- Конвертирование файлов в кодировку UTF-8 в Linux
- Конвертирование файлов из UTF-8 в ASCII
- Конвертирование нескольких файлов в кодировку UTF-8
- Как перекодировать имена файлов из CP1251 в UTF-8
- Re: Как перекодировать имена файлов из CP1251 в UTF-8
- Re: Как перекодировать имена файлов из CP1251 в UTF-8
- Re: Как перекодировать имена файлов из CP1251 в UTF-8
- Re: Как перекодировать имена файлов из CP1251 в UTF-8
- Re: Как перекодировать имена файлов из CP1251 в UTF-8
- Re: Как перекодировать имена файлов из CP1251 в UTF-8
- Re: Как перекодировать имена файлов из CP1251 в UTF-8
- Re: Как перекодировать имена файлов из CP1251 в UTF-8
- проблемы с кодировкой в названии файлов
- LinuxSoID
- понедельник, 2 февраля 2009 г.
- Преобразование кодировки имени файла
- Смена кодировки имен файлов
Конвертирование файлов в кодировку UTF-8 в Linux
Оригинал: How to Convert Files to UTF-8 Encoding in Linux
Автор: Aaron Kili
Дата публикации: 2 ноября 2016 года
Перевод: А. Кривошей
Дата перевода: ноябрь 2017 г.
В этом руководстве мы рассмотрим кодировки символов и разберем несколько примеров преобразования файлов из одной кодировки в другую с помощью утилиты командной строки. Затем мы покажем, как преобразовать файлы в Linux из любой кодировки (charset) в UTF-8.
Как вы, наверное, уже знаете, компьютер не понимает и не хранит информацию в виде букв, цифр или чего-либо еще. Он работает только с битами. Бит имеет только два возможных значения — 0 или 1, true или false, да или нет. Все остальное кодируется последовательностями битов.
Простыми словами, кодировка символов — это способ кодировки различных символов определенными последовательностями нулей и единиц. Когда мы вводим текст и сохраняем его в файл, слова и предложения, которые мы набираем, состоят из разных символов, а символы преобразуются в биты с помощью кодировки.
Существуют различные схемы кодирования, такие как ASCII, ANSI, Unicode и другие. Ниже приведен пример кодировки ASCII.
В Linux для преобразования текста из одной кодировки в другую используется утилита командной строки iconv.
Вы можете проверить кодировку файла с помощью команды file, используя флаг -i или -mime, который печатает строку типа mime, как в приведенных ниже примерах:

Синтаксис команды iconv следующий:
Где -f или —from-code задает входную кодировку, а -t или —to-encoding задает конечную кодировку.
Для того, чтобы вывести список всех доступных опций, введите:
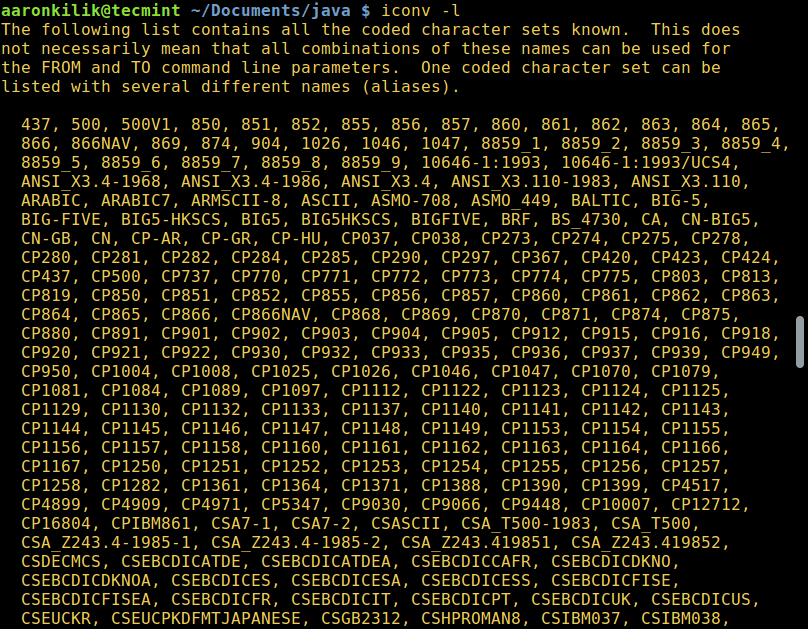
Конвертирование файлов из UTF-8 в ASCII
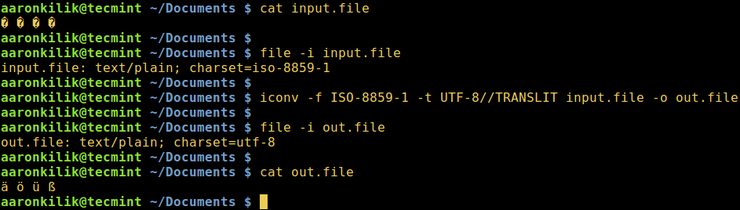
Далее мы научимся конвертировать текст из одной кодировки в другую. Приведенная ниже команда преобразует текст из ISO-8859-1 в кодировку UTF-8.
Рассмотрим файл input.file, который содержит следующие символы:
(Прим: вы увидите эти символы на снимке ниже)
Начнем с проверки кодировки файла, затем просмотрим его содержимое. Мы можем преобразовать все символы в кодировку ASCII.
После запуска команды iconv мы затем проверяем содержимое выходного файла и новую кодировку, как показано ниже.
Примечание. Если в команду добавлена строка //IGNORE, то символы, которые не могут быть преобразованы, и ошибка выводятся после преобразования.
Далее, если добавлена строка //TRANSLIT, как в приведенном выше примере (ASCII//TRANSLIT), преобразуемые символы при необходимости и по возможности транслитерируются. Это означает, что если символ не может быть представлен в целевой кодировке, его можно аппроксимировать одним или несколькими похожими символами.
Далее, любой символ, который не может быть транслитерирован и которого нет в целевой кодировке, заменяется в выводе вопросительным знаком (?).
Конвертирование нескольких файлов в кодировку UTF-8
Возвращаясь к основной теме нашей статьи, мы можем написать небольшой скрипт для преобразования нескольких или всех файлов в каталоге в кодировку UTF-8, под названием encoding.sh:
Сохраните этот файл и сделайте скрипт исполняемым. Запускайте его из той директории, где расположены ваши файлы.
Важное замечание. Вы также можете также использовать этот скрипт для преобразования нескольких файлов из одной заданной кодировки в другую (любую), просто меняйте со значения переменных FROM_ENCODING и TO_ENCODING, не забывая об имени выходного файла «$
Для получения дополнительной информации почитайте руководство iconv:
Подводя итог этой статье, необходимо отметить, что понимание способов преобразования текста из одной кодировки в другую — это знания, необходимые каждому пользователю компьютера, а тем более программистам, когда дело касается работы с текстами.
Если вы хотите лучше понять проблему кодировок символов, прочитайте следующие статьи:
Источник
Как перекодировать имена файлов из CP1251 в UTF-8
Проблема вот в чем:
linux, debian. раньше в системе основной локалью была CP1251, теперь я перешел на UTF-8. В системе есть дисковый раздел с файловой системой reiserfs на которой хранится много файлов. Так вот, бытностью CP1251 там было создано много файлов с русскими именами в CP1251 кодировке. При смене локали на UTF-8 все эти имена отобразились как . Даже если файловую систему просматривать через броузер с выставленной кодировкой CP1251 всё равно имена файлов — . Как можно перекодировать эти . в нормальные русские UTF-8.

Re: Как перекодировать имена файлов из CP1251 в UTF-8

Re: Как перекодировать имена файлов из CP1251 в UTF-8
apt-cache show conmv W: Не могу найти пакет conmv E: Не найдено ни одного пакета
Re: Как перекодировать имена файлов из CP1251 в UTF-8
>apt-cache show conmv W: Не могу найти пакет conmv E: Не найдено ни >одного пакета
apt-cache search conmv
Re: Как перекодировать имена файлов из CP1251 в UTF-8
#apt-cache search conmv #
пусто, нету такого 🙂
Re: Как перекодировать имена файлов из CP1251 в UTF-8
convmv — filename encoding conversion tool
Re: Как перекодировать имена файлов из CP1251 в UTF-8
господа, я перепробовал и comvmv и скрипт из faq — не фига не отрабатывает, как имена файлов были . так и остаются.
может быть эти скрипты работают только в случае koi8-r в cp1251 и наоборот, но не для utf-8?
Re: Как перекодировать имена файлов из CP1251 в UTF-8
>как имена файлов были . так и остаются.
Сначала стоит переименовать файлы, а потом менять локаль
Re: Как перекодировать имена файлов из CP1251 в UTF-8
Попробуй ls >files, а потом iconv -f cp1251 -t utf8 files >files.1
И еще посмотри вывод ls в виде hexdump, чтобы убедиться, что это действительно имена в cp1251 (а не настоящие вопросики)
Источник
проблемы с кодировкой в названии файлов
Перенес файлы с одного сервера на другой. Некоторые символы в названиях файлов стали отображаться как квадраты, например «№». Причем с этими файлами нельзя ничего сделать через файлменеджер, ни удалить, ни переименовать, т.к. пишет что файл не сущетвует (а его видно).
Вопрос в том, что сделать, чтобы названии таких файлов корректно отображались все символы?

Можно сделать по номеру inode через find. Вменяемого решения проблемы в целом не могу сказать, не ясно что там приключилось в процессе переноса — как переносили файлы, какая ОС\локали там и там?

Включить однобайтную локаль. Например, KOI8-R. Тогда отдельные байты распарсятся без ошибок. Хоть и смысла в итоговых именах может быть никакого. Но, зато с файлами можно будет легко проводить операции — переименовывать, удалять. и т.д.
Переносил rsync, с ubuntu 12.04 (cp1251) на ubuntu 14.04(utf8). С локального компьютера, где стоит ubuntu 14.04, подключаюсь через файловый менеджер к старому серверу и тоже вижу квадраты. Т.е. проблема возникла не во время переноса
подскажите, пожалуйста, что для этого нужно)
Если имена файлов уже в cp1251, то выставить лучше cp1251. Для этого надо выполнить
После этого, кстати, можно будет пройтись по файлам скриптом, автоматически переименовывая их в UTF-8. Например, таким:
/cp1251toutf8. Тогда можно просто перейти в директорию с файлами и выполнить
После переименования можно будет вернуть обратно UTF-8.
не хотелось бы выставлять cp1251. в названии файлов, думаю кириллицы нет, только с символами типа «№» проблемы почему то(
rsync не меняет кодировку имен файлов, как записано, так и сохраняет. Вот и остались в однобайтной CP1251. Для перекодирования можно использовать утилиту convmv:
Потому, что этих символов нет в ASCII. Соответственно, для однобайтной cp1251 их коды больше чем 127. Что для парсера юникода включает _последовательности_ из ряда байтов. При этом, поскольку, эти байты никто не подбирал, чтобы они создавали корректные для UTF-8 последовательности, местами получаются невалидные для UTF-8 последовательности (да, в UTF-8 есть такое). И парсеры юникода ломаются.
Для парсеров же однобайтных кодировок любые последовательности байт валидны, поскольку каждый отдельный байт воспринимается как отдельный указатель на один из 256-ти символов.
юзал без ключа «—notest», сам затупил. Очень много нервных клеток вы мне съэкономили)
Источник
LinuxSoID
Интересные и полезные заметки связанные с ОС Linux
понедельник, 2 февраля 2009 г.
Преобразование кодировки имени файла
Часто бывает, что в системе остаются такие артефакты, как файлы,
имя которых записано в кодировке koi8-r или cp1251.
Обычно такое случается, когда раздел или устройство с которого были скопированы файлы, были смонтированы без указания кодировки, или с указанием неверной кодировки.
Выглядит все это вот так:
# ls
. 1 . 3
Чтобы легко и просто переделать имя файла в читабельный вид, можно воспользоваться утилитой convmv.
Если у вас имена файлов в кодировке koi8-r, то перекодировать их можно так:
convmv -t koi8-r -f utf8 * — выведет список файлов в старой и в новой кодировках:
# convmv -f koi8-r -t utf8 *
Starting a dry run without changes.
mv «./����1» «./Файл1»
mv «./����3» «./Файл3»
И если вас это устраивает, добавляем опцию —notest и программа уже реально переименует файлы:
convmv -f koi8-r -t utf8 —notest *
Convmv поддерживает также кучу дополнительных полезных опций:
—list Покажет список поддерживаемых кодировок.
-r Рекурсивно обойти каталоги.
-i Спрашивать о каждом действии (интерактивный режим).
—lower Переделывает имя файла в нижний регистр
convmv -r -f koi8-r -t utf-8 —notest
Каждому пользователю, в домашнем каталоге которого утилита convmv переименовала хотя бы один файл, был автоматически выслан журнал переименований.
При необходимости можно выполнить обратное преобразование:
convmv -r -f utf-8 -t koi8-r
После проверки вывода команды повторить с ключем —notest. Ключ -r включает рекурсивный обход каталогов.
Переходим в папку с файлами/папками с отличной от системной кодировкой, затем выполняем:
% convmv -f cp1251 -t utf-8 ./
Конвертируем имена из cp1251 в utf-8, вывод этой команды покажет новое имя файла/папки, но не будет переименовывать, если новое имя правильное, то запустим эту же команду с опцией —notest.
Для рекурсивного переименования запускаем convmv с опцией -r.
(Замените koi8-r кодировкой, с которой хотите конвертировать)
# convmv -f koi8-r -t utf-8 filename
Вот пример конвертирования в папке рекурсивно:
convmv -f koi8-r -t utf-8 ./Music —notest -r
Источник
Смена кодировки имен файлов
Здравствуйте. Как перекодировать имена файлов и каталогов вида #U0440#U0438#U0441#U0443#U043d#U043e#U043a-1.png и подобного? Их очень много и это по ходу когда-то было в UTF-8 и теперь с ними что-то случилось. Прошу помощи. Пробовал convmv, но это кажется не то что нужно.

Решается простеньким скриптом. Можно на баше, можно на чём-нибудь ещё.
Скрипт напишу, но приведете пример команды как конвертировать хотя бы один файл?
Скрипт напишу, но приведете пример команды как конвертировать хотя бы один файл?
Но учти, что этот код небезопасен. Например, если в каком-то имени окажутся закодированные юникодом ../../../../../etc/passwd то после запуска такого скрипта от рута файл /etc/passwd будет перезаписан, так что в реальном скрипте нужно ввести дополнительные проверки. Ну и ещё нет гарантий, что подобная команда корректно отработает для всех имён.
Считай что это просто proof of concept
Кроме того, заменятся не только #Uxxxx но и другие последовательности, что может быть нежелательным.
Но тут нужно проанализировать всё дерево, встречаются ли там другие спецсимволы. Есть ли там # в другом контексте и тд.

что было, сказать теперь вряд ли возможно, но то, что есть — это UCS2 или UTF-16, причем первые 2 цифры — 04 — старший байт.
Спасибо большое! Попробовал вот такой скрипт:
и там где есть пробелы, выдаёт не одной строкой:
Как это можно сделать чтобы одной строкой выводило а не переносило на следующую?
Вообще на этом сайте описано множество типичных ошибок пишущих скрипты.
Кроме того -name «*» вообще излишен.
Спасибо, но как всё-же сделать чтобы не переносило на новую строку? Как бы сделали Вы? 🙂
Источник



