- Что каждый программист должен знать о памяти.
- Часть 4: Поддержка устройств NUMA
- 5.1 Аппаратные устройства NUMA
- Linux память процесса numa
- СООТВЕТСТВИЕ СТАНДАРТАМ
- ЗАМЕЧАНИЯ
- Поддержка в библиотеках
- Как Linux работает с памятью. Семинар в Яндексе
- Термины
- Страницы памяти
- Memory Zones и NUMA
- Page Cache
- Память процесса
- Выделение памяти
- Работа с файлами и с памятью
- Readahead
- Источники пополнения Free List
Что каждый программист должен знать о памяти.
Часть 4: Поддержка устройств NUMA
Прим.ред.: Напомним, что NUMA (Non-Uniform Memory Access — «неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — схема реализации компьютерной памяти, используемая в мультипроцессорных системах, когда время доступа к памяти определяется её расположением по отношению к процессору.
В разделе 2 мы видели, что на некоторых машинах, стоимость доступа к конкретным областям физической памяти различается в зависимости от того, откуда происходит доступ. Для этого типа устройств требуется особое внимание со стороны операционной системы и приложений. Мы начнем с некоторых особенностей устройств NUMA, а затем рассмотрим некоторые средства поддержки, предлагаемые в ядре Linux для устройств NUMA.
5.1 Аппаратные устройства NUMA
Использование архитектуры с неравномерным доступом к памяти становятся все более и более распространенным явлением. В простейшем случае архитектуры NUMA процессор может иметь локальную память (смотрите рис.2.3), доступ к которой дешевле, чем доступ к этой локальной памяти из других процессоров. Различие в стоимости для данного типа системы NUMA невысокая, то есть показатель NUMA является низким.
Архитектура NUMA используется также, и в особенности, в больших машинах. Мы описали проблемы получения доступа к одной и той же памяти из различных процессоров. С точки зрения аппаратных средств, все процессоры будут использовать один и тот же северный мост (без учета на данный момент узлов NUMA для машин AMD Opteron, у которых есть свои собственные проблемы). Это делает северный мост одним из самых узких мест, поскольку весь трафик с памятью проходит через него. В больших машинах можно, конечно, вместо северного моста использовать специальные аппаратные средства, но, если используемые чипы памяти не имеют несколько портов, то есть они не могут использоваться из нескольких шин, то узкие места все еще остаются. Многопортовая память является сложной и дорогой для производства и эксплуатации и, поэтому, почти не используется.
Следующим шагом по сложности является использование модели AMD, в которой механизм взаимодействия (Hypertransport, в случае AMD, технология, лицензированная фирмой Digital) предоставляет доступ процессорам, которые не имеют непосредственного доступа к памяти. Для того, чтобы диаметр (т.е., максимальное расстояние между любыми двумя узлами) не увеличивался произвольным образом, размер структур, которые могут формироваться таким образом, должен быть ограничен.
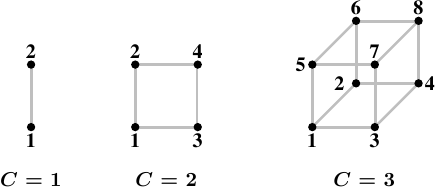
Рис 5.1: Гиперкубы
Наилучшей топологией для узлов является гиперкуб, в котором количество узлов ограничено 2 C , где С — количество интерфейсов взаимных соединений, которое есть в каждом узле. Гиперкубы для всех систем с числом процессоров, равным 2n, имеют маленький диаметр. На рис.5.1 показаны первые три гиперкуба. Каждый гиперкуб имеет диаметр С, что является абсолютным минимумом. В первом поколении процессоров Opteron фирмы AMD было по три гипертранспортных соединения на процессор. По крайней мере, к одному из соединений должен быть подключен южный мост, а это означает, что в настоящее время эффективно и без всяких ухищрений можно реализовать гиперкуб с C = 2. Объявлено, что в следующем поколении соединений будет четыре, благодаря чему удастся реализовать гиперкуб с C = 3.
Однако, это не означает, что нельзя поддерживать работу большего количества процессоров. Есть компании, которые разработали сборки, позволяющие использовать наборы с большим количеством процессоров (например, Horus фирмы Newisys). Но эти сборки имеют большой показатель NUMA и при определенном количестве процессоров они становятся неэффективными.
Следующий шаг состоит в подключении групп процессоров и реализация совместно используемой памяти для каждого процессора из группы. Для всех таких систем требуются специализированные аппаратные средства и такие системы не являются изделиями широкого спроса. Такие конструкции имеют несколько уровней сложности. Системой, которая все еще достаточно похожа на машину широкого спроса, является машина IBM X445 и аналогичные машины. Их можно купить как обычные машины, имеющие размер 4U, 8 каналов и процессорами x86 и x86-64. Две такие машины (а с некоторого момента и четыре такие машины) можно объединить для работы в виде одной машины с совместно используемой памятью. Используемые соединения имеют большой показатель NUMA, что должно учитываться как операционной системой, так и приложением.
На другом конце спектра находятся машины, такие как Altix фирмы SGI, которые специально предназначены для подключения друг к другу. Механизм соединения NUMA, реализованный SGI, очень быстрый и имеет более низкую латентность; оба этих свойства очень важны при высокопроизводительных вычислениях (high-performance computing — HPC), особенно в случаях, когда используются интерфейсы Message Passing Interfaces (MPI). Недостатком является, конечно, то, что такая сложность и специализация стоят очень дорого. С их помощью можно получить достаточно низкий коэффициент NUMA, но с тем числом процессоров, которые могут быть в этих машинах (а это — несколько тысяч), а также из-за ограниченных возможностей соединений, показатель NUMA фактически является динамическим и, в зависимости от нагрузки, может достичь неприемлемых уровней.
Наиболее часто используются решения, в которых с помощью высокоскоростных соединений создается кластер из широко распространенных машин. Но они не являются системами NUMA, у них нет общего адресного пространства и, следовательно, они не попадают в какую-нибудь из категорий, которые здесь обсуждаются.
Источник
Linux память процесса numa
В каждой строке содержится информация области памяти, используемом процессом, отражающей, помимо прочего, применяемую политику памяти для этой области и какие страничные узлы были выделены.
Файл numa_maps доступен только на чтение. При чтении /proc/
/numa_maps ядро сканирует виртуальное адресное пространство процесса и выдаёт как используется память. Одна строка соответствует уникальной области памяти процесса.
В первом поле каждой строки содержится начальный адрес области памяти. Это поле позволяет провести параллель с файлом /proc/
/maps, в котором содержится конечный адрес области и другая информация, такая как права доступа и данные о совместном использовании.
Во втором поле показана политика памяти, которая применена к области в настоящее время. Заметим, что применённая политика необязательно является политикой, установленной процессом для этой области памяти. В частности, если для этой области процесс установил политику «default» (по умолчанию), то применяемая политика для этой области будет политикой процесса, которая может совпадать, а может и не совпадать с «default».
В оставшейся части строки содержится информация о страницах, выделенных в области памяти:
N = Количество страниц, выделенных на . В учитываются только страницы, отображённые процессом в настоящий момент. Перемещение (migration) страниц и возвращение памяти может приводить к временному неотображению страниц, связанных с этой областью памяти. Такие страницы могут появиться снова только после того, как процесс попытается обратиться к ним. Если область памяти считается общей или является отображением файла, то для других процессов в это же время могут быть показаны дополнительные страницы, отображённые в соответствующее адресное пространство. file= Файл, отображаемый в область памяти. Если файл отображён как закрытый (private), попытка записи может сгенерировать страницы COW (копирование при записи) в этой области памяти. Эти страницы показываются как анонимные. heap Область памяти, используемая под кучу. stack Область памяти, используемая под стек. huge Область огромной памяти. Показывает количество огромных страниц, а не страниц обычного размера. anon= Количество анонимных страниц в области. dirty= Количество грязных (dirty) страниц. mapped= Общее количество отображённых страниц, если оно отличается от количества страниц dirty и anon. mapmax= Максимальный mapcount (количество процессов, отображающих одну страницу) обнаруженный при сканировании. Может использоваться как индикатор степени совместного использования заданной области памяти. swapcache= Количество страниц, связанных с участками на устройстве подкачки. active= Количество страниц в активном списке. Это поле показывается только, если его значение отличается от количества страниц в этой области. Это означает, что в области памяти существует несколько неактивных страниц, которые могут быть скоро удалены swapper. writeback= Количество страниц, которые в настоящий момент записываются на диск.
СООТВЕТСТВИЕ СТАНДАРТАМ
ЗАМЕЧАНИЯ
Поддержка в библиотеках
Однако, приложения не должны использовать эти системные вызовы напрямую. Вместо этого, рекомендуется использовать интерфейс высокого уровня, предоставляемый функциями numa(3) из пакета numactl. Пакет numactl доступен по адресу Пакет также включён в некоторые дистрибутивы Linux. Некоторые дистрибутивы помещают библиотеку для разработки и заголовочные файлы в пакет numactl-devel.
Источник
Как Linux работает с памятью. Семинар в Яндексе
Привет. Меня зовут Вячеслав Бирюков. В Яндексе я руковожу группой эксплуатации поиска. Недавно для студентов Курсов информационных технологий Яндекса я прочитал лекцию о работе с памятью в Linux. Почему именно память? Главный ответ: работа с памятью мне нравится. Кроме того, информации о ней довольно мало, а та, что есть, как правило, нерелевантна, потому что эта часть ядра Linux меняется достаточно быстро и не успевает попасть в книги. Рассказывать я буду про архитектуру x86_64 и про Linux-ядро версии 2.6.32. Местами будет версия ядра 3.х.
Эта лекция будет полезна не только системным администраторам, но и разработчикам программ высоконагруженных систем. Она поможет им понять, как именно происходит взаимодействие с ядром операционной системы.
Термины
Резидентная память – это тот объем памяти, который сейчас находится в оперативной памяти сервера, компьютера, ноутбука.
Анонимная память – это память без учёта файлового кеша и памяти, которая имеет файловый бэкенд на диске.
Page fault – ловушка обращения памяти. Штатный механизм при работе с виртуальной памятью.
Страницы памяти
Работа с памятью организована через страницы. Объём памяти, как правило, большой, присутствует адресация, но операционной системе и железу не очень удобно работать с каждым из адресов отдельно, поэтому вся память и разбита на страницы. Размер страницы – 4 KБ. Также существуют страницы другого размера: так называемые Huge Pages размером 2 MБ и страницы размером 1 ГБ (о них мы говорить сегодня не будем).
Виртуальная память – это адресное пространство процесса. Процесс работает не с физической памятью напрямую, а с виртуальной. Такая абстракция позволяет проще писать код приложений, не думать о том, что можно случайно обратиться не на те адреса памяти или адреса другого процесса. Это упрощает разработку приложений, а также позволяет превышать размер основной оперативной памяти за счёт описанных ниже механизмов. Виртуальная память состоит из основной памяти и swap-устройства. То есть объём виртуальной памяти может быть в принципе неограниченного размера.
Для управления виртуальной памятью в системе присутствует параметр overcommit . Он следит за тем, чтобы мы не переиспользовали размер памяти. Управляется через sysctl и может быть в следующих трех значениях:
- 0 – значение по умолчанию. В этом случае используется эвристика, которая следит за тем, чтобы мы не смогли выделить виртуальной памяти в процессе намного больше, чем есть в системе;
- 1 – говорит о том, что мы никак не следим за объёмом выделяемой памяти. Это полезно, например, в программах для вычислений, которые выделяют большие массивы данных и работают с ними особым способом;
- 2 – параметр, который позволяет строго ограничивать объем виртуальной памяти процесса.
Посмотреть, сколько у нас закоммичено памяти, сколько используется и сколько мы можем ещё выделить, можно в строках CommitLimit и Commited_AS из файла /proc/meminfo .
Memory Zones и NUMA
В современных системах вся виртуальная память делится на NUMA-ноды. Когда-то у нас были компьютеры с одним процессором и одним банком памяти (memory bank). Называлась такая архитектура UMA (SMP). Всё было предельно понятно: одна системная шина для общения всех компонентов. В последствии это стало неудобно, начало ограничивать развитие архитектуры, и, как следствие, была придумана NUMA.

Как видно из слайда, у нас есть два процессора, которые общаются между собой по какому-то каналу, и у каждого из них есть свои шины, через которые они общаются со своими банками памяти. Если мы посмотрим на картинку, то задержка от CPU 1 к RAM 1 в NUMA-ноде будет в два раза меньше, чем от CPU 1 на RAM 2. Получить эти данные и прочую информацию мы можем, используя команду numactl hardware .
Мы видим, что сервер имеет две ноды и информацию по ним (сколько в каждой ноде свободной физической памяти). Память выделяется на каждой ноде отдельно. Поэтому можно потребить всю свободную память на одной ноде, а другую — недогрузить. Чтобы такого не было (это свойственно базам данных), можно запускать процесс с командой numactl interleave=all. Это позволяет распределять выделение памяти между двумя нодам равномерно. В противном случае ядро выбирает ноду, на которой был запланирован запуск этого процесса (CPU scheduling) и всегда пытается выделить память на ней.
Также память в системе поделена на Memory Zones. Каждая NUMA-нода делится на какое-то количество таких зон. Они служат для поддержки специального железа, которое не может общаться по всему диапазону адресов. К примеру, ZONE_DMA – это 16 MБ первых адресов, ZONE_DMA32 – это 4 ГБ. Смотрим на зоны памяти и их состояние через файл /proc/zoneinfo .
Page Cache
Через Page Cache в Linux по умолчанию идут все операции чтения и записи. Он динамического размера, то есть именно он съест всю вашу память, если она свободна. Как гласит старая шутка, если вам нужна свободная память в сервере, просто вытащите ее из сервера. Page Cache делит все файлы, которые мы читаем, на страницы (страница, как мы сказали, – 4 KБ). Посмотреть, есть ли в Page Cache какие-то страницы какого-то конкретного файла, можно с помощью системного вызова mincore() . Или с помощью утилиты vmtouch, которая написана с использованием этого системного вызова.
Как же происходит запись? Любая запись происходит на диск не сразу, а в Page Cache, и делается это практически моментально. Тут можно увидеть интересную «аномалию»: запись на диск идет намного быстрее, чем чтение. Дело в том, что при чтении (если данной странички файла в Page Cache нет) мы пойдем в диск и будем синхронно ждать ответа, а запись в свою очередь пройдет моментально в кеш.
Минусом такого поведения является то, что на самом деле данные никуда не записались, — они просто находятся в памяти, и когда-то их нужно будет сбросить на диск. У каждой странички при записи проставляется флажок (он называется dirty). Такая «грязная» страничка появляется в Page Cache. Если накапливается много таких страничек, система понимает, что пора их сбросить на диск, а то можно их потерять (если внезапно пропадет питание, наши данные тоже пропадут).
Память процесса
Процесс состоит из следующих сегментов. У нас есть stack, который растет вниз; у него есть лимит дальше котрого он расти не может.
Затем идет регион mmap: там находятся все отображенные на память файлы процесса, которые мы открыли или создали через системный вызов mmap() . Далее идет большое пространство невыделенной виртуальной памяти, которую мы можем использовать. Снизу вверх растет heap – это область анонимной памяти. Внизу идут области бинарника, который мы запускаем.
Если мы говорим о памяти внутри процесса, то работать со страницами тоже неудобно: как правило, выделение памяти внутри процесса происходит блоками. Очень редко требуется выделить одну-две странички, обычно нужно выделить сразу какой-то промежуток страниц. Поэтому в Linux существует такое понятие, как область памяти (virtual memory area, VMA), которая описывает какое-то пространство адресов внутри виртуального адресного пространства этого процесса. На каждую такую VMA есть свои права (чтения, записи, исполнения) и области видимости: она может быть приватная или общая (которая «шарится (share)» с другими процессами в системе).
Выделение памяти
Выделение памяти можно поделить на четыре случая: есть выделение приватной памяти и памяти, которой можем с кем-то поделиться (share); двумя другими категорями являются разделение на анонимную память и ту, у которая связана с файлом на диске. Самые частые функции выделения памяти – это malloc и free. Если мы говорим о glibc malloc() , то он выделяет анонимную память таким интересным способом: использует heap для аллокации маленьких объемов (менее 128 KБ) и mmap() для больших объемов. Такое выделение необходимо для того, чтобы память расходовалась оптимальнее и её можно было запросто отдавать в систему. Если в heap не хватает памяти для выделения, вызывается системный вызов brk() , который расширяет границы heap. Системный вызов mmap() занимается тем, что отображает содержимое файла на адресное пространство. munmap() в свою очередь освобождает отображение. У mmap() есть флаги, которые регулируют видимость изменений и уровень доступа.
На самом деле, Linux не выделяет всю запрошенную память сразу. Процесс выделения памяти — Demand Paging — начинается с того, что мы запрашиваем у ядра системы страничку памяти, и она попадает в область Only Allocated. Ядро отвечает процессу: вот твоя страница памяти, ты можешь её использовать. И больше ничего происходит. Никакой физической аллокации не происходит. А произойдет она только в том случае, если мы попробуем в эту страницу произвести запись. В этот момент пойдёт обращение в Page Table – эта структура транслирует виртуальные адреса процесса в физические адреса оперативной памяти. При этом будут задействованы также два блока: MMU и TLB, как видно из рисунка. Они позволяют ускорять выделение и служат для трансляции виртуальных адресов в физические.
После того, как мы понимаем, что этой странице в Page Table ничего не соответствует, то есть нет связи с физической памятью, мы получаем Page Fault – в данном случае минорный (minor), так как отсутствует обращение в диск. После этого процесса система может производить запись в выделенную страницу памяти. Для процесса все это происходит прозрачно. А мы можем наблюдать увеличение счетчика минорных Page Fault для процесса на одну единицу. Также бывает мажорный Page Fault – в случае, когда происходит обращение в диск за содержимым страницы (в случае mmpa() ).
Один из трюков в работе с памятью в Linux – Copy On Write – позволяет делать очень быстрые порождения процессов (fork).
Работа с файлами и с памятью
Подсистема памяти и подсистема работы с файлами тесно связаны. Так как работа с диском напрямую очень медленна, ядро использует в качестве прослойки оперативную память.
malloc() использует больше памяти: происходит копирование в user space. Также потребляется больше CPU, и мы получаем больше переключений контекста, чем если бы мы работали с файлом через mmap() .
Какие выводы можно сделать? Мы можем работать с файлами, как с памятью. У нас есть lazy lоading, то есть мы можем замапить очень-очень большой файл, и он будет подгружаться в память процесса через Page Cache только по мере надобности. Всё также происходит быстрее, потому что мы используем меньше системных вызовов и, в конце концов, это экономит память. Ещё стоит отметить, что при завершении программы память никуда не девается и остается в Page Cache.
В начале было сказано, что вся запись и чтение идут через Page Cache, но иногда по какой-то причине, есть необходимость в отходе от такого поведения. Некоторые программные продукты работают таким способом, например MySQL с InnoDB.
Подсказать ядру, что в ближайшее время мы не будем работать с этим файлом, и заставить выгрузить страницы файла из Page Cache можно с помощью специальных системных вызовов:
- posix_fadvide();
- madvise();
- mincore().
Утилита vmtouch также может вынести страницы файла из Page Cache – ключ “e”.
Readahead
Поговорим про Readahead. Если читать файлы с диска через Page Cache каждый раз постранично, то у нас будет достаточно много Page Fault и мы будем часто ходить на диск за данными. Поэтому мы можем управлять размером Readahead: если мы прочитали первую и вторую страничку, то ядро понимает, что, скорее всего, нам нужна и третья. И так как ходить на диск дорого, мы можем прочитать немного больше заранее, загрузив файл наперёд в Page Cache и отвечать в будущем из него. Таким образом происходит замена будущих тяжёлых мажорных (major) Page Faults на минорные (minor) page fault.
Итак мы выдали всем память, все процессы довольны, и внезапно память у нас закончилась. Теперь нам нужно ее как-то освобождать. Процесс поиска и выделения свободной памяти в ядре называется Page Reclaiming. В памяти могут находится страницы памяти, которые нельзя забирать, – залокированные страницы (locked). Помимо них есть ещё четыре категории страниц. Cтраницы ядра, которые выгружать не стоит, потому что это затормозит всю работу системы; cтраницы Swappable – это такие страницы анонимной памяти, которые никуда, кроме как в swap устройство выгрузить нельзя; Syncable Pages – те, которые могут быть синхронизированы с диском, а в случае открытого файла только на чтение – такие страницы можно с лёгкостью выбросить из памяти; и Discardable Pages – это те страницы, от которых можно просто отказаться.
Источники пополнения Free List
Если говорить упрощённо, то у ядра есть один большой Free List (на самом деле, это не так), в котором хранятся страницы памяти, которые можно выдавать процессам. Ядро пытается поддерживать размер этого списка в каком-то не нулевом состоянии, чтобы быстро выдавать память процессам. Пополняется этот список за счёт четырех источников: Page Cache, Swap, Kernel Memory и OOM Killer.
Мы должны различать участки памяти на горячую и холодную и как-то пополнять за счет них наши Free Lists. Page Cache устроен по принципу LRU/2 очереди. Есть активный список страниц (Active List) и инактивный список (Inactive List) страничек, между которыми есть какая-то связь. В Free List прилетают запросы на выделение памяти (allocation). Система отдаёт страницы из головы этого списка, а в хвост списка попадают страницы из хвоста инактивного (inactive) списка. Новые страницы, когда мы читаем файл через Page Cache, всегда попадают в голову и проходят до конца инактивного списка, если в эти страницы не было еще хотя бы одного обращения. Если такое обращение было в любом месте инактивного списка, то страницы попадают сразу в голову активного списка и начинают двигаться в сторону его хвоста. Если же в этот момент опять к ним происходит обращение, то страницы вновь пробиваются в верх списка. Таким образом система пытается сбалансировать списки: самые горячие данные всегда находятся в Page Cache в активном списке, и Free List никогда не пополняется за их счет.
Также тут стоит отметить интересное поведение: страницы, за счет которых пополняется Free List, которые в свою очередь прилетают из инактивного списка, но до сих пор не отданные для аллокации, могут быть возвращены обратно в инактивный списка (в данном случае в голову инактивного списка).
Итого у нас получается пять таких листов: Active Anon, Inactive Anon, Active File, Inactive File, Unevictable. Такие списки создаются для каждой NUMA ноды и для каждой Memory Zone.
Источник



