- Размеры папок и дисков в Linux. Команды df и du
- Свободное место на диске (df)
- Примечание:
- Опция -h
- Размер конкретного диска
- Размер папок на диске (du)
- Просмотр размера текущей папки
- Посмотреть размеры всех папок
- Отобразить размеры всех вложенных папок
- Отсортировать папки по объёму
- Как отсортировать каталоги по фактическому размеру в Linux —
- Способ 1. Сортировка каталогов с помощью анализатора использования дисков
- Метод 2: Использование Classic du Tool
- Как отсортировать вывод du -h по размеру
- Ответ 1
- Ответ 2
- Ответ 3
- Ответ 4
- Ответ 5
- Ответ 7
- Ответ 8
- Ответ 9
- Ответ 10
- Ответ 11
- Ответ 12
- Ответ 13
- Ответ 14
- Ответ 15
- Ответ 19
- Ответ 20
- Ответ 21
- Ответ 23
- Ответ 24
Размеры папок и дисков в Linux. Команды df и du
Свободное место на диске (df)
Для просмотра свободного и занятого места на разделах диска в Linux можно воспользоваться командой df.
Первым делом можно просто ввести команду df без каких-либо аргументов и получить занятое и свободное место на дисках. Но по умолчанию вывод команды не очень наглядный — например, размеры выводятся в КБайтах (1К-блоках).
Примечание:
df не отображает информацию о не смонтированных дисках.
Опция -h
Опция -h (или —human-readable) позволяет сделать вывод более наглядным. Размеры выводятся теперь в ГБайтах.
Размер конкретного диска
Команде df можно указать путь до точки монтирования диска, размер которого вы хотите вывести:
Размер папок на диске (du)
Для просмотра размеров папок на диске используется команда du. Если просто ввести команду без каких либо аргументов, то она рекурсивно проскандирует вашу текущую директорию и выведет размеры всех файлов в ней. Обычно для du указывают путь до папки, которую вы хотите проанализировать. Если нужно просмотреть размеры без рекурсивного обхода всех папок, то используется опция -s (—summarize). Также как и с df, добавим опцию -h (—human-readable).
Просмотр размера текущей папки
Чтобы показать объем просто одного текущего каталога (со всеми вложенными файлами + подкаталогами) подойдёт команда du с ключиком -sh.
Вот пример, как определить размер директории данного сайта:
Посмотреть размеры всех папок
Если нужно посчитать вес всех директорий плюс файлы — добавляем звёздочку:
Отобразить размеры всех вложенных папок
Чтобы проверить информацию в том числе вообще по всем папкам, вместе со вложенными — понадобится самый короткий вариант:
Внимание: если такой случайно запустить в корне на объёмном диске с большим количеством информации — лучше сразу жмите CTRL-C, т.к. во-первых, иначе придётся сильно подождать 😉 , во-вторых, десятки-сотни экранов информации будут бессмысленными. Потому эта простая команда должна использоваться лишь для, соответственно, простых случаев.
Отсортировать папки по объёму
Покажет объём в килобайтах с сортировкой — самые большие папки/файлы сверху. Если нужно в мегабайтах:
К сожалению более удобный ключик h («human» — автовыбор кило-мега-гига) в данном случае (du -sh *| sort -nr) не подойдёт, т.к. сортировка идёт по «числам» (не учитывая, что это KB/MB/GB). Для этого придётся использовать длинную команду:
Источник
Как отсортировать каталоги по фактическому размеру в Linux —
Браузеры файлов Linux ведут себя так же, как и Проводник файлов под Windows или Finder под OS X, в которых сортировка каталогов по размеру не работает так, как этого ожидают многие пользователи. Вы можете сортировать каталоги по количеству подкаталогов, которые они содержат, или по количеству файлов внутри них. Тем не менее, реальный размер файла в большинстве случаев не работает, и вам понадобится дополнительный инструмент.
К счастью, есть несколько хитростей, которые вы можете сделать, чтобы узнать фактический размер каталогов по объему занимаемой ими памяти. С точки зрения файловых систем, между папками и каталогами очень мало различий. То, что ваш файловый браузер называет папкой, на самом деле одно и то же, поэтому эти приемы будут работать независимо от того, какое слово вы предпочитаете. Термин каталог используется для согласованности.
Способ 1. Сортировка каталогов с помощью анализатора использования дисков
Пользователи Ubuntu, Debian и Linux Mint, которые предпочитают инструменты для анализа графических дисков, могут попробовать использовать sudo apt-get install baobab из командной строки. Пользователи Fedora и Red Hat могут обычно использовать sudo yum install baobab из командной строки, но имейте в виду, что, будучи приложением GTK +, вам может понадобиться заполнить некоторые зависимости, если вы используете среду рабочего стола на основе QT, такую как KDE или LXQT ,
Как только вы все удовлетворите, вы можете запустить приложение из командной строки, введя baobab, или вы сможете искать его из Dash в Ubuntu на рабочем столе Unity. Вы можете удерживать клавишу Super или Windows и нажать R, а затем набрать baobab, если вы предпочитаете использовать Application Finder или запустить его, щелкнув меню «Приложения» и найдя GNOME Disk Usage Analyzer в категории «Системные инструменты». Все зависит от того, какую среду рабочего стола вы используете.
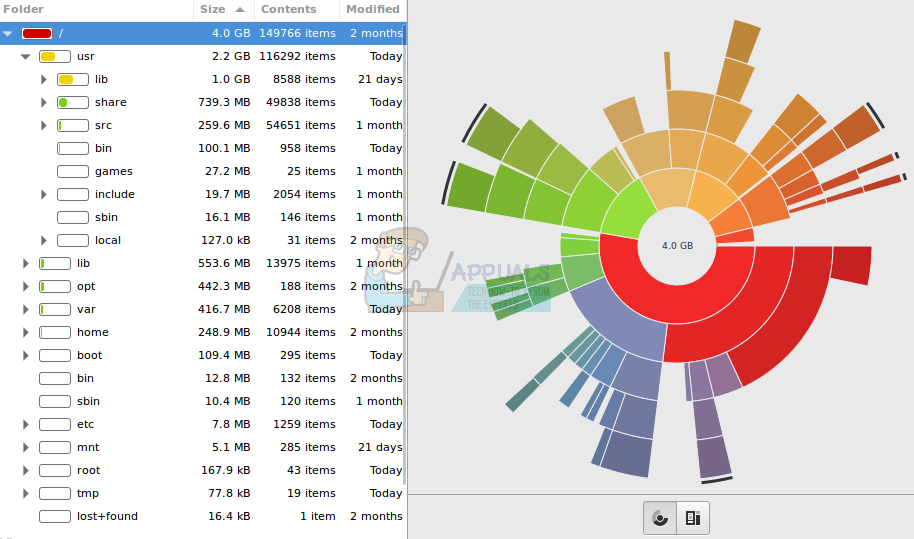
Как только он запустится, baobab предложит вам выбрать файловую систему. Выберите, какое устройство содержит каталог, который вы ищете, и дайте ему несколько минут, чтобы перечислить структуру каталога на нем. Как только это произойдет, программа представит вам на верхнем уровне все каталоги на вашем устройстве.
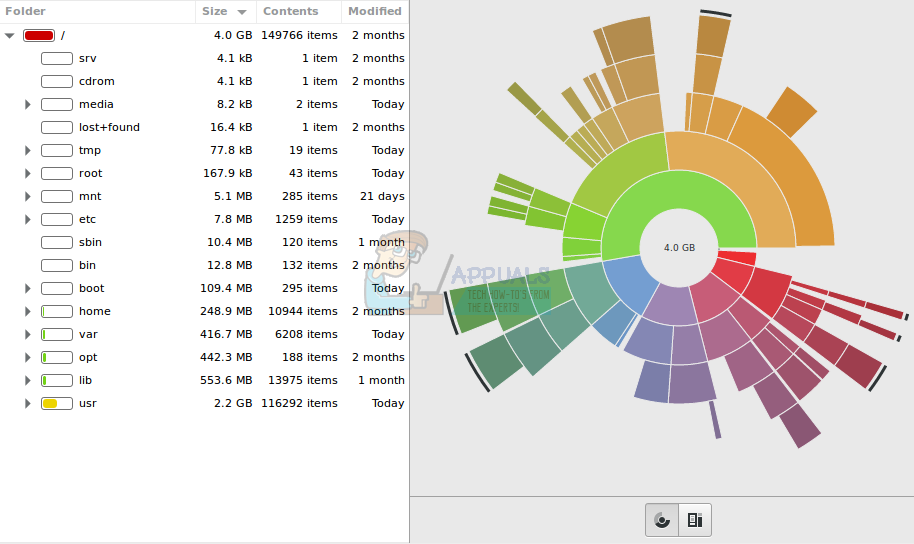
Вы можете нажать на кнопку «Размер», чтобы отсортировать каталоги по возрастанию с наименьшего значения по фактическому размеру, но по умолчанию это не так. Нажмите на стрелки рядом с именем каталога, чтобы развернуть его и таким образом отсортировать подкаталоги, которые находятся под ним.
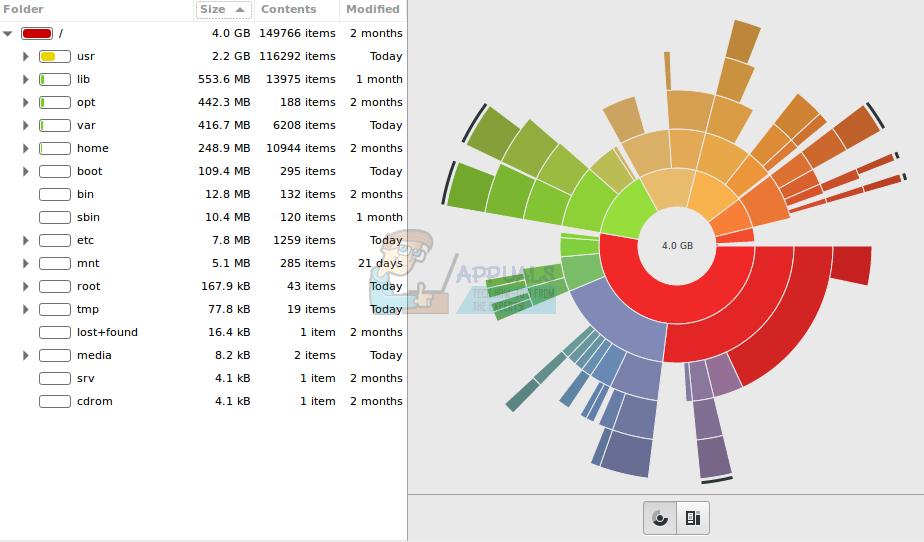
Нажав на подзаголовок «Содержание», вы фактически отсортируете каталоги так же, как это обычно делает файловый менеджер, так что это может быть полезно для сравнения фактического размера с абсолютным количеством элементов, находящихся в подкаталогах каждого каталога верхнего уровня.
Метод 2: Использование Classic du Tool
Вы можете использовать инструмент использования диска (du) из командной строки Unix практически из любой командной строки Linux, если не возражаете работать с командной строкой. Эта программа суммирует использование диска любым набором файлов. Если вы запустите его без каких-либо аргументов, он будет рекурсивно просматривать каждый каталог и суммировать размер каждого из них, пока не достигнет конца дерева.
Предполагая, что вы предпочитаете сортировать каждый каталог из определенного раздела по размеру, вы можете использовать следующую команду:
du –si –max-deep = 1 nameOfDirectory | сортировать -h
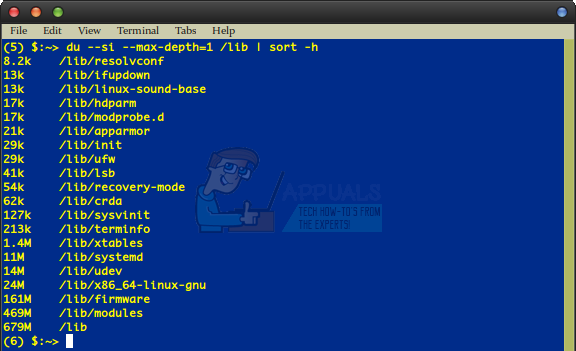
Вам нужно заменить nameOfDirectory каталогом, в котором вы бы хотели начать. Скажем, например, что вы хотите отсортировать все каталоги, найденные непосредственно в / lib, по размеру. Вы можете запустить команду как:
du –si –max-глубина = 1 / lib | сортировать -h
Вы можете изменить число после –max-deep =, так как это значение определяет, как далеко вниз в структуре каталогов должна искать команда du. Однако, поскольку цель здесь состояла в том, чтобы избежать поиска по всему дереву, мы решили оставить его равным 1 и посмотреть под одним каталогом.
Аргумент –si указывает, что команда du должна печатать размеры, используя Международную систему единиц, в которой один килобайт равен 1000 байтов. Хотя это предпочитают те, кто перешел на Linux с OS X или привык к расчету размеров каталогов с аппаратными размерами, многие пользователи чаще всего используют двоичные размеры, где 1024 байта равны 1 мегабайту. Замените –si на -h следующим образом:
du -h –max-глубина = 1 / lib | сортировать -h
Это будет отображать вывод, как и ожидалось, если вы предпочитаете двоичные размеры. Если вы привыкли измерять вещи в так называемых кибибайтах, то вы также захотите использовать эту команду. Вы также можете включить | меньше или | Команда more до конца этой командной строки, если вы находите в подкаталогах верхнего уровня так много подкаталогов, что вывод перетекает сразу со страницы. Помните, что вы должны иметь возможность использовать свою полосу прокрутки, трекпад или сенсорный экран для прокрутки результатов в любом современном эмуляторе X-терминала.
Если вы часто используете это решение и вместо этого хотите, чтобы у вас была версия, построенная на новых curses, вы можете использовать sudo apt-get install ncdu в Debian, Ubuntu, различные спины Ubuntu, Bodhi и Linux Mint для установки ncurses- на основе дю зрителя. Пользователи Fedora и Red Hat должны иметь возможность использовать sudo yum install ncdu, если они настроили файл sudoers, или su -, за которым следует пароль администратора, а затем yum install ncdu, если они еще этого не сделали.
Скорее всего, вы не должны сталкиваться с какими-либо зависимостями, потому что программа основана на ncurses и немногих других. Вы можете запустить его из текущего каталога, набрав ncdu, или заглянуть внутрь другой части дерева, набрав ncdu / lib или любой каталог, который вас интересует.
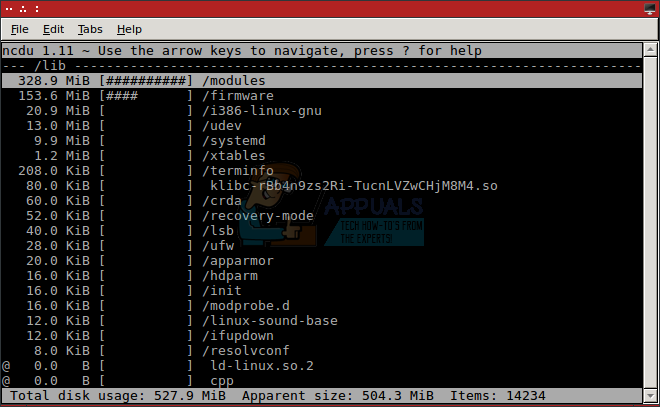
Вам сообщат, что программное обеспечение рассчитывает количество элементов, найденных в запрошенном каталоге. По завершении вы можете просматривать каталоги в порядке их истинного размера с помощью клавиш со стрелками. Вы можете нажать клавишу S, чтобы отсортировать каталоги назад и вперед в порядке их размера.
Источник
Как отсортировать вывод du -h по размеру
Мне нужно получить список вывода, который может читать человек.
Однако у du нет опции «сортировать по размеру», sort не работает с флагом, понятным человеку.
Выводит отсортированное использование диска по размеру (по убыванию):
Однако запуск его с флагом, понятным для человека, не выполняет сортировку должным образом:
Кто-нибудь знает способ сортировки du -h по размеру?
Ответ 1
Начиная с версии GNU coreutils 7.5, выпущенной в августе 2009 года, sort допускает параметр -h, который позволяет использовать числовые суффиксы, подобные тем, что выдает du -h:
Если же использовать сортировку, которая не поддерживает -h, можно установить GNU Coreutils. Например, на старой версии Mac OS X:
rew install coreutils
du -hs * | gsort -h
Из sort руководства:
-h, —human-numeric-sort compare human readable numbers (e.g., 2K 1G)
Ответ 2
Есть очень полезный инструмент под названием ncdu, который я использую для поиска и удаления этих надоедливых папок и файлов, которые занимают много места на диске. Он работает в консоли, быстрый и легкий, и имеет пакеты для всех основных дистрибутивов.
Ответ 3
Отсортируйте человекочитаемый вывод du -h с помощью другого инструмента. Например, Perl!
du -h | perl -e «sub h<%h=(K=>10,M=>20,G=>30);($n,$u)=shift=
Можно разделить на несколько строк, чтобы поместить на экране, или оставить как есть, он будет работать в любом случае.
Вывод:
Окончательный результат следующий:
Ответ 4
У меня тоже была такая проблема, и сейчас я использую другой способ:
du -scBM | sort -n
Это не даст масштабированных значений, но всегда будет отображать размер в мегабайтах. Это не идеально, но для меня это лучше, чем ничего.
Ответ 5
Насколько я могу судить, есть три варианта:
Изменить du для сортировки перед отображением.
Изменить sort для поддержки человечески понятных размеров для числовой сортировки.
Постобработка вывода из sort для изменения базового вывода на понятный человеку.
Вы также можете сделать du -k и выводить в килобайтах.
Для 3 варианта вы можете использовать следующий сценарий:
for line in sys.stdin.readlines():
if size =1024; x/=1024)<
Запуск этой программы в моем каталоге .vim дает результат:
Ответ 7
Эта версия использует awk для создания дополнительных столбцов для ключей сортировки. Она вызывает du только один раз. Вывод должен выглядеть точно так же, как в du.
Я разбил его на несколько строк, но его можно собрать и в одну.
index(«KMG», substr($1, length($1))),
substr($1, 0, length($1)-1), $0>’ |
sort -r | cut -f2,3
Пояснения:
BEGIN — создает строку для индекса, чтобы подставить 1, 2, 3 для K, M, G для группировки по единицам, если нет единицы (размер меньше 1K), то нет совпадения и возвращается ноль (идеально!).
Выводит новые поля — единицу измерения, значение (для правильной работы альфа-сорта с добавкой нуля, фиксированной длины) и исходную строку.
Проиндексировать последний символ поля размера.
Вытащить числовую часть размера.
Сортирует результаты, отбросывает лишние столбцы.
Попробуйте без команды cut, чтобы увидеть, что она делает.
Вот версия, которая выполняет сортировку внутри сценария AWK и не требует команды cut:
index(«KMG», substr($1, length($1))),
substr($1, 0, length($1)-1), $0);
for (i = c; i >= 1; i—)
Ответ 8
Вот пример, который показывает каталоги в более компактной обобщенной форме. Он обрабатывает пробелы в именах каталогов.
% du -s * | sort -rn | cut -f2- | xargs -d «\n» du -sh
7.2G VirtualBox VMs
Сортировка файлов по размеру в МБ:
du —block-size=MiB —max-depth=1 path | sort -n
Ответ 9
У меня есть простая, но полезная обертка для du на языке python под названием dutop. Обратите внимание, что мы (сопровождающие coreutils) рассматриваем возможность добавления функциональности для сортировки «человеческого» вывода напрямую.
Ответ 10
$ du -B1 | sort -nr | perl -MNumber::Bytes::Human=format_bytes -F’\t’ -lane ‘print format_bytes($F[0]).»\t».$F[1]’
Мне начинает нравиться perl. Возможно, вам придется сделать так:
Ответ 11
Этот фрагмент был заимствован у «Жан-Пьера» с http://www.unix.com/shell-programming-scripting/32555-du-h-sort.html . Можно ли верить ему?
du -k | sort -nr | awk ‘
$1 = sprintf(«%.1f %s», $1, Units[u]);
Ответ 12
Используйте флаг «-g»:
compare according to general numerical value
В моем каталоге /usr/local выводится примерно так:
Ответ 13
Нашел это в сети . похоже, работает нормально:
du -sh * | tee /tmp/duout.txt | grep G | sort -rn ; cat /tmp/duout.txt | grep M | sort -rn ; cat /tmp/duout.txt | grep K | sort -rn ; rm /tmp/duout.txt
Ответ 14
Ответ 15
Я изучил awk, придумав вчера этот пример. Это заняло некоторое время, но было очень весело, и я научился использовать awk.
Он запускает du один раз, и его вывод очень похож на du -h
2.35MB ./Work Docs
1.59MB ./Work Docs/Work
584.00KB ./scan 1.pdf
16.00KB ./Membership Transmittal Template.xlsx
Ответ 19
du -h /folder/subfolder —max-depth=1 | sort -hr
Можно добавить, | head -10, чтобы найти первые 10 или любое количество подпапок в указанном каталоге.
Ответ 20
du -sk /var/log/* | sort -rn | awk ‘
Ответ 21
Используйте следующий сценарий bash:
# list contents of the current directory by increasing
#+size in human readable format
# for some, «-d 1» will be «—maxdepth=1»
du -k -d 1 | sort -g | awk ‘
(Поскольку это последовательный вывод, вы можете добавить | sort -n, если вам действительно нужен отсортированный результат).
Эта команда, отфильтрует любой каталог, чье (суммарное) содержимое не превышает 512 МБ, а затем отображдает размеры в гигабайтах. По умолчанию du использует размер блока 512 байт (поэтому условие awk в 220 блоков равно 512 МБ, а его делитель 221 преобразует единицы измерения в ГБ — мы могли бы использовать du -kx с $1 > 512*1024 и s/1024^2 для лучшей человекочитаемости). Внутри условия awk мы устанавливаем s в размер, чтобы можно было удалить его из строки ($0). При этом сохраняется разделитель (который сворачивается в один пробел), поэтому конечный %s представляет собой пробел, а затем имя объединенного каталога. %7s округляет размер %.2f GB (увеличивает до %8s, если у вас >10TB).
В отличие от большинства приведенных здесь решений, это правильно поддерживает каталоги с пробелами в именах (хотя все решения, включая это, будут неправильно обрабатывать имена каталогов, содержащие переносы строк).
Ответ 23
По крайней мере, с помощью обычных инструментов это будет трудно сделать из-за формата человекочитаемых чисел (обратите внимание, что sort все делает правильно, поскольку сортирует числа — 508, 64, 61, 2, 2 — он просто не может сортировать числа с плавающей запятой с дополнительным множителем).
Я бы попробовал сделать все наоборот — использовать вывод «du | sort -n -r», а затем преобразовать числа в человекочитаемый формат с помощью какого-нибудь скрипта или программы.
Ответ 24
Вы можете попробовать следующее:
for i in «du -s * | sort -n | cut -f2»
Мы будем очень благодарны
если под понравившемся материалом Вы нажмёте одну из кнопок социальных сетей и поделитесь с друзьями.
Источник



