- Linux: перенаправление
- Три стандартных потока ввода/вывода
- Перенаправление стандартного потока вывода
- Перенаправление стандартного потока ввода
- Перенаправление стандартного потока ошибок
- Итоги
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Использование потоков, конвейеров и перенаправлений в Linux
- Стандартный вывод ошибок.
- Конвейер
Linux: перенаправление
Если вы уже освоились с основами терминала, возможно, вы уже готовы к тому, чтобы комбинировать изученные команды. Иногда выполнения команд оболочки по одной вполне достаточно для решения некоей задачи, но в некоторых случаях вводить команду за командой слишком утомительно и нерационально. В подобной ситуации нам пригодятся некоторые особые символы, вроде угловых скобок.

Для оболочки, интерпретатора команд Linux, эти дополнительные символы — не пустая трата места на экране. Они — мощные команды, которые могут связывать воедино различные фрагменты информации, разделять то, что было до этого цельным, и делать ещё много всего. Одна из самых простых, и, в то же время, мощных и широко используемых возможностей оболочки — это перенаправление стандартных потоков ввода/вывода.
Три стандартных потока ввода/вывода
Для того, чтобы понять то, о чём мы будем тут говорить, важно знать, откуда берутся данные, которые можно перенаправлять, и куда они идут. В Linux существует три стандартных потока ввода/вывода данных.
Первый — это стандартный поток ввода (standard input). В системе это — поток №0 (так как в компьютерах счёт обычно начинается с нуля). Номера потоков ещё называют дескрипторами. Этот поток представляет собой некую информацию, передаваемую в терминал, в частности — инструкции, переданные в оболочку для выполнения. Обычно данные в этот поток попадают в ходе ввода их пользователем с клавиатуры.
Второй поток — это стандартный поток вывода (standard output), ему присвоен номер 1. Это поток данных, которые оболочка выводит после выполнения каких-то действий. Обычно эти данные попадают в то же окно терминала, где была введена команда, вызвавшая их появление.
И, наконец, третий поток — это стандартный поток ошибок (standard error), он имеет дескриптор 2. Этот поток похож на стандартный поток вывода, так как обычно то, что в него попадает, оказывается на экране терминала. Однако, он, по своей сути, отличается от стандартного вывода, как результат, этими потоками, при желании, можно управлять раздельно. Это полезно, например, в следующей ситуации. Есть команда, которая обрабатывает большой объём данных, выполняя сложную и подверженную ошибкам операцию. Нужно, чтобы полезные данные, которые генерирует эта команда, не смешивались с сообщениями об ошибках. Реализуется это благодаря раздельному перенаправлению потоков вывода и ошибок.
Как вы, вероятно, уже догадались, перенаправление ввода/вывода означает работу с вышеописанными потоками и перенаправление данных туда, куда нужно программисту. Делается это с использованием символов > и в различных комбинациях, применение которых зависит от того, куда, в итоге, должны попасть перенаправляемые данные.
Перенаправление стандартного потока вывода
Предположим, вы хотите создать файл, в который будут записаны текущие дата и время. Дело упрощает то, что имеется команда, удачно названная date , которая возвращает то, что нам нужно. Обычно команды выводят данные в стандартный поток вывода. Для того, чтобы эти данные оказались в файле, нужно добавить символ > после команды, перед именем целевого файла. До и после > надо поставить пробел.
При использовании перенаправления любой файл, указанный после > будет перезаписан. Если в файле нет ничего ценного и его содержимое можно потерять, в нашей конструкции допустимо использовать уже существующий файл. Обычно же лучше использовать в подобном случае имя файла, которого пока не существует. Этот файл будет создан после выполнения команды. Назовём его date.txt . Расширение файла после точки обычно особой роли не играет, но расширения помогают поддерживать порядок. Итак, вот наша команда:
Нельзя сказать, что сама по себе эта команда невероятно полезна, однако, основываясь на ней, мы уже можем сделать что-то более интересное. Скажем, вы хотите узнать, как меняются маршруты вашего трафика, идущего через интернет к некоей конечной точке, ежедневно записывая соответствующие данные. В решении этой задачи поможет команда traceroute , которая сообщает подробности о маршруте трафика между нашим компьютером и конечной точкой, задаваемой при вызове команды в виде URL. Данные включают в себя сведения обо всех маршрутизаторах, через которые проходит трафик.
Так как файл с датой у нас уже есть, будет вполне оправдано просто присоединить к этому файлу данные, полученные от traceroute . Для того, чтобы это сделать, надо использовать два символа > , поставленные один за другим. В результате новая команда, перенаправляющая вывод в файл, но не перезаписывающая его, а добавляющая новые данные после старых, будет выглядеть так:
Теперь нам осталось лишь изменить имя файла на что-нибудь более осмысленное, используя команду mv , которой, в качестве первого аргумента, передаётся исходное имя файла, а в качестве второго — новое:
Перенаправление стандартного потока ввода
Используя знак вместо > мы можем перенаправить стандартный ввод, заменив его содержимым файла.
Предположим, имеется два файла: list1.txt и list2.txt , каждый из которых содержит неотсортированный список строк. В каждом из списков имеются уникальные для него элементы, но некоторые из элементов список совпадают. Мы можем найти строки, которые имеются и в первом, и во втором списках, применив команду comm , но прежде чем её использовать, списки надо отсортировать.
Существует команда sort , которая возвращает отсортированный список в терминал, не сохраняя отсортированные данные в файл, из которого они были взяты. Можно отправить отсортированную версию каждого списка в новый файл, используя команду > , а затем воспользоваться командой comm . Однако, такой подход потребует как минимум двух команд, хотя то же самое можно сделать в одной строке, не создавая при этом ненужных файлов.
Итак, мы можем воспользоваться командой для перенаправления отсортированной версии каждого файла команде comm . Вот что у нас получилось:
Круглые скобки тут имеют тот же смысл, что и в математике. Оболочка сначала обрабатывает команды в скобках, а затем всё остальное. В нашем примере сначала производится сортировка строк из файлов, а потом то, что получилось, передаётся команде comm , которая затем выводит результат сравнения списков.
Перенаправление стандартного потока ошибок
И, наконец, поговорим о перенаправлении стандартного потока ошибок. Это может понадобиться, например, для создания лог-файлов с ошибками или объединения в одном файле сообщений об ошибках и возвращённых некоей командой данных.
Например, что если надо провести поиск во всей системе сведений о беспроводных интерфейсах, которые доступны пользователям, у которых нет прав суперпользователя? Для того, чтобы это сделать, можно воспользоваться мощной командой find .
Обычно, когда обычный пользователь запускает команду find по всей системе, она выводит в терминал и полезные данные и ошибки. При этом, последних обычно больше, чем первых, что усложняет нахождение в выводе команды того, что нужно. Решить эту проблему довольно просто: достаточно перенаправить стандартный поток ошибок в файл, используя команду 2> (напомним, 2 — это дескриптор стандартного потока ошибок). В результате на экран попадёт только то, что команда отправляет в стандартный вывод:
Как быть, если нужно сохранить результаты работы команды в отдельный файл, не смешивая эти данные со сведениями об ошибках? Так как потоки можно перенаправлять независимо друг от друга, в конец нашей конструкции можно добавить команду перенаправления стандартного потока вывода в файл:
Обратите внимание на то, что первая угловая скобка идёт с номером — 2> , а вторая без него. Это так из-за того, что стандартный вывод имеет дескриптор 1, и команда > подразумевает перенаправление стандартного вывода, если номер дескриптора не указан.
И, наконец, если нужно, чтобы всё, что выведет команда, попало в один файл, можно перенаправить оба потока в одно и то же место, воспользовавшись командой &> :
Итоги
Тут мы разобрали лишь основы механизма перенаправления потоков в интерпретаторе командной строки Linux, однако даже то немногое, что вы сегодня узнали, даёт вам практически неограниченные возможности. И, кстати, как и всё остальное, что касается работы в терминале, освоение перенаправления потоков требует практики. Поэтому рекомендуем вам приступить к собственным экспериментам с > и .
Уважаемые читатели! Знаете ли вы интересные примеры использования перенаправления потоков в Linux, которые помогут новичкам лучше освоиться с этим приёмом работы в терминале?
Источник
ИТ База знаний
Курс по Asterisk
Полезно
— Узнать IP — адрес компьютера в интернете
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Калькулятор инсталляции IP — АТС Asterisk
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Использование потоков, конвейеров и перенаправлений в Linux
Работаем в командной строке
Операционные системы Unix традиционно используют такие понятия, как стандартный ввод, вывод и вывод ошибки. Чаще всего ввод — это клавиатура, а вывод это на кран. Но конечно же мы можем выводить исполнение какой-то команды в файл и передавать другой команде, потому что работая в Linux, создается такая последовательность из команд, т.е результат предыдущей мы отправляем следующей и т.д
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Целью данной статьи является рассмотреть:
- Перенаправление стандартных ввода, вывода и ошибок;
- Передача вывода одной команды в качестве аргументов другой;
- Получение выходных данных в файл и на стандартный вывод;
- Stdin (0) – ввод
- Stdout(1) – вывод
- Stderr (2) – вывод ошибки
- > — передать в
- >> — дописать в
- — взять из
- | — отправить следующей команде
- Tee — отправить в файл и на стандартный вывод
- Xargs – построчно передать на ввод команде
Для начала воспользуемся командой wc которая посчитает, количество слов, символов и строк в файле wc test.txt .
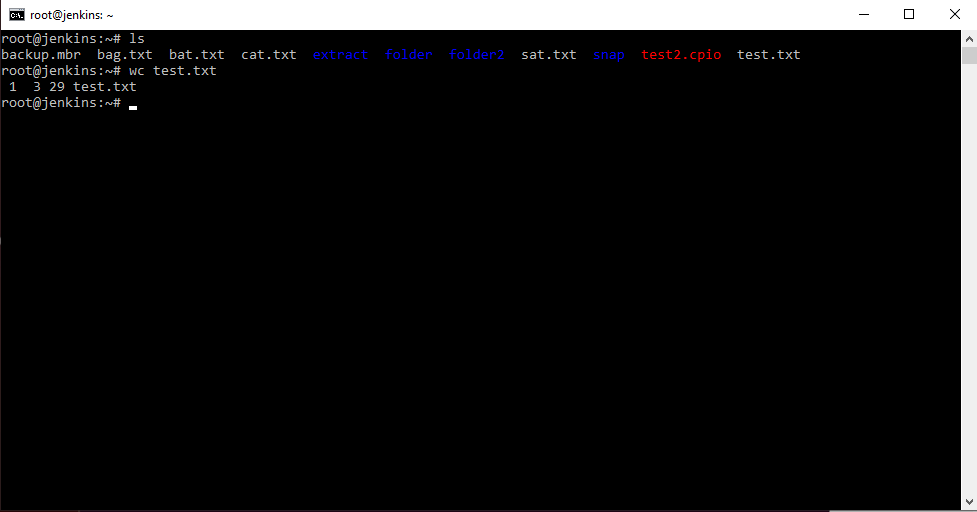
Мы можем указать данной команде другой input . Мы можем ей сказать взять информацию из файла, т.е. записать вот таким образом wc т.е. данной команде передать информацию из этого файла. И данная команда отработав посчитает в принципе то же самое. В таком варианте команда не знает с каким файлом она работает ей просто поступает вывод из файла. Файл выводит свой результат этой команде. Такая стрелочка редко используется, чаще используется стрелка в другую сторону. Например, мы можем список файлов вывести командой ls . А можем сказать, чтобы данная команда отправила результат не на наш стандартный вывод т.к. результат всех наших команд по умолчанию выводится в консоль, а например в файл ls > list.txt . По сути означает выполнить команду, а результат передать в файл. Фал можно посмотреть командой cat list.txt .
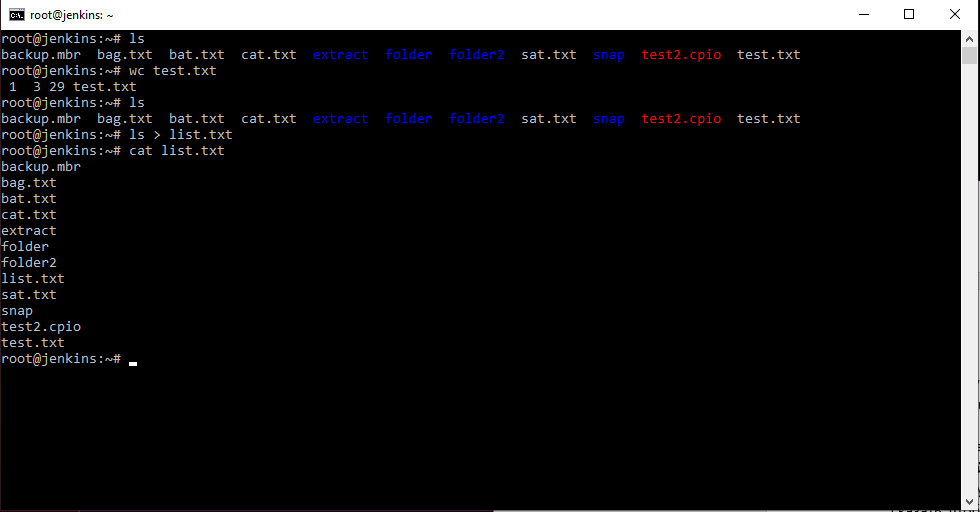
И мы можем убедится, что в данном файле находится перечень, всего что находилось в данной папке. Если мы выполним еще раз команду ls > list.txt , то данный файл каждый раз будет перезаписываться. Если же мы хотим, чтобы наш файл не перезаписывался, а дописывался, используем другую стрелочку ls >> list.txt .
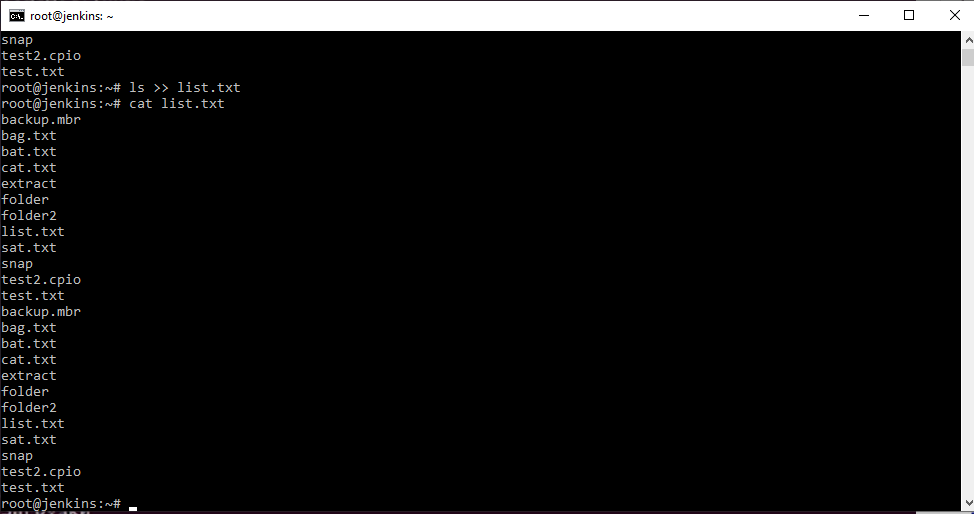
И теперь вы можете видеть, что файл стал больше. Т.е. у нас записалось, то что было, а затем еще раз добавилось. Если опять выполнить команду со стрелочками >> , то опять допишется информация в файл. Вот таким образом работают “стрелочки”.
Стандартный вывод ошибок.
Мы можем, например, сказать машине, выведи нам содержимое папки bob , которая не существует ls bob > result.txt , естественно мы получим ошибку которую система вывела на экран. Экран является стандартным выводом ошибок. В нашем случае нет папки bob и нет файла resut.txt . Если мы хотим отправить ошибку в файл, так же как результат выполнения команды, то ls bob 2> result.txt , вспоминаем основные понятия, в которых было указанно, что 2 – это стандартный вывод ошибки.
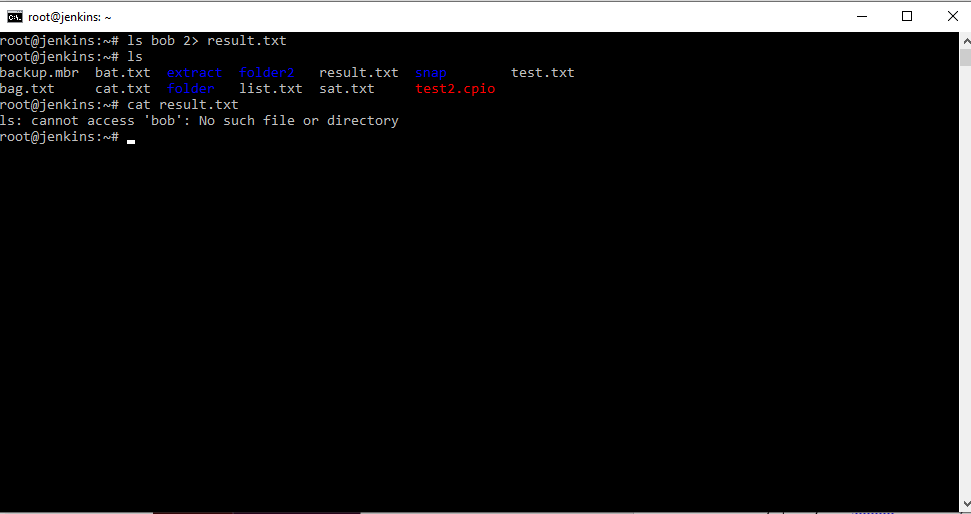
Следовательно, на экране мы уже не видим ошибки, потому что она отправилась в указанный файл.
Кстати мы можем объединить стандартный вывод команды и стандартный вывод ошибки. Например: ls bob > result.txt 2> error.txt . Выведи содержимое папки bob в файл result.txt , а если возникнет ошибка внеси в файл error.txt .
В таком случае и команда выполнится и что-то будет в файле и если ошибка возникнет, то она будет записана в файл error.txt . Это можно применять на практике, когда мы что-то делаем и предполагаем, что в процессе выполнения возникнут ошибки, то используя данную конструкцию данные ошибки мы все можем отправить в отдельный файл.
Конвейер
Конвейер умеет передавать выходные данные из одной программы, как входные данные для другой. Т.е. выполняется команда, мы получаем результат и передаем эти данные далее на обработку другой программе.
Например, выполнить команду ls и далее мы могли стрелочкой отправлять результаты выполнения команды в файл, т.е. мы меняли только стандартный вывод, а не передавали другой программе. А можем выполнить ls | grep r , т.е. получить содержимое и передать по конвейеру команде сортировки и сказать отсортировать по наличию буквы r , а если перенаправить еще вывод в файл, то cat имя файла , мы сможем увидеть информацию в файле.
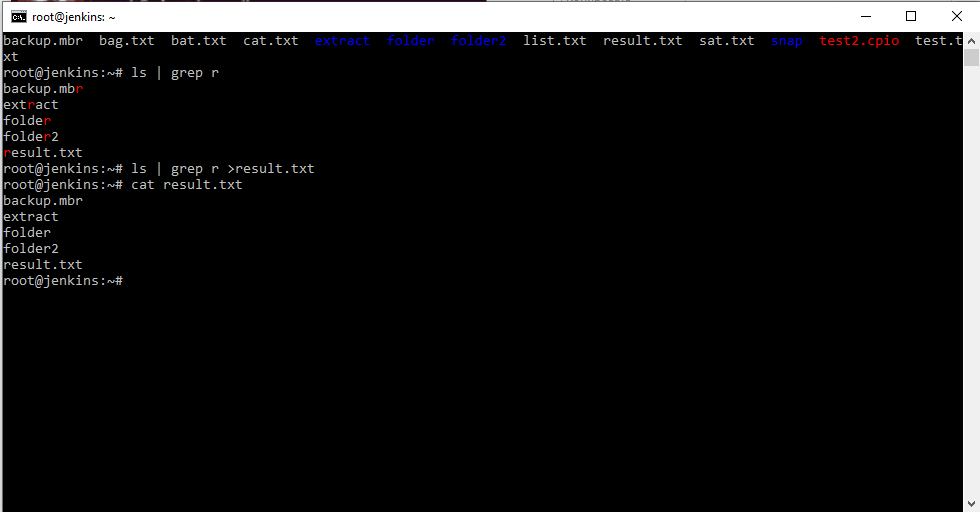
Но есть другая команда tee которая позволяет работать немного удобнее. Например: ls | tee output.txt . Те данная команда выводит информацию сразу на экран и в указанный файл. Что достаточно удобно с точки зрения работы с выводами.
И еще одна команда xargs – она построчно работает с выводами. Если у нас есть какая-то команда, которая выдает нам вывод в виде нескольких строк ответа, то мы можем эти строки построчно передавать этой команде, т.е. не одной кашей, а построчно. Например find . –name “*.txt” найти все файлы в текущем каталоге с расширением txt . И если бы мы захотели удалить все эти файлы нам бы пришлось построчно их удалять, но мы можем сказать, чтобы выходные данные были переданы по конвейеру xargs и удалить. 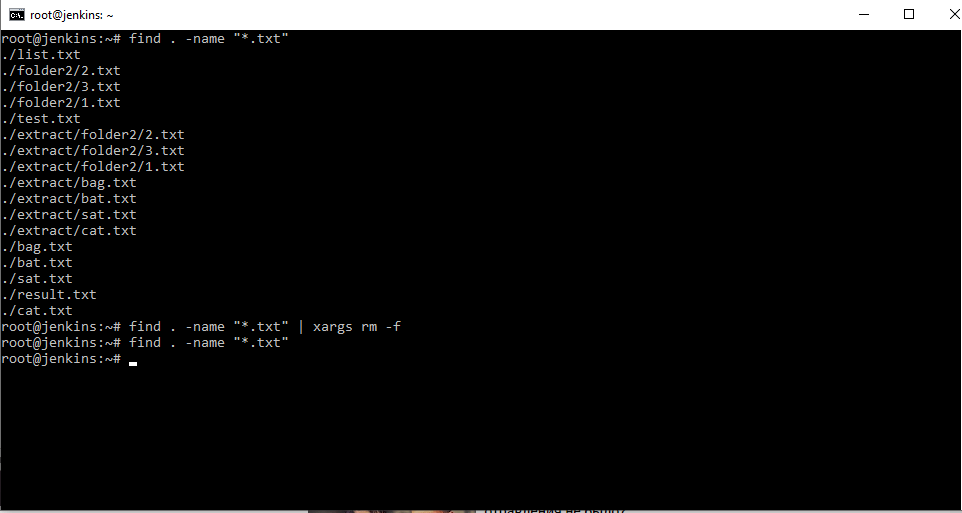
Как видите после данной конструкции команд файлов не осталось. Т.е. данные построчно передались на команду удаления, которая построчно каждый файл с ключом –f (принудительно) их и удалила.
Мини — курс по виртуализации
Знакомство с VMware vSphere 7 и технологией виртуализации в авторском мини — курсе от Михаила Якобсена
Источник



