- Linux Network Statistics Tools / Commands
- nstat command : Network Statistics Tool
- ss command : Utility To Investigate Sockets
- netstat command : The Old Good Utility To Show Sockets
- ip / ifconfig command : Configure or Show a Network Interface Info
- sar command: Display Network Stats
- Interface statistics¶
- Overview¶
- Standard interface statistics¶
- Protocol-specific statistics¶
- ethtool¶
- Driver-defined statistics¶
- uAPIs¶
- procfs¶
- sysfs¶
- netlink¶
- ethtool¶
- ethtool-netlink¶
- debugfs¶
- struct rtnl_link_stats64В¶
- Notes for driver authors¶
- Kernel-internal data structures¶
- 18 Commands to Monitor Network Bandwidth on Linux server
- Network monitoring on Linux
- 1. Nload
- 2. iftop
- 3. iptraf
- 4. nethogs
- 5. bmon
- 6. slurm
- 7. tcptrack
- 8. Vnstat
- 9. bwm-ng
- 10. cbm — Color Bandwidth Meter
- 11. speedometer
- 12. Pktstat
- 13. Netwatch
- 14. Trafshow
- 15. Netload
- 16. ifstat
- 17. dstat
- 18. collectl
- Summary
- 88 thoughts on “ 18 Commands to Monitor Network Bandwidth on Linux server ”
Linux Network Statistics Tools / Commands
H ow do I find out the current network interface throughput statistics on Linux (CentOS or Debian based distro)? How do I see current kernel snmp counters and network interface statistics on Linux operating systems?
| Tutorial details | |
|---|---|
| Difficulty level | Easy |
| Root privileges | No |
| Requirements | None |
| Est. reading time | N/A |
You can use any one of the following commands:
nstat command : Network Statistics Tool
Type the following command:
# nstat
Sample outputs:
ss command : Utility To Investigate Sockets
To see summary of stats, enter:
# ss -s
Sample outputs:
See ss command tutorial for more information.
netstat command : The Old Good Utility To Show Sockets
To see a table of all network interfaces and its summary, enter:
# netstat -i
Sample outputs:
- No ads and tracking
- In-depth guides for developers and sysadmins at Opensourceflare✨
- Join my Patreon to support independent content creators and start reading latest guides:
- How to set up Redis sentinel cluster on Ubuntu or Debian Linux
- How To Set Up SSH Keys With YubiKey as two-factor authentication (U2F/FIDO2)
- How to set up Mariadb Galera cluster on Ubuntu or Debian Linux
- A podman tutorial for beginners – part I (run Linux containers without Docker and in daemonless mode)
- How to protect Linux against rogue USB devices using USBGuard
Join Patreon ➔
To see summary statistics for each protocol, enter:
# netstat -s
Sample outputs:
ip / ifconfig command : Configure or Show a Network Interface Info
Type the following command:
# ifconfig
OR
# /sbin/ifconfig
OR
# ifconfig eth0
To display network interface statistics, enter:
# ip -s link
Sample outputs:
sar command: Display Network Stats
Type the following command (you need to install and enable sar via sysstat package):
sar -n DEV
Or type the following command:
# sar -n DEV 1 3
Sample outputs:
🐧 Get the latest tutorials on Linux, Open Source & DevOps via
Источник
Interface statistics¶
Overview¶
This document is a guide to Linux network interface statistics.
There are three main sources of interface statistics in Linux:
standard interface statistics based on struct rtnl_link_stats64 ;
protocol-specific statistics; and
driver-defined statistics available via ethtool.
Standard interface statistics¶
There are multiple interfaces to reach the standard statistics. Most commonly used is the ip command from iproute2 :
Note that -s has been specified twice to see all members of struct rtnl_link_stats64 . If -s is specified once the detailed errors won’t be shown.
ip supports JSON formatting via the -j option.
Protocol-specific statistics¶
Protocol-specific statistics are exposed via relevant interfaces, the same interfaces as are used to configure them.
ethtool¶
Ethtool exposes common low-level statistics. All the standard statistics are expected to be maintained by the device, not the driver (as opposed to driver-defined stats described in the next section which mix software and hardware stats). For devices which contain unmanaged switches (e.g. legacy SR-IOV or multi-host NICs) the events counted may not pertain exclusively to the packets destined to the local host interface. In other words the events may be counted at the network port (MAC/PHY blocks) without separation for different host side (PCIe) devices. Such ambiguity must not be present when internal switch is managed by Linux (so called switchdev mode for NICs).
Standard ethtool statistics can be accessed via the interfaces used for configuration. For example ethtool interface used to configure pause frames can report corresponding hardware counters:
General Ethernet statistics not associated with any particular functionality are exposed via ethtool -S $ifc by specifying the —groups parameter:
Driver-defined statistics¶
Driver-defined ethtool statistics can be dumped using ethtool -S $ifc , e.g.:
uAPIs¶
procfs¶
The historical /proc/net/dev text interface gives access to the list of interfaces as well as their statistics.
Note that even though this interface is using struct rtnl_link_stats64 internally it combines some of the fields.
sysfs¶
Each device directory in sysfs contains a statistics directory (e.g. /sys/class/net/lo/statistics/ ) with files corresponding to members of struct rtnl_link_stats64 .
This simple interface is convenient especially in constrained/embedded environments without access to tools. However, it’s inefficient when reading multiple stats as it internally performs a full dump of struct rtnl_link_stats64 and reports only the stat corresponding to the accessed file.
Sysfs files are documented in Documentation/ABI/testing/sysfs-class-net-statistics .
netlink¶
rtnetlink ( NETLINK_ROUTE ) is the preferred method of accessing struct rtnl_link_stats64 stats.
Statistics are reported both in the responses to link information requests ( RTM_GETLINK ) and statistic requests ( RTM_GETSTATS , when IFLA_STATS_LINK_64 bit is set in the .filter_mask of the request).
ethtool¶
Ethtool IOCTL interface allows drivers to report implementation specific statistics. Historically it has also been used to report statistics for which other APIs did not exist, like per-device-queue statistics, or standard-based statistics (e.g. RFC 2863).
Statistics and their string identifiers are retrieved separately. Identifiers via ETHTOOL_GSTRINGS with string_set set to ETH_SS_STATS , and values via ETHTOOL_GSTATS . User space should use ETHTOOL_GDRVINFO to retrieve the number of statistics ( .n_stats ).
ethtool-netlink¶
Ethtool netlink is a replacement for the older IOCTL interface.
Protocol-related statistics can be requested in get commands by setting the ETHTOOL_FLAG_STATS flag in ETHTOOL_A_HEADER_FLAGS . Currently statistics are supported in the following commands:
debugfs¶
Some drivers expose extra statistics via debugfs .
struct rtnl_link_stats64В¶
The main device statistics structure.
Definition
Members
Number of good packets received by the interface. For hardware interfaces counts all good packets received from the device by the host, including packets which host had to drop at various stages of processing (even in the driver).
Number of packets successfully transmitted. For hardware interfaces counts packets which host was able to successfully hand over to the device, which does not necessarily mean that packets had been successfully transmitted out of the device, only that device acknowledged it copied them out of host memory.
Number of good received bytes, corresponding to rx_packets.
For IEEE 802.3 devices should count the length of Ethernet Frames excluding the FCS.
Number of good transmitted bytes, corresponding to tx_packets.
For IEEE 802.3 devices should count the length of Ethernet Frames excluding the FCS.
Total number of bad packets received on this network device. This counter must include events counted by rx_length_errors, rx_crc_errors, rx_frame_errors and other errors not otherwise counted.
Total number of transmit problems. This counter must include events counter by tx_aborted_errors, tx_carrier_errors, tx_fifo_errors, tx_heartbeat_errors, tx_window_errors and other errors not otherwise counted.
Number of packets received but not processed, e.g. due to lack of resources or unsupported protocol. For hardware interfaces this counter may include packets discarded due to L2 address filtering but should not include packets dropped by the device due to buffer exhaustion which are counted separately in rx_missed_errors (since procfs folds those two counters together).
Number of packets dropped on their way to transmission, e.g. due to lack of resources.
Multicast packets received. For hardware interfaces this statistic is commonly calculated at the device level (unlike rx_packets) and therefore may include packets which did not reach the host.
For IEEE 802.3 devices this counter may be equivalent to:
Number of collisions during packet transmissions.
Number of packets dropped due to invalid length. Part of aggregate “frame” errors in /proc/net/dev .
For IEEE 802.3 devices this counter should be equivalent to a sum of the following attributes:
Receiver FIFO overflow event counter.
Historically the count of overflow events. Such events may be reported in the receive descriptors or via interrupts, and may not correspond one-to-one with dropped packets.
The recommended interpretation for high speed interfaces is — number of packets dropped because they did not fit into buffers provided by the host, e.g. packets larger than MTU or next buffer in the ring was not available for a scatter transfer.
Part of aggregate “frame” errors in /proc/net/dev .
This statistics was historically used interchangeably with rx_fifo_errors.
This statistic corresponds to hardware events and is not commonly used on software devices.
Number of packets received with a CRC error. Part of aggregate “frame” errors in /proc/net/dev .
For IEEE 802.3 devices this counter must be equivalent to:
Receiver frame alignment errors. Part of aggregate “frame” errors in /proc/net/dev .
For IEEE 802.3 devices this counter should be equivalent to:
Receiver FIFO error counter.
Historically the count of overflow events. Those events may be reported in the receive descriptors or via interrupts, and may not correspond one-to-one with dropped packets.
This statistics was used interchangeably with rx_over_errors. Not recommended for use in drivers for high speed interfaces.
This statistic is used on software devices, e.g. to count software packet queue overflow (can) or sequencing errors (GRE).
Count of packets missed by the host. Folded into the “drop” counter in /proc/net/dev .
Counts number of packets dropped by the device due to lack of buffer space. This usually indicates that the host interface is slower than the network interface, or host is not keeping up with the receive packet rate.
This statistic corresponds to hardware events and is not used on software devices.
Part of aggregate “carrier” errors in /proc/net/dev . For IEEE 802.3 devices capable of half-duplex operation this counter must be equivalent to:
High speed interfaces may use this counter as a general device discard counter.
Number of frame transmission errors due to loss of carrier during transmission. Part of aggregate “carrier” errors in /proc/net/dev .
For IEEE 802.3 devices this counter must be equivalent to:
Number of frame transmission errors due to device FIFO underrun / underflow. This condition occurs when the device begins transmission of a frame but is unable to deliver the entire frame to the transmitter in time for transmission. Part of aggregate “carrier” errors in /proc/net/dev .
Number of Heartbeat / SQE Test errors for old half-duplex Ethernet. Part of aggregate “carrier” errors in /proc/net/dev .
For IEEE 802.3 devices possibly equivalent to:
Number of frame transmission errors due to late collisions (for Ethernet — after the first 64B of transmission). Part of aggregate “carrier” errors in /proc/net/dev .
For IEEE 802.3 devices this counter must be equivalent to:
Number of correctly received compressed packets. This counters is only meaningful for interfaces which support packet compression (e.g. CSLIP, PPP).
Number of transmitted compressed packets. This counters is only meaningful for interfaces which support packet compression (e.g. CSLIP, PPP).
Number of packets received on the interface but dropped by the networking stack because the device is not designated to receive packets (e.g. backup link in a bond).
Notes for driver authors¶
Drivers should report all statistics which have a matching member in struct rtnl_link_stats64 exclusively via .ndo_get_stats64 . Reporting such standard stats via ethtool or debugfs will not be accepted.
Drivers must ensure best possible compliance with struct rtnl_link_stats64 . Please note for example that detailed error statistics must be added into the general rx_error / tx_error counters.
The .ndo_get_stats64 callback can not sleep because of accesses via /proc/net/dev . If driver may sleep when retrieving the statistics from the device it should do so periodically asynchronously and only return a recent copy from .ndo_get_stats64 . Ethtool interrupt coalescing interface allows setting the frequency of refreshing statistics, if needed.
Retrieving ethtool statistics is a multi-syscall process, drivers are advised to keep the number of statistics constant to avoid race conditions with user space trying to read them.
Statistics must persist across routine operations like bringing the interface down and up.
Kernel-internal data structures¶
The following structures are internal to the kernel, their members are translated to netlink attributes when dumped. Drivers must not overwrite the statistics they don’t report with 0.
Источник
18 Commands to Monitor Network Bandwidth on Linux server
Network monitoring on Linux
This post mentions some linux command line tools that can be used to monitor the network usage.
These tools monitor the traffic flowing through network interfaces and measure the speed at which data is currently being transferred. Incoming and outgoing traffic is shown separately.
Some of the commands, show the bandwidth used by individual processes. This makes it easy to detect a process that is overusing network bandwidth.
The tools have different mechanisms of generating the traffic report.
Some of the tools like nload read the «/proc/net/dev» file to get traffic stats, whereas some tools use the pcap library to capture all packets and then calculate the total size to estimate the traffic load.
Here is a list of the commands, sorted by their features.
Now lets take a look at each of the commands and how to use them to monitor network usage:
1. Nload
Nload is a commandline tool that allows users to monitor the incoming and outgoing traffic separately.
It also draws out a graph to indicate the same, the scale of which can be adjusted. Easy and simple to use, and does not support many options.
So if you just need to take a quick look at the total bandwidth usage without details of individual processes, then nload will be handy.
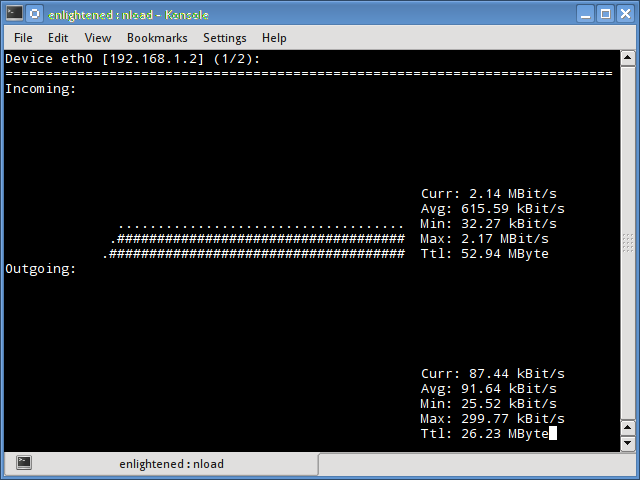
Installing Nload — Fedora and Ubuntu have got it in the default repos. CentOS users need to get nload from Epel repositories.
2. iftop
Iftop measures the data flowing through individual socket connections, and it works in a manner that is different from Nload.
Iftop uses the pcap library to capture the packets moving in and out of the network adapter, and then sums up the size and count to find the total bandwidth under use.
Although iftop reports the bandwidth used by individual connections, it cannot report the process name/id involved in the particular socket connection.
But being based on the pcap library, iftop is able to filter the traffic and report bandwidth usage over selected host connections as specified by the filter.
The n option prevents iftop from resolving ip addresses to hostname, which causes additional network traffic of its own.
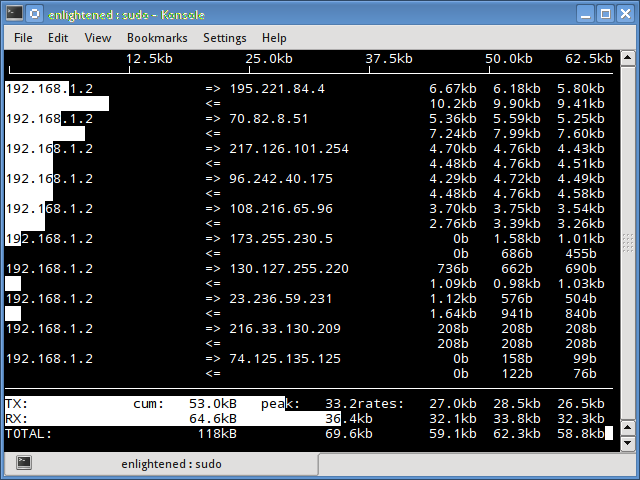
Install iftop — Ubuntu/Debian/Fedora users get it from default repos. CentOS users get it from Epel.
3. iptraf
Iptraf is an interactive and colorful IP Lan monitor. It shows individual connections and the amount of data flowing between the hosts. Here is a screenshot
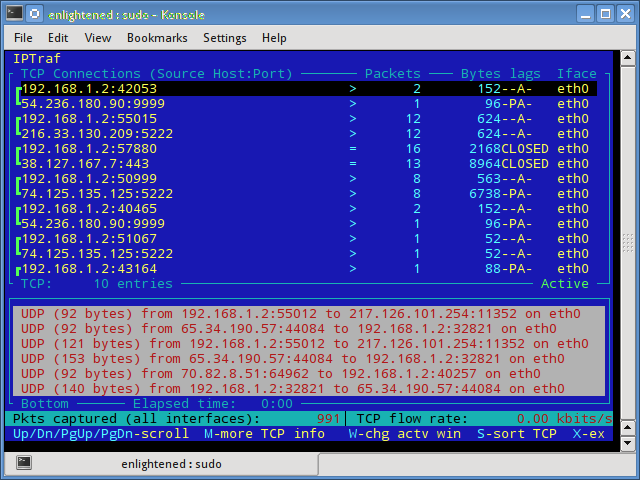
4. nethogs
Nethogs is a small ‘net top’ tool that shows the bandwidth used by individual processes and sorts the list putting the most intensive processes on top.
In the event of a sudden bandwidth spike, quickly open nethogs and find the process responsible. Nethogs reports the PID, user and the path of the program.
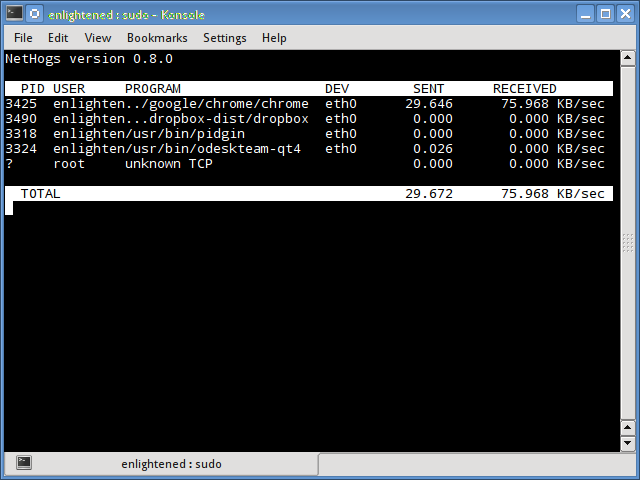
Install Nethogs — Ubuntu, Debian, Fedora users get from default repos. CentOS users need Epel
5. bmon
Bmon (Bandwidth Monitor) is a tool similar to nload that shows the traffic load over all the network interfaces on the system. The output also consists of a graph and a section with packet level details.
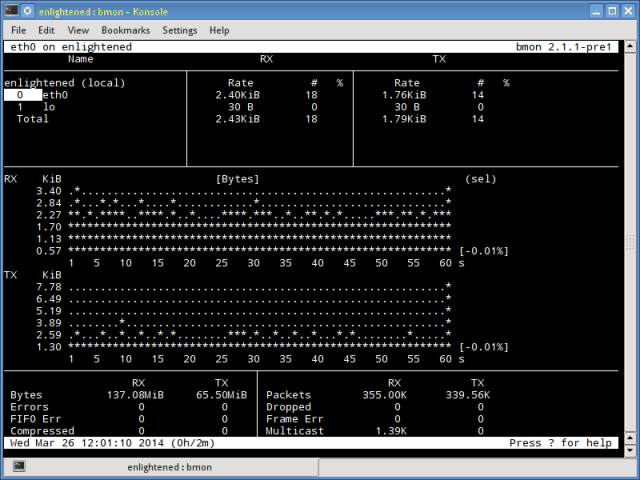
Install Bmon — Ubuntu, Debian and Fedora users can install from default repos. CentOS users need to setup repoforge, since its not available in Epel.
Bmon supports many options and is capable of producing reports in html format. Check the man page for more information
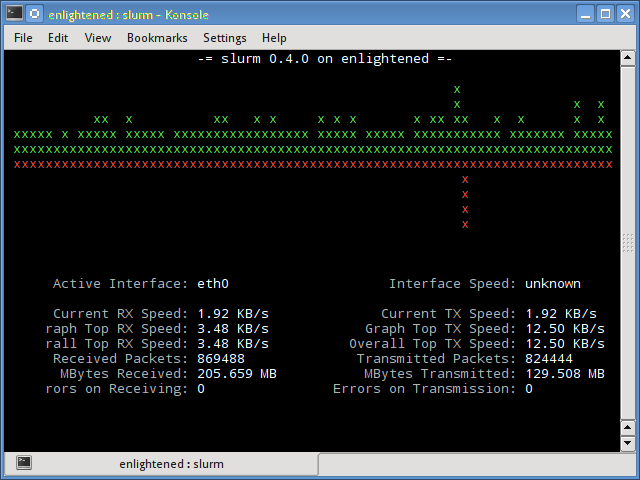
6. slurm
Slurm is ‘yet’ another network load monitor that shows device statistics along with an ascii graph. It supports 3 different styles of graphs each of which can be activated using the c, s and l keys. Simple in features, slurm does not display any further details about the network load.
7. tcptrack
Tcptrack is similar to iftop, and uses the pcap library to capture packets and calculate various statistics like the bandwidth used in each connection.
It also supports the standard pcap filters that can be used to monitor specific connections.
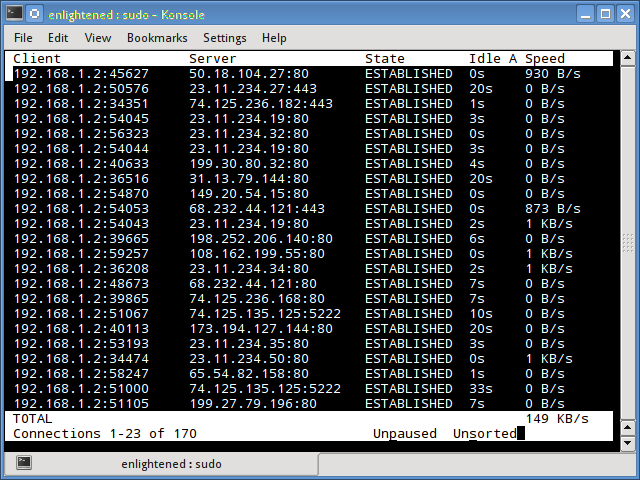
Install tcptrack — Ubuntu, Debian and Fedora have it in default repos. CentOS users need to get it from RepoForge as it is not available in Epel either.
8. Vnstat
Vnstat is bit different from most of the other tools. It actually runs a background service/daemon and keeps recording the size of data transfer all the time.
Next it can be used to generate a report of the history of network usage.
Running vnstat without any options would simply show the total amount of data transfer that took place since the date the daemon is running.
To monitor the bandwidth usage in realtime, use the ‘-l’ option (live mode). It would then show the total bandwidth used by incoming and outgoing data, but in a very precise manner without any internal details about host connections or processes.
Vnstat is more like a tool to get historic reports of how much bandwidth is used everyday or over the past month. It is not strictly a tool for monitoring the network in real time.
Vnstat supports many options, details about which can be found in the man page.
9. bwm-ng
Bwm-ng (Bandwidth Monitor Next Generation) is another very simple real time network load monitor that reports a summary of the speed at which data is being transferred in and out of all available network interfaces on the system.
If the console size is sufficiently large, bwm-ng can also draw bar graphs for the traffic using the curses2 output mode.
Install Bwm-NG — On CentOS bwm-ng can be installed from Epel.
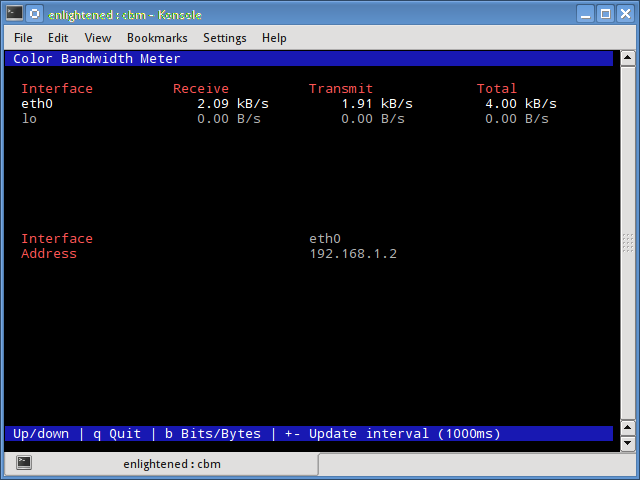
10. cbm — Color Bandwidth Meter
A tiny little simple bandwidth monitor that displays the traffic volume through network interfaces. No further options, just the traffic stats are display and updated in realtime.
11. speedometer
Another small and simple tool that just draws out good looking graphs of incoming and outgoing traffic through a given interface.
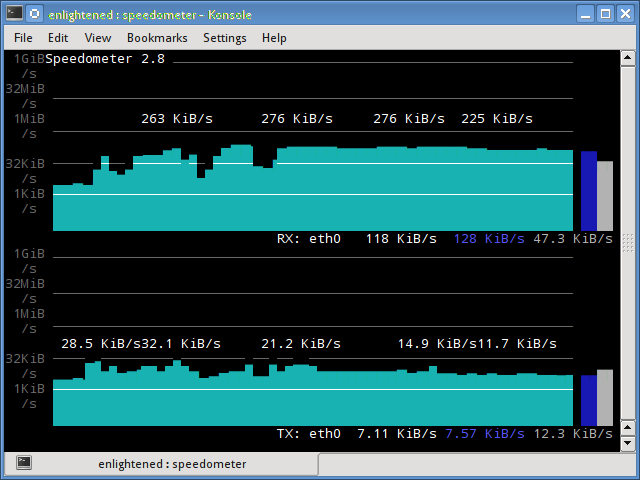
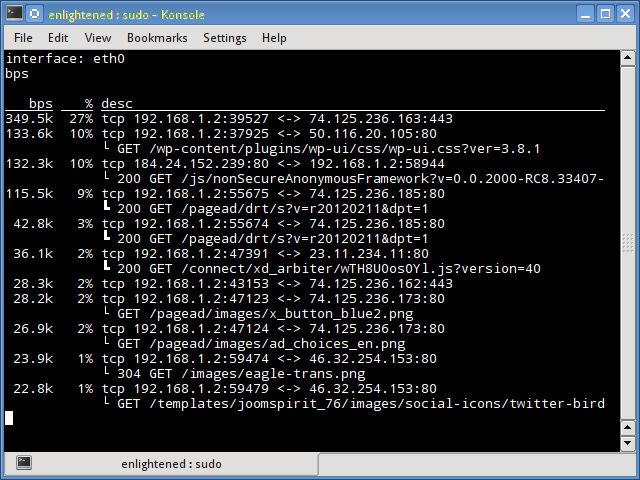
12. Pktstat
Pktstat displays all the active connections in real time, and the speed at which data is being transferred through them.
It also displays the type of the connection, i.e. tcp or udp and also details about http requests if involved.
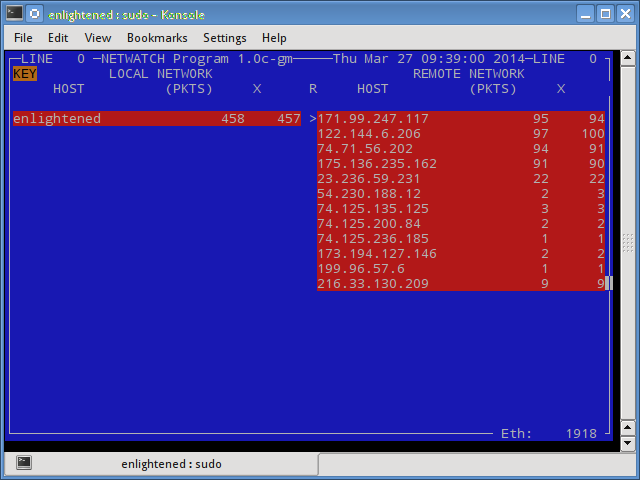
13. Netwatch
Netwatch is part of the netdiag collection of tools, and it too displays the connections between local host and other remote hosts, and the speed at which data is transferring on each connection.
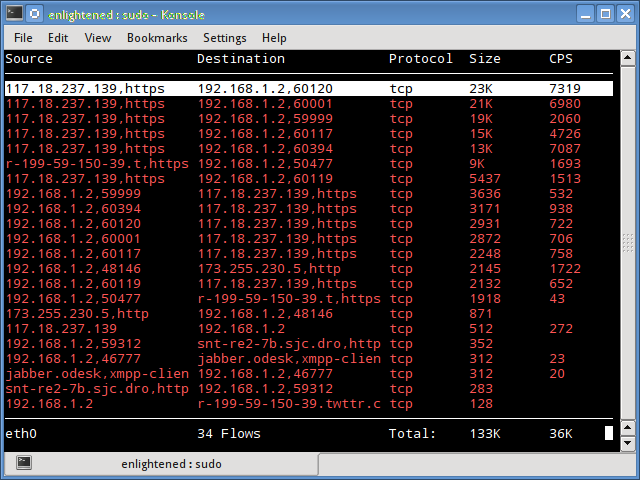
14. Trafshow
Like netwatch and pktstat, trafshow reports the current active connections, their protocol and the data transfer speed on each connection. It can filter out connections using pcap type filters.
Monitor only tcp connections
15. Netload
The netload command just displays a small report on the current traffic load, and the total number of bytes transferred since the program start. No more features are there. Its part of the netdiag.
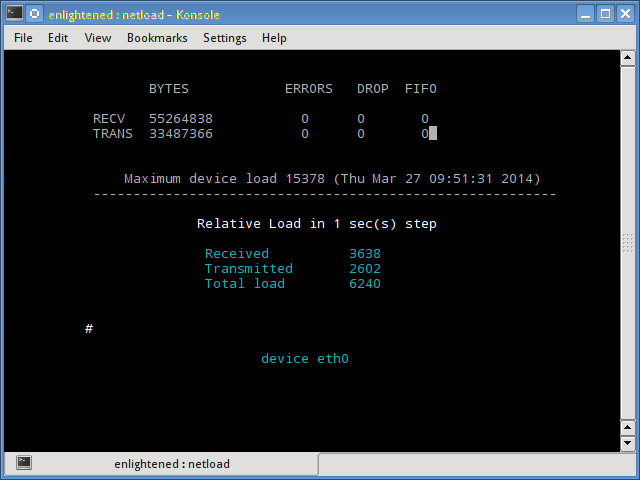
16. ifstat
The ifstat reports the network bandwidth in a batch style mode. The output is in a format that is easy to log and parse using other programs or utilities.
Install ifstat — Ubuntu, Debian and Fedora users have it in the default repos. CentOS users need to get it from Repoforge, since its not there in Epel.
17. dstat
Dstat is a versatile tool (written in python) that can monitor different system statistics and report them in a batch style mode or log the data to a csv or similar file. This example shows how to use dstat to report network bandwidth
18. collectl
Collectl reports system statistics in a style that is similar to dstat, and like dstat it is gathers statistics about various different system resources like cpu, memory, network etc.
Over here is a simple example of how to use it to report network usage/bandwidth.
Summary
Those were a few handy commands to quickly check the network bandwidth on your linux server. However these need the user to login to the remote server over ssh.
Alternatively web based monitoring tools can also be used for the same task.
Ntop and Darkstat are some of the basic web based network monitoring tools available for Linux.
Beyond these lie the enterprise level monitoring tools like Nagios that provide a host of features to not just monitor a server but entire infrastructure.
A Tech Enthusiast, Blogger, Linux Fan and a Software Developer. Writes about Computer hardware, Linux and Open Source software and coding in Python, Php and Javascript. He can be reached at [email protected] .
88 thoughts on “ 18 Commands to Monitor Network Bandwidth on Linux server ”
Amazing Article, Really useful information to all So, I hope you will share more information to be check and share here.thanks for sharing.
Thanks for sharing this amazing informative article. this is best for cs students mainly linux student to know about these commands.
Wow, so much loads of usefulness! Thank you for this! Lots of tools I never heard and surprise they are there by default on reposity, just apt install away!!
Based on nethogs, there’s a Qt software providing charts per application:
https://slist.lilotux.net/linux/nethogs-qt/index_en.html
thanks for mentioning.
Very informative and useful article. We can see all the commands at one shot.
Thanks for sharing
it is really a great article and helping to learn about Linux network.
Keep sharing such great knowledge
These are perfect 100% working commands. That is quite amazing. Thanks for such a useful article…
Great article.It’s a big collection for monitor, is any app can track daily bandwidth ?
Thanks! Nethogs is perfect for me as it shows usage per process: current bandwith and total used, great!
Thanks, it is saving a lot of time
Very informative and useful article.
Thanks for sharing
that was really useful
thanks
Thanks for sharing informative article I have been looking for these command with step by step guide you did a great job and i found a solution that I am looking for keep up the good work.
You are right.
Actually i was too looking about this commands.
At least i found these all here.
Thanks.
This commands its very helpful for me i want to i want to know how to create a server 2012 r2 in home
20+ year vet here. pure gold .. many of these are new to me.
excellent article
glad that you liked it.
thanks for the comment.
Very good and useful compilation.
Good job and thanks!!
Now an article about _graphical_ monitor network applications would be even better 🙂
This a gem for commands.
Thanks 🙂
Thank you for this article, I didn’t know about these tools.
Thank you, very good article, a treasure trove 🙂
In our company we are several clients which are connected to an Ubuntu Server. Sometimes there is problem in entire network of company and we have heavy load on server. We try to find which client causes this problem.
As part of solution should be monitored entire network 24 hour per day? And if yes, which network monitoring tool helps us to find bad client and how to log it to analyze later?
How can we get complete status of each client and its transaction with our server? For example, a client named A have connection with server, how can we see how many bandwidths is used by this client?
Use a proper router like opnsense. It can monitor per host traffic and even put quotas on certain hosts or otherwise profile them to use less bandwidth.
Thank you. We can see all the commands at one shot.
Great article. Thanks for all you have done here. Very good examples and a good read. Exceptionally useful information.
Источник



