- Linux packet flow diagram
- 2 Traffic Control System Components
- 3 Hierarchical Token Bucket
- 4 General Traffic Control Concepts
- 5 Domain Name System Overview
- 6 Additional diagrams
- Network packet flow in Linux — Part 1
- Linux packet flow diagram
- Войти
- Packet flow или как работает Linux kernel netfilter
- Предисловие
- Для кого эта статья
- Теоретическая часть
- Что такое Layer3 Firewall
- Packet Flow Diagram
- Особенности терминологии
- Базовые варианты следования пакета
- Транзитный
- Входящий
- Исходящий
- Connection Tracker
- Конфигурация Connection tracker
- Список функций зависящих от connection tracker:
- Цепочки(chains) базовые и пользовательские
- Условия в правилах
- Действия в таблицах
- Пара слов про DPI
- Примеры
- Дефолтный Firewall RouterOS
- Минимальный «домашний» firewall
- Пример с DMZ
- HairPin NAT
- Правильное использование netmap
Linux packet flow diagram
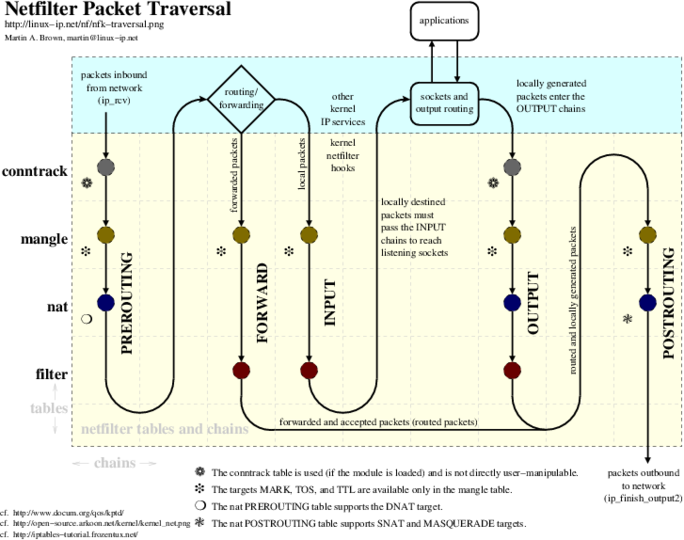
Netfilter Packet Traversal diagram, also available in the following formats nfk-traversal.pdf, nfk-traversal.png, nfk-traversal.jpg, and nfk-traversal.svg.
There are a number of different diagrams of kernel packet traversal. Here are some others:
2 Traffic Control System Components
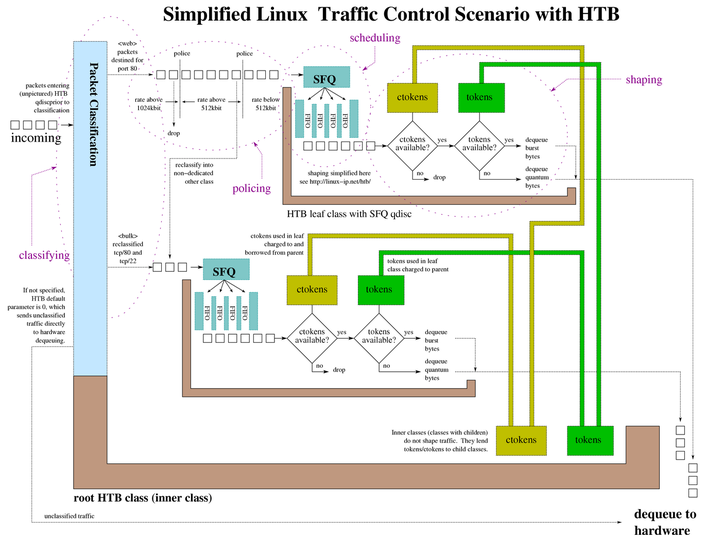
Traffic Control System Component Diagram, also available in the following formats htb-class.pdf, htb-class.png, htb-class.jpg, and htb-class.svg.
The above diagram demonstrates the resulting kernel traffic control structures generated from the following tcng configuration. The purpose is to illustrate visually many of the simplest forms of the features of the traffic control subsystem (shaping, nested qdiscs, HTB token handling, policing and reclassification).
The above tcng configuration file would create the traffic control structures shown at the top of the section Traffic Control System Components.
3 Hierarchical Token Bucket
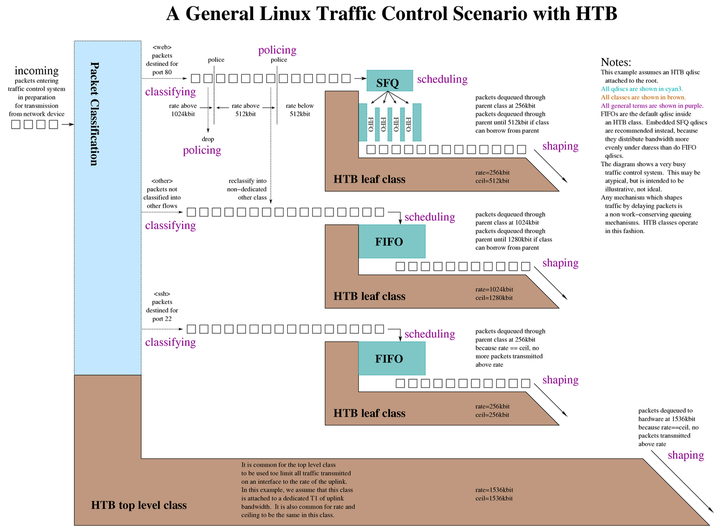
There’s no accompanying configuration file (as included in Traffic Control System Components, but this is one attempt to show where the different familiar features of general traffic control concepts would be applied when using the Hierarchical Token Bucket (HTB) qdisc under Linux.
4 General Traffic Control Concepts
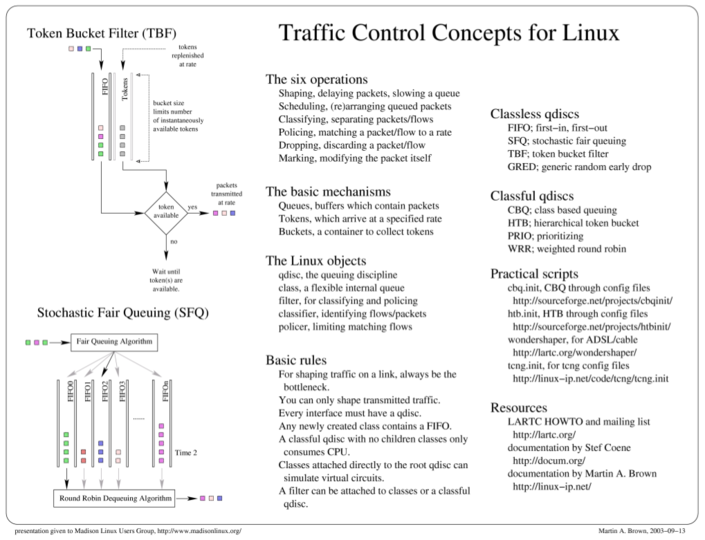
And, around the same time as creating the above diagrams, I also gave a talk on the different componentry involved in the Linux traffic control system. This is a general introduction.
5 Domain Name System Overview
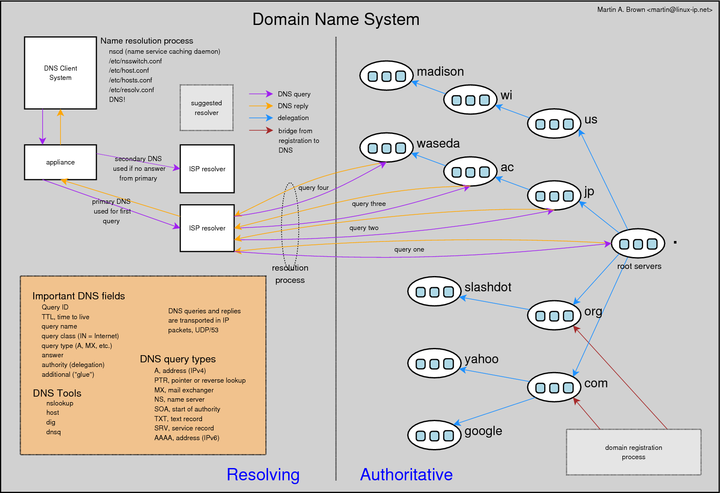
A slice of the domain name system, demonstrating the resolution process on the left hand side of the diagram and the delegation process on the right hand side. Also available in dns-overview.dia, dns-overview.eps, dns-overview.pdf, dns-overview.png, dns-overview.jpg, and dns-overview.svg.
Over the years, I had to explain both the authoritative and the resolving sides of the Domain Name System (DNS), so I created this diagram to capture a good chunk of the behaviour of the distributed system.
6 Additional diagrams
There are smaller diagrams related to individual components of the Linux traffic control subsystem scattered throughout and included in the Traffic-Control-HOWTO.
Powered by Pelican and Python. Theme based on Fresh by jsliang
Источник
Network packet flow in Linux — Part 1
Sep 29, 2018 · 4 min read
In today’s blog we see how the receive path of the network packet looks like.
There are quite a few involved concepts and digressions, but we intend to give an overview as to how a packet from network interface card flows back to the application layer and how some of the kernel APIs and data structures facilitate the flow.
So first of all what is a network packet at the wire level

A packet at wire has few headers and the actual payload which is represented as data.
The ethernet header constitutes of the mac address of the source and destination.
IP header constitutes of the source and destination IP
TCP header constitutes of the source and destination port information.
There are a couple of data structures which are key to understand here.
1. Net_device — Each NIC is represented by this data structure and has some information about the device like the mac address .The device can be physical or virtual device like tun/tap software bridges etc. Device also defines the Max Transmission Unit (mtu) which defines the max frame size a device can handle. This can be changed by using the ethtool utility. The device also exposes a set of operations as function pointers which can be used to change the device settings. Each device also maintains a set of transmission and receive queue per cpu. When the device is initialized the functions are called to setup the tx,rx queues. Device driver also setups an area of memory via DMA to be used by the device to put the network packets. DMA is the mechanism via which the hardware is allocated memory to interface with the kernel and freeing up the cpu of doing a data copy.
2. Sk_buff — This is the structure which defines the meta-data about the packet. This is one of the key data structures for network packet handling. This has pointers to the DMAed packets received. As the packet moves up the stack from L2 to L3 and L4 upto application, the pointers are adjusted on sk_buff structure as the packet flows. The diagram below shows the structure of sk_buff and how the mapping to the packet is done.

1. Packet arrives at the NIC
2. Packet gets copied via the DMA mechanism to the kernel memory
3. An interrupt is generated to have the packet processing code started
4. Linux provides interrupt handling in 2 parts
The idea behind this is that top half should be freed up quickly to handle more interrupts and the bottom half can then be scheduled. Bottom halves can be implemented in multiple ways like Softirqs , Tasklets . For the network packet receive path there is a softirq which is executed as a bottom half. The softirq runs as a softirq daemon on each of the cpu.
5. During device initialization the softirq handler is registered via the functions for both tx and rx functions
6. The net_rx_action calls the igb_clean_rx_queue which fetches the packet from the buffer and creates a skb_buf structure for the packet
7. Then netif_receive_skb is called to start the packet flow to the protocol layer
8. Ip_receive function is called which handles the ip primitives like
a. IP tables via the NF hooks.
b. Determine the routing whether the packet is for local delivery or to be forwarded
9. Tcp_recieve is called to transfer packets to the TCP layer where the sk_buff are queued in the socket buffers
10. The app layer invokes a read on the socket via the file descriptor and the packets in the socket read buffer are copied to the application layer.
There are other optimizations in the data path like
1. Receive Side scaling which is where the NIC if it supports multiple tx/rx queues can have a pair of queue per cpu. This will then allow the packets to be processed in parallel across different cpu cores
2. Receive Packet Steering — Sometimes the NIC doesn’t support multiple queues, but the same mechanism can be done in software where the packets though received on single queue are further distributed across queues.
3. Generic Receive offloading (GRO) — This allows to combine similar packets. Instead of having multiple small packets, GRO combines similar such packages into one packet with a huge payload. This allows only a single packet to be processed and reduces the overhead.
In future blogs we try to cover send side of the packet and also discuss how a L2 Bridge works in software in context of say a linux Bridge.
Disclaimer : The views expressed above are personal and not of the company I work for.
Источник
Linux packet flow diagram
Войти
Авторизуясь в LiveJournal с помощью стороннего сервиса вы принимаете условия Пользовательского соглашения LiveJournal
Packet flow или как работает Linux kernel netfilter
Во первых, очень полезная иллюстрация, глядя на нее все становится понятным. Копирайты соблюдены. Ну и добавим немного текста с википедии.
В системе netfilter, пакеты пропускаются через цепочки. Цепочка является упорядоченным списком правил, а каждое правило может содержать критерии и действие или переход. Когда пакет проходит через цепочку, система netfilter по очереди проверяет, соответствует ли пакет всем критериям очередного правила, и если так, то выполняет действие (если критериев в правиле нет, то действие выполняется для всех пакетов проходящих через правило). Вариантов возможных критериев очень много. Например, пакет соответствует критерию --source 192.168.1.1 если в заголовке пакета указано, что отправитель — 192.168.1.1. Самый простой тип перехода, —jump , просто пересылает пакет в начало другой цепочки. Также при помощи --jump можно указать действие. Стандартные действия доступные во всех цепочках — ACCEPT (пропустить), DROP (удалить), QUEUE (передать на анализ внешней программе), и RETURN (вернуть на анализ в предыдущую цепочку).
Существует пять типов стандартных цепочек, встроенных в систему:
- PREROUTING — для изначальной обработки входящих пакетов.
- INPUT — для входящих пакетов адресованных непосредственно локальному процессу (клиенту или серверу).
- FORWARD — для входящих пакетов перенаправленных на выход (заметьте, что перенаправляемые пакеты проходят сначала цепь PREROUTING, затем FORWARD и POSTROUTING).
- OUTPUT — для пакетов генерируемых локальными процессами.
- POSTROUTING — для окончательной обработки исходящих пакетов.
Также можно создавать и уничтожать собственные цепочки при помощи утилиты iptables.
Цепочки организованны в 4 таблицы:
- raw — просматривается до передачи пакета системе определения состояний. Используется редко, например для маркировки пакетов, которые НЕ должны обрабатываться системой определения состояний. Для этого в правиле указывается действие NOTRACK. Содержит цепочки PREROUTING и OUTPUT.
- mangle — содержит правила модификации (обычно заголовка) IP‐пакетов. Среди прочего, поддерживает действия TTL, TOS, и MARK (для изменения полей TTL и TOS, и для изменения маркеров пакета). Редко необходима и может быть опасна. Содержит все пять стандартных цепочек.
- nat — просматривает только пакеты, создающие новое соединение (согласно системе определения состояний). Поддерживает действия DNAT, SNAT, MASQUERADE, REDIRECT. Содержит цепочки PREROUTING, OUTPUT, и POSTROUTING.
- filter — основная таблица, используется по умолчанию если название таблицы не указано. Содержит цепочки INPUT, FORWARD, и OUTPUT.
Цепочки с одинаковым названием но в разных таблицах — совершенно независимые объекты. Например, raw PREROUTING и mangle PREROUTING обычно содержат разный набор правил; пакеты сначала проходят через цепочку raw PREROUTING, а потом через mangle PREROUTING.
Для полного понимания всех процессов NetFilter рекомендую Iptables tutorial. И ее русский вариант.
Источник
Предисловие
Для кого эта статья
Если вы умеете работать с iptables, то дерзайте и настраивайте firewall, для вас в этой статье не будет ничего нового (ну разве что в таблице NAT используются цепочки с другими именами). Если вы впервые видите firewall в RouterOS и хотите получить готовый скрипт для конфигурации, то вы его здесь не найдете. Материал нацелен на тех, кто хочет получить базовое представление о том как работает firewall и что происходит с ip пакетом на разных этапах его обработки. Более глубокое понимание прейдет с опытом и решением повседневных и необычных задач с использованием пакетного фильтра.
Теоретическая часть
Что такое Layer3 Firewall

Предположим, что у вас есть роутер с выходом в интернет и двумя bridge интерфейсами: bridge-lan(ether2-ether5) и bridge-dmz(ether6-ether10).
В пределах Bridge интерфейса устройства самостоятельно находят соседей из свой подсети и обмениваются пакетами, роутер выполняет функции свича и не отслеживает такой трафик на сетевом уровне (конечно можно принудительно заставить его это делать, но про Layer2 Firewall поговорим в другой раз).
При необходимости связаться с устройством подключенного к другому bridge интерфейсу или находящемуся в глобальной сети устройства передают пакеты маршрутизатору, который определяет маршрут следования и обрабатывает их на сетевом(Layer 3) уровне.
Packet Flow Diagram
Полный путь трафика описан в Packet Flow Diagram, есть несколько официальных(v5, v6) версий, их необходимо знать и использовать в повседневной работе, но для понимания работы пакетного фильтра они перегружены, поэтому я буду объяснять на облегченном варианте.

Input/Output Interface — это любой (физический или виртуальный) Layer 3 интерфейс роутера. Пакет который идет из локальной сети в интернет попадает на input interface, а уходит с output interface. Пакет из интернета в локальную сеть, также попадает на input interface, а уходит с output interface. Packet Flow всегда читается в одном направлении input -> output.
Особенности терминологии
Изучая packet flow для iptables, можно встретить описания через «цепочки в таблицах» либо «таблицы в цепочках». На схеме представлены таблицы в цепочках, при добавлении правил в firewall все будет наоборот.
Но на самом деле пакет перемещается между блоками [цепочка+таблицы], например если вы сделайте accept в блоке [prerouting+mangle] транзитный пакет все-равно будет обработан в [forward+mangle]. Это важно помнить в сложных конфигурациях с pbr и queues.
В документации iptables есть более точные определения, но простыми словами:
Цепочки отвечают за место обработки пакета и последовательность правил.
Таблицы определяют действия, которые можно произвести над пакетом.
Базовые варианты следования пакета

Транзитный

- Пакет из сети приходит на один из интерфейсов роутера
- В цепочке PREROUTING администратор может повлиять на маршрут следования пакета: определить выходной интерфейс (Policy base routing) или перенаправить на другой адрес (dst-nat).
- В соответствии с таблицей маршрутизации для пакета определяется исходящий интерфейс.
- Цепочка FORWARD — основное место фильтрации проходящего трафика.
- Последним пунктом перед выходом в сеть является цепочка POSTROUTING, в которой можно изменить адрес отправителя (src-nat).
- Пакет ушел в сеть.
Входящий

- Пакет из сети пришел на один из интерфейсов роутера
- Попал в цепочку PREROUTING.
- В соответствии с таблицей маршрутизации пакет был отправлен на обработку локальному процессу.
- В цепочке INPUT происходит фильтрация входящего трафика администратором.
- Пакет ушел на обработку локальному процессу.
Исходящий

- Один из процессов роутера сгенерировал ip пакет (новый или ответный — неважно).
- В соответствии с таблицей маршрутизации для пакета определен выходной интерфейс.
- Администратор может фильтровать исходящий трафик, либо изменять маршрут в цепочке OUTPUT.
- Для пакета принимается окончательное решение о выходном интерфейсе.
- Пакет попадает в POSTROUTING, как и проходящий трафик.
- Пакет ушел в сеть.
Connection Tracker
Для начала необходимо понять, что представляет из себя stateful и stateless пакетные фильтры.

Пример. Компьютер 192.168.100.10 открывает tcp соединение с сервером 192.0.2.10. На стороне клиента используется динамический порт 49149, на стороне сервера 80. Еще до получения контента клиент и сервер должны обменяться пакетами для установки tcp сессии.
В stateless потребуется открыть трафик из локальной сети в интернет и из интернета в локальную сеть (как минимум для диапазона динамических портов). Что в целом является дырой.
В stateful маршрутизатор анализирует пакеты и получив tcp syn от 192.168.100.10:49149 для 192.0.2.10:80 считает это началом нового (new) соединения. Все дальнейшие пакеты (в любом направлении) между 192.168.100.10:49149 и 192.0.2.10:80 будут считаться частью установленного (established) соединения, до закрытия tcp сессии или истечения таймеров.
Для UDP/ICMP и других видов трафика, где нельзя четко выделить начало и конец соединения, новым пакетом является первый, остальные считаются частью установленного соединения и обновляют таймеры, маршрутизатор забывает про подобные соединения по истечению таймеров.
Connection tracker делит пакеты на несколько типов:

new — пакет открывающий соединение, например syn для tcp или первый пакет в udp потоке.
established — пакет относящийся к известному соединению.
related — пакет относящийся к дополнительному соединению в мультипротоколе (sip, pptp, ftp, . ).
invalid — пакет от неизвестного соединения.
untracked — пакет не отслеживаемый connection tracker.
Конфигурация Connection tracker
enabled=yes — включен.
enabled=no — отключен.
enabed=auto — отключен, пока в firewall не появится правило использующее возможности conntrack. Используется по умолчанию.

Остальные параметры являются различными таймерами и обычно не требуют тюнинга.
Администратор может просматривать и удалять соединения, например так выглядит соединение с NAT:

Использование conntrack сказывается на производительности и потреблении ресурсов (особенно при большом числе соединений), но отключить его в большинстве конфигураций не получится, т.к. у вас останется stateless firewall без NAT.
Список функций зависящих от connection tracker:

Time To Live — поле в заголовке IP пакета определяющее число маршрутизаторов через которые может пройти пакет прежде чем будет уничтожен, защищает от бесконечной пересылки пакетов при петлях маршрутизации.

При пересылке (forwarding) роутер уменьшает значение TTL на 1 отбрасывает, если TTL=0. При этом пакет с TTL=1 попадет локальному процессу роутера.
Некторые операторы связи используют трюки с TTL для пресечения использования роутеров. Все эти ограничения прекрасно обходятся увеличением значения ttl в таблице mangle.
Network Address Translation — технология изменения адресов в заголовке ip пакета. Как и в linux, NAT является частью пакетного фильтра. NAT работает на основе connection tracker.
Изначально NAT был разработан как быстрое решение проблемы исчерпания IPv4 адресов, для локальных сетей было предложено использовать подсеть из диапазонов: 10.0.0.0/8; 172.16.0.0/12; 192.168.0.0/16 и транслировать их в один(или несколько) маршрутизируемых адресов. На самом деле есть еще несколько служебных подсетей, которые можно использовать в частных сетях и роутеру в принципе все-равно что и как NAT’ить, но рекомендуется следовать стандартам.
NAT обрабатывает только: tcp, udp, icmp и некоторых мультипротоколов из [IP]->[Firewall]->[Service Port]. Обрабатывается только первый (connection-state=new) пакет в соединении, оставшиеся обрабатываются автоматически без участия таблицы NAT. Это можно отследить по изменению счетчиков в правилах.
В заголовке пакета присутствует Source и Destenation address, соответственно и NAT делится на Source и Destenation NAT.
Source NAT — подмена адреса отправителя, присутствует на подавляющем большинстве домашних и корпоративных роутеров в мире.

Позволяет множеству устройств с «серыми» адресами в локальной сети общаться с интернетом используя один (или несколько) реальных адресов.

Возвращаясь к Packet Flow смотрим, что SRC-NAT находится в Postrouting, после принятия решения о маршрутизации пакета.
Ответный пакет проходит неявный DST-NAT в котором адрес получателя меняется на локальный.
Destenation NAT — подмена адреса получателя.

Применяется при необходимости переслать пакет на другой адрес, обычно используется для «проброса портов» из внешней сети в локальную.

По Packet Flow работа DST-NAT происходит до принятия решения о маршрутизации в Prerouting, присутствует неявный SRC-NAT для ответного трафика.
NAT является довольно мощным инструментом управления трафиком, но применять его стоит в последнюю очередь (когда остальные инструменты не могут помочь).
Цепочки(chains) базовые и пользовательские
Цепочки состоят из правил и форсируют логику обработки пакета.
Есть несколько базовых цепочек, отображенных на packet flow:
Prerouting(dstnat) — обработка пакета до принятия решения о маршрутизации
Input — обработка пакетов предназначеных локальным процессам маршрутизатора
Output — обработка пакетов пакетов сгенерированных локальными процессами маршрутизатора
Forward — Обработка проходящего трафика
Postrouting(srcnat) — Обработка трафика готового к передаче на интерфейс
Все как в iptables, но цепочки в nat переименованы. С чем это связано (скорее всего с hotspot или аппаратной разгрузкой nat) мне неизвестно, но в корне ничего не меняет.
Пакет проходит правила в цепочке последовательно, если он подходим по всем условиям, то к пакету применяется действие. Если действие является терминирующим и не отбрасывает пакет, то он передается в следующий блок packet flow.
У всех цепочек базовых есть действие по умолчанию (если пакет не подошел ни под одно из правил) — accept.
Пользовательские цепочки необходимы для уменьшения количества правил которые проходит каждый пакет и для построения сложных правил обработки трафика. У всех пользовательских цепочек есть действие по умолчанию — return.

В пределах таблицы можно пересылать правила из нескольких различных базовых (и пользовательских) цепочек в пользовательскую, но вернется пакет в ту цепочку из которой пришел.

Условия в правилах
Цепочки состоят из правил, каждое правило состоит из условий и действия. Условий достаточно много, но далеко не все вы будете использовать в реальных конфигурациях. Большинству условий можно поставить префикс «не» (знак «!»). Для совпадением с правилом, пакет должен подходить под все указанные условия.

Некоторые из условий:
| Условие | Описание |
|---|---|
| src-address | Адрес источника |
| dst-address | Адрес получателя |
| src-address-list | Адрес источника присутствует в списке |
| dst-address-list | Адрес получателя присутствует в списке |
| protocol | Протокол транспортного уровня |
| src-port | Порт источника |
| dst-port | Порт получателя |
| port | Порт источника или получателя |
| in-interface | Интерфес на который пришел пакет |
| out-interface | Интерфейс с которого пакет будет отправлен в сеть |
| in-interface-list | Интерфес на который пришел пакет присутствует в списке |
| out-interface-list | Интерфейс с которого пакет будет отправлен в сеть присутствует в списке |
| layer7-protocol | Анализ содержимого первых 10 пакетов в соединениий |
| content | Поиск заданной строки в пакете |
| tls-host | Поиск хоста в заголовке tls |
| ipsec-policy | Проверить подпадает пакет под политику ipsec или нет |
| packet-size | размер пакета в байтах |
| src-mac-address | mac адрес источника пакета |
| connection-mark | Метка соединения |
| packet-mark | Метка пакета |
| routing-mark | Маршрутная метка пакета |
| connection-state | Состояние пакета в соединении |
| tcp-flags | Флаги tcp пакета |
| icmp-options | Опции icmp пакета |
| random | Правило срабатывает(при совпадении остальных условий) с заданной вероятностью |
| time | Можно указать рабочее время правила, к сожалению без конктеризации даты |
| ttl | Значение поля ttl в пакете |
| dscp | Значение поля DSCP(ToS) в пакете |
| —//— | —//— |
| place-before | Консольная опция(не условие), позволяет добавить правило перед указанным |
| disabled | Консольная опция(не условие), позволяет отключить правило |
Примечания
В качестве src.(dst.) address можно указывать: одиночный ip, диапазон адресов через дефис, либо подсеть.
Списки адресов необходимы для объединения под одним именем нескольких несвязанных ip. В отличии от ipset в netfilter, записи в списках MikroTik могут удаляться через заданный промежуток времени. Просмотреть списки и внести изменения можно в [IP]->[Firewall]->[Address Lists].
В качестве номера порта(port, src-port, dst-port) можно указывать одиночный порт, несколько портов через запятую, либо диапазон портов через дефис.
На последнем MUM в МСК была неплохая презентация на тему влияния различных условий на скорость обработки пакетов (там же вы узнаете как использовать таблицу raw для снижения нагрузки на роутер), кому интересно: запись и презентация.
Действия в таблицах
Набор доступных действий над пакетом, зависит от таблицы в которой он обрабатывается.

Filter — таблица фильтрации трафика, одно из двух мест, где можно отбросить пакет.
NAT — таблица модификации ip адресов и портов(tpc, udp) в заголовке ip пакета.
Mangle — таблица для модификации других полей ip пакета и установки различных меток.

Существует три типа внутренних меток пакетов: connection, packet, route. Сетки существуют только в пределах роутера и не уходят в сеть. Пакет может иметь по одной метке каждого типа, при последовательном прохождении нескольких mark-* правил метки перезаписываются.
Маршрутные метки можно ставить только в цепочках prerouting и output, остальные в любых цепочках.
Хорошей практикой считается сначала маркировать соединение (connection), а потом пакет (packet) либо маршрут (route). Проверка наличия метки происходит быстрее чем полей пакета. На практике, это не всегда так и в сложных очередях или pbr дополнительная маркировка соединения не приносит пользы.
RAW — таблица позволяющая пакетам обходить механизм трекинга соединений (connection tracker). Используется для противодействия DoS и снижения нагрузки на cpu (например исключением multicast трафика). Позволяет отбросить пакет.
Терминирующие действия завершают обработку пакета в цепочке и передают следующему блоку в packet flow, либо отбрасывают.
| Таблица | Действие | Описание | Терминирующее? |
|---|---|---|---|
| Все | accept | Прекратить обработку пакета и передать в следующий блок Pakcet flow | Да |
| Все | log | Записать в log информацию о пакете.В современных версиях можно добавить log к любому другому действию | Нет |
| Все | passtrough | Посчитать число пакетов. Используется для отладки | Нет |
| Все | add src to address list и add dst to address list | Добавить source (destenation) адрес из пакета в заданный список | Нет |
| Все | jump | Перейти в пользовательскую цепочку | Да |
| Все | return | Вернуться в родительскую цепочку. В базовых цепочках работает как accept | Да |
| Filter и Raw | drop | Остановить движение пакета по packet flow и отбросить | Да |
| Filter и Prerouting | fasttrack | Пометить пакет для быстрого прохождения packet flow | Да |
| Filter | reject | Аналогично drop, но отправителю пакетов отправляется уведомление(tcp или icmp) о отброшенном пакете | Да |
| Filter | trapit | Эмулировать наличие открытого порта. Используется для защиты от DoS, ввода в заблуждение и(иногда) отладке | Да |
| NAT | src-nat | Подмена адреса отправителя на указанный | Да |
| NAT | masquerade | Частный случай src-nat, подменяет адрес отправителя на один из адресов с интерфейса, используется на динамических(dhcp, vpn) интерфейсах. Не рекомендуется использовать при наличии нескольких ip на интерфейсе | Да |
| NAT | same | Частный случай src-nat. Подменяет адрес отправителя на адрес из заданного диапазона | Да |
| NAT | dst-nat | Подменяет адрес получателя на указанный | Да |
| NAT | redirect | Частный случай dst-nat, подменяет адрес получателя на адрес интерфейса роутера на который пришел пакет | Да |
| NAT | netmap | Не замена dst-nat. Применяется при трансляции сеть-в-сеть, смотрите примеры | Да |
| Mangle | mark connection | Метка соединения | Нет |
| Mangle | mark packet | Метка пакета, применяется в очередях | Нет |
| Mangle | mark routing | Метка маршрута, применяется в Policy base routing | Нет |
| Mangle | change ttl | Изменить ttl | Нет |
| Mangle | change dcsp(tos) | Изменить dcsp, в десятичном виде | Нет |
| Mangle | change mss | Изменить mss в tcp syn | Нет |
| Mangle | clear df | Очистить флаг do not fragmet | Нет |
| Mangle | strip ipv4 options | Очистить дополнительные опции ipv4 | Нет |
| Mangle | set priority | Установить приоритет для CoS | Нет |
| Mangle | route | Задать gateway для пакета. Простая версия PBR | Нет |
| Mangle | sniff tzsp | Инкапсулировать пакеты в udp и отправить на указанный ip | Нет |
| Mangle | sniff pc | Аналог tzsp, но с другим типом инкапсуляции. В wiki если примеры использования с calea | Нет |
| Mangle | passtrough | По умолчанию большинство правил в mangle не останавливает прохождение пакета, можно изменить это поведение установить passtrough=no | Нет |
| Raw | notrack | Не отслеживать пакет в connection tracker | Да |
Если найдутся желающие, могу написать подробнее про FastTrack и FastPath, но чудес от этих технологий ждать не стоит.
Пара слов про DPI
Существует несколько возможностей заглядывать в пакет чуть глубже заголовка транспортного уровня:
content — производит поиск заданной строки в пакете.
layer7-protocol — буферезирует первые 10 пакетов (или 2KiB) из соединения и производит поиск по regexp в буферезированных данных. Большое число layer7 правил существенно влияют на производительность.
tls-host — адрес имени хоста в заголовке TLS/SNI соединения HTTPS.
Примеры
Не копируйте примеры бездумно, лучше возбмите устройство и постарайтесь написать конфигурацию самостоятельно (или переписать примеры, но вникнуть что делает каждое из правил). Если не знаете как дополнить правила: в дефолтной и минимальной домашней конфигурациях нет доступа на роутер с wan интерфейса, добавьте его с фильтрацией по списку адресов.
Дефолтный Firewall RouterOS
Достаточно защищенная конфигурация, но местами сильно замороченая:
Никогда не использовал дефолтный конфиг, но раньше дефолтный firewall был значительно хуже.
Минимальный «домашний» firewall
Самый простой, что удалось придумать. Да в нем не разрешен untracked трафик (но на этапе базового изучения firewall он вам всеравно не нужен) и будут проблемы с туннельным ipsec (опять-же, если вы умеете настраивать ipsec, то сами знаете что необходимо сделать).
Пример с DMZ
На «домашних» роутерах аббревиатурой DMZ любят обзывать компьютер в локальной подсети для которого проброшены все порты из внешней сети.
На самом деле это не так и один из вариантов DMZ — отделение ресурса на который необходимо предоставить доступ из сети интернет и может быть проведена успешная атака (web server с cms в которых постоянно находят дыры — хорошая цель для взломщика). В случае взлома, злоумышленник не сможет повлиять на участников локальной сети.

HairPin NAT

Типичная ситуация, когда вы делайте проброс порта на сервер в локальной сети и извне все работает, а вот внутри локальной сети сервер не доступен по внешнему адресу.
Давайте разберем что происходит:
- Компьютер 192.168.100.10 отправляет запрос на 192.0.2.100
- На роутере отрабатывает DST-NAT и пакет пересылается на 192.168.100.2
- Сервер видит, что к нему на адрес 192.168.100.2 пришел пакет от 192.168.100.10 и отвечает с локального адреса
- Компьютер получает неожиданный пакет от 192.168.100.2 и отбрасывает его.
Решение — добавить дополнительное правило изменяющее адрес источника на адрес роутера, таким образом сервер вернет пакет на роутер, который отправит его на компьютер инициализатор.
На практике такую схему используют не часто, но как пример отладки firewall мне очень нравится.
Правильное использование netmap

Netmap — технология трансляции адресов из одной подсети в адреса другой подсети.
IP адрес (в записи с маской) состоит из двух частей: сетевой (число бит указанных в маске подсети) и хостовой (оставшиеся биты). Netmap изменяет сетевую часть адреса, но не трогает хостовую.

Есть два роутера соединенные VPN каналом. Роутеры обслуживают подсети с одинаковой адресацией. Необходимо сделать доступ между подсетями.
Без дополнительной адресации тут не обойтись.
Пользователи из левой подсети будут стучаться в правую через подсеть 192.168.102.0/24
Пользователи из правой подсети будут стучаться в левую через подсеть 192.168.101.0/24
Конфигурация на MikroTik 1.
Конфигурация MikroTik2 практически аналогична:
Есть более сложные конфигурации с использованием netmap, например если у вас множество подключений к удаленным точкам с пересекающимеся подсетями и нет возможности изменить настройки на удаленном оборудовании, но это уже advanced routing.
Если вы ничего не поняли (про netmap), значит оно вам не нужно и просто не используйте данное действие при пробросе портов.
Источник



