автоматизированный Nagios»). Назначение FAN – обеспечить установку Nagios, в том числе и инструментария, предоставляемого сообществом Nagios. FAN распространяется в виде CD образа в стандартном формате ISO, что упрощает установку сервера Nagios. Вдобавок на дистрибутиве имеется масса инструментальных средств, повышающих практическую отдачу от использования Nagios.
№ 18: Cacti – инструментальное веб приложение, используемое для мониторинга
Пакет Cacti является полностью сетевым графическим решением, созданным для добавления графической оболочки к мощному средству хранения данных RRDTool. В пакете Cacti уже «из коробки» имеются средства быстрой регистрации, графические шаблоны с расширенными возможностями, множество методов для сбора данных и пользовательские функции управления. Все это помещено в интуитивно понятный и удобный для использования интерфейс, что имеет смысл при установке в локальных сетях вплоть до сложных сетей с сотнями устройств. Пакет предоставляет данные о сети, процессоре, памяти, зарегистрированных пользователях, серверах Apache, DNS и многое другое. По следующей ссылке смотрите описание, как под CentOS / RHEL установить и сконфигурировать сетевое графическое средство Cacti .
№ 19: KDE System Guard – графический монитор, выдающий сведения о системе в режиме реального времени
KSysguard – сетевое приложение для KDE, осуществляющее мониторинг системы и задач. Это средство может работать в ssh сессии. В нем имеется масса возможностей, например, такие, как клиент/серверные технологии, что позволяет осуществлять мониторинг локальных и удаленных хостов. В графической оболочке используются так называемые сенсоры, которые собирают информацию, выдаваемую приложением. Сенсор может возвращать либо простое значение, либо более сложно сформированные данные, например, таблицы. Для каждого вида данных предлагается один или несколько вариантов выдачи данных. Изображаемые данные сгруппированы в виде отдельных листов, которые можно сохранять и загружать независимо друг от друга. Таким образом, KSysguard не только менеджер простых задач, но также и мощное средство для управления большим серверным хозяйством.
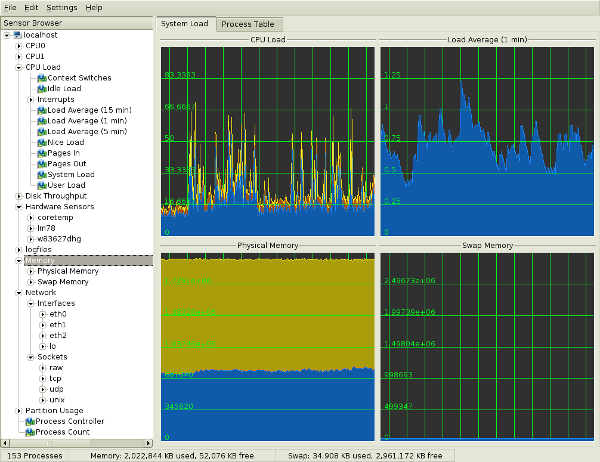
Рис.05: KDE System Guard (рисунок взят из Википедии)
Подробности использования смотрите по следующей ссылке: Руководство по KSysguard .
№ 20: Gnome System Monitor – графическое средство выдачи информации о системе в режиме реального времени
Приложение System Monitor позволит вам получить базовую информацию о системе, а также следить за системными процессами, использованием системных ресурсов и системными файлами. Вы также можете использовать System Monitor для изменения характеристик своей системы. Хотя это не такое мощное приложение, как System Guard для KDE, оно предоставляет основную информацию, которая может быть полезной для пользователей – новичков:
- Отображается различная основная информация об аппаратном и программном обеспечении компьютера
- Версия ядра Linux
- Версия GNOME
- Аппаратные средства
- Установленная оперативная память
- Процессоры и их скорость
- Статус системы
- Имеющееся в наличии дисковое пространство
- Процессы
- Память и пространство своппинга
- Использование сети
- Файловые системы
- Список всех смонтированных файловых систем вместе с основной информацией о каждой из них
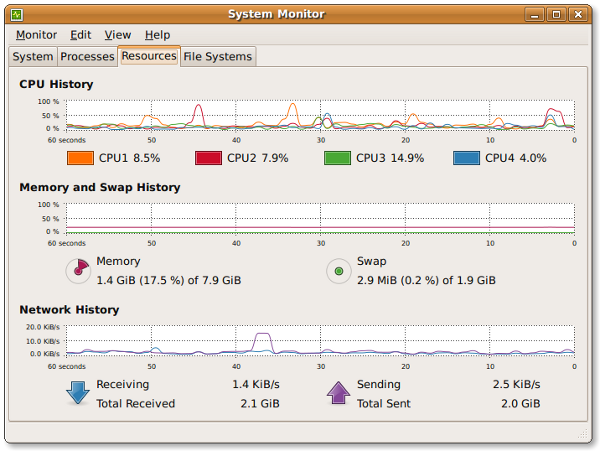
Рис.6: Приложение Gnome System Monitor
Бонус: Дополнительные инструментальные средства
И еще несколько инструментальных средств:
- nmap — сканирует ваш сервер на предмет открытых портов..
- lsof — перечисляет открытые файлы, сетевые соединения и еще многое.
- ntop — инструментальное веб средство ntop является наилучшим средством, следящим за использованием сети, причем это делается точно так, как с помощью команды top просматриваются процессы, т.е. это программное обеспечение мониторинга сетевого трафика. Вы можете следить за состоянием сети и распределением трафика по различным протоколам, таким как UDP, TCP, DNS, HTTP и другим.
- Conky — Еще одно хорошее средство мониторинга, предназначенное для использования в X Window. Оно хорошо конфигурируемое и позволяет следить за многими системными переменными, в том числе состоянием процессора, памяти, пространства свопинга, дисковыми носителями, температурой, процессами, сетевыми интерфейсами, зарядом батареи, системными сообщениями, поступающими письмами и т.д.
- GKrellM — Может использоваться для мониторинга состояния процессоров, оперативной памяти, жестких дисков, сетевыми интерфейсами, локальными и удаленными почтовыми ящиками и многими другими вещами.
- vnstat — vnStat является консольным монитором сетевого трафика. Она позволяет для выбранных интерфейсов вести журнал сетевого трафика в течение часов, дней и месяцев.
- htop — улучшенная версия интерактивного просмотрщика процессов top. htop позволяет просматривать процессы в виде дерева процессов.
- mtr — mtr объединяет в одной сетевой инструментальной программе функциональность программ traceroute и ping.
Не упустил ли я чего-либо? Пожалуйста, добавьте в комментариях свои любимые средства мониторинга системы.
Комментарии
Приведены выборочно только те, в которых сообщается об инструментальных программах, не указанных в основном списке – прим.пер.
№ 3, Chris: … для систем с небольшим количеством машин я рекомендую использовать Munin . Его легко устанавливать и конфигурировать. Мое любимое средство мониторинга linux кластера — Ganglia .
№ 4, Ftaurino: Еще один полезный инструмент — dstat , который выдает столько же данных, как вместе взятые vmstat, iostat, ifstat и netstat, и даже больше…
№ 10, Amr El-Sharnoby: Я убедился, что самое лучшее средство для отслеживания узких мест, связанных с процессами, процессором, памятью и жесткими дисками, причем все в одном, – это atop… Но само средство может вызвать массу проблем на сильно загруженных серверах, поскольку учет процессов идет непрерывно и сервис работает постоянно…
Для того, чтобы в системах RHEL, CentOS использовать это средство эффективно, выполните следующее:
1 — подключите rpmforge repo,
2 — установите atop с помощью # yum
3 – уничтожьте процесс с помощью # killall atop,
4 – отключите atop с помощью # chkconfig,
5 – удалите rf /tmp/atop.d/ и /var/log/atop/,
6 – после это не запускайте его с помощью команды «atop», вместо этого используйте команду #ATOPACCT=»atop».
Этот инструмент сэкономил мне сотни часов времени, помог найти узкие места и решить связанные с ними проблемы …
№ 14, Cristiano: … хотелось бы добавить IFTOP, это действительно простое и не требующее значительных ресурсов средство, оно очень полезно, когда Вы хотите узнать, откуда был последний доступ к серверу и куда идет трафик…
№ 21, Ponzu: vi – инструметальное средство (хорошо известный мощный текстовый редактор — прим. пер.), используемое для проверки и модификации практически любого конфигурационного файла.
№ 22, Eric Schulman: … стоит упомянуть о dtrace, которое пригодится требовательным хакерам, желающим больше узнать об операционной системе и о внутренней структуре ее программ…
№ 25, Adrian Fita: … мне бы хотелось добавить iotop, отслеживающий использование диска различными процессами, и jnettop – очень простое средство, отслеживающее разделение ширины сетевого канала между различными подключениями в системе Linux …
№ 27, Praveen K: … я бы добавил команды whoami ,who am i, finger, pinky , id …
№ 29, Mathieu Desnoyers: … еще инструмент который, как мне кажется, пропущен в этом списке, — это LTTng. Это общесистемное средство трассировки, которое поможет разобраться со сложными проблемами, возникающими в многопоточных многопроцессорных приложениях, многократно обращающихся к ядру. Проект доступен по ссылке http://www.lttng.org . Трасировщик входит в состав последних версий дистрибутивов SuSE, WindRiver, Monta Vista и STLinux. Стандартный способ его использования – установить пропатченное ядро. Оно идет вместе с анализатором трассировок LTTV, который является прекрасным средством слежения за поведением системы…
№ 33, Kburger: … если Вы обсуждаете веб сервер, то прекрасное средство следить за активностью сервера Apache — apachetop
№ 34, Ram: … Вы забыли самое важное — net-snmpd. С его помощью Вы можете собрать сырые данные. Затем с помощью snmpwalk и скриптов Вы можете сделать свой собственный веб NMS, который будет собирать обычные данные, такие как прохождение пингов, использование дискового пространства, падение сервисов…
№ 35, Kartik Mistry: …»iotop» – прекрасное средство, которое следовало бы включить в список. Я очень часто использую «vnstat» для отслеживания закачек данных …
№ 37, Feilong: … обратите внимание на очень мощное средство, называемое nmon. Я использую его в системе AIX IBM, но сейчас оно работает на всех современных системах GNU/linux…
№ 40, Ken McDonell: …Если ваша «система » большая и / или распределенная и вопросы производительности, которыми Вы занимаетесь, сложные, вам желательно использовать Performance Co-Pilot (PCP). В нем Вы получите все данных, которые можно получить с помощью упомянутых вами инструментальных средств (и даже больше), его можно расширить добавляя новые приложения и слои сервисов, он работает по сети, пригоден для оценки кластеров и выдает как информацию в режиме реального времени, так и выполняет ретроспективный анализ. Смотрите http://www.oss.sgi.com/projects/pcp . PCP входит в состав дистрибутивов на основе Debian и в дистрибутив SUSE; вероятнее всего в ближайшем будущем он появится в дистрибутивах RH. В качестве бонуса PCP может выполнять мониторинг платформ не на базе Linux (Windows и некоторые производные от систем Unix).
№ 45. Aleksey Tsalolikhin: … я бы еще упомянул «ngrep» – сетевой (network) grep…
№ 48, Komradebob: …удивлен, что среди предложений не обнаружил следующий инструментарий: bmon – отображает / отслеживает в режиме реального времени сетевую активность / ширину пропускания канала; etherape – отличный визуальный индикатор, показывающий сетевой трафик; wireshark – tcpdump на стероидах; multitail – отслеживание в одном терминальном окне состояния многих файлов; swatch – отслеживает состояние регистрационных файлов и выдает оповещения.
№ 50, Jay: … phpsysinfo – еще один прекрасный и не требующий много ресурсов веб инструмент, осуществляющий мониторинг. Очень прост в настройке и использовании …
№ 51, Manuel Fraga: Osmius — инструментальное средство мониторинга (open source) — C++ и Java. С невероятной производительностью мониторит все, что подключается к сети …
№ 55, Balaji: … trafmon – еще одно полезное средство …
№ 56, Stefan: А для тех, кому нравятся несложные и компактные графические средства измерения, — xosview +disk -ints –bat
№ 63, Tman: Для профессионального мониторинга сетей используйте Zenoss: Zenoss Core (open source): http://www.zenoss.com/product/network-monitoring
№ 65, Eddy: Я не вижу в списке ifconfig или iwconfig
№ 66, Kestev: openNMS
Вы можете также прочитать другие статьи о средствах мониторинга системы в Линукс в разделе Разные административные задачи Библиотеки нашего сайта.
Источник



