- Команда Head в Linux
- Синтаксис команды Head
- Как использовать команду головы
- Как отобразить определенное количество строк
- Как отобразить определенное количество байтов
- Как отображать несколько файлов
- Как использовать голову с другими командами
- Выводы
- Команды фильтрации в Linux. head, tail, sort, nl, wc, cut, sed, uniq, tac
- Фильтры в Linux
- head
- tail
- sort
- nl
- wc
- cut
- sed
- uniq
- tac
- Вывод
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Работа с текстовыми выводами в Linux
- Команда cat
- Команда cut
- Команда expand
- Команда fmt
- Команда head
- Команда od
- Команда join
- Команда less
- Команда nl
- Команда paste
- Команда pr
- Команда sed
- Команда sort
- Команда split
- Команда tail
- Команда tr
- Команда unexpand
- Команда uniq
- Команда wc
Команда Head в Linux
Команда head выводит первые строки (по умолчанию 10 строк) одного или нескольких файлов или передаваемых данных в стандартный вывод.
В этом руководстве мы объясним, как использовать утилиту head в Linux, на практических примерах и подробных объяснениях наиболее распространенных опций head.
Синтаксис команды Head
Синтаксис команды head следующий:
- OPTION — варианты головы . Мы рассмотрим наиболее распространенные варианты в следующих разделах.
- FILE — Ноль или более имен входных файлов. Если ФАЙЛ не указан или если ФАЙЛ — — , head будет читать стандартный ввод.
Как использовать команду головы
В простейшей форме при использовании без каких-либо параметров команда head отобразит первые 10 строк.
Как отобразить определенное количество строк
Используйте параметр -n ( —lines ), за которым следует целое число, указывающее количество отображаемых строк:
Вы можете опустить букву n и использовать только дефис ( — ) и цифру (без пробелов между ними).
Чтобы отобразить первые 30 строк файла с именем filename.txt , введите:
Следующее приведет к тому же результату, что и приведенные выше команды:
Как отобразить определенное количество байтов
Параметр -c ( —bytes ) позволяет распечатать определенное количество байтов:
Например, чтобы отобразить первые 100 байтов данных из файла с именем filename.txt , введите:
Вы также можете использовать суффикс множителя после числа, чтобы указать количество отображаемых байтов. b умножает его на 512, kB умножает на 1000, K умножает на 1024, MB умножает на 1000000, M умножает на 1048576 и так далее.
Следующая команда отобразит первые пять килобайт (2048) файла filename.txt :
Как отображать несколько файлов
Если в качестве входных данных для команды head указано несколько файлов, она отобразит первые десять строк из каждого предоставленного файла.
Вы можете использовать те же параметры, что и при отображении одного файла.
В этом примере показаны первые 20 строк файлов filename1.txt и filename2.txt :
Если используется более одного файла, каждому выходному файлу предшествует заголовок с именем файла.
Как использовать голову с другими командами
Команду head можно использовать в сочетании с другими командами, перенаправляя стандартный вывод из / в другие утилиты с помощью каналов.
Следующая команда будет хешировать переменную среды $RANDOM , отображать первые 32 байта и отображать случайную строку из 24 символов:
Выводы
К настоящему времени вы должны хорошо понимать, как использовать команду Linux head. Это дополнение к команде tail, которая выводит последние строки файла на терминал.
Источник
Команды фильтрации в Linux. head, tail, sort, nl, wc, cut, sed, uniq, tac
В статье мы рассмотрим множество команд для фильтрации. Изучение команд будет сопровождаться подробными примерами.
Фильтры в Linux
Фильтры — это способ получения необработанных данных, созданных другой программой или сохраненных в файле.
Эти фильтры имеют различные параметры командной строки, которые изменяют их поведение. В результате, всегда полезно проверить страницу руководства для фильтра.
В приведенных ниже примерах мы будем предоставлять данные для этих программ с помощью файла.
Для каждой из демонстраций ниже будет использоваться следующий файл в качестве примера. Этот файл примера содержит список содержимого, чтобы немного облегчить понимание примеров. Кроме того, файл фактически указан как путь, и поэтому вы можете использовать абсолютные и относительные пути, а также подстановочные знаки.
head
Head — это программа, которая печатает первые строки ввода. По умолчанию он напечатает первые 10 строк, но мы можем изменить это с помощью аргумента командной строки.
head [-количество строк для печати] [путь]

tail
Данная команда противоположна head. Tail — это команда, которая печатает последние строки ввода. По умолчанию он напечатает последние 10 строк, но мы можем изменить это с помощью аргумента командной строки.
tail [-количество строк для печати] [путь]

Выше было поведение tail по умолчанию. А ниже указывается заданное количество строк.
sort
Сортировка — это красиво и просто. По умолчанию сортировка выполняется в алфавитном порядке. Между тем, существует множество параметров, позволяющих изменить механизм сортировки. Кроме того, не забудьте проверить справочную страницу, чтобы увидеть все, что он может сделать.
sort [-options] [path]

nl
Обозначение чисел в Linux реализуется за счет команды nl.
nl [-options] [путь]

Вот еще несколько полезных опций командной строки.

В приведенном выше примере мы использовали 2 параметра командной строки. Первый -s указывает, что следует печатать после числа. С другой стороны, второй -w указывает, сколько отступов ставить перед числами. Для первого нам нужно было включить пробел как часть того, что было напечатано.
Поскольку пробелы обычно используются в качестве символов-разделителей в командной строке, нам нужен был способ указать, что пробел является частью нашего аргумента, а не просто между аргументами. Мы сделали это, включив аргумент в кавычки.
wc
wc обозначает количество слов, а также символы и строки. По умолчанию он подсчитывает все вышеперечисленное. Между тем, используя параметры командной строки, мы можем ограничить его только тем, что нам нужно.
wc [-options] [путь]

Иногда вам просто нужно одно из этих значений. -l даст нам только строки, -w даст нам слова, а -m даст нам символы.

Кроме того, Вы можете комбинировать аргументы командной строки.

cut
Cut — это хорошая команда, которую можно использовать, если ваш контент разделен на столбцы и вам нужны только определенные поля.
вырезать [-опции] [путь]
В нашем примере файла у нас есть данные в 3 столбцах. Допустим, мы хотели только первый столбец.

По умолчанию cut использует символ TAB в качестве разделителя для идентификации полей. Опция -f позволяет нам указать, какое поле мы бы хотели. Если нам нужно 2 или более полей, мы разделяем их запятой, как показано ниже.
sed
Sed расшифровывается как Stream Editor и позволяет эффективно выполнять поиск и замену наших данных. Это довольно мощная команда, но мы будем использовать ее здесь в ее базовом формате.
Инициал s обозначает замену и определяет действие, которое нужно выполнить. Между первой и второй косой чертой (/) мы размещаем то, что ищем. Затем между вторым и третьим слэшем, чем мы хотим его заменить.

uniq
Uniq означает уникальный, и его работа заключается в удалении повторяющихся строк из данных. Однако одно ограничение заключается в том, что эти линии должны быть смежными.
uniq [опции] [путь]

tac
Ребята из Linux известны своим забавным чувством юмора. Программа TAC на самом деле является CAT наоборот. Это было названо так, как это делает противоположность CAT. Получив данные, он напечатает последнюю строку первой, вплоть до первой строки.

Вывод
В данной статье мы ознакомились со следующими командами:
- head — просмотр первых n строк данных.
- tail — просмотр последних n строк данных.
- sort — организуйте данные в порядке.
- nl — напечатайте номера строк перед данными.
- wc — распечатать количество строк, слов и символов.
- cut — разрезать данные на поля и отображать только указанные поля.
- sed — сделайте поиск и замените данные.
- uniq — удалить дубликаты строк.
- tac — распечатайте данные в обратном порядке.
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Работа с текстовыми выводами в Linux
10 минут чтения
Цель стати разобраться с текстовыми потоками. А также рассмотреть фильтрование текстовых выводы логов их редактирование, журналов сообщений и т.д. Проще говоря, рассмотреть фильтрация и корректировка выводимого на экран текста. Текстовый поток так называется, потому что это выводимая информация может быть не просто статичный текстовый файл, а те текстовые файлы, которые постоянно меняются или дополняются в режиме реального времени.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена

Список стандартных команд, которые понадобятся для достижения цели:
Для начала создадим пару текстовых файлов. Переходим в домашнюю корневую папку пользователя root. Переключение пользователя sudo su , и cd
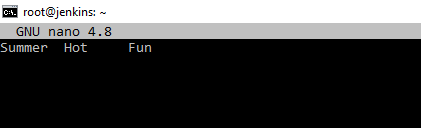
. В любом текстовом редакторе создаем 2 файла hello1.txt и hello2.txt с содержанием как на скриншотах.

Первый. И второй ниже.
Команда cat
Начнем с команды, с которой уже не однократно встречались, команда cat. Сначала посмотрим справку по данной команде. man cat . Тут мы можем увидеть, что данная команда предназначена для объединения файлов и печати на стандартный вывод информации. Под стандартным выводом подразумевается вывод на консоль информации. Так же можно увидеть, что у данной команды есть ключи.
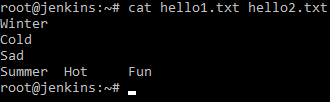
Самое простое применение данной команды. Вводим cat hello1.txt команда показывает то, что на скриншоте выше.
Проведем маленький эксперимент и выведем сразу информацию из двух созданных файлов.
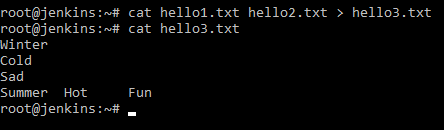
А в справке было написано, что команда может объединять содержимое файлов. Попробуем:
Мы вывели на стандартный вывод (консоль) содержимое файлов и передали то, что на экране в новый файл hello3.txt. А затем просто вывели на консоль. Результат можно посмотреть на скриншоте ниже.
Если нам файл более не нужен можно воспользоваться командой для удаления файлов
Команда cat более часто используется для объединения файлов, для просмотра содержимого чаще используются другие команды.
Команда cut
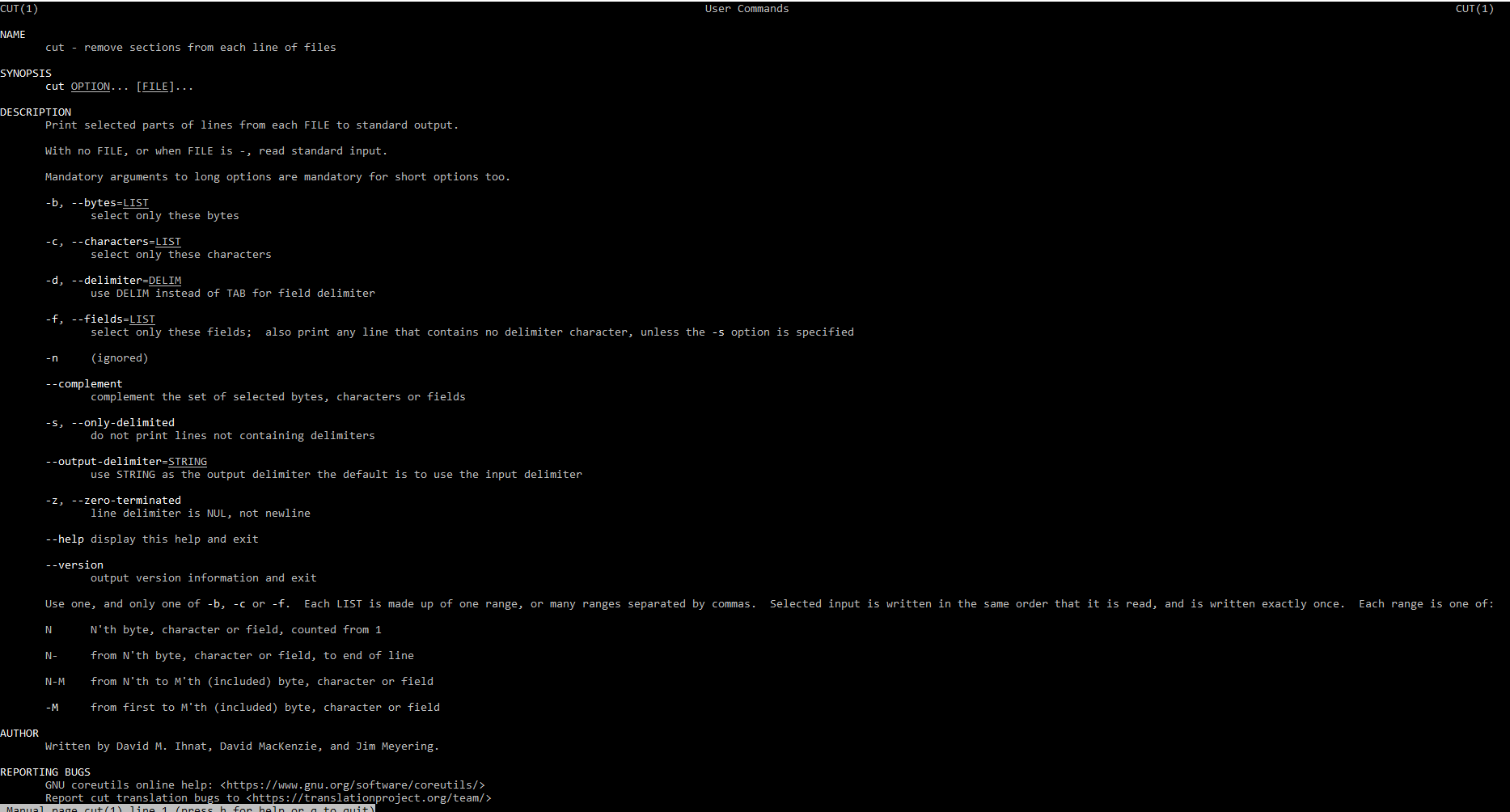
Данная команда предназначена для удаления секций из строчек файлов. Если посмотреть на ключи, то мы можем увидеть, что данная команда может удалять по различным признакам. По полям, по символам, по байтам, это интересная команда, которая позволяет нам вырезать части из файлов. Небольшой пример:
Данной командой мы говорим, что при выводе на экран нам необходимо «вырезать» перечисленные символы и вывести оставшееся на экран. Замечу, что команда cut не является текстовым редактором и поэтому фалы не правит! А только правит вывод в консоль. Если посмотреть командой cat hello1.txt файл остался неизменным.

Все команды, про которые речь в статье не редактируют исходные файлы, они только фильтруют или редактируют стандартный вывод информации. Для редактирования файлов используются текстовые редакторы.
Мы посмотрели, как данная команда редактирует вывод, на практике мы можем редактировать колонки, столбцы, вывода в каком-то конкретном логе или таблице. Т.е. мы можем выводить на экран только то, что нам нужно. Например, у нас есть лог события, какого-то, мы можем вывести только дату и события, остальное все лишнее отрезать данной командой в выводе.
Команда expand

Данная команда редко используется. Она необходима для конвертации символов табуляции в пробелы. Пример: expand hello2.txt и все табуляции превратились в пробелы. На практики редко применяемая команда.
Команда fmt
Как написано в мануале это текст форматер. Это серьезная команда, она умеет форматировать вывод текста различными способами.

Теперь посмотрим, как данной командой пользоваться.
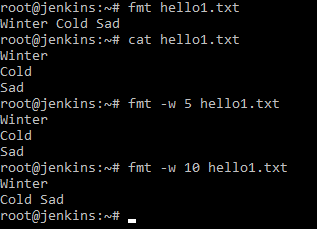
Например, написать fmt hello1.txt , как вы видите команда сделала вывод в одну строчку. Следовательно, команда без указания ключа, команда игнорирует все символы переноса каретки.
Т.е. все «enter» и перехода на новую строку он убрал.
Мы можем сказать, чтобы команда отформатировала текст так. чтобы на одной строке не было не более 5 символов, но это без переносов, если первое слово на 20 символов он его не перенесет, а если 2 слова по 2 символа, то оба оставит на этой строке.
Ничего не произошло, а если мы дадим fmt w 10 hello1.txt , то мы видим, что команда осуществила перенос. Таким образом можно просматривать длинные логи в удобном для нас виде, т. к. лог может уходить очень далеко в сторону, а через данную команду мы можем разбить на удобные абзацы для нас.
Команда head
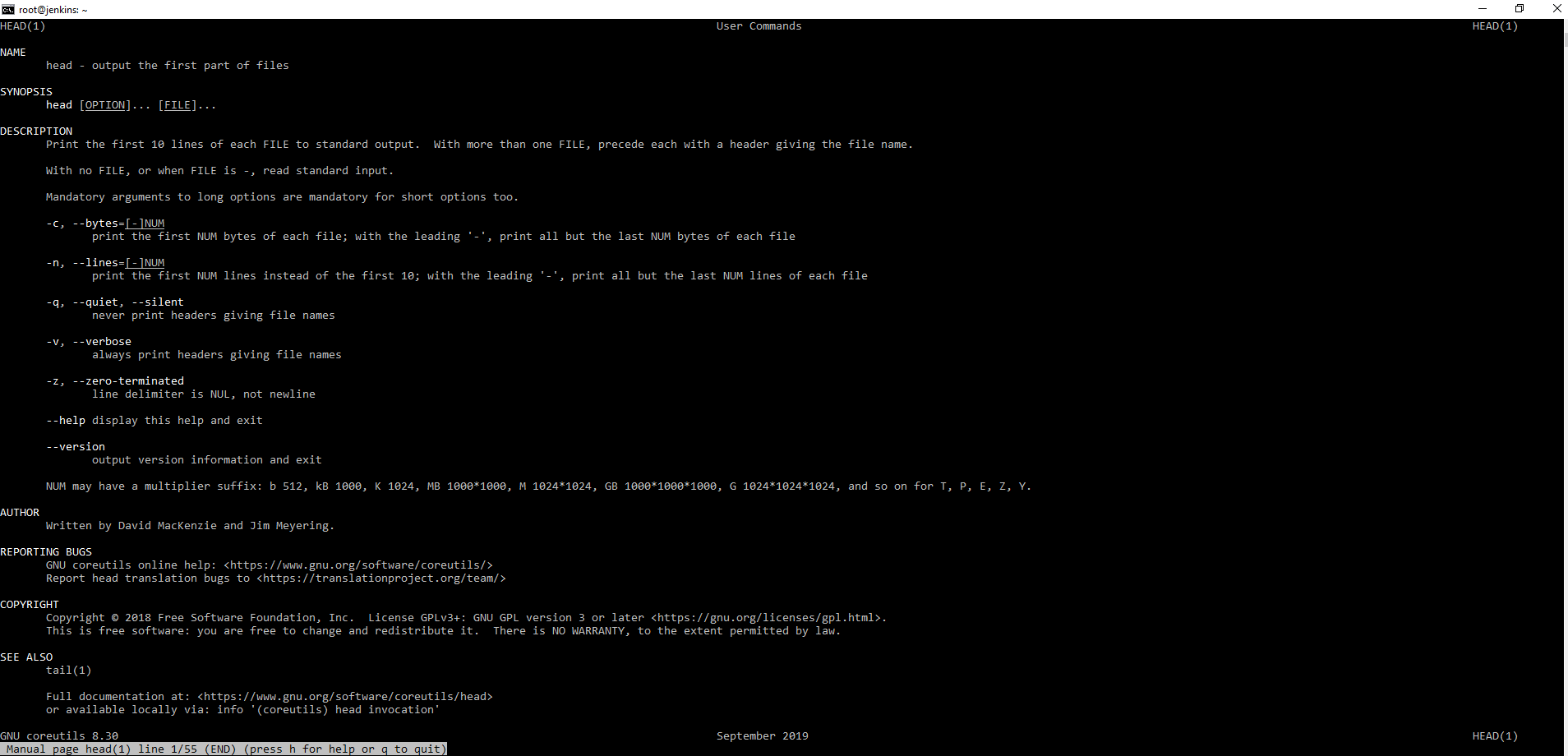
Показывает первую часть файлов. Очень удобная команда, для просмотра того, что было в начале файла. По умолчанию показывает первые 10 строк файла.
Для изменения, количества выводимых строк необходимо использовать ключ n и за ним указать необходимое количество строк.
Команда od
Превращает файлы в другие форматы. Грубо говоря это программа конвертор. Редко используется на практике.
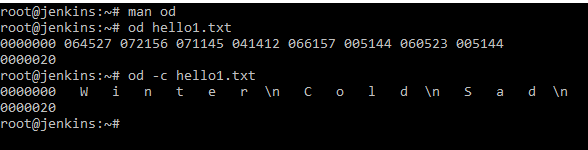
Используя данную команду по умолчанию, мы можем превратить файл в восьмеричный код od hello1.txt . Или с использованием ключа c превратить в формат ASCII, od c hello1.txt . это может понадобится для конвертации файла, например для другой машины со специфичным форматом данных.
Команда join
Данная команда, объединяет строчки файлов по общему полю. Для того, чтобы понять, как работает данная команда необходимо создать 2 текстовых файла touch <1,2>.txt . Создаем сразу 2 файла 1.txt и 2.txt. И с помощью редактора nano редактируем. При применении команды join мы видим произошло объединение по полю нумерации.
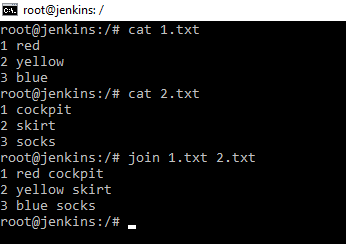
Это удобно, например, для слияния файлов, особенно логов, например, два файла логов и вам необходимо их сопоставить по времени.
Команда less

В описании команды говорится, что эта команда противоположна команде more. По сути это команда, которая позволяет читать файл.
Можно посмотреть работу ее на примере. Например, cat /var/log/syslog при запуске этой, команды мы получим очень большой вывод на несколько экранов. Если мы воспользуемся командой less /var/log/syslog , то вывод даст возможность листать постранично, через pgdn. Согласитесь, это намного упрощает чтение и просмотр файла. Бывает такое, что работа идет в консоли, в которой нету прокрутки, через мышку, то в таком случае данная команда становится вообще не заменимой. Если посмотреть описание, данная команда еще умеет делать небольшой поиск по файлу.
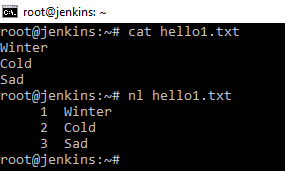
Команда nl

Нумерация строк. Простой пример. Берем файл и говорим пронумеровать строки. На картинке наглядно показано, как работает команда.
Команда paste
Команда вставка умеет вставлять построчно вставлять какие-то строки в файлы. Объединяет строки файлов, как написано в мануале.
У нас есть 2 файла 1.txt и 2.txt. Команда join их объединяла по определенному полю. Если мы применим команду paste мы увидим, что команда paste объединила их построчно.
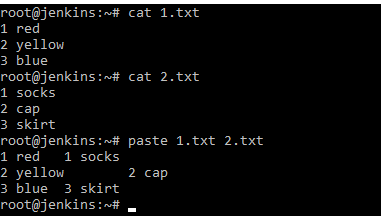
Т.е. это может быть очень удобно. У нас объединились первые строки, вторые строки и т.д. Например, если мы сопоставляем какие-нибудь события или файлы и т.д.
Команда pr

Данная команда конвертирует текстовые файлы для вывода на печать. Очень наглядно можно увидеть, как работает данная команда, если ее применить к большому файлу. Например, pr /var/log/syslog
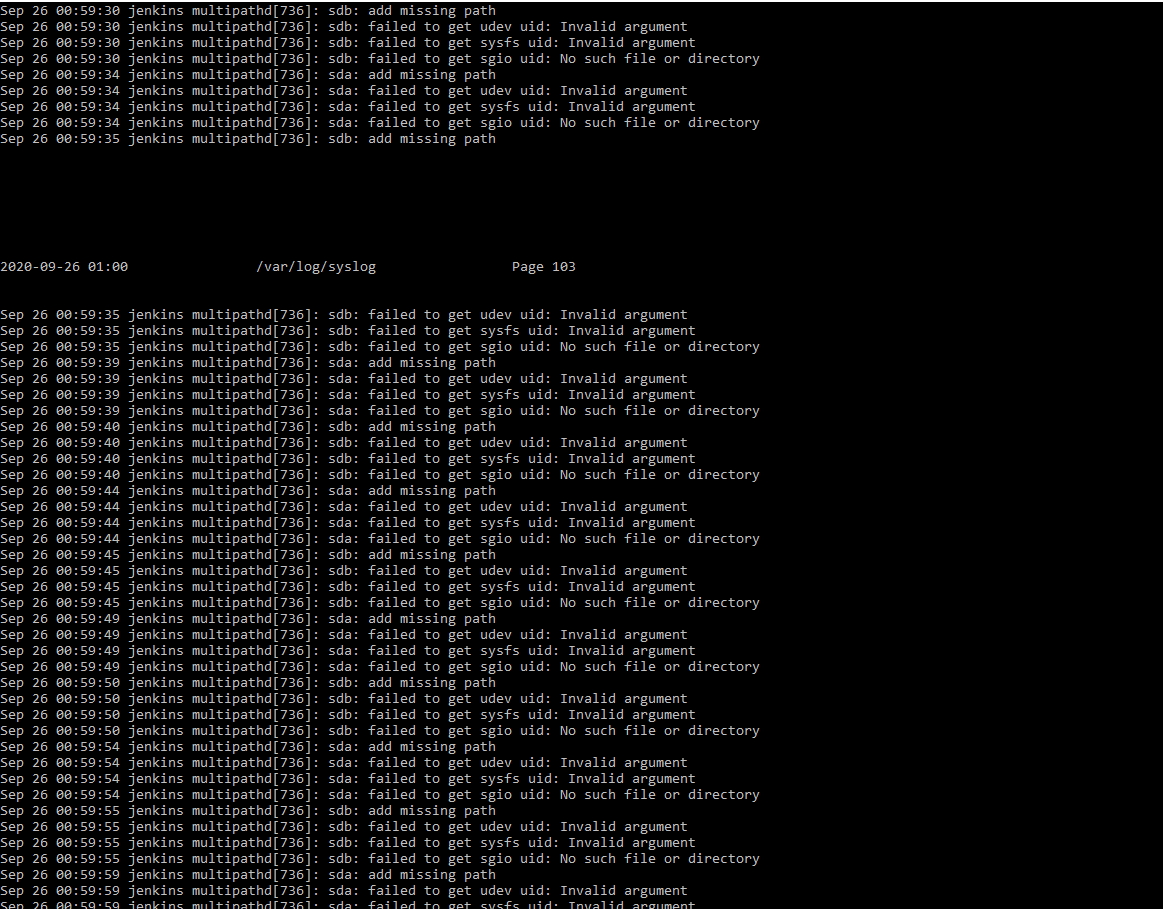
Как можно убедится, команда разбила вывод на страницы и подготовила данный вывод для печати.
Команда sed
Потоковый редактор для фильтрации и трансформирования текста. Это практически полноценный текстовый редактор, но опять же он не редактирует файлы, а работает с выводом.
Как его использовать, пример следующий заменим в файле 2.txt слово socks на слово people получается примерно так:

Функционал у команды очень большой, вывод можно для себя очень сильно изменить, заменить слова, удалить, отредактировать, отрезать, добавить, все это можно делать с помощью данной команды. При этом содержимое файла не меняется. Меняется только для нас вывод.
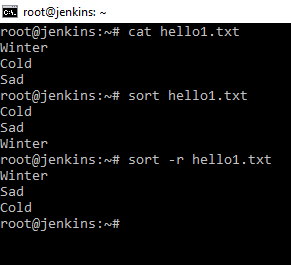
Команда sort
Сортирует строки в файлах по какому-то признаку. Поработаем с файлом hello1.txt. Если мы применим команду к данному файлу sort hello1.txt, то мы увидим, что вывод отсортировал строчки по алфавиту. А если применить ключик r, то от сортируется в обратном порядке. Это удобно использовать так же в совокупности с другими командами, отсортировать лишнее.
Команда split
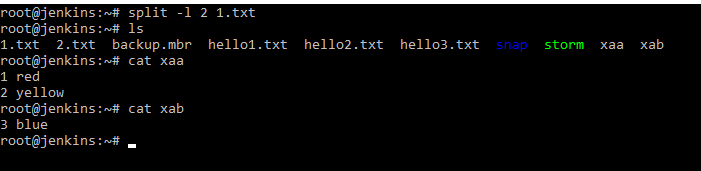
Данная команда бьет файл на куски. Даная команда работает следующим образом. Даная команда разбивает файл на части, но при этом исходный не меняет. Например разобьем по строчкам фал 1.txt. split -l 2 1.txt . Разбивку делаем на 2 строчки. И мы видим, что у нас исходный файл остался неизменным, а появилось еще 2 файла xaa и xab. Они как раз и содержат разбиение.
Данную команду удобно применять к большим файлам и использовать ключик для разбивки по размеру, например, по байтам b и указываем на какие куски разбить в байтах. Пример:
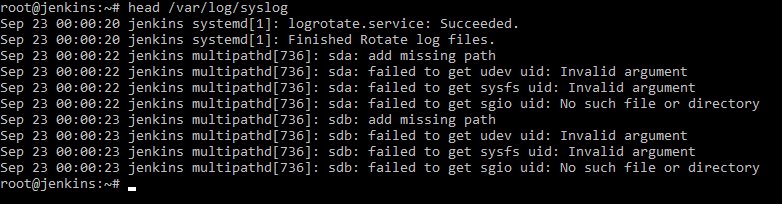
Команда tail
В отличии от команды head, данная команда показывает последнюю часть файла. Например, tail /var/log/syslog нам покажет последнюю часть лога событий.
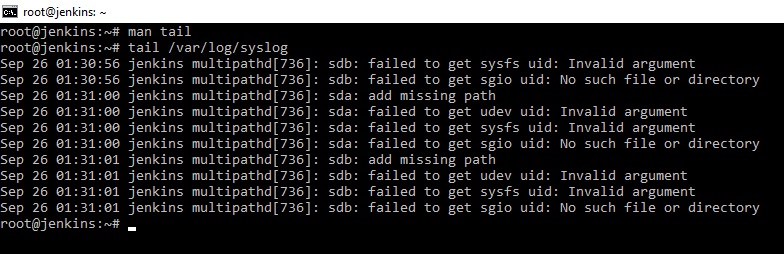
Добавляем ключ -n и число, мы получим число последних событий, которых мы указали. Очень полезный ключ -f, который говорит показывать добавление в файл на «живую», т.е в реальном времени. Очень удобно для диагностики, события пишутся в лог и сразу выводится на экран. Например, запись лога прокси сервера. Прерывание такого режима ctr+C.
Команда tr
Переводит или удаляет символы. Посмотрим на прямом выводе текста. Введем echo Hello. Далее введем echo Hello | tr -t A-Z a-z и заглавные буквы будут заменены строчными. Echo Hello | tr -t l L и маленькие l будет заменены на L. Echo Hello | tr -d l и буквы l будут удалены.
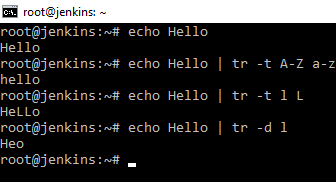
Мощный трансформатор текста. Работает непосредственно с текстом, ключей у него полно их можно посмотреть в мануале.
Команда unexpand
Работает в противоположную сторону команде expand. Конвертирует пробелы в знаки табуляции.
Обычно работают в паре expand и unexpand, для раздвижения столбцов.
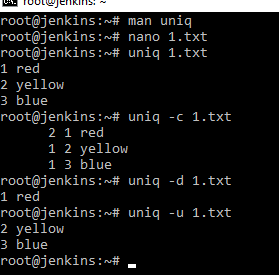
Команда uniq
Даная команда ищет уникальные и дублирующийся линии, т.е. она смотрит что у нас в строчках есть одинакового и разного. Для примера, я в файл 1.txt добавлю повторяющуюся строчку. И сделаю вывод uniq 1.txt команда покажет только уникальные строчки, а затем uniq c 1.txt и команда покажет строчки с числом повторений. Можно сказать, чтобы показала команда только дублирующиеся строчки uniq d 1.txt или неповторяющиеся uniq u 1.txt. Применение заключается в том. что если у нас есть файлы с повторяющееся информацией мы можем таким образом ее фильтровать.
Команда wc

Показывает число строк, байт, слов и т.д. для определенного файла. Например: wc 1.txt показывает 4 строки, 8 слов, 28 символов.
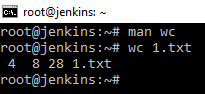
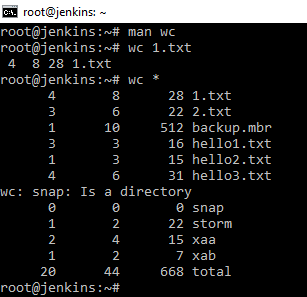
Можно использовать с ключом w покажет количество слов. И т.д., можно получить информацию полностью по папке:
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник



