- Конфигурирование и компиляция ядра Linux
- Установка утилит
- Скачиваем исходный код ядра
- Распаковываем исходный код ядра
- Конфигурация ядра
- Компиляция ядра
- Установка (инсталляция) ядра
- Запуск системы с новым ядром
- How to check how many CPUs are there in Linux system
- How do you check how many CPUs are there in Linux system?
- How to display information about the CPU on Linux
- Use /proc/cpuinfo to find out how many CPUs are there in Linux
- Run top or htop command to obtain the number of CPUs/cores in Linux
- Execute nproc print the number of CPUs available on Linux
- How to probe for CPU/core on Linux using hwinfo command
- Linux display CPU core with getconf _NPROCESSORS_ONLN command
- dmidecode -t processor command
- Here is a quick video demo of lscpu and other commands:
- Conclusion
- Пишем простой модуль ядра Linux
- Захват Золотого Кольца-0
- Не для простых смертных
- Необходимые компоненты
- Установка среды разработки
- Начинаем
- Немного интереснее
- Тестирование улучшенного примера
- Заключение
Конфигурирование и компиляция ядра Linux
Пересборка ядра Linux дело очень интересное и почему-то часто отпугивает новичков. Но ничего сложного в этом нет, и скомпилировать ядро Linux бывает не сложнее, чем собрать (скомпилировать) любую другую программу из исходников. Пересборка ядра может понадобиться, когда вам требуются какие-нибудь функции, не включенные в текущее ядро, или же, наоборот, вы хотите что-то отключить. Все дальнейшие действия мы будем выполнять в Ubuntu Linux.
Установка утилит
Для настройки и сборки ядра Linux вам потребуется установить несколько пакетов, которые понадобятся для сборки и настройки ядра: kernel-package , build-essential , libncurses-dev . Сделать это можно командой:
Скачиваем исходный код ядра
Теперь нужно скачать исходный код ядра. Мы будем скачивать ядро для Ubuntu. Вы можете скачать определенную версию ядра, например, ту, которую вы в данный момент используете или же скачать самую последнюю версию. Для того, чтобы определить версию ядра Linux, которую вы используете, выполните команду uname с параметром -r :
Вывод команды будет примерно следующим:
Имя пакета, содержащего исходные коды ядра обычно имеет следующий вид: linux-source-Версия. Например, для ядра версии 2.6.24: linux-source-2.6.24. Самая последняя версия ядра в репозиториях Ubuntu называется просто linux-source, без указания версии на конце. Для установки исходных кодов последней версии ядра Ubuntu Linux, выполните команду:
Эта команда скачивает исходники ядра и размещает их в директории /usr/src . На момент написания заметки последняя версия ядра, которая была скачана — 2.6.27, ее мы и будем использовать. Если мы теперь перейдем в директорию /usr/src и выполним команду ls , то увидим, что среди файлов присутствует файл linux-source-2.6.27.tar.bz2. Это и есть исходные коды ядра Linux (ядра Ubuntu).
Распаковываем исходный код ядра
Перейдем в директорию /usr/src и разархивируем ядро. Для этого выполните следующие команды:
Для удобства мы создали символьную ссылку с именем linux , которая указывает на директорию с исходниками.
Конфигурация ядра
Теперь перейдем к конфигурированию ядра. Чтобы не создавать конфигурацию с нуля, возьмем за основу конфигурацию ядра, которая в данный момент используется. Получить текущую конфигурацию можно выполнив команду make oldconfig . Выполните в терминале:
В результате выполнения команды make oldconfig создастся файл .config , содержащий параметры конфигурации ядра.
Получить справку по всем параметрам make для ядра Linux вы можете, выполнив команду make help .
Для изменения конфигурации ядра мы воспользуемся консольной утилитой menuconfig . Для ее запуска выполните:
Перед вами появится интерфейс, в котором вы можете включать или отключать определенные опции ядра:
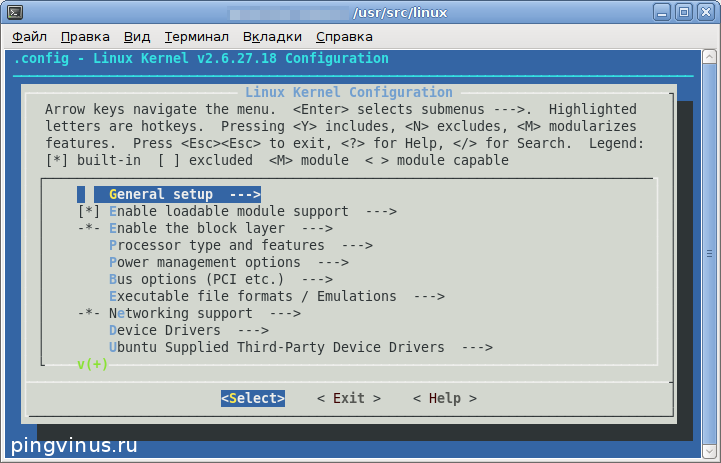
Для примера я включу опцию «NTFS write support». Для этого, нажимая кнопку Вниз , найдите пункт «File systems» и нажмите Enter .
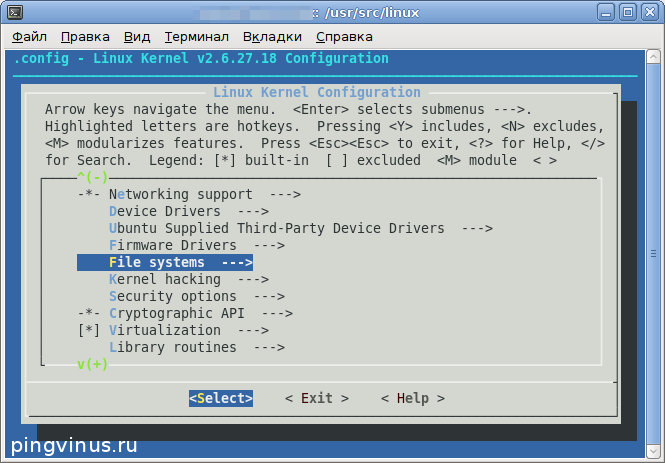
Вы окажетесь в меню настройки файловых систем. Найдите в этом списке пункт «DOS/FAT/NT Filesystems» и нажмите Enter .
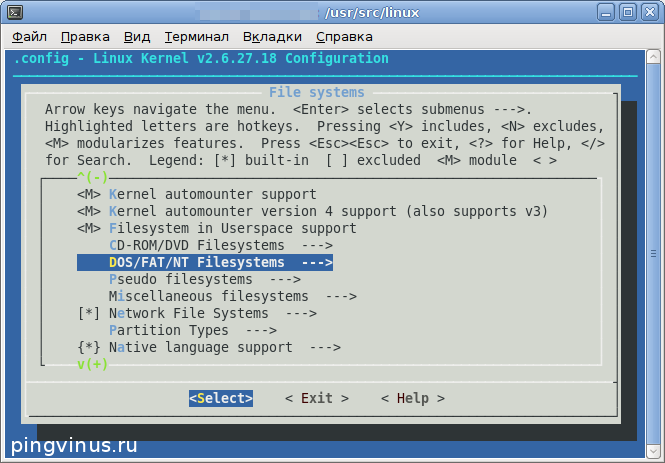
Перейдите к пункту «NTFS write support» и нажмите Пробел , рядом с пунктом появится звездочка, означающая, что данная опция будет включена в ядро.
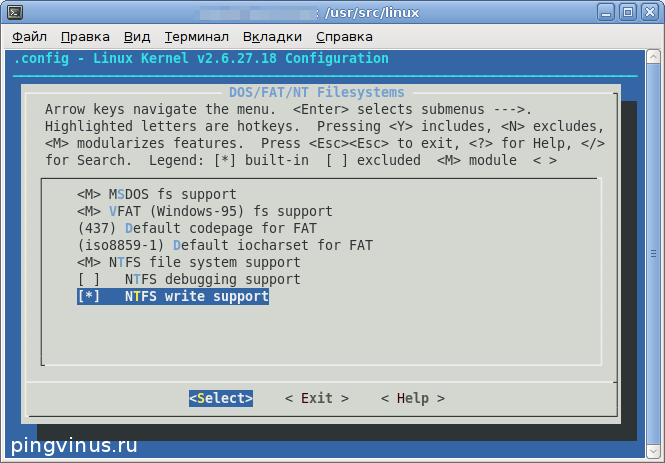
Теперь выберите «Exit» (нажав кнопку Вправо и затем Enter ) и выйдите из утилиты. Перед выходом из утилиты выскочит сообщение с вопросом — сохранить проделанные изменения, выберите Yes.
Компиляция ядра
Пришло время скомпилировать ядро с теми изменениями, которые мы внесли на предыдущем шаге. Для начала выполним команду, которая удалит файлы (если они имеются), оставшиеся от предыдущей компиляции:
Наконец, чтобы запустить компиляцию ядра, выполним команду:
Ключ -append-to-version используется, чтобы добавить к имени файла образа ядра, который мы получим после компиляции, строку -mykernel , чтобы было проще идентифицировать свое ядро. Вместо -mykernel вы можете использовать любой префикс.
Компиляция ядра занимает довольно много времени и может длиться от нескольких десятков минут до нескольких часов, в зависимости от мощности вашего компьютера.
Установка (инсталляция) ядра
После компиляции ядра вы получили на выходе два файла: linux-image-2.6.27.18-mykernel_2.6.27.18-mykernel-10.00.Custom_i386.deb, linux-headers-2.6.27.18-mykernel_2.6.27.18-mykernel-10.00.Custom_i386.deb. Мы воспользуемся командной dpkg -i , которая автоматически установит ядро и пропишет его в ваш загрузчик GRUB (в файл /boot/grub/menu.lst ). Отмечу, что ядро будет установлено, как ядро по умолчанию, поэтому если оно у вас не загрузится вам нужно будет загрузиться, используя ваше предыдущее ядро (оно должно быть в списке меню GRUB при загрузке компьютера) и вручную изменять файл menu.lst . Итак, для установки ядра выполните команды:
Запуск системы с новым ядром
Проверим работоспособность системы с новым ядром. Перезагрузите компьютер. В меню загрузчика GRUB вы должны будете увидеть новый пункт, соответствующей вашему новому ядру, которое должно загрузиться по умолчанию. Если все пройдет успешно, то система запустится с новым ядром.
Источник
How to check how many CPUs are there in Linux system
I am a new Linux user. How do you check how many CPUs are there in Linux system using the command line option?
Introduction: One can obtain the number of CPUs or cores in Linux from the command line. The /proc/cpuinfo file stores CPU and system architecture dependent items, for each supported architecture. You can view /proc/cpuinfo with the help of cat command or grep command/egrep command. This page shows how to use /proc/cpuinfo file and lscpu command to display number of processors on Linux.
| Tutorial details | |
|---|---|
| Difficulty level | Easy |
| Root privileges | Yes |
| Requirements | None |
| Est. reading time | 3 minutes |
How do you check how many CPUs are there in Linux system?
You can use one of the following command to find the number of physical CPU cores including all cores on Linux:
- lscpu command
- cat /proc/cpuinfo
- top or htop command
- nproc command
- hwinfo command
- dmidecode -t processor command
- getconf _NPROCESSORS_ONLN command
Let us see all commands and examples in details.
How to display information about the CPU on Linux
Just run the lscpu command:
$ lscpu
$ lscpu | egrep ‘Model name|Socket|Thread|NUMA|CPU\(s\)’
$ lscpu -p
The output clearly indicate that I have:
- CPU model/make: AMD Ryzen 7 1700 Eight-Core Processor
- Socket: Single (1)
- CPU Core: 8
- Thread per core: 2
- Total threads: 16 ( CPU core[8] * Thread per core [2])
Use /proc/cpuinfo to find out how many CPUs are there in Linux
Run top or htop command to obtain the number of CPUs/cores in Linux
Execute nproc print the number of CPUs available on Linux
Let us print the number of installed processors on your system i.e core count:
$ nproc —all
$ echo «Threads/core: $(nproc —all)»
Sample outputs:
How to probe for CPU/core on Linux using hwinfo command
$ hwinfo —cpu —short ## short info ##
$ hwinfo —cpu ## detailed info on CPUs ##
Linux display CPU core with getconf _NPROCESSORS_ONLN command
One can query Linux system configuration variables with getconf command:
$ getconf _NPROCESSORS_ONLN
$ echo «Number of CPU/cores online at $HOSTNAME: $(getconf _NPROCESSORS_ONLN)»
Sample outputs:
- No ads and tracking
- In-depth guides for developers and sysadmins at Opensourceflare✨
- Join my Patreon to support independent content creators and start reading latest guides:
- How to set up Redis sentinel cluster on Ubuntu or Debian Linux
- How To Set Up SSH Keys With YubiKey as two-factor authentication (U2F/FIDO2)
- How to set up Mariadb Galera cluster on Ubuntu or Debian Linux
- A podman tutorial for beginners – part I (run Linux containers without Docker and in daemonless mode)
- How to protect Linux against rogue USB devices using USBGuard
Join Patreon ➔
dmidecode -t processor command
You can use get BIOS and hardware information with dmidecode command (DMI table decoder) on Linux. To find out how many CPUs are there in Linux system, run:
$ sudo dmidecode -t 4
$ sudo dmidecode -t 4 | egrep -i ‘core (count|enabled)|thread count|Version’
Here is a quick video demo of lscpu and other commands:
Conclusion
You learned how to display information about the CPU architecture, core, threads, CPU version/model, vendor and other information using various Linux command line options.
🐧 Get the latest tutorials on Linux, Open Source & DevOps via
Источник
Пишем простой модуль ядра Linux

Захват Золотого Кольца-0
Linux предоставляет мощный и обширный API для приложений, но иногда его недостаточно. Для взаимодействия с оборудованием или осуществления операций с доступом к привилегированной информации в системе нужен драйвер ядра.
Модуль ядра Linux — это скомпилированный двоичный код, который вставляется непосредственно в ядро Linux, работая в кольце 0, внутреннем и наименее защищённом кольце выполнения команд в процессоре x86–64. Здесь код исполняется совершенно без всяких проверок, но зато на невероятной скорости и с доступом к любым ресурсам системы.
Не для простых смертных
Написание модуля ядра Linux — занятие не для слабонервных. Изменяя ядро, вы рискуете потерять данные. В коде ядра нет стандартной защиты, как в обычных приложениях Linux. Если сделать ошибку, то повесите всю систему.
Ситуация ухудшается тем, что проблема необязательно проявляется сразу. Если модуль вешает систему сразу после загрузки, то это наилучший сценарий сбоя. Чем больше там кода, тем выше риск бесконечных циклов и утечек памяти. Если вы неосторожны, то проблемы станут постепенно нарастать по мере работы машины. В конце концов важные структуры данных и даже буфера могут быть перезаписаны.
Можно в основном забыть традиционные парадигмы разработки приложений. Кроме загрузки и выгрузки модуля, вы будете писать код, который реагирует на системные события, а не работает по последовательному шаблону. При работе с ядром вы пишете API, а не сами приложения.
У вас также нет доступа к стандартной библиотеке. Хотя ядро предоставляет некоторые функции вроде printk (которая служит заменой printf ) и kmalloc (работает похоже на malloc ), в основном вы остаётесь наедине с железом. Вдобавок, после выгрузки модуля следует полностью почистить за собой. Здесь нет сборки мусора.
Необходимые компоненты
Прежде чем начать, следует убедиться в наличии всех необходимых инструментов для работы. Самое главное, нужна машина под Linux. Знаю, это неожиданно! Хотя подойдёт любой дистрибутив Linux, в этом примере я использую Ubuntu 16.04 LTS, так что в случае использования других дистрибутивов может понадобиться слегка изменить команды установки.
Во-вторых, нужна или отдельная физическая машина, или виртуальная машина. Лично я предпочитаю работать на виртуальной машине, но выбирайте сами. Не советую использовать свою основную машину из-за потери данных, когда сделаете ошибку. Я говорю «когда», а не «если», потому что вы обязательно подвесите машину хотя бы несколько раз в процессе. Ваши последние изменения в коде могут ещё находиться в буфере записи в момент паники ядра, так что могут повредиться и ваши исходники. Тестирование в виртуальной машине устраняет эти риски.
И наконец, нужно хотя бы немного знать C. Рабочая среда C++ слишком велика для ядра, так что необходимо писать на чистом голом C. Для взаимодействия с оборудованием не помешает и некоторое знание ассемблера.
Установка среды разработки
На Ubuntu нужно запустить:
Устанавливаем самые важные инструменты разработки и заголовки ядра, необходимые для данного примера.
Примеры ниже предполагают, что вы работаете из-под обычного пользователя, а не рута, но что у вас есть привилегии sudo. Sudo необходима для загрузки модулей ядра, но мы хотим работать по возможности за пределами рута.
Начинаем
Приступим к написанию кода. Подготовим нашу среду:
Запустите любимый редактор (в моём случае это vim) и создайте файл lkm_example.c следующего содержания:
Мы сконструировали самый простой возможный модуль, рассмотрим подробнее самые важные его части:
- В include перечислены файлы заголовков, необходимые для разработки ядра Linux.
- В MODULE_LICENSE можно установить разные значения, в зависимости от лицензии модуля. Для просмотра полного списка запустите:
Впрочем, пока мы не можем скомпилировать этот файл. Нужен Makefile. Такого базового примера пока достаточно. Обратите внимание, что make очень привередлив к пробелам и табам, так что убедитесь, что используете табы вместо пробелов где положено.
Если мы запускаем make , он должен успешно скомпилировать наш модуль. Результатом станет файл lkm_example.ko . Если выскакивают какие-то ошибки, проверьте, что кавычки в исходном коде установлены корректно, а не случайно в кодировке UTF-8.
Теперь можно внедрить модуль и проверить его. Для этого запускаем:
Если всё нормально, то вы ничего не увидите. Функция printk обеспечивает выдачу не в консоль, а в журнал ядра. Для просмотра нужно запустить:
Вы должны увидеть строку “Hello, World!” с меткой времени в начале. Это значит, что наш модуль ядра загрузился и успешно сделал запись в журнал ядра. Мы можем также проверить, что модуль ещё в памяти:
Для удаления модуля запускаем:
Если вы снова запустите dmesg, то увидите в журнале запись “Goodbye, World!”. Можно снова запустить lsmod и убедиться, что модуль выгрузился.
Как видите, эта процедура тестирования слегка утомительна, но её можно автоматизировать, добавив:
в конце Makefile, а потом запустив:
для тестирования модуля и проверки выдачи в журнал ядра без необходимости запускать отдельные команды.
Теперь у нас есть полностью функциональный, хотя и абсолютно тривиальный модуль ядра!
Немного интереснее
Копнём чуть глубже. Хотя модули ядра способны выполнять все виды задач, взаимодействие с приложениями — один из самых распространённых вариантов использования.
Поскольку приложениям запрещено просматривать память в пространстве ядра, для взаимодействия с ними приходится использовать API. Хотя технически есть несколько способов такого взаимодействия, наиболее привычный — создание файла устройства.
Вероятно, раньше вы уже имели дело с файлами устройств. Команды с упоминанием /dev/zero , /dev/null и тому подобного взаимодействуют с устройствами “zero” и “null”, которые возвращают ожидаемые значения.
В нашем примере мы возвращаем “Hello, World”. Хотя это не особенно полезная функция для приложений, она всё равно демонстрирует процесс взаимодействия с приложением через файл устройства.
Вот полный листинг:
Тестирование улучшенного примера
Теперь наш пример делает нечто большее, чем просто вывод сообщения при загрузке и выгрузке, так что понадобится менее строгая процедура тестирования. Изменим Makefile только для загрузки модуля, без его выгрузки.
Теперь после запуска make test вы увидите выдачу старшего номера устройства. В нашем примере его автоматически присваивает ядро. Однако этот номер нужен для создания нового устройства.
Возьмите номер, полученный в результате выполнения make test , и используйте его для создания файла устройства, чтобы можно было установить коммуникацию с нашим модулем ядра из пространства пользователя.
(в этом примере замените MAJOR значением, полученным в результате выполнения make test или dmesg )
Параметр c в команде mknod говорит mknod, что нам нужно создать файл символьного устройства.
Теперь мы можем получить содержимое с устройства:
или даже через команду dd :
Вы также можете получить доступ к этому файлу из приложений. Это необязательно должны быть скомпилированные приложения — даже у скриптов Python, Ruby и PHP есть доступ к этим данным.
Когда мы закончили с устройством, удаляем его и выгружаем модуль:
Заключение
Надеюсь, вам понравились наши шалости в пространстве ядра. Хотя показанные примеры примитивны, эти структуры можно использовать для создания собственных модулей, выполняющих очень сложные задачи.
Просто помните, что в пространстве ядра всё под вашу ответственность. Там для вашего кода нет поддержки или второго шанса. Если делаете проект для клиента, заранее запланируйте двойное, если не тройное время на отладку. Код ядра должен быть идеален, насколько это возможно, чтобы гарантировать цельность и надёжность систем, на которых он запускается.
Источник



